
概述
Logstash是一个类似实时流水线的开源数据传输引擎,它像一个两头连接不同数据源的数据传输管道,将数据实时地从一个数据源传输到另一个数据源中。在数据传输的过程中,Logstash还可以对数据进行清洗、加工和整理,使数据在到达目的地时直接可用或接近可用,为更复杂的数据分析、处理以及可视化做准备。
既然需要将数据搬运到指定的地点,为什么不在数据产生时,就将数据写到需要的地方呢?这个问题可以从以下几个方面理解。首先,许多数据在产生时并不支持直接写入到除本地文件以外的其他数据源。比如大多数第三方软件在运行中产生的日志,都以文本形式写到本地文件中。其次,在分布式环境下许多数据都分散在不同容器甚至不同机器上,而在处理这些数据时往往需要将数据收集到一起统一处理。最后,即使软件支持将数据写入到指定的地点,但随着人们对数据理解的深入和新技术的诞生又会有新的数据分析需求出现,总会有一些接入需求是原生软件无法满足的。综上,Logstash的核心价值就是在于它将业务系统与数据处理系统隔离开来,屏蔽了各自系统变化对彼此的影响,使系统之间的依赖降低并可独自进化发展。
为了达成这样的能力,Logstash设计了良好的体系结构并基于插件开发。下面就先看一下Logstash的体系结构。
12.1 Logstash体系结构
Logstash数据传输管道所具备的流水线特征,体现在数据传输过程分为三个阶段一一输入、过滤和输出。这三个阶段按顺序依次相连,像一个加工数据的流水线。在实现上,它们分别由三种类型的插件实现,即输入插件、过滤器插件和输出插件,并可通过修改配置文件实现快速插拔。除了这三种类型的插件以外,还有一种称为编解码器(Codec)的插件。编解码器插件用于在数据进入和离开管道时对数据做解码和编码,所以它一般都是与具体的输入插件或输出插件结合起来使用。
事件(Event)是Logstash中另一个比较重要的概念,它是对Logstash处理数据的一种面向对象的抽象。如果将 Logstash比喻为管道,那么事件就是流淌在管道中的涓涓细流。事件有输入插件在读入时产生,不同输入插件产生的事件的属性并不完全相同,但其中一定会包含有读入的原始数据。过滤器插件会对事件做进一步处理,处理的方式主要体现在对事件属性的访问、添加和修改。最后,输出插件会将事件转换为目标数据源的数据格式并将它们存储到目标数据源中。
在Logstash管道中,每个输入插件都是在独立的线程中读取数据并产生事件。但输入插件并不会将事件直接传递给过滤器插件或输出插件,而是将事件写入到一个队列中。队列可以是基于内存的,也可以是基于磁盘的可持久化队列。Logstash管道会预先生成一组工作线程,这些线程会从队列中取出事件并在过滤器中处理,然后在通过输出插件将事件输出。事件队列可以协调输入插件与过滤器插件、输出插件的处理能力,使得Logstash具备一定的削峰填谷能力。
除了输入插件使用事件队列与过滤器插件、输出插件交互以外,Logstash还在输出插件与目标数据源之间提供了一个死信队列(Dead Letter Queue)。死信队列会在目标数据源没有成功接收到数据时,将失败的事件写入到死信队列中以供后续做进一步处理。死信队列是一种容错机制,但目前仅支持Elasticsearch。
可见,输入插件、过滤器插件、输出插件、编解码插件以及事件、队列等组件,共同协作形成了整个Logstash的管道功能,它们构成Logstash的体系结构,如图12-1所示。
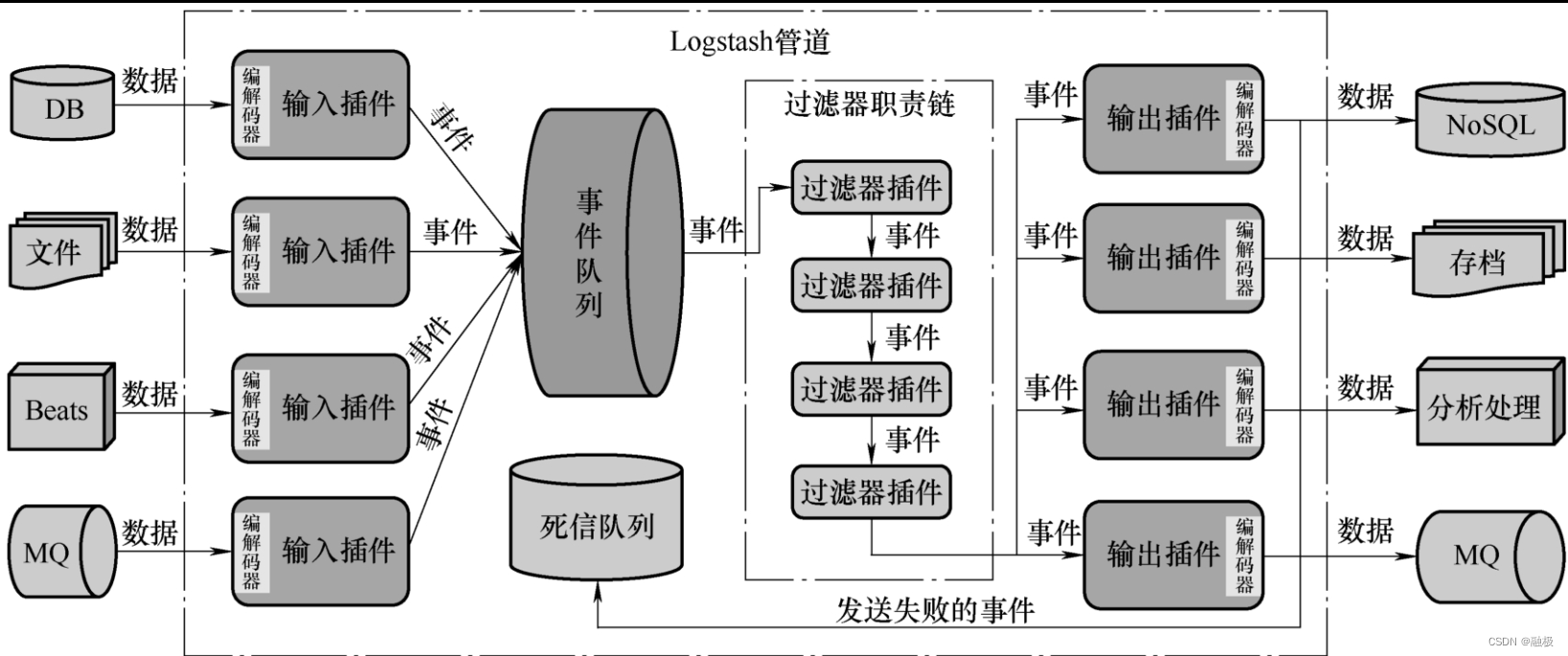

通过图12-1可以看到,插件、事件、队列是Logstash中的核心概念。
12.1.1插件
插件(Plugin)最吸引人的特征就是它的的可插拔性,通过简单的配置就可接入系统并增强系统功能。Logstash提供了丰富的输入、过滤器、输出和编解码器插件,它们也都是通过配置接入系统并增强Logstash在某一方面的功能。输入插件的作用是使数据进入管道并生成数据传输事件,过滤器插件则对进入管道的事件进行修改、清洗等预处理,而输出插件则将过滤器处理好的事件发送到目标数据源。输入插件和输出插件都可以使用编解码器在数据进入或退出管道时对数据进行编码或解码,使数据以用户期望的格式进入或退出管道。
插件另一个吸引人的特征就是它们往往都开发便捷,一般都会提供统一接口作为开发框架,开发人员只要遵从接口规范并编写逻辑就可以开发出新的插件。Logstash插件使用Ruby语言开发,可以作为gems托管到RubyGems.org上,所以建议读者简单了解一下Ruby语法。本小节仅介绍插件的管理,具体插件的使用将在本书第13~14章中介绍。
1. logstash-plugin命令
Logstash官方提供的插件并非全部绑定在Logstash中,有一部分插件需要用户在使用时手工安装,比如log4j输入插件在默认情况下就没有安装。Logstash提供了一条插件管理的命令logstash-plugin,可以用于查看、安装、更新或删除插件。除了Logstash官方提供的插件以外,用户还可以根据需要自定义插件,这些插件也需要使用logstash-plugin命令管理。有关logstash-plugin的具体使用方法,可通过执行logstash-plugin–help查看帮助。示例12-1中列出了部分logstash-plugin命令的使用实例:

通过logstash-plugin的list命令可以查看Logstash已经安装的插件,该命令的基本格式为“logstash-plugin list[OPTIONS][PLUGIN]”,其中OPTIONS包括–installed、–group[NAME]、–verbose、–help等;PLUGIN则用于指定插件名称,支持使用*号等通配符。通过logstash-plugin的install命令可以安装Logstash插件,要安装的插件需要预先在RubyGems.org上注册发布。未在RubyGems.org上注册发布的插件,可以指定.gem文件路径通过本地安装插件。
通过logstash-plugin的update、remove和generate命令可以更新、删除和创建插件,如果update命令中没有指定具体插件名称则将更新所有插件。在示例12-1的generate命令中,–type参数指定了插件类型为输入插件input,–name参数指定了插件名称为first,而–path则指定了插件目录创建的路径。示例12-1中的generate命令执行结束后,会在C盘根路径下创建一个名为logstash-input-first的目录。在这个目录中会按插件目录结构,将需要的目录和文件全部创建出来。
2.插件配置
Logstash插件的可插拔性,除了体现在可通过logstash-plugin命令方便地安装与删除以外,还体现在已安装插件的使用和关闭仅需要通过简单的配置即可实现。Logstash配置文件分为两类,一类是用于设置Logstash自身的配置文件,主要是设置Logstash启动、执行等基本信息的配置文件。这类配置文件位于Logstash安装路径的config目录中,包括logstash.yml、pipelines.yml、jvm.options、log4j.properties等文件。对于使用DEB或RPM方式安装的Logstash,这些配置文件位于/etc/logstash目录中;而使用Docker镜像启动的Logstash,它们则位于/usr/share/logstash/config中。在这些配置文件中,logstash.yml文件是核心配置文件,采用的语法格式为YAML;其余文件分别用于配置JVM和log4j。本章不会专门讨论这些配置文件,但会在讲解具体组件时介绍与它们相关的配置参数。
另一类配置就是设置Logstash管道的配置文件了,它们用于设置Logstash如何应用这几种插件组成管道,是应用Logstash最核心的内容之一。
最简单的配置Logstash管道的方式就是在本书第1章1.4.2节中示例中展示的方式,通过logstash命令参数-e配置管道。再有一种方式就是通过-f参数指定管道配置文件的路径,以配置文件的形式设置Logstash管道。
对于Linux版本中使用DEB或RPM安装的Logstash,管道配置文件位于/etc/logstash/conf.d/目录中;而使用Docker镜像启动的Logstash,它们则位于/usr/share/logstash/pipeline中。Logstash在启动时会自动扫描这个目录,并加载所有以.conf为扩展名的配置文件,所以用户可以将Logstash的管道配置文件放置在这个目录中。
Logstash管道配置的语法格式不是YAML,它的语法格式是更接近Ruby哈希类型的初始化格式,有关Logstash管道配置将在本章第12.2节中统一介绍。
12.1.2 事件
Logstash事件由一组属性组成,包括数据本身、事件产生时间、版本等。不同输入插件产生事件的属性各不相同,这些事件属性可以在过滤器插件和输出插件中访问、添加、修改或是删除。由于事件本身由输入插件产生,所以在输入插件中不能访问事件及其属性。这里所说的对事件及其属性的访问是指在Logstash管道配置中的访问,比如过滤器插件配置中根据事件属性执行不同的过滤等。管道配置在本书第1章1.4.3节中已经见过,在本章12.2节中会对管道配置做更详细的介绍。
在事件属性中有一个比较特殊的属性tags,它的类型为数组,包含了插件在处理事件过程中为事件打上所有标签。比如插件在处理事件中发生了异常,一般都会为事件添加一个异常标签。标签本身就是一个字符串,没有特别的限制。事件的标签在一开始的时候都是空的,只有插件为事件打上了新标签,这个属性才会出现在输出中。所以,总体来说可以认为事件是一组属性和标签的集合。
访问事件属性
在管道配置中访问事件属性的最基本语法形式是使用方括号和属性名,例如[name]代表访问事件的name属性;如果要访问的属性为嵌套属性,则需要使用多层次的路径,如[parent][child]相当于访问parent.child属性;如果要访问的属性为事件的最顶层属性则可以省略方括号。
事件中有哪些属性取决于输入插件的类型,但有一些事件属性几乎在所有事件中都有,比如@version、@timestamp和@metadata等。这类属性大多以@开头,可以认为是事件的元属性。其中,@version代表了事件的版本,@timestamp是事件的时间戳。@metadata与前述两个属性不同,它在默认情况下是一个空的散列表(Hash table)。@metadata最重要的特征是不会在最终的输出中出现,即使在插件中向这个散列表中添加了内容也是如此。只有当输出插件使用rubydebug解码器,并且将它的metadata参数设置为true,@metadata属性才会在输出中显示,例如:

@metadata属性设计的目的并不是为了给输出添加数据,而是为了方便插件做数据运算。@metadata是在Logstash 1.5之后加入的新属性,它类似于一个共享的存储空间,在过滤器插件和输出插件中都可以访问。因为在实际业务有一些运算结果是需要在插件间共享而又不需要在最终结果中输出,这时就可以将前一插件处理的中间结果存储在@metadata中。
除了使用方括号访问事件属性以外,在插件参数中还可以通过“%{field_name}”的形式访问事件属性,其中field_name就是前述的方括号加属性名的形式。例如,在文件输出插件中将日志根据级别写入到不同的文件中:

在示例12-3中,loglevel是当前事件的一个属性名称,file输出插件的path参数通过%{loglevel}的形式读取这个属性的值,并以它的值为日志文件名称。
2.事件API
事件API主要是在一些支持Ruby脚本的插件中使用,比如Aggregate插件、Ruby插件等。这些插件一般都有一个code参数接收并运行Ruby脚本,在这些脚本中就可以使用event内置对象访问、修改或者删除事件属性。事实上,event对象是一个按Ruby语法定义的对象,可以通过methods方法将它所有的方法提取出来。例如在示例12-4的配置中,在输出事件中就会添加一个event_methods属性,其中会包含event对象的近百个方法名称:

在实际应用中,除非是特别复杂的应用场景,一般都只会使用event对象的get和set两个方法,前者用于访问事件属性,而后者则用于添加或修改事件属性。例如在示例12-2和12-4中使用的ruby过滤器中,code参数就使用了set方法为事件添加了属性。属性名称的格式与上一节介绍的方括号加属性名的格式一致,例如event.get(‘[parent][child]’)就是获取parent属性下的child子属性。除了这两个方法以外,还可以通过remove方法删除某个属性,或者使用cancel方法将整个事件作废。
尽管event对象有近百个方法,但在使用上可以将它看成是散列表,event.to_hash方法就是将event中的事件属性转换为真正的散列表,这时就可以按照Ruby散列表语法访问它的键值对了。最后,如果想要为事件添加标签,可以调用event.tag(‘tag content’)方法。
12.1.3 队列
在互联网时代,许多活动或突发事件会导致应用访问量在某一时间点瞬间呈几何式增长。在这种情况下,应用产生的数据也会在瞬间爆发,而类似Logstash这样的数据管道要搬运的数据也会突然增加。如果没有应对这种瞬间数据爆炸的机制,轻则导致应用数据丢失,重则直接导致系统崩溃,甚至引发雪崩效应将其他应用一并带垮。
应对瞬间流量爆炸的通用机制是使用队列,将瞬间流量先缓存起来再交由后台系统处理。后台系统能处理多少就从队列中取出多少,从而避免了因流量爆炸导致的系统崩溃。Logstash输入插件对接的事件队列实际上就是应对瞬间流量爆炸、提高系统可用性的机制,它利用队列先进先出的机制平滑事件流量的峰谷,起到了削峰填谷的重要作用。
除了输入插件使用的事件队列,输出插件还有一个死信队列。这个队列将会保存输出插件没有成功发送出去的事件,它的作用不是削峰填谷而是容错。
1.持久化队列
Logstash输入插件默认使用基于内存的事件队列,这就意味中如果Logstash因为意外崩溃,队列中未处理的事件将全部丢失。不仅如此,基于内存的队列容量小且不可以通过配置扩大容量,所以它能起到的缓冲作用也就非常有限。为了应对内存队列的这些问题,可以将事件队列配置为基于硬盘存储的持久化队列(Persistent Queue)。
持久化队列将输入插件发送过来的事件存储在硬盘中,只有过滤器插件或输出插件确认已经处理了事件,持久化队列才会将事件从队列中删除。当Logstash因意外崩溃后重启,它会从持久化队列中将未处理的事件取出处理,所以使用了持久化队列的Logstash可以保证事件至少被处理一次。
如果想要开启Logstash持久化队列,只要在logstash.yml文件中将queue.type参数设置为persisted即可,它的默认值是memory。当开启了持久化队列后,队列数据默认存储在Logstash数据文件路径的queue目录中。数据文件路径默认是在Logstash安装路径的data目录,这个路径可以通过path.data参数修改。持久化队列的存储路径则可以通过参数path.queue修改,它的默认值是${path.data}/queue。
尽管持久化队列将事件存储在硬盘上,但由于硬盘空间也不是无限的,所以需要根据应用实际需求配置持久化队列的容量大小。Logstash持久化队列容量可通过事件数量和存储空间大小两种方式来控制,在默认情况下Logstash持久化队列容量为1024MB即1GB,而事件数量则没有设置上限。当持久化队列达到了容量上限,Logstash会通过控制输入插件产生事件的频率来防止队列溢出,或者拒绝再接收输入事件直到队列有空闲空间。持久化队列事件数量容量可通过queue.max_events修改,而存储空间容量则可通过queue.max_bytes来修改。
为了提升处理效率,Logstash持久化队列在存储上是分页的,一页就是一个独立的文件。在默认情况下,页文件的容量上限为64MB,可使用queue.page_capacity来修改页文件的大小。当页文件达到容量上限时,Logstash就会创建出一个新的页文件出来。输入事件只能添加到页文件的尾部,而不允许在页文件中删除事件或插入事件。只有当页文件存储的所有事件全部处理完,页文件才会一次性删除。显然一次性删除整个页文件的效率,比在页文件中删除单个事件要高得多。
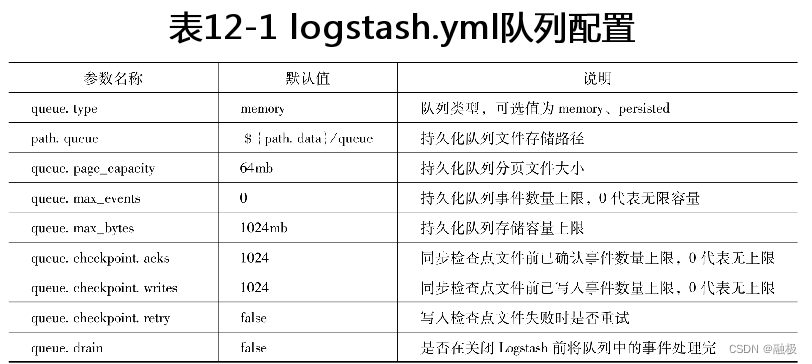
除了页文件以外,在持久化队列存储文件中还有一个检查点文件(Checkpoint File)。检查点文件记录了持久化队列自身分页的情况,以及每页事件处理的情况等等。Logstash管道的工作线程通过读取检查点文件来了解队列是否有新事件加入,还有哪些事件没有处理等等信息。所以当新事件持久化到页文件时,必须要同时更新检查点文件,而且这个操作必须是原子的才能保证不丢失事件。但是如果写入一个事件就更新检查点文件,对于事件进入队列时的性能影响会比较大,所以持久化队列默认会在写入1024个事件后统一更新一次检查点文件。这也就意味着,事件持久化到队列后并不会立即更新检查点文件,而在这时如果发生崩溃则将丢失这些信息。不过可以通过配置queue.checkpoint.writes参数,将默认值1024修改为1就可以保证事件不会丢失了。但显然这对性能的影响会比较大,需要根据实际情况做权衡。logstash.yml配置文件中有关队列的参数总结在表12-1中。
事实上在许多高访问量的应用中,单纯使用Logstash内部队列的机制还是远远不够的。许多应用会在Logstash接收数据前部署专业的消息队列,以避免瞬间流量对后台系统造成冲击。这就是人们常说的MQ(Message Queue),比如Kafka、RocketMQ等。这些专业的消息队列具有千万级别的数据缓存能力,从而可以保护后续应用避免被流量压跨。所以在Logstash的输入插件中也提供了一些对接MQ的输入插件,比如kafka、rabbitmq等。有关MQ的内容已经超出本书要讨论的技术范畴,但在本书第13章中会专门介绍针对这些MQ的输入和输出插件。
2.死信队列
Logstash输入插件的事件队列位于输入插件与其他插件之间,而死信队列则位于输出插件与目标数据源之间。如果Logstash处理某一事件失败,事件将被写入到死信队列中。Logstash死信队列以文件的形式存储在硬盘中,为失败事件提供了采取补救措施的可能。死信队列并不是Logstash中特有的概念,在许多分布式组件中都采用了死信队列的设计思想。由于死信队列的英文名称为Dead Letter Queue,所以在很多文献中经常将它简写为DLQ。
Logstash在目标数据源返回400或404响应状态码时认为事件失败,而支持这种逻辑的目标数据源只有Elasticsearch。所以Logstash死信队列目前只支持目标数据源为Elasticsearch的输出插件,并且在默认情况下死信队列是关闭的。开启死信队列的方式与持久化队列类似,也是在logstash.yml文件中配置,参数名为dead_letter_queue.enable。死信队列默认存储在Logstash数据路径下的dead_letter_queue目录中,可通过path.dead_letter_queue参数修改。死信队列同样也有容量上限,默认值为1024MB,可通过dead_letter_queue.max_bytes参数修改。logstash.yml文件中有关死信队列的参数总结在表12-2中。

虽然死信队列可以缓存一定数量的错误事件,但当容量超过上限时它们还是会被删除,所以依然需要通过某种机制处理这些事件。Logstash为此专门提供了一种死信队列输入插件,它可以将死信队列中的事件读取出来并传输至另一个管道中处理。有关死信队列输入插件请参考本书第13章13.1.3节。
12.1.4 Logstash监控
在本书第11章11.3节中曾经介绍过如何通过Kibana监控Elasticsearch和Kibana自身,只要开启监控数据收集就可以在Kibana中看到这两个组件的监控卡片。
事实上,Logstash也可以通过一些简单的配置实现监控。从监控机制上来说,Logstash的监控与Elasticsearch和Kibana的监控一样,Elasticsearch在监控中依然处于核心地位。首先要开启Elasticsearch监控数据收集,接下来只要再告诉Logstash将监控数据发送到哪里就可以了。在Logstash的配置文件中,添加xpack.monitoring.elasticsearch.hosts参数,该参数可以接收一组Elasticsearch节点地址。修改后重启Logstash,进入Kibana监控功能就会看到Logstash的监控卡片了,如图12-2所示。

12.2 管道配置
Logstash安装路径下的bin目录包含了一些重要的命令,启动Logstash管道就是通过其中的logstash命令实现。logstash命令在执行时会读取管道配置,然后根据管道配置初始化管道。管道配置可通过命令行-e参数以字符串的形式提供,也可以通过命令行-f参数以文件形式提供。前者定义管道配置的方式称为配置字符串(Config String)后者则是配置文件,这两种方式只能任选其一而不能同时使用。
在logstash.yml配置文件中,也包含了config.string和path.config两个参数,分别用于以上述两种方式配置默认管道。如果使用logstash–help查看该命令的参数就会发现,-e实际上是–config.string参数的简写,而-f则是–path.config参数的简写。所以如果在logstash.yml文件中指定了config.string或path.config,就不需要在命令行中设置它们了。除了这两个参数以外,logstash命令与logstash.yml配置文件之间还有许多这样用于配置管道的共享参数,下面就先来看看这些配置参数。
12.2.1 主管道配置
Logstash启动后会优先加载在logstash.yml文件中配置的管道,并且为这个管道指定惟一标识main,本书称这个管道为主管道。无论是通过-e参数以配置字符串的形式创建管道,还是通过-f参数以配置文件的形式创建管道,它们在默认情况下都是在修改主管道的配置。
既然有主管道存在,那么是不是还可以配置其他管道呢?答案是肯定的。事实上Logstash可以在一个进程中配置多个管道,不同的是主管道是在logstash.yml文件中配置,而其他管道则是在pipeline.yml文件中配置。但是pipeline.yml中配置的管道与主管道互斥,如果在logstash.yml文件中或是使用logstash命令行的-e、-f等参数配置了主管道,那么pipeline.yml文件中配置的其他管道就会被忽略。只有主管道缺失,logstash命令才会尝试通过pipeline.yml文件初始化其他管道。无论是主管道还是其他管道,它们的配置参数都是相同的,示例12-5就是在logstash.yml文件中主管道的一些配置参数:

在示例12-5中,pipeline.id用于设置管道的ID,对应logstash命令参数为-pipeline.id。而pipelne.workers则用于设置并发处理事件的线程数量,默认情况下与所在主机CPU核数相同,对应logstash命令参数为–pipeline.works。可见配置文件中的参数名称与logstash命令行参数之间就差了“–”符号,只是logstash命令为部分常用参数提供了简写形式,比如-e和-f。表12-3中列出了所有logstash.yml中有关管道的配置参数,它们加上“–”前缀都可以在logstash命令行中使用,表格第二列中还给出了它们在命令行中使用时的简写形式:
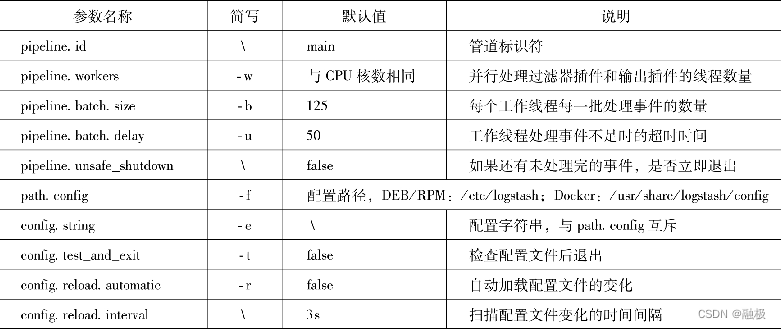
Logstash处理事件并不是来一个处理一个,而是先缓存125个事件或超过50ms后再统一处理。由于使用了缓存机制,所以当Logstash管道因意外崩溃时会丢失已缓存事件。在示例12-5中,pipeline.unsafe_shutdown参数用于设置在Logstash正常退出时,如果还有未处理事件是否强制退出。在默认情况下,Logstash会将未处理完的事件全部处理完再退出。如果将这个参数设置为true,会因为强制退出而导致事件丢失。同时,这个参数也解决不了因意外崩溃而导致缓存事件丢失的问题。
在这些参数中,将pipeline.batch.size参数设置大一些,会提升Logstash管道处理事件的速度,但会加大Logstash对内存的需求。所以当pipeline.batch.size参数加大时,应该通过jvm.options文件将-Xms和-Xmx参数值相应提升,以加大JVM内存分配量。
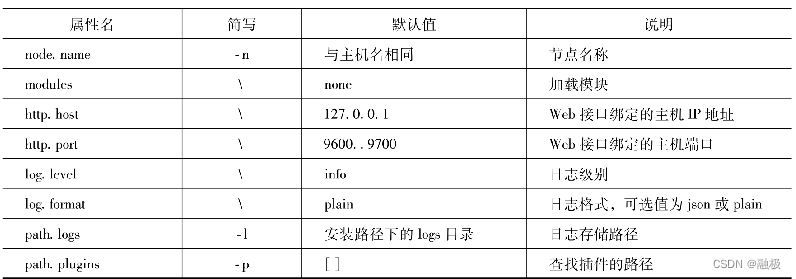
除了与管道相关的参数以外,logstash还有一些用于配置Logstash自身运行的参数,这些参数也有与logstash命令相对应的参数,见表12-4。表12-4 配置属性
事实上,如果没有通过命令行-e或-f参数明确定义管道配置,Logstash在启动时会加载pipelines.yml文件,并通过这个文件查找多管道的配置文件或配置字符串。因此学会单管道配置是学习多管道配置的基础,下面就先来看一看单个管道是如何配置的。
12.2.2 单管道配置
一个Logstash实例可以运行一个管道也可以运行多个管道,它们相互之间可以不受任何影响。一般来说,如果只需要运行一个管道可以使用logstash.yml配置的主管道;而在需要运行多个管道时才会使用pipeline.yml配置。无论是单管道还是多管道,对于其中某一具体管道的配置格式完全一致。这种格式不仅在配置文件中有效,在使用字符串配置管道时也是有效的。
1. 语法格式
管道配置由3个配置项组成,分别用于配置输入插件、过滤器插件和输出插件,如示例12-5所示。尽管输入插件、过滤器插件和输出插件在处理数据时按顺序进行,但在配置文件中它们的顺序并不重要,而且它们也都不是必要配置。所有插件配置都必须要在这三个配置项中,插件是哪一种类型就应该放置在哪一个配置项中。每一个配置项可以放多个插件配置,并可以通过一些参数设置这些插件的特性。

一个插件的具体配置由插件名称和一个紧跟其后的大括号组成,大括号中包含了这个插件的具体配置信息。虽然编解码器也是一种插件类型,但由于只能与输入或输出插件结合使用,所以编解码器只能在输入或输出插件的codec参数中出现。例如,在示例12-7中就配置了一个stdin输入插件、一个aggregate过滤器插件和一个stdout输出插件。其中,stdin使用的编解码器multiline也是一个插件,它的配置也遵从插件配置格式,由编解码器插件名称和大括号组成。在编解码器multiline的大括号中配置了pattern和what两个参数,而在过滤器插件aggregate的大括号中则配置了task_id和code两个参数。

如示例12-7所示,插件参数的格式与插件本身的配置在格式上有些相同,但又有着比较明显的区别。插件配置在插件名称与大括号之间是空格,而插件参数则是使用“=>”关联起来的键值对。其中,键是插件参数名称,而值就是参数值。这种格式与Ruby哈希类型的初始化一样,所以本质上来说每个插件的配置都是对Ruby哈希类型的初始化。所以读者在编写管道配置时,一定要区分配置的是插件还是插件参数,否则很容易会出现错误。
管道配置的这种格式中还可以添加注释,注释以井号“#”开头,可以位于文件的任意位置。在Logstash安装路径的config目录中,有一个logstash-sample.conf的样例配置文件,可以在配置管道时参考。
2. 数据类型
插件配置参数的数据类型与Ruby类似,包括数值、布尔、列表和散列表等,它们在配置参数时的格式有一些不同。简单来说,数值类型包括整型和浮点型,在配置时直接填写到参数后面即可;布尔类型包括true和false两个值,也是直接填写到参数后面;而字符串则需要使用双引号括起来。比较特别的类型还有数组和列表,它们使用方括号“[]”将一组值设置给参数;而散列表类型则使用花括号“{}”将一组键值对组成的对应关系配置给参数。Logstash官方文档中给出的这些数据类型的格式,具体见表12-5。

在这些数据类型中,散列表类型与插件配置的格式很像,它们都有名称和大括号。不同的是,哈希类型与其他参数一样都是使用“=>”将参数名称与参数值连接起来,而插件配置则没有。
默认情况下,参数值不支持转义字符,即以“\”开头的字符形式。例如参数值中包含的“\r”将会被转义为“\r”而非回车符。如果确实需要在参数值中使用转义符,可以通过logstash.yml文件将config.support_escapes参数设置为true以支持转义符。
3.分支语句
在一些情况下,用户可能会希望根据事件自身的一些特征将它们发送给不同的目标数据源,这时就可以使用Logstash提供的分支语句做控制。Logstash提供了if、else if和else语句来实现分支控制,它们可以在配置文件中使用,但也必须在三个配置项中使用。分支语句的基本语法形式如示例12-8所示:

Logstash配置文件中分支语句含义与用法与普通编程语言中的分支语句完全相同,其中的EXPRESSION就是用于判断分支走向的表达式。这些表达式可以是关系运算表达式,也可以是逻辑运算表达式,它们的运算结果是布尔类型的true或false。在表达式中可以使用的运算符见表12-6。

在表达式中可以使用第12.1.2节介绍的方式访问事件属性,还可以使用小括号给运算分组或改变运算优先级。一般来说,分支语句用于根据事件属性选择不同的插件,所以分支语句基本上都是用于具体插件配置的外层。例如在示例12-9中,根据事件的tag属性值设置了不同的aggregate过滤器插件:

4. 环境变量
在Logstash管道配置中还可以使用环境变量,基本的语法形式为“${var:default value}”。其中冒号前面的var为环境变量名称,而环境变量后面则为默认值。默认值可以设置也可以不设置,它会在环境变量缺失时作为环境变量的缺省值。
12.2.3 多管道配置
Logstash应用多管道通常是由于数据传输或处理的流程不同,使得不同输入事件不能共享同一管道。假如Logstash进程运行的宿主机处理能力超出一个管道的需求,如果想充分利用宿主机的处理能力也可以配置多管道。当然在这种情况下,也可以通过在宿主机上启动多个Logstash实例的方式,充分挖掘宿主机的处理能力。但多进程单管道的的Logstash比单进程多管道的Logstash占用资源会更多,单进程多管道的Logstash在这种情况下就显现出它的意义了。多管道虽然共享同一Logstash进程,但它们的事件队列和死信队列是分离的。在使用多管道的情况下,要分析清楚每个管道的实际负载,并以此为依据为每个管道分配合理的计算资源,起码每个管道的工作线程数量pipeline.workers应该与工作负载成正比。
配置单进程多管道的Logstash,是通过pipeline.yml配置文件实现的。pipelines.yml文件专门用于配置Logstash多管道,一般位于Logstash安装路径下的config目录中。但对于使用DEB或RPM方式安装的Logstash位于/etc/logstash目录中,而使用Docker镜像启动的Logstash则位于/usr/share/logstash/config中。
在启动Logstash时,如果没有设置主管道信息,Logstash读取pipeline.yml文件以加载管道配置信息。pipeline.yml通过config.string或path.config参数以配置字符串或配置文件的形式为每个管道设置独立的配置信息,还可以设置包括事件队列、管道工作线程等多种配置信息。pipeline.yml文件也采用YAML语法格式,它使用YAML中的列表语法来定义多个管道,在每个列表项中通过键值对的形式来定义管道的具体配置。默认情况下,logstash.yml没有配置主管道,而pipeline.yml文件的内容也全部注释了,所以直接无参运行logstash时会报pipeline.yml文件为空的错误。在pipeline.yml文件中给出了一段配置了两组管道的示例,如示例12-10所示:
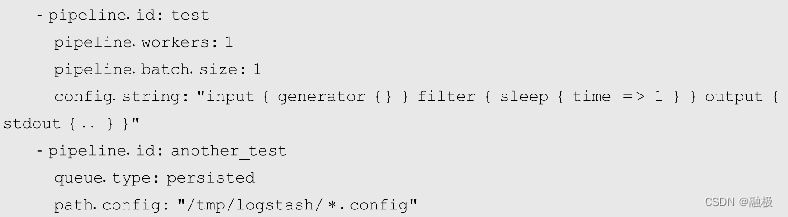
在示例12-10中配置了两组管道,它们的惟一标识分别是test和another_test。test管道使用config.string直接设置了管道的插件信息,而another_test则通过path.config指定了管道配置文件的路径。可见,pipeline.yml配置多管道时使用的参数与logstash.yml中完全一致,它还可以使用配置队列和死信队列的参数,只是这些参数都只对当前管道有效。
在Logstash新版本中还支持通过pipeline输入输出插件实现多管道之间的通信。具体来说,先在一个管道中将事件输出到pipeline输出插件定义的虚拟地址上,然后再通过另一个管道从虚拟地址中读取事件。例如在示例12-11中就是定义了两个管道之间的事件传输:

需要注意的是,截止到本书交稿时,在Logstash版本7中多管道之间的通信还处于Beta版本中。
12.3 编解码器插件
在Logstash管道中传递是事件,所以输入和输出插件都存在数据与事件的编码或解码工作。为了能够复用编码和解码功能,Logstash将它们提取出来抽象到一个统一的组件中,这就是Logstash的编解码器插件。由于编解码器在输入和输出时处理数据,所以编解码器可以在任意输入插件或输出插件中通过codec参数指定。
12.3.1 plain编解码器
Logstash版本7中一共提供了20多种官方编解码器插件,在这些编解码器插件中最为常用的是plain插件,有超过八成的输入和和输出插件默认使用的编解码器插件就是plain。plain编解码器用于处理纯文本数据,在编码或解码过程中没有定义明确的分隔符用于区分事件。与之相较,line编解码器则明确定义了以换行符作为区分事件的分隔符,每读入一行文本就会生成一个独立的事件,而每输出一个事件也会在输出文本的结尾添加换行符。line编解码器符合人们处理文本内容的习惯,所以也是一种比较常用的编解码器。除了plain和line编解码器以外,json编解码器是另一种较为常用的编解码器,主要用于处理JSON格式的文本数据。表12-7列出了Logstash中输入输出插件默认使用的编解码器,没有出现在表格中的输入输出插件使用的都是plain。
表12-7 Logstash输入输出插件默认编解码器

Logstash版本7官方输入输出插件加起来有将近100种,但在表12-7中默认使用非plain编解码器的其实没有多少。尽管plain编解码器非常重要,但它在使用上却非常简单,只有charset和format两个参数。其中,charset用于设置文本内容采用的字符集,默认值为UTF-8;而format则用于定义输出格式,只能用于输出插件中。format参数定义输出格式时,采用的是第12.1.2节介绍的“%{}”形式,例如:

在示例12-12中,Logstash在标准输入(即命令行)等待输入,并将输入内容按format参数定义的格式以两行打印在标准输出中。
12.3.2 line编解码器
12.3.3 json编解码器
12.3.4 序列化编解码器
12.3.5 collectd编解码器
12.3.6 cef编解码器
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/100099.html

