
概述
Java线程之间的通信对程序员完全透明,内存可见性问题很容易困扰Java程序员,本章将接口Java内存模型 神秘的面纱。
Java内存模型的基础
并发编程模型的两个关键问题
在命令式编程中,线程之间的通信机制有两种:共享内存和消息传递。
Java的并发采用的是共享内存模型,Java线程之间的通信总是隐式的,整个通信过程对程序员完全透明。如果编写多线程程序的Java程序员不理解隐式进行的线程之间通信的工作机制,很可能会遇到各种奇怪的内存可见性问题。
Java内存模型的抽象结构
在Java中,所有实例域、静态域和数组元素都存储在堆内存中,堆内存在线程之间共享。局部变量,方法定义参数和异常处理器参数不会在线程之间共享,它们不会有内存可见性的问题,也不受内存模型的影响。
Java线程之间的通信由Java内存模型(Java Memory Model本文简称JMM)控制,JMM决定一个线程对共享变量的写入何时对另一个线程可见。从抽象的角度来看,JMM定义了线程和主内存之间的抽象关系:线程之间的共享变量存储在主内存中,每个线程都有一个私有的本地内存,本地内存中存储了该线程用以读/写的共享变量的副本。本地内存是JMM的一个抽象概念,并不真实存在。它涵盖了缓存、写缓冲区、寄存器以及其他的硬件和编译器优化。下面是Java内存模型的抽象示意图:
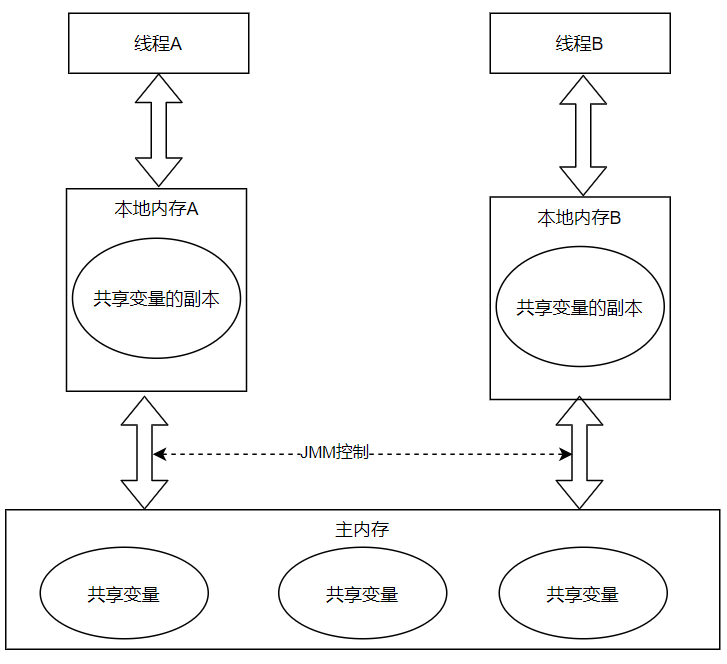
从上图看,如果线程A与线程B之间要通信的话,必须要经过下面两个步骤:
- 线程A把本地内存A中更新过的共享变量刷新到主内存中去。
- 线程B到主内存中去读取线程A之前已经更新过的共享变量。
从整体上看,通信过程必须要经过主内存。JMM通过控制主内存与每个线程的本地内存之间的交互,来为Java程序员提供内存可见性保证。
从源代码到指令序列的重排序
在执行程序时,为了提高性能,编译器和处理器常常会对指令做重排序。重排序分3种类型。
1)编译器优化的重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
2)指令级并行的重排序。现代处理器采用了指令级并行技术(Instruction-Level Parallelism, ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
3)内存系统的重排序。由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上去可能是乱序执行。
从Java源代码到最终实际执行的指令序列,会分别经历下面3种重排序,如下图所示:

上述的1属于编译器重排序,2和3属于处理器重排序。这些重排序可能会导致多线程程序出现内存可见性问题。对与编译器,JMM的编译器重排序规则会禁止特定类型的编译器重排序(不是所有的编译器重排序都要禁止)。对于处理器重排序,JMM的处理器重排序规则会要求Java编译器在生成指令序列时,插入特定类型的内存屏障(Memory Barriers)指令,通过内存屏障指令来禁止特定类型的处理器重排序。
JMM属于语言级的内存模型,它确保在不同的编译器和不同的处理器平台之上,通过禁止特定类型的编译器重排序和处理器重排序,为程序员提供一致的内存可见性保证。
并发编程模型的分类
现代的处理器使用写缓冲区临时保存向内存写入的数据。写缓冲区可以保证执行流水线持续运行,它可以避免由于处理器停顿下来等待向内存写入数据而产生的延迟。同时,通过以批处理的方式刷新写缓冲区,以及合并写缓冲区中对同一内存地址的多次写,减少对内存总线的占用。虽然写缓冲区有这么多好处,但是每个处理器上的写缓冲区,仅仅对它所在的处理器可见。这个特性会对内存操作的执行顺序产生重要的影响:处理器对内存的读/写操作的执行顺序,不一定与内存实际发送的读/写操作顺序一致。
重排序
指令重排序必须保证单线程的执行结果不会改变,也就是说指令重排序不会影响单线程的执行结果。
重排序对多线程的影响
首先是代码示例:
class RecorderExample {
int a = 0;
boolean flag = false;
public void writer() {
a = 1; // 1
flag = true; // 2
}
public void reader() {
if (flag) { // 3
int i = a * a; // 4
}
}
}
flag 变量是个标记,用来标识变量a是否已经被写入。这里假设有两个线程A和B,A首先执行writer()方法,随后B线程接着执行reader()方法。线程B在执行操作4时,能否看到线程A在操作1对共享变量a的写入呢?
答案是:不一定能看到。
由于操作1和操作2没有数据依赖关系,编译器和处理器可以对这两个操作重排序;同样,操作3和操作4只是存在控制依赖关系而不是数据依赖关系,编译器和处理器也可以对这两个操作重排序。让我们来看看,当操作1和操作2重排序是,可能会产生什么效果?
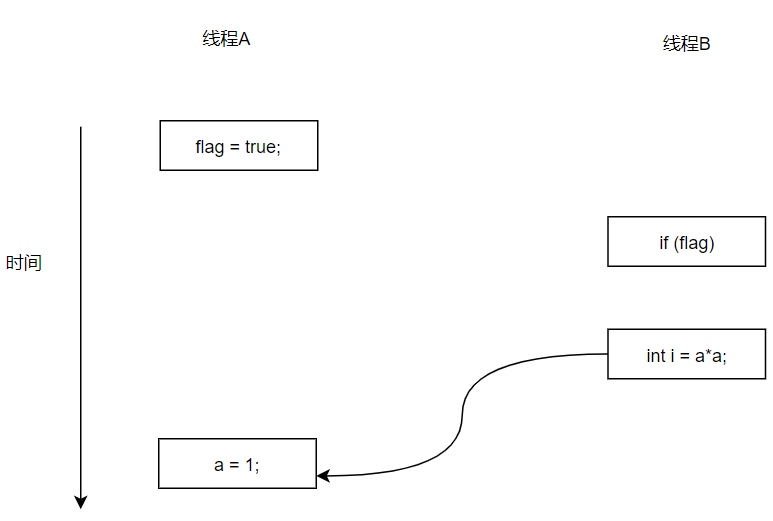
如上图,操作1和操作2做了重排序。程序执行时,线程A首先写标记编程flag,随后线程B读这个变量。由于条件判断为真,线程B将读取变量a。此时,变量a还没有被线程A写入,在这里多线程程序的语义被重排序破坏了!
下面再让我们看看,当操作3和操作4重排序是会产生什么效果(借助这个重排序,可以顺便说明控制依赖性)。下面是操作3和操作4重排序后,程序执行的时序图。
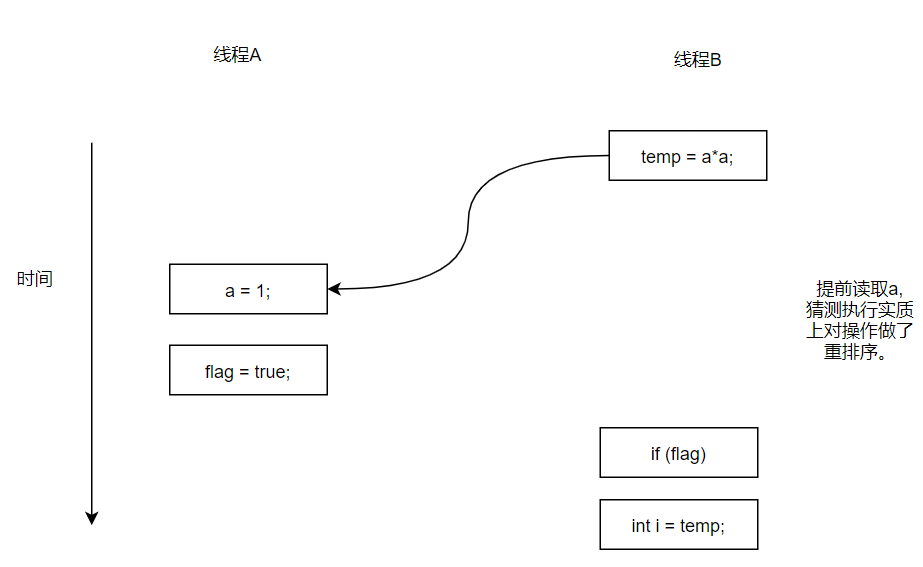
在程序中,操作3和操作4存在控制依赖关系。当代码中存在控制依赖性时,会影响指令序列执行的并行度。为此,编译器和处理器会采用猜测执行来克服控制相关性对并行度的影响。以处理器的猜测执行为例,执行线程B的处理器可以提前读取并及时a*a,然后把及时结果临时保存都一个名为重排序缓冲的硬件缓冲中。当操作3的条件判断为真时,就把计算结果写入变量i中。
从上图中我们可以看到,猜测执行实质上对操作3和4做了重排序。重排序在这里破坏了多线程程序的语义!
在单线程程序中,对存在控制依赖的操作重排序,不会改变执行结果(这也是as-if-serial语义允许对存在控制依赖的操作做重排序的原因);但在多线程程序中,对存在控制依赖的操作重排序可能会改变程序的执行结果。
顺序一致性
volatile的内存语义
锁的内存语义
final域
双重检查锁定与延迟初始化
实现方案参考设计模式之单例模式。
Java内存模型综述
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/100138.html

