
概述
并行流
我们通常使用的Stream都是单线程执行的, 可以对收集源调用parallel方法来把集合转换为并行流。并行流就是一个把内容分成多个数据块,并用不同的线程分别处理每个数据块的流。
并行流背后使用的基础架构是分支/合并框架。
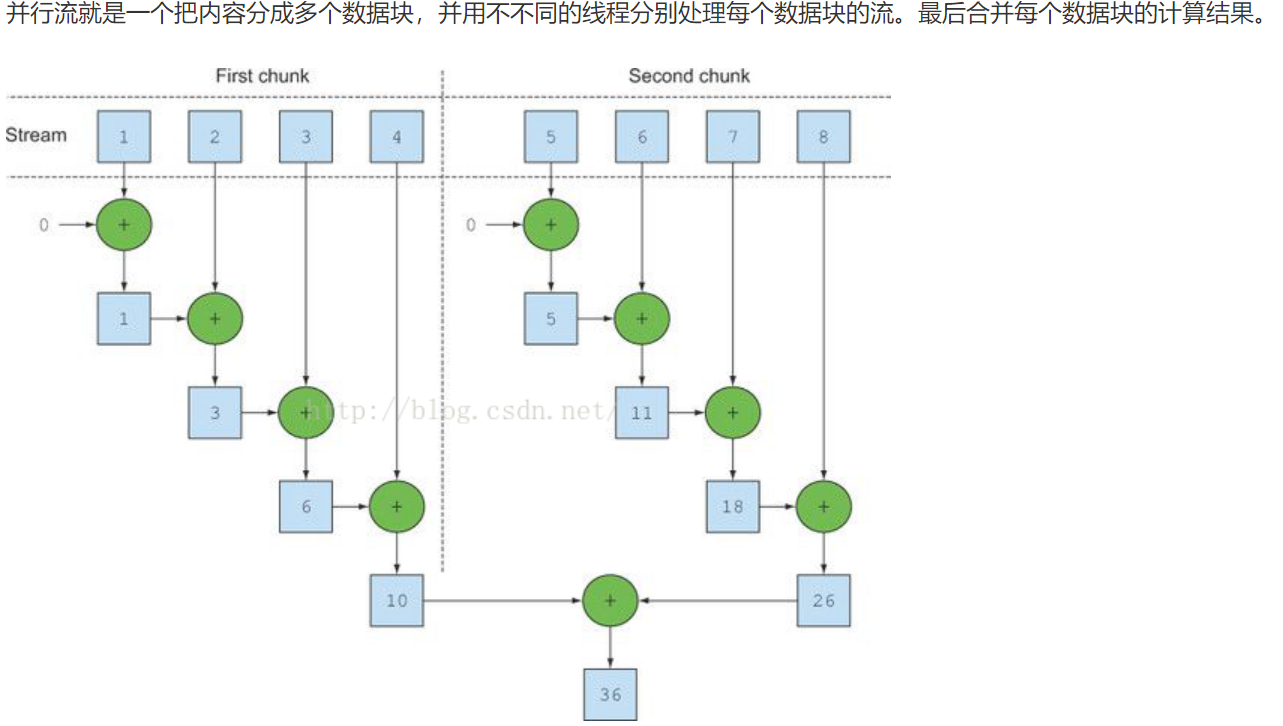
顺序流转换为并行流
你可以把流转换为并行流,对顺序流调用parallel方法即可。
public static long parallelSum( long n) {
return Stream.iterate(1L, i -> i +1).limit(n).parallel().reduce(0L,Long::sum);
}
请注意,在现实中,对顺序流调用parallel方法并不意味着流本身有任何实际的变化。它在内部实际上就是一个boolean标记,表示你想让调用parallel之后进行的所有操作都并行执行。类似地,你只需要对并行流调用sequential方法就可以把它变成顺序流。
请注意,你可能以为把这两个方法结合起来,就可以更细化地控制在遍历流时哪些操作要并行执行,哪些要顺序执行,实际上这是不可以的。
例如你可以这样做:
stream.parallel().filter().sequential().map().parallel().reduce();
实际上只有最后一次的parallel或sequential调用会影响流水线的执行。上面,流水线会并行执行,因为最后调用的是parallel。
因此,parallel/sequential在那个地方设置都一样,因为所有的中间操作都只是设置操作步骤或标记,只有终端操作设置了才会真正执行整个for循环。
分支/合并框架
分支/合并框架的目的是以递归的方式将可以并行的任务拆分成更小的任务,然后将每个子任务的结果合并起来生成整体结果。
参考:线程池之ForkJoinPool
使用RecursiveTask
工作窃取
Spliterator
Spliterator是Java 8中加入的另一个新接口;这个名字代表“可分迭代器”。和Iterator一样,Spliterator也用于遍历数据源中的元素,但它是为了并行执行而设计的。Java 8已经为集合框架中包含的所有数据结构提供了一个默认的Spliterator实现。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/100151.html

