
HTTP报文
- 用于HTTP协议交互的信息被称为HTTP报文。请求端(客户端)的HTTP报文叫做请求报文,响应端(服务器端)的叫做响应报文。HTTP报文本身是由多行(用CR+LF作换行符)数据构成的字符串文本。
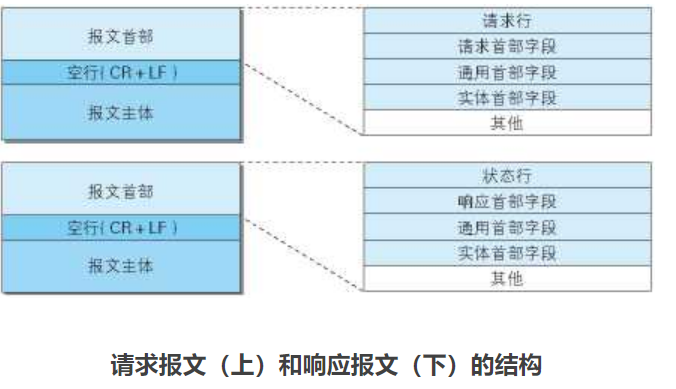
- HTTP报文大致可分为报文首部和报文主体两块。两种由最初出现的恐慌(CR+LF)来划分。通常,并不一定要有报文主体。


请求报文及响应报文的结构
示例如下:
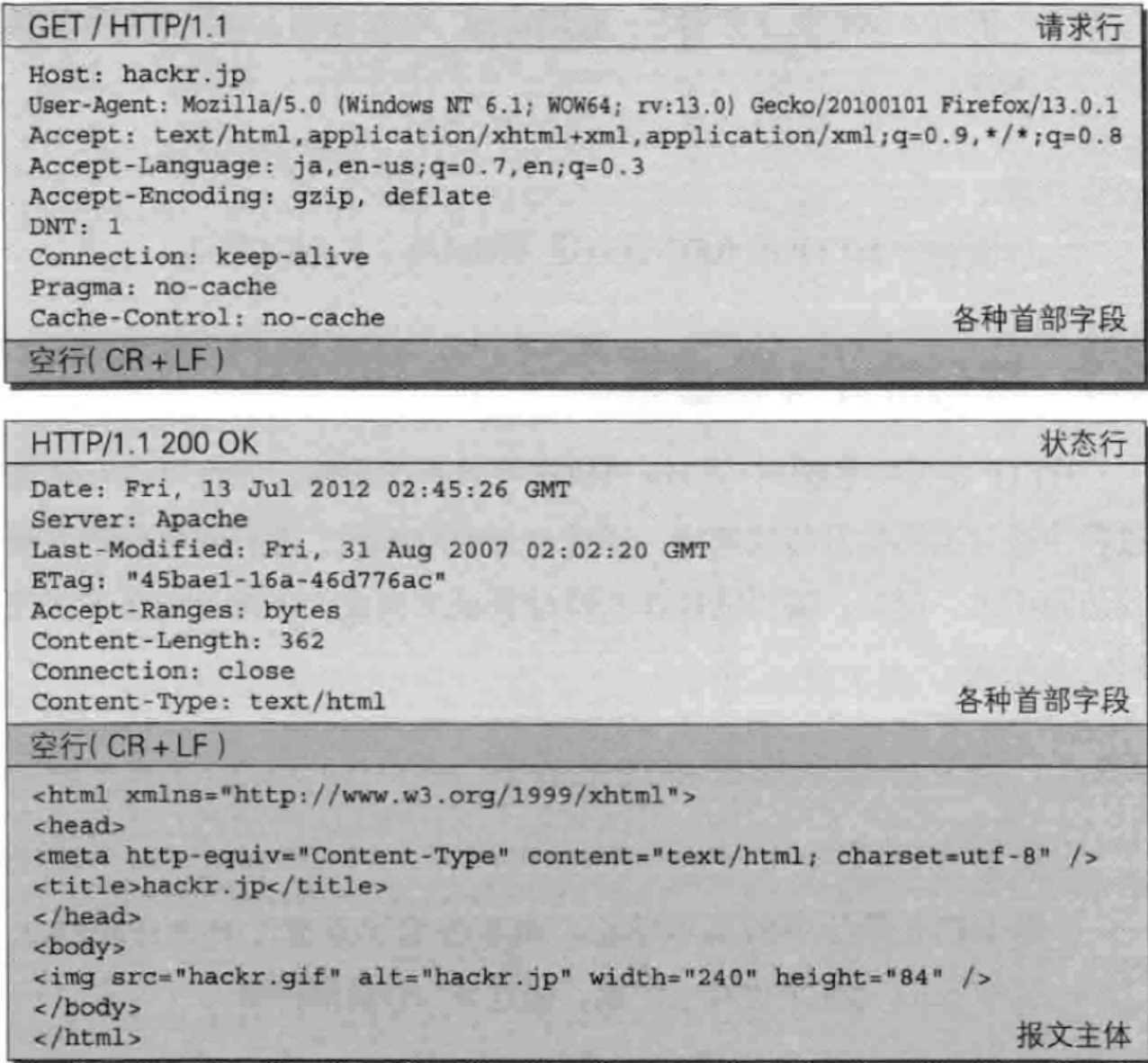
请求报文和响应报文的首部内容由以下数据组成。
请求行
包含用于请求的方法,请求URI和HTTP版本。
状态行
包含表明响应结果的状态码,原因短语和HTTP版本。
首部字段
包含表示请求和响应的各种条件和属性的各类首部。
一般有4种首部,分别是:通用首部、请求首部、响应首部和实体首部。
其他
可能包含HTTP的RFC里未定义的首部(Cookie等)。
编码提升传输速率
HTTP在传输数据时可以按照数据原貌直接传输(数据量大会造成网络阻塞,比较慢),但也可以在传输过程中通过编码提升传输速率。通过在传输时编码,能有效地处理大量的访问请求(提供传输速度)。通过在传输时编码,能有效地处理大量的方法请求。但是,编码的操作需要计算器来完成,因此会消耗更多的CPU等资源。
报文主体和实体主体的差异
报文时Http通信的基本单位,实体是有效载荷数据,报文相当于实体的传输工具,对我们有用的是实体。
- 报文(message)
是HTTP通信中的基本单位,由8位组字节流(octet sequence,其中octet为8个比特)组成,通过HTTP通信传输。 - 实体(entity)
作为请求或响应的有效载荷数据(补充项)被传输,其内容又实体首部和实体主体组成。
HTTP报文的主体用于传输请求或响应的实体主体。
通常,报文主体等于实体主体。只有当传输中进行编码操作时,实体主体的内容发送变化(编码导致内容变化),才导致它和报文主体产生差异。
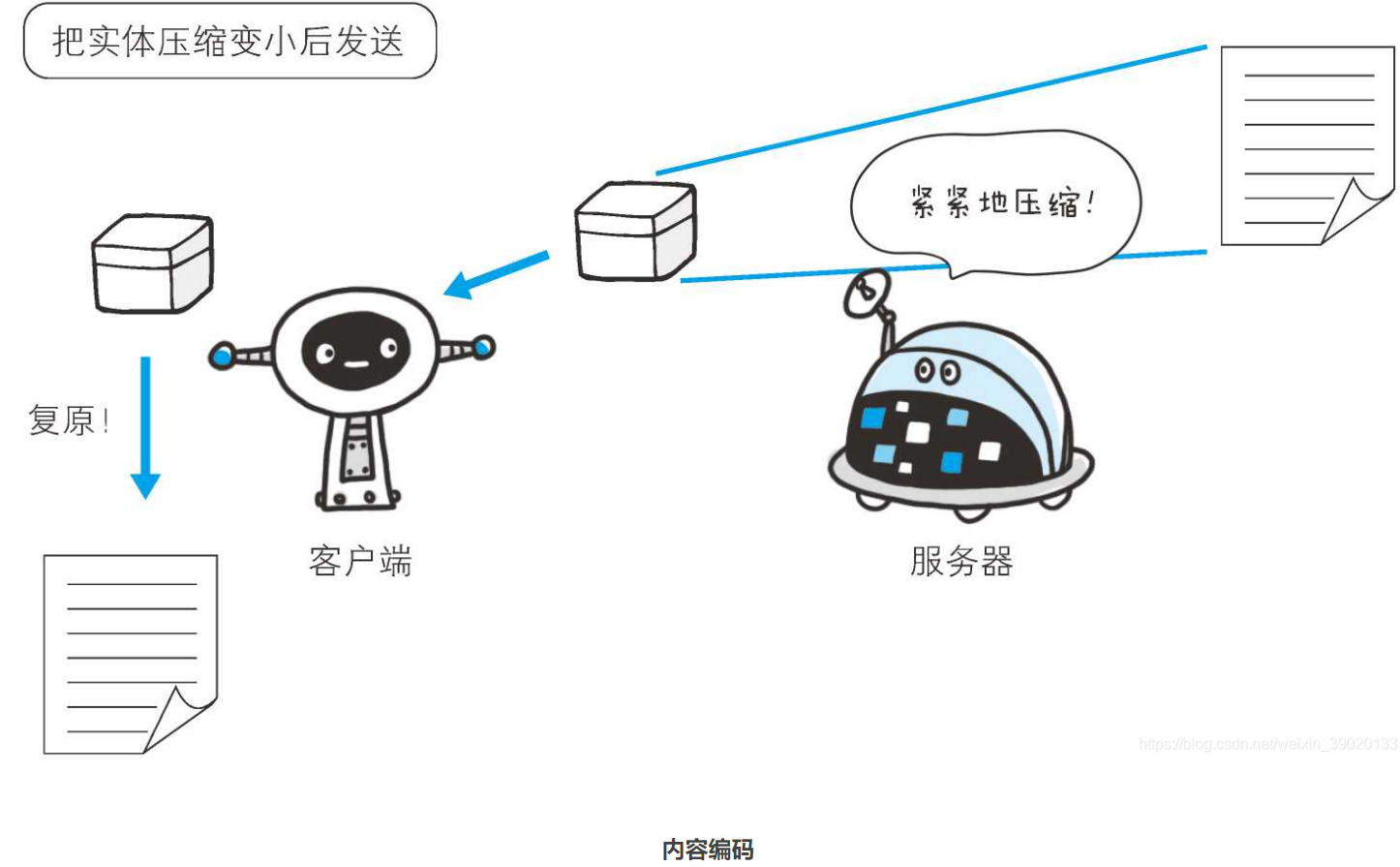
压缩传输的内容编码
- 向待发送邮件内增加附加时,为了使邮件容量变小,我们会先用ZIP等工具压缩文件后再添加附件发送。HTTP协议有一种被称为内容编码的功能也能进行类似的操作。
- 内容编码指明应用在实体内容上的编码格式,并保持实体信息原样压缩。
- 内容编码后的实体由客户端接收并负责解码。
常用的内容编码有以下几种: - gzip(GNU zip)
- compress(UNIX系统的标准压缩)
- deflate(zlib)
- identity(不进行编码)
分割发送的分块传输编码
- 在HTTP通信过程中,请求的编码实体资源尚未全部传输完成之前,浏览器无法显示请求页面。在传输大容量数据时,通过把数据分割成多块,能够让浏览器逐步显示页面。
- 这种把实体主体分块的功能称为分块传输编码(Chunk Transfer Coding)。
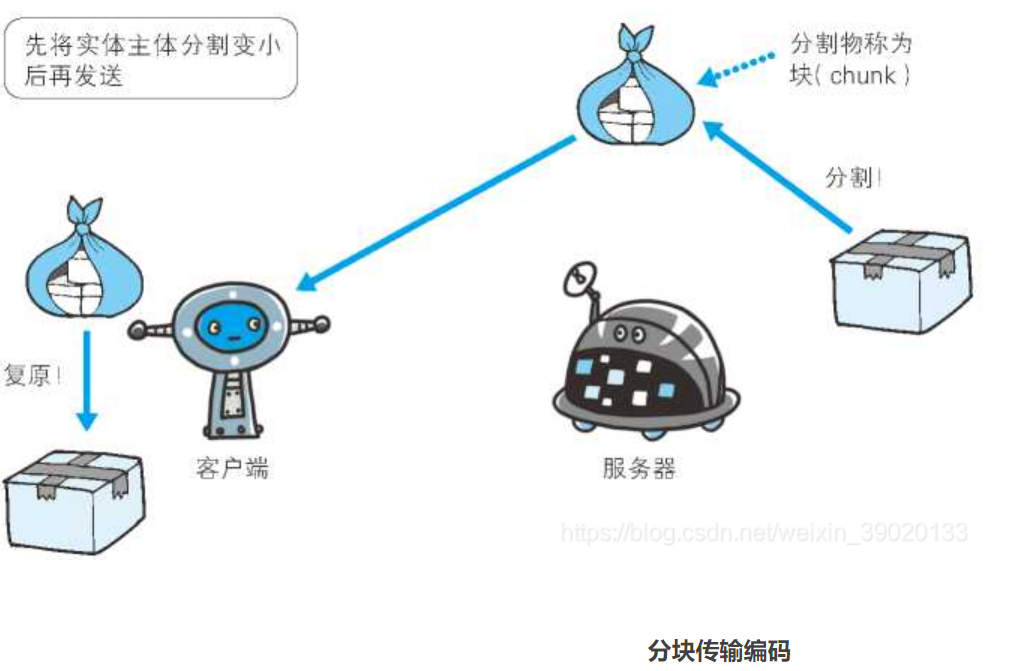
- 分块传输编码会将实体主体分割成多个部分(块)。没一块都会用十六进制来标记块的大小,而实体主体的最后一块会使用“0(CR+LF)”来标记。
- 使用分块传输编码的实体主体会由接收的客户端负责解码,恢复到编码请求的实体主体。
- HTTP/1.1中存在一种称为传输编码(Transfer Coding)的机制,它可以在通信时按某种编码方式传输,但只定义作用于分块传输编码中。
发送多种数据的多部分对象集合
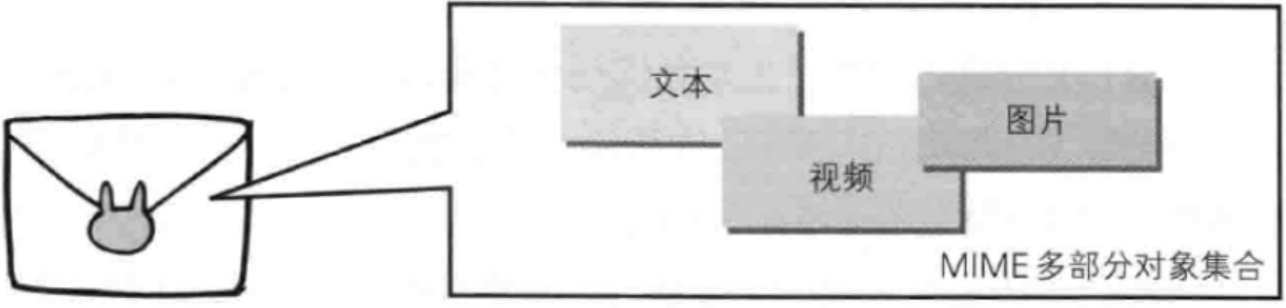
- 发送邮件是,我们可以在邮件里写入文字并添加多份附件。这是因为采用了MIME(Multipurpose Internet Mail Extensions,多用途英特网邮件扩展)机制,它允许邮件处理文本、图片、视频等多个不同类型的数据。例如,图片等二进制数据以ASCII码字符串编码的方式指明,就是利用MIME来描述标记数据类型。而在MIME扩展中会使用一种称为多部分对象集合(Multipart)的方法,来容纳多份不同类型的数据。
- 相应的,HTTP协议中也采纳了多部分对象集合,发送的一份报文主体内可含有多类型实体。通常是在图片或文本文件等上传时使用。
多部分对象集合包含的对象如下:
multipart/form-data
在Web表达文件上传是使用。
用于请求,上传。

代码示例
public class HttpTest {
@GetMapping("/simple/post")
public String testHttpPost() throws IOException {
// 创建HttpClient对象
CloseableHttpClient httpClient = HttpClients.createDefault();
try {
// 创建HttpPost对象
HttpPost httpPost = new HttpPost("http://127.0.0.1:5015/file/upload");
// 设置请求参数
MultipartEntityBuilder builder = MultipartEntityBuilder.create();
File file = new File("F:\\tmp\\test.txt");
// 添加文件
builder.setCharset(StandardCharsets.UTF_8).addBinaryBody("file", new FileInputStream(file),
ContentType.MULTIPART_FORM_DATA, file.getName());
// 添加文本
builder.addTextBody("isHttps", "true", ContentType.MULTIPART_FORM_DATA);
HttpEntity httpEntity = builder.build();
httpPost.setEntity(httpEntity);
httpPost.addHeader("bucket", "test");
// 发送请求
CloseableHttpResponse response = httpClient.execute(httpPost);
// 解析响应信息
if (response.getStatusLine().getStatusCode() == 200) {
HttpEntity responseEntity = response.getEntity();
log.info(EntityUtils.toString(responseEntity));
}
return "success";
} finally {
// 释放连接
try {
httpClient.close();
} catch (Exception e) {
log.error("test error", e);
}
}
}
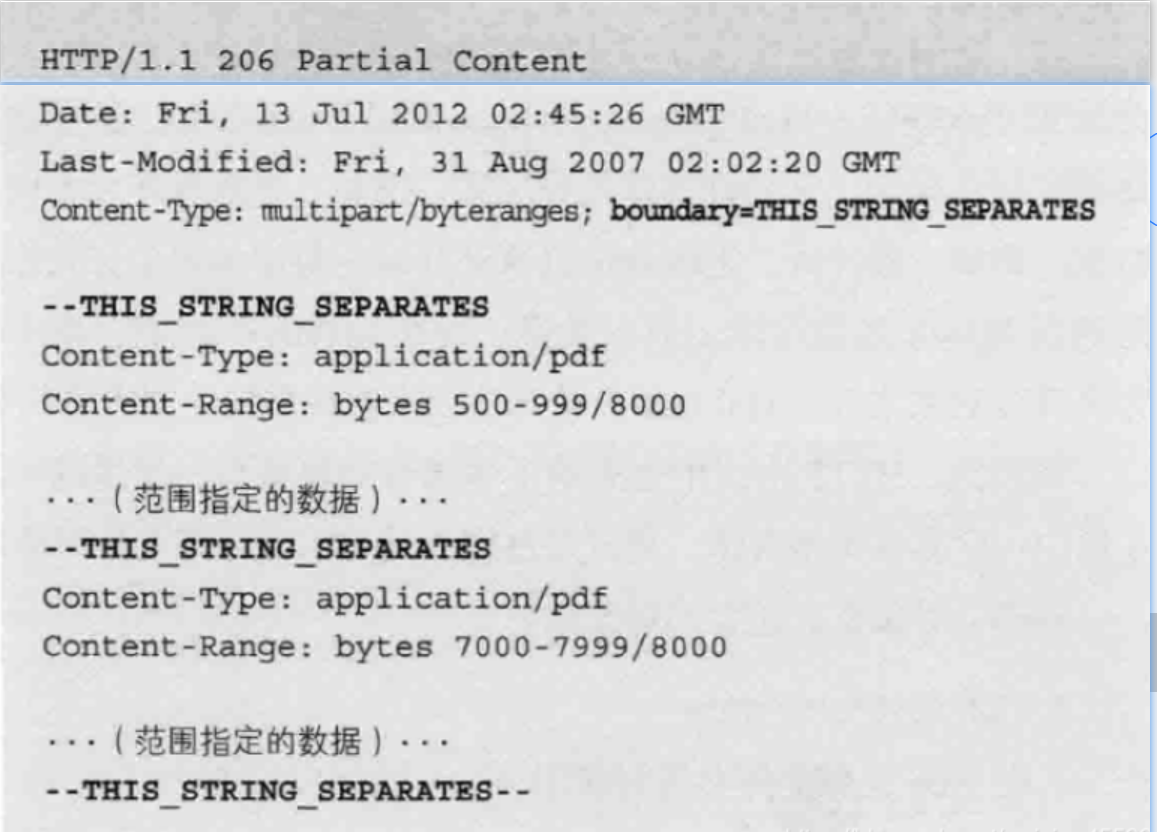
multipart/byteranges
状态码206(Partial Content,部分内容)响应报文包含了多个范围的内容时使用。
用于响应,下载。
代码示例
response.setStatus(HttpServletResponse.SC_PARTIAL_CONTENT);
response.setHeader(HttpHeaders.CONTENT_RANGE,
"bytes " + range.getFrom() + "-" + range.getTo() + "/" + fileSize);
- 在HTTP报文中使用多部分对象集合时,需要在首部字段里添加上Content-type。
- 使用boundary字符串来划分多部分对象集合指明的各类实体。在boundary字符串指定的各个实体的起始行之前加入“–”标记(例如:–AaB0x3x,–THIS_STRING_SEPARATES),而在多部分对象集合对应的字符串的最后插入“–”标记(例如:–AaB03x–、–THIS_STRING_SEPARATES–)作为结束。
- 多部分对象集合的每个部分类型中,都可以包含有首部字段。另外,可以在某个部分中嵌套使用多部分对象集合。
获取部分内容的范围请求
- 以前,用户不能使用现在这种高速的带宽访问互联网,当时,下一个尺寸稍大的图片或文件就已经很吃力了。如果下载过程中遇到网络中断的情况,那就必须重头开始。为了解决上述问题,需要一种可恢复的机制。所谓恢复是指能从之前中断处恢复下载。
- 要实现该功能需要指定下载的实体范围。像这样,指定范围发送的请求叫做范围请求(Range Request)。
- 对一份10 000字节大小的资源,如果使用范围请求,可以只请求50001~10000字节内的资源。
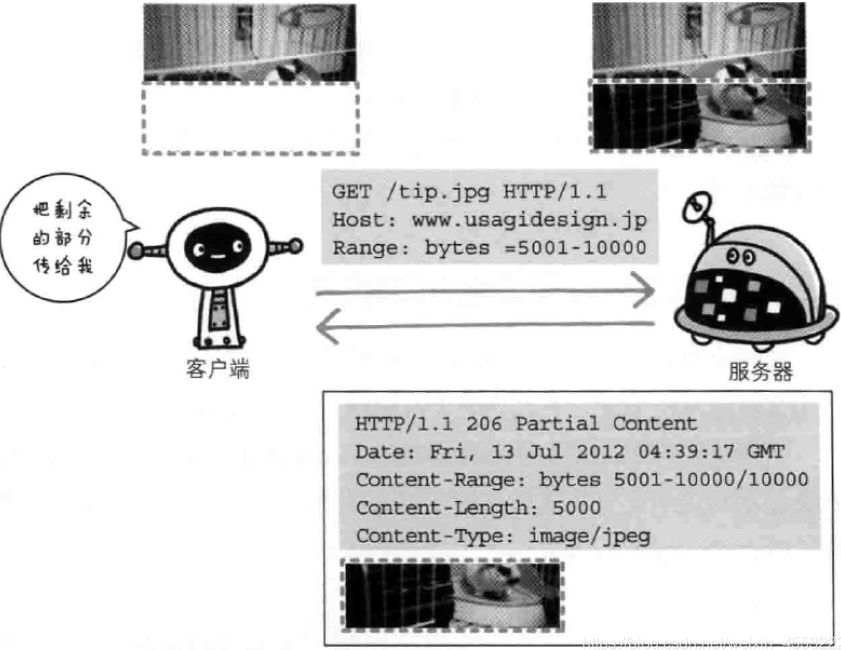
执行范围请求时,会用到首部字段Range来指定资源的byte范围。
byte范围的指定形式如下: - 5000~10000字节
// 具体的形式,还是得看后端是如何实现的,这个只是http对应的协议格式而已,具体实现看后端服务器的,前端传递后端支持的形式即可
Range: bytes=5001-10000
- 从5001字节之后全部的
Range: bytes=5001-
- 从一开始到3000字节和5000~7000字节的多重范围
Range: bytes=0-3000,5000-7000
针对范围请求,服务端的响应报文为:返回状态码206 Partial Content。
另外,对应多重范围的范围请求,响应会在首部字段Content-Type表明multipart/byteranges后返回响应报文。
- 如果服务端无法响应范围请求,则会返回状态码200 OK和完整的实体内容。
内容协商返回最合适的内容
- 大概思路是,后端服务器根据前端请求首部的相应字段返回给前端相应的响应报文。
- 同一个Web网站有可能存在着多份相同内容的页码。比如英文和中文版的Web页面,它们内容上虽相同,但使用的语言却不同。
- 当浏览器的默认语言为英文或中文,访问相同URI的Web页面时则会显示对应的英语版或中文版的Web页面。这样的机制称为内容协商(Content Negotiation)。
- 内容协商机制是指客户端和服务端就响应的资源内容进行交涉,然后提供给客户端最为适合的资源。内容协商会以语言、字符集、编码方式等为基准判断响应的资源。
- 包含在请求报文中的某些首部字段(如下)就是判断的基准。
- Accept
- Accept-Charset
- Accept-Encoding
- Accept-Language
- Content-Language
内容协商技术有以下3种类型:
服务器驱动协商(Server-driven Negotiation)
由服务端进行内容协商。以请求的首部字段为参考,在服务端自动处理。但对用户来说,以浏览器发送的信息作为判定的依据,并不一定能筛选出最优内容。
客户端驱动协商(Agent-driven Negotiation)
由客户端进行内容协商的方式。用户从浏览器显示的可选项列表中手动选择。还可以利用JavaScript脚本在Web页面上自动进行上述选择。比如按OS的类型或浏览器类型,自行切换成PC版页面或手机版页面。
透明协商(Transparent Negotiation)
是服务器驱动和客户端驱动的结合体,是由服务器端和客户端各自进行内容协商的一种方法。
参考
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/100258.html

