
什么是哈希
核心理论
Hash也称散列、哈希,对应的英文都是Hash。基本原理就是把任意长度的输入,通过Hash算法变成固定长度的输出。
这个映射的规则就是对应的Hash算法,而原始数据映射后的二进制串就是哈希值。
Hash的特点
- 从hash值不可以反向推导出原始的数据。
- 输入数据的微小变化会得到完全不同的hash值,相同的数据会得到相同的值。
- 哈希算法的执行效率要高效,长的文本也能快速地计算出哈希值。
- hash算法的冲突概率要小。
注意
由于hash的原理是将输入控件的值映射到Hash空间内,而hash值的空间远远小于输入的空间。(输入的值范围肯定是要大于hash输出值的范围的)
根据抽屉原理,一定会存在不同的输入被映射成相同输出的情况。
抽屉原理:桌上有10个苹果,要把10个苹果放入9个抽屉里,无论怎么放,我们会发现至少会有一个抽屉里面放不少于两个苹果。这一现象就是我们所说的“抽屉原理”。
HashMap原理讲解
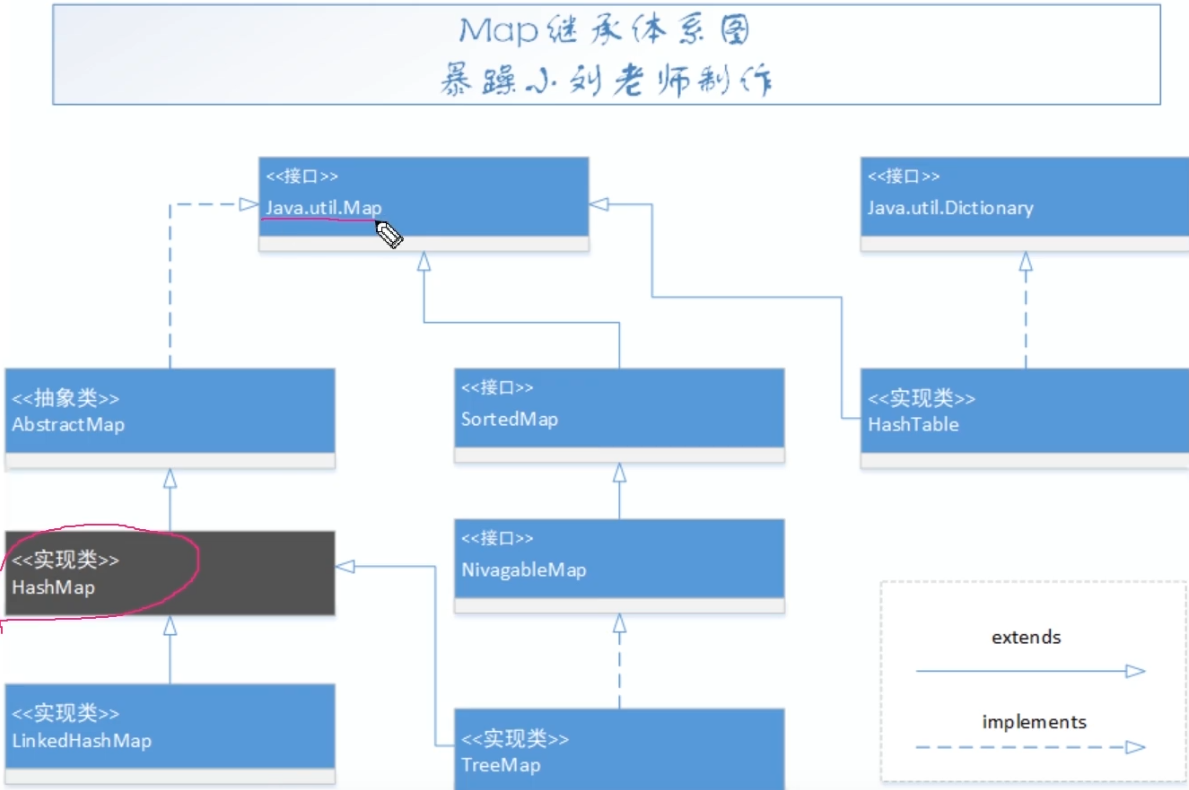
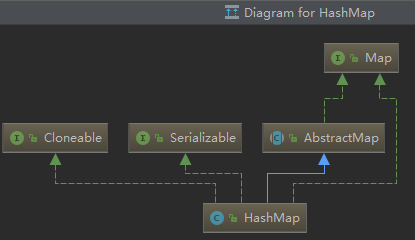
HashMap继承体系图
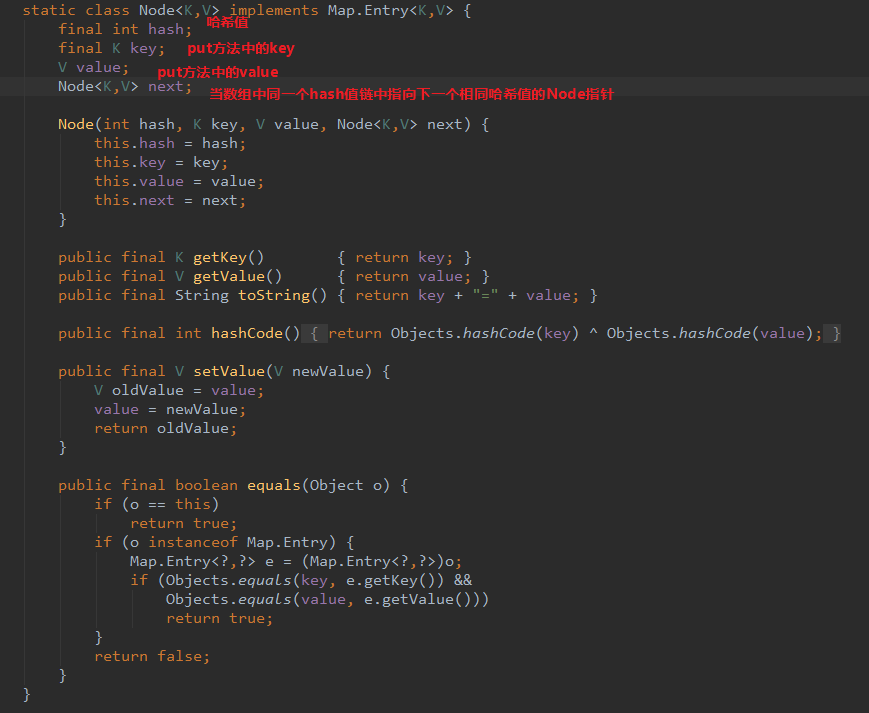
HashMap中Node节点
HashMap底层存储结构图
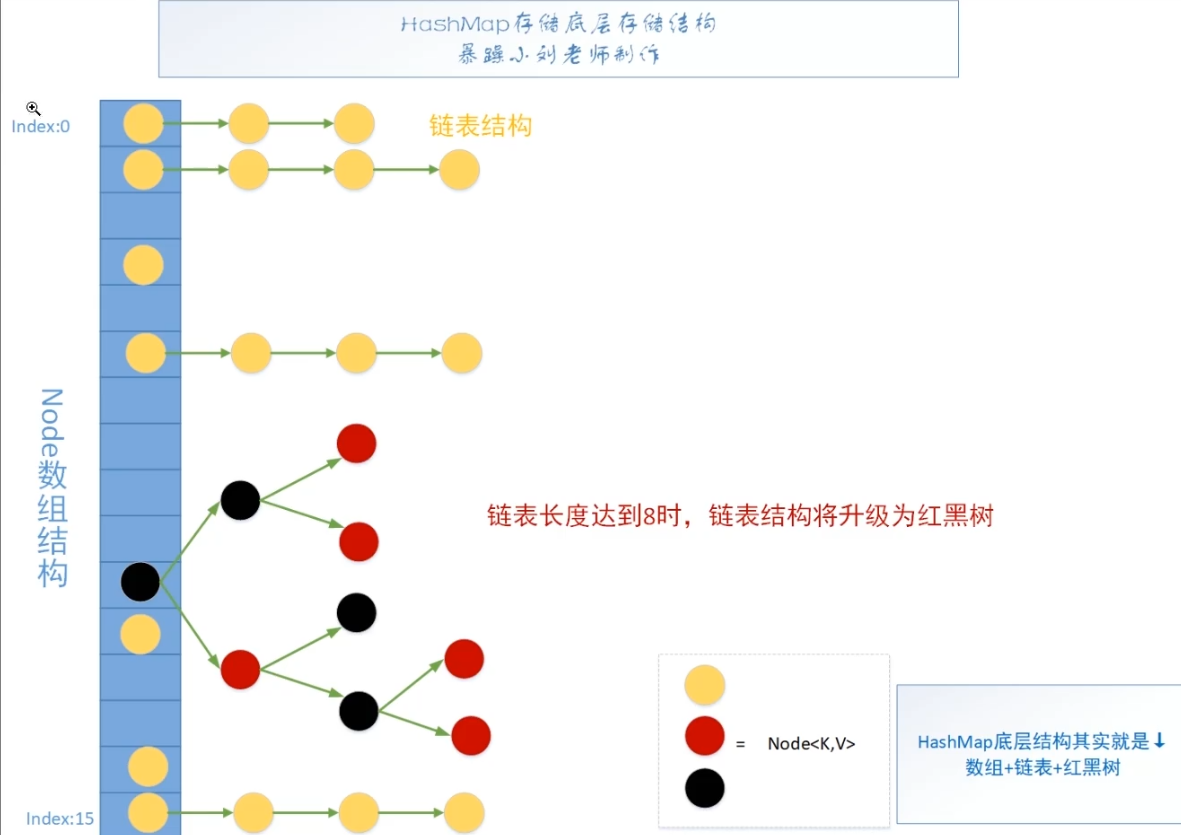
- Node就是我们平时操作的数据(K,V键值对数据)。
- 默认情况下数组长度为16。
- 当节点值发生hash冲突后,冲突的数据形成一个链表或者红黑树。
- 当链表长度达到8时(如加上数组中的元素是9),且整个hash存储结构中元素数达到64个时,链表结构将升级为红黑树。
put方法原理分析
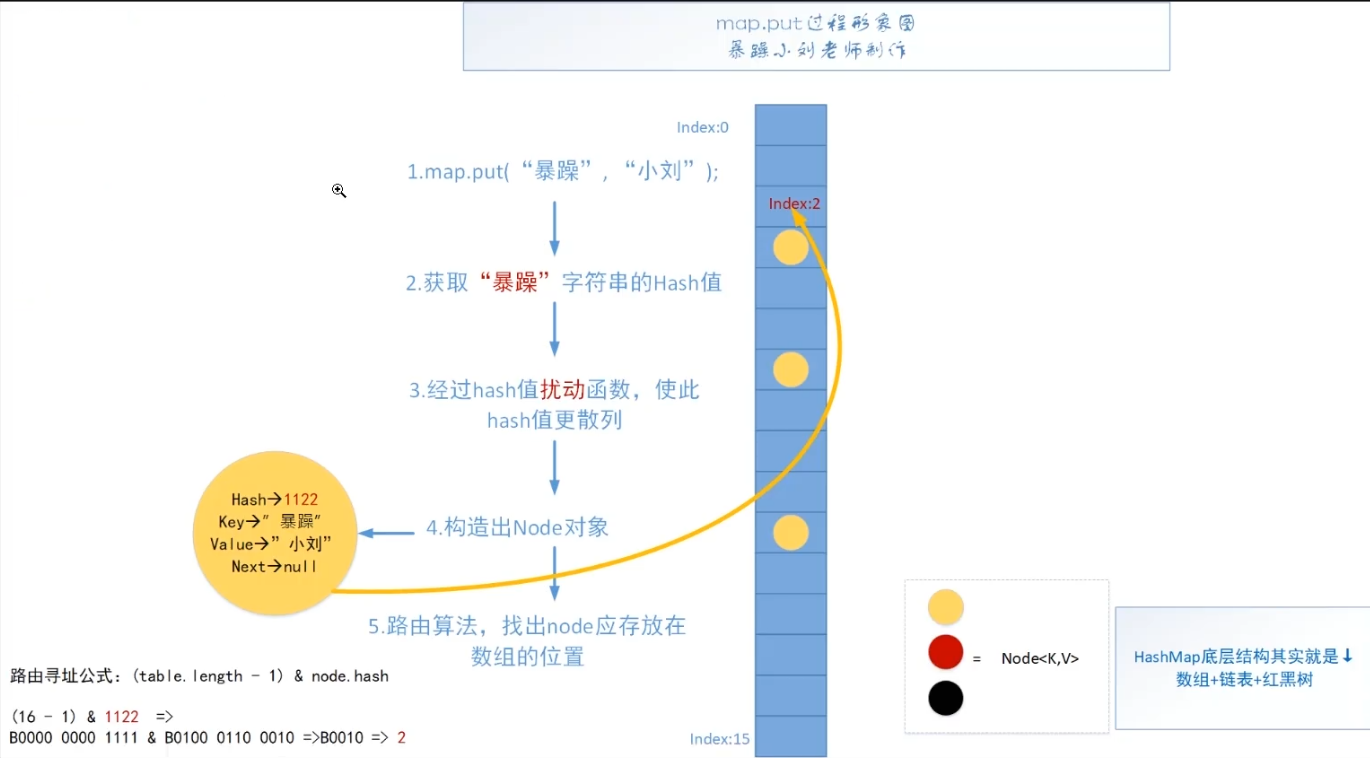
什么是hash碰撞
- 上图中插入的数据经过扰动函数算出的Hash值是1122,经过路由后存放在Index为2的数组下标中。
- 如果再次插入的数据,经过hash算出的值还是1122,那么理论上还是存放在index为2的数组下标中,因此index为2的数组就会存放哈希值为1122的链表的头节点(第一次hash值为1122的Node节点),头节点的next指向存放的数据地址。
- 如果hash值为1122的数据很多,那么碰撞的结果就会是index2的位置的链表会很长,导致寻找数据复杂度变高,效率降低。
- 查找数据的过程,map.get(key)的过程,和put方法的前3步一样,先获取key的hash扰动值,然后根据路由算法路由到数组的index值,如果该位置是链表数据,遍历链表节点直到找到节点中与Key相同的节点,如果链表较长寻找效率就会变低,所以需要红黑树结构(JDK8引人红黑色结构)。
HashMap为什么要扩容
- 当链表太长后,会导致查找效率太差,hashMap可能替换成链表线性查找。
- 扩容就是扩大数据的长度(数组的长度必须是2的n次方),数组中存储的位置更多了,以空间换时间,提高查询效率。
- 当数组扩大后,链表的长度就会减少,查找效率自然就会变得高效。
HashMap源码分析
总结
- HashMap刚创建时,table是null(table是存放Hash数据的地方,Node<K,V>[] table),为了节省空间,当添加第一个元素时,table容量调整为16(如果创建的时候没有指定大小)。
- 当元素个数大于阈值(16*0.75=12)时,会进行扩容,扩容后大小是原有大小的两倍,如果16变成32;目的是增加数组长度,减少hash冲突,减少调整元素的个数,提高效率。
- jdk1.8 当一个链表大于8,并且整个数据结构元素超过64时,会把大于8的那个链表调整为红黑树,目的是为了提高查找、插入效率。
- jdk1.8 当某个红黑树元个数小于6时,调整为链表。
- jdk1.8 以前,链表是头插入,就是新插入的数据放在数组中,jdk1.8以后改成尾插法,元素放入最后。
- HashSet底层数据的存储结构就是HashMap,使用了适配器模式,把Map转成了Set而已。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/100424.html

