
🙋作者:爱编程的小贤
⛳知识点:python爬虫—url传参
🥇:每天学一点,早日成大佬
文章目录
👊前言
💎 💎 💎今天为大家介绍爬虫的url传参啦!!! 这是爬虫的第三讲咯!!!🚀 🚀 🚀
如果你看完感觉对你有帮助,,,欢迎给个三连哦💗!!!您的支持是我创作的动力。🌹 🌹 🌹 🌹 🌹 🌹 感谢感谢!!!😘😘😘
🏆一、URL传参
1.图片显示
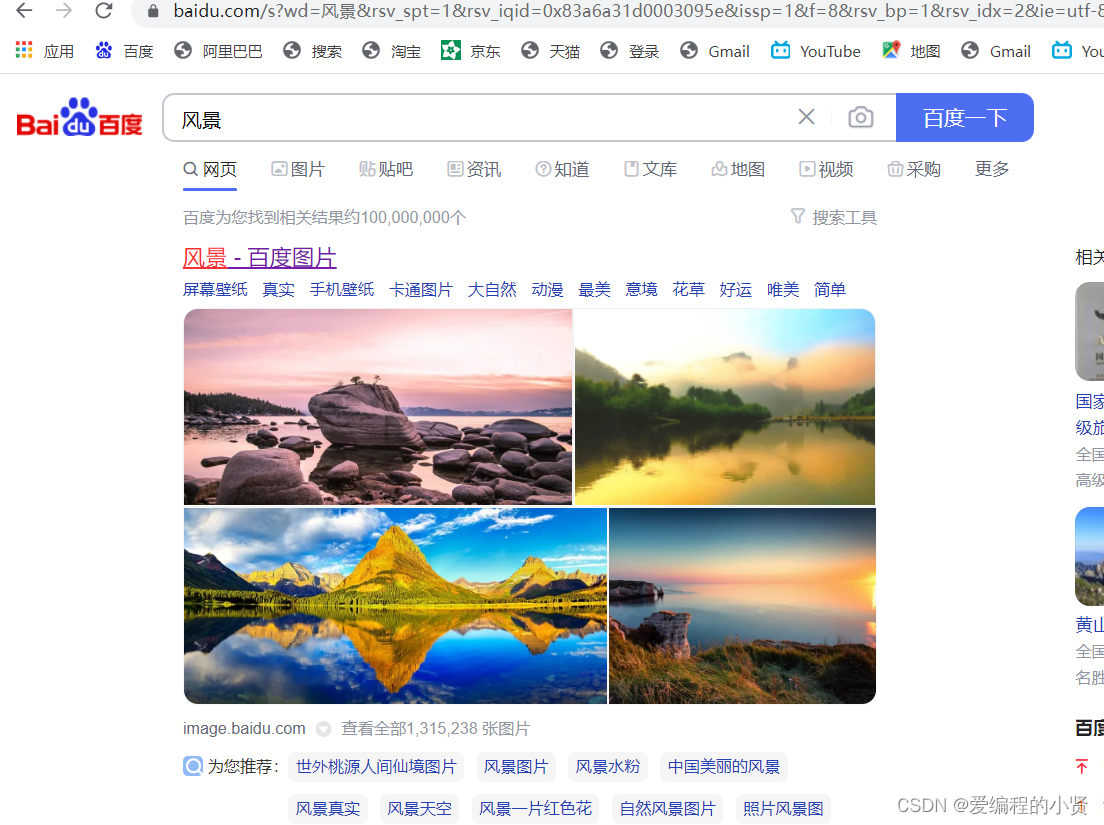
首先分析一下网页上的图片是如何存储进行显示的呢 ?
根据network里面的数据包的分析,图片都是一个单独的数据包,单独发送
HTML骨架
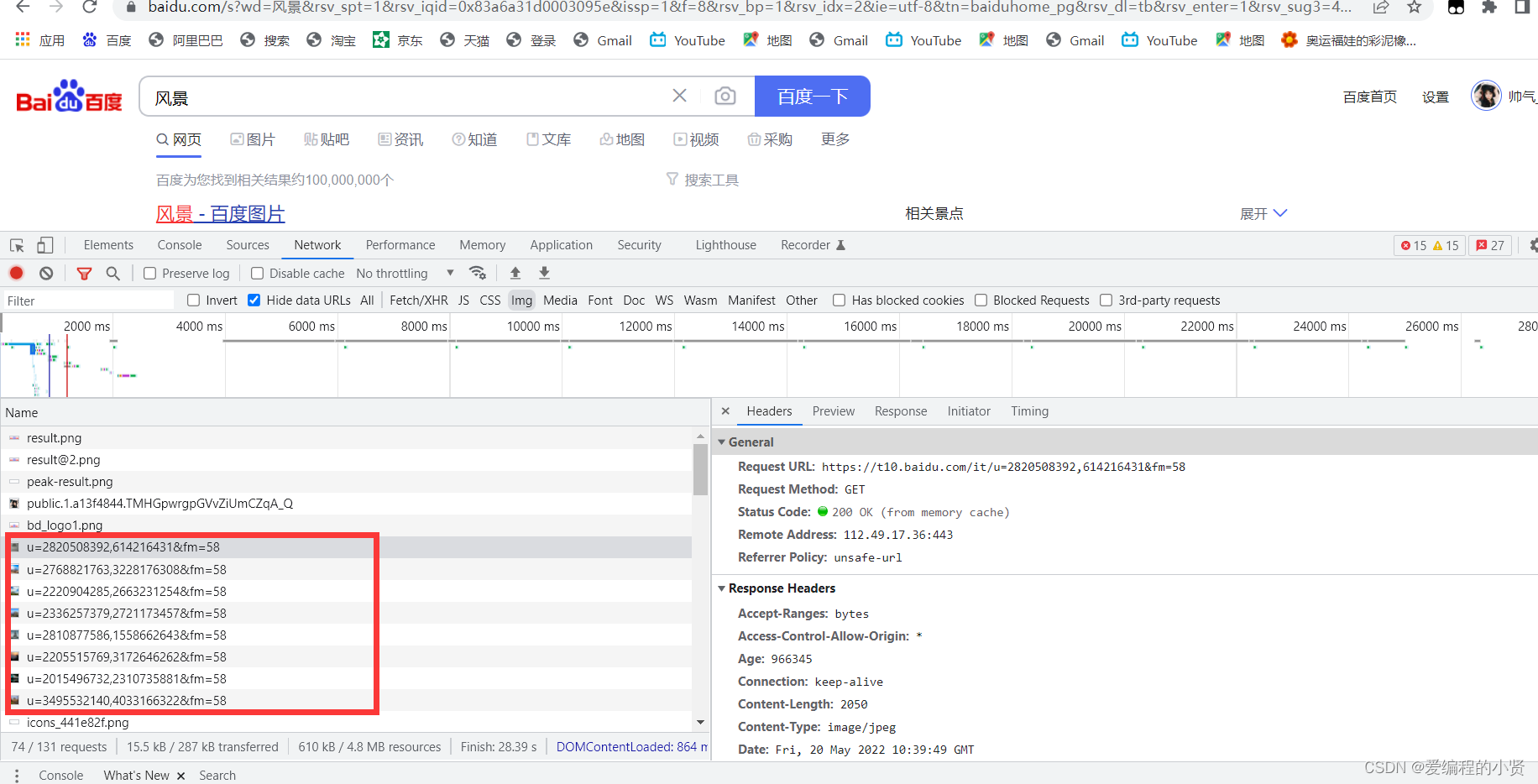
我们在网址栏输入的url,一般情况下都是网页主框架的url,当浏览器拿到了该主框架的url的响应response以及接受到了这个html文件的代码之后就会呈现出来,同时图片也是url,浏览器会拿着这个url去请求这个图片,在拿到具体的响应之后就将图片显示出来,最终组成了一个完整的 页面给我们查看。
2.url路径分析

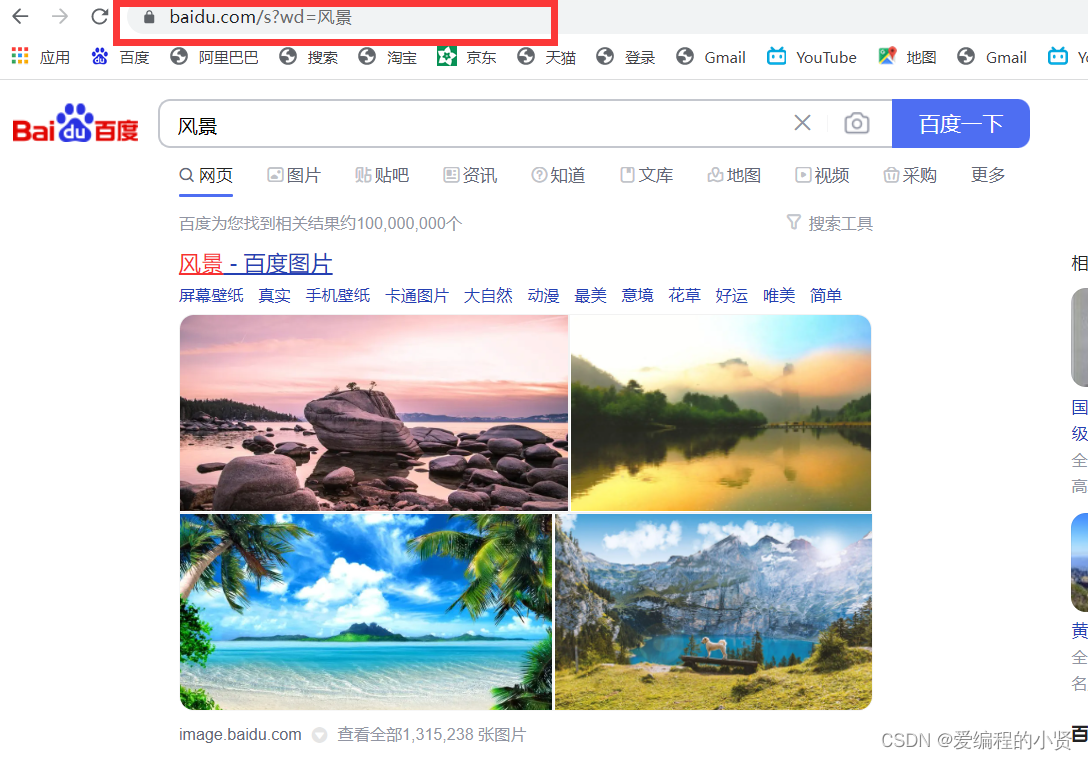
从上方我们可以看到,当我们将url路径中的参数删除掉一些只剩下wd参数之后仍然可以得到服务器给我们的响应,那么也就是说,url中并不是所有的参数都是有效参数。
大家可以测试一下参数完整时和参数不完整时的情况。 其实,经过分析的话能得出的结果那就是只要关键参数wd存在那么就会返回正确的响应,并且响 应的数据是一样的,也就是说在当前的这个URL中,只有wd这个参数是关键的。
综上,我们就知道了在url中并不是所有参数都是有效参数,例如百度搜索的url地址,其中只有一个wd参数是有用的,而其他的参数都是可以删除的,那么如何确定那些请求参数有用或者没用呢?
最简单的方法:一个一个的尝试。对应的,在后续的爬虫学习过程中,遇到很多参数的url地址,都可以尝试删除 参数。
总结:参数是以键值对的形式存在的。
3. request URL
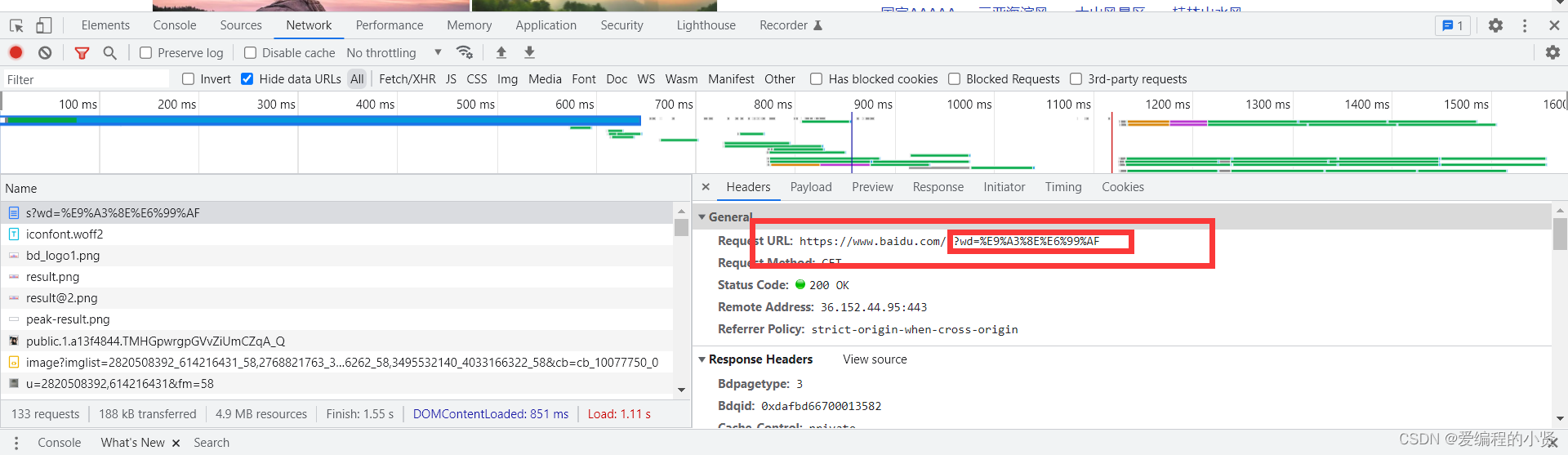
通过对url的观察发现,中文的传参并不是那么的友好,中文经过浏览器的解析之后发送给服务器。
风景=%E9%A3%8E%E6%99%AF
https://www.baidu.com/s?wd=%E9%A3%8E%E6%99%AF
将url放在浏览器访问,会发现转义部分进行直接请求也是可以的
4.url转义
quote():将明文转为密文
unquote():将密文转为明文
# 类似的url的转义 了解即可 知道有这个东西就可以了
from urllib.parse import quote,unquote
# 明文(看得懂的数据): 风景 固定的关系映射表(固定的格式)
# 密文(看不懂的) 加密的场景....
# 明文转密文
data_ = '风景'
print(quote(data_))
# %E7%BE%8E%E5%A5%B3
# 密文转为明文
print(unquote('%E9%A3%8E%E6%99%AF'))
# 风景
下载本页面
import requests
# 1. 确定目标url
url = "https://www.baidu.com/s?wd=%E9%A3%8E%E6%99%AF"
# 1.1 使用用户代理
header_ = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36", }
# 2.发送请求,获取响应对象
response = requests.get(url, headers=header_)
# 获取字节类型数据
bytes_data = response.content
# 解码 进行字节转换为字符串
str_data = bytes_data.decode()
# 3.保存到本地
with open('baidu_风景.html', 'w', encoding='utf-8') as f:
f.write(str_data)
不带cookie,出现了百度安全验证,被识别出来了是一个爬虫
import requests
# 1. 确定目标url
url = "https://www.baidu.com/s?wd=%E9%A3%8E%E6%99%AF"
# 1.1 使用用户代理
header_ = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36",
# Cookie:前后端的会话记录
"Cookie": "BAIDUID=48348A43C350B83863CB8463819C68D5:FG=1; PSTM=1626964492; BIDUPSID=AD35169F5464900C8C61323FD91243A1; BD_UPN=12314753; BDORZ=FFFB88E999055A3F8A630C64834BD6D0"
}
# 2.发送请求,获取响应对象
response = requests.get(url, headers=header_)
# 获取字节类型数据
bytes_data = response.content
# 解码 进行字节转换为字符串
str_data = bytes_data.decode()
# 3.保存到本地
with open('baidu_风景.html', 'w', encoding='utf-8') as f:
f.write(str_data)
对比搜索框和wd,我们发现搜索框是什么值,wd后面就是什么值
那么,我们是否可以通过改变wd的值来修改搜索框的值来进行一个动态的下载,那么百度里面在搜索框输入,我们的代码输入在哪里呢,是不是就可以在控制台输入也就是input。
🏆二、发送带参数的请求
我们在使用百度搜索的时候经常发现url地址中会有一个 ? ,那么该问号后面的就是请求参数,又叫做查询字符串或查询参数。
1.什么叫做请求参数
例1:http://www.webkaka.com/tutorial/server/2015/021013/
例2:https://www.baidu.com/s?wd=python&a=c
例1中没有请求参数!例2中?后边的就是请求参数
2.请求参数的形式:字典
kw = {‘wd’:‘风景’}
3.请求参数的用法
requests.get(url,params=kw)
4.两种方式:发送带参数的请求
- 对 https://www.baidu.com/s?wd=python 发起请求可以使用 requests.get(url, params=kw) 的方式
模拟浏览器上搜索
1.浏览器上面是输入要搜索的内容,那么我们现在用代码模拟在哪输入呢 input
2.确定目标的url
3.发送网络请求
4.保存数据
""" url传参第一种, 发送请求的时候再进行传参携带, 而不是直接放在url里面 """
import requests
# 程序入口
if __name__ == '__main__':
# 手动输入获取关键字
input_wd = input("请输入你想搜索的关键字:")
# 1.确认目标的url
url = 'https://www.baidu.com/s?'
# 1.1 使用用户代理 Cookie:前后端的会话记录
header_ = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36",
"cookie": "BAIDUID=48348A43C350B83863CB8463819C68D5:FG=1; PSTM=1626964492; BIDUPSID=AD35169F5464900C8C61323FD91243A1; BD_UPN=12314753; BDORZ=FFFB88E999055A3F8A630C64834BD6D0"
}
# 设置字典,用来url携带参数
params = {
'wd': input_wd
}
# 2.发送网络请求,获取响应对象 指定参数params
response = requests.get(url, headers=headers, params=params)
bytes_data = response.content
str_data = bytes_data.decode()
# 3.保存到本地
with open(f'baidu_{input_wd}.html', 'w', encoding='utf-8') as f:
f.write(str_data)
- 也可以直接对 https://www.baidu.com/s?wd={变量} 完整的url直接发送请求,不使用params参 数
import requests
""" url 传参 爬虫演示 第二种 携带参数直接放在url里面 """
# 程序入口
if __name__ == '__main__':
# 手动输入获取关键字
input_wd = input("请输入你想搜索的关键字:")
# 1.确认目标的url
url = f"https://www.baidu.com/s?&wd={input_wd}"
# 1.1 添加用户代理User-Agent伪造身份
header_ = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36",
}
# 2.发送网络请求,获取响应对象
response = requests.get(url, headers=headers)
# 2.1 提取出里面的文本数据
bytes_data = response.content
str_data = bytes_data.decode() # 设置的是默认的utf-8
# 3.保存到本地
with open(f'baidu_{input_wd}.html', 'w', encoding='utf-8') as f:
f.write(str_data)
🏆三、案例
1.网易云单张图片下载
2.网易云非VIP歌曲下载
3.网易云单首MV下载
4.QQ音乐抽离音频
5.附录
ffmpeg下载地址:http://www.ffmpeg.org/download.html
ffmpeg -i 被抽离的文件.mp4-vn -y -acodec copy
抽离后的文件.m4a -loglevel quiet
回顾:
requests模块
– 发起get请求- 通过requests.get()
– 发起post请求 – 通过requests.post()
headers:可以用于伪装爬虫,添加浏览器信息->User-Agent注意首字母要大写
proxy->代理IP的使用
timeout->请求时长,如果超出了请求时长,则返回请求失败的错误信息response:text->获取文本数据 content:获取字节类型的数据,二进制数据 status_code:获取服务器返回的状态码 cookies:获取服务器为我们设置的cookie信息 json:获取服务器返回的json类型的数据网易云案例需求:
爬取华语、欧美、民谣三个类别的歌单
新的请求抓到的包一般情况会出现在抓包工具栏的最下方
# https://music.163.com/discover/playlist/?cat=%E6%B0%91%E8%B0%A3
# https://music.163.com/#/discover/playlist/?cat=%s
🏆总结
案例有需要的可以私我获取哦 🥰🥰🥰本文到这里就结束啦👍👍👍,如果有帮到你欢迎给个三连支持一下哦❤️ ❤️ ❤️
文章中有哪些不足需要修改的地方欢迎指正啦!!!让我们一起加油👏👏👏
⭕⭕⭕最最最后还是要提示一下啦!!!!!🔺🔺🔺
提示:做爬虫一定要**注意**如果涉及到私人信息或者公司单位的机密信息就不要去碰,爬虫开发过程中意外拿到了用户私人信息或者公司机密,千万不要交易!!!!掌握好爬虫的度就没有任何问题!!!!!!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/100726.html

