
目录
CPU与GPU的区别
CPU被Cache(高速缓冲存储器)占据了大量空间,还有复杂的控制逻辑和优化电路。
-
GPU采用了数量众多的计算单元和超长的流水线,只有非常简单的控制逻辑。
GPU软件结构
- 内核(kernel):可以理解为C/C++中的一个函数function。
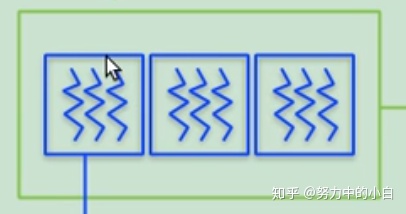
- 网格(grid):对应一个kernel,由若干个线程块组成,如图所示的绿色框。
- 线程块(block):由若干条线程组成,如图所示的蓝色框。
- 线程(thread)

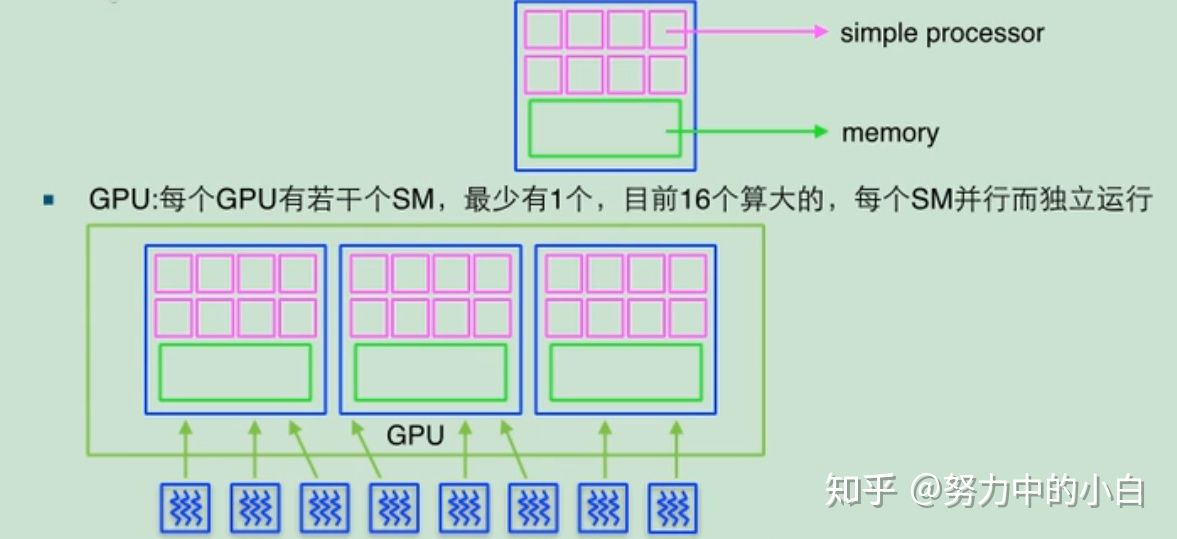
GPU硬件结构
流处理器(SM:stream multiprocessor):相当于CPU的一个核
CUDA编程模型的保证性原则
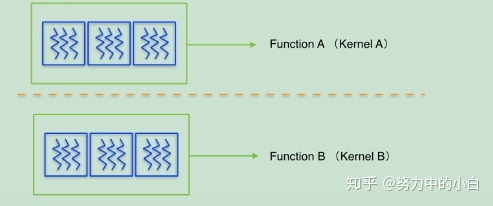
- 所有在同一个线程块上的线程必然会在同一时间运行在同一个SM上
- 同一个内核的所有线程块必然会全部完成了后,才会运行下一个内核
操作流程
Cuda是Nvidia发布的并行计算框架,GPU的工作早已不局限于处理图形图像,它所包含的大量的计算单元用来执行那些计算量大但可以并行处理的任务。
Cuda的操作概括来说包含5个步骤:
1.CPU在GPU上分配内存:cudaMalloc;
2.CPU把数据发送到GPU:cudaMemcpy;
3.CPU在GPU上启动内核(kernel),它是自己写的一段程序,在每个线程上运行;
4.CPU把数据从GPU取回:cudaMemcpy;
5.CPU释放GPU上的内存。
其中关键是第3步,能否写出合适的kernel,决定了能否正确解决问题和能否高效的解决问题。
基本概念
Cuda对线程做了合适的规划,引入了grid和block的概念,block由线程组成,grid由block组成,一般说blocksize指一个block放了多少thread;gridsize指一个grid放了多少个block。
一个kernel结构如下:Kernel<<<Dg, Db, Ns, S>>>(param1, param2, …)
-Dg:grid的尺寸,grid_size ;
-Db:block的尺寸,block_size;
-Ns:可选参数,如果kernel中有动态分配内存的shared memory,需要在此指定大小,以字节为单位;
-S:可选参数,表示该kernel处在哪个流当中。
如何选取grid_size和block_size
grid_size 和 block_size 分别代表了本次 kernel 启动对应的 block 数量和每个 block 中 thread 的数量,所以显然两者都要大于 0。
Guide 中 K.1. Features and Technical Specifications ( https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#features-and-technical-specifications )指出, Maximum number of threads per block 以及 Maximum x- or y-dimension of a block 都是 1024,所以 block_size 最大可以取 1024。
同一个 block 中,连续的 32 个线程组成一个 warp,这 32 个线程每次执行同一条指令,也就是所谓的 SIMT,即使最后一个 warp 中有效的线程数量不足 32,也要使用相同的硬件资源,所以 block_size 最好是 32 的整数倍。
与 block 对应的硬件级别为 SM,SM 为同一个 block 中的线程提供通信和同步等所需的硬件资源,跨 SM 不支持对应的通信,所以一个 block 中的所有线程都是执行在同一个 SM 上的,而且因为线程之间可能同步,所以一旦 block 开始在 SM 上执行,block 中的所有线程同时在同一个 SM 中执行(并发,不是并行),也就是说 block 调度到 SM 的过程是原子的。SM 允许多于一个 block 在其上并发执行,如果一个 SM 空闲的资源满足一个 block 的执行,那么这个 block 就可以被立即调度到该 SM 上执行,具体的硬件资源一般包括寄存器、shared memory、以及各种调度相关的资源。
这里的调度相关的资源一般会表现为两个具体的限制, Maximum number of resident blocks per SM 和 Maximum number of resident threads per SM ,也就是 SM 上最大同时执行的 block 数量和线程数量。因为 GPU 的特点是高吞吐高延迟,就像一个自动扶梯一分钟可以运送六十个人到另一层楼,但是一个人一秒钟无法通过自动扶梯到另一层楼,要达到自动扶梯可以运送足够多的人的目标,就要保证扶梯上同一时间有足够多的人,对应到 GPU,就是要尽量保证同一时间流水线上有足够多的指令。
要到达这个目的有多种方法,其中一个最简单的方法是让尽量多的线程同时在 SM 上执行,SM 上并发执行的线程数和SM 上最大支持的线程数的比值,被称为 Occupancy,更高的 Occupancy 代表潜在更高的性能。
显然,一个 kernel 的 block_size 应大于 SM 上最大线程数和最大 block 数量的比值,否则就无法达到 100% 的 Occupancy,对应不同的架构,这个比值不相同,对于 V100 、 A100、 GTX 1080 Ti 是 2048 / 32 = 64,对于 RTX 3090 是 1536 / 16 = 96,所以为了适配主流架构,如果静态设置 block_size 不应小于 96。考虑到 block 调度的原子性,那么 block_size 应为 SM 最大线程数的约数,否则也无法达到 100% 的 Occupancy,主流架构的 GPU 的 SM 最大线程数的公约是 512,96 以上的约数还包括 128 和 256,也就是到目前为止,block_size 的可选值仅剩下 128 / 256 / 512 三个值。
还是因为 block 调度到 SM 是原子性的,所以 SM 必须满足至少一个 block 运行所需的资源,资源包括 shared memory 和寄存器, shared memory 一般都是开发者显式控制的,而如果 block 中线程的数量 * 每个线程所需的寄存器数量大于 SM 支持的每 block 寄存器最大数量,kernel 就会启动失败。
目前主流架构上,SM 支持的每 block 寄存器最大数量为 32K 或 64K 个 32bit 寄存器,每个线程最大可使用 255 个 32bit 寄存器,编译器也不会为线程分配更多的寄存器,所以从寄存器的角度来说,每个 SM 至少可以支持 128 或者 256 个线程,block_size 为 128 可以杜绝因寄存器数量导致的启动失败,但是很少的 kernel 可以用到这么多的寄存器,同时 SM 上只同时执行 128 或者 256 个线程,也可能会有潜在的性能问题。但把 block_size 设置为 128,相对于 256 和 512 也没有什么损失,128 作为 block_size 的一个通用值是非常合适的。
确定了 block_size 之后便可以进一步确定 grid_size,也就是确定总的线程数量,对于一般的 elementwise kernel 来说,总的线程数量应不大于总的 element 数量,也就是一个线程至少处理一个 element,同时 grid_size 也有上限,为 Maximum x-dimension of a grid of thread blocks ,目前在主流架构上都是 2^31 – 1,对于很多情况都是足够大的值。
我们可以想象,GPU 一次可以调度 SM 数量 * 每个 SM 最大 block 数个 block,因为每个 block 的计算量相等,所以所有 SM 应几乎同时完成这些 block 的计算,然后处理下一批,这其中的每一批被称之为一个 wave。想象如果 grid_size 恰好比一个 wave 多出一个 block,因为 stream 上的下个 kernel 要等这个 kernel 完全执行完成后才能开始执行,所以第一个 wave 完成后,GPU 上将只有一个 block 在执行,GPU 的实际利用率会很低,这种情况被称之为 tail effect。
我们应尽量避免这种情况,将 grid_size 设置为精确的一个 wave 可能也无法避免 tail effect,因为 GPU 可能不是被当前 stream 独占的,常见的如 NCCL 执行时会占用一些 SM。所以无特殊情况,可以将 grid_size 设置为数量足够多的整数个 wave,往往会取得比较理想的结果,如果数量足够多,不是整数个 wave 往往影响也不大.
综上所述,普通的 elementwise kernel 或者近似的情形中,block_size 设置为 128,grid_size 设置为可以满足足够多的 wave 就可以得到一个比较好的结果了。但更复杂的情况还要具体问题具体分析,比如,如果因为 shared_memory 的限制导致一个 SM 只能同时执行很少的 block,那么增加 block_size 有机会提高性能,如果 kernel 中有线程间同步,那么过大的 block_size 会导致实际的 SM 利用率降低,这些我们有机会单独讨论。
如何知道自己显卡的属性
通过以下代码可以从prop中查看显卡属性。
cudaDeviceProp prop;
CUDA_SAFE_CALL(cudaGetDeviceProperties(&prop,0));maxThreadsPerBlock-每个block的最大线程数;
maxGridSize-最大block数;
multiProcessorCount-流处理器SM数;
常用函数
Event
CUDA中Event用于在流的执行中添加标记点,用于检查正在执行的流是否到达给定点。
作用一,Event可用于等待和测试时间插入点前的操作,作用和streamSynchronize类似。
作用二,Event可插入不同的流中,用于流之间的操作。不同流执行是并行的,特殊情况下,需要同步操作。同样,也可以在主机端操控设备端执行情况。
作用三,可以用于统计时间,在需要测量的函数前后插入Event。调用cudaEventElapseTime()查看时间间隔;
// create two events
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
// record start event on the default stream
cudaEventRecord(start);
// execute kernel
kernel<<<grid, block>>>(arguments);
// record stop event on the default stream
cudaEventRecord(stop);
// wait until the stop event completes
cudaEventSynchronize(stop);
// calculate the elapsed time between two events
float time;
cudaEventElapsedTime(&time, start, stop);
// clean up the two events
cudaEventDestroy(start);
cudaEventDestroy(stop);Stream流
一个流对应并发的概念,是一组顺序执行的操作(可能由多个主机线程发出);
多个流对应并行的概念,因为发生顺序具有不确定性。
基本函数
cudaStream_t stream//定义流
cudaStreamCreate(cudaStream_t * s)//创建流
cudaStreamDestroy(cudaStream_t s)//销毁流
显性同步
cudaStreamSynchronize()//同步单个流:等待该流上的命令都完成
cudaDeviceSynchronize()//同步所有流同步:等待整个设备上流都完成
cudaStreamWaitEvent()//通过某个事件:等待某个事件结束后执行该流上的命令
cudaStreamQuery()//查询一个流任务是否完成
回调
cudaStreamAddCallback()//在任何点插入回调函数
优先级
cudaStreamCreateWithPriority()
cudaDeviceGetStreamPriorityRange()
//创建两个流
cudaStream_t stream[2];
for (int i = 0; i < 2; ++i)
cudaStreamCreate(&stream[i]);
float* hostPtr;
cudaMallocHost(&hostPtr, 2 * size);
...
//两个流,每个流有三个命令
for (int i = 0; i < 2; ++i) {
//从主机内存复制数据到设备内存
cudaMemcpyAsync(inputDevPtr + i * size, hostPtr + i * size, size, cudaMemcpyHostToDevice, stream[i]);
//执行Kernel处理谁被内存
MyKernel <<<100, 512, 0, stream[i]>>>(outputDevPtr + i * size, inputDevPtr + i * size, size);
//从设备内存到主机内存
cudaMemcpyAsync(hostPtr + i * size, outputDevPtr + i * size, size, cudaMemcpyDeviceToHost, stream[i]);
}
...
//销毁流
for (int i = 0; i < 2; ++i)
cudaStreamDestroy(stream[i]);内存分配以及数据传输
在device上分配内存
分配size字节的存储器,并将其首地址赋给devPtr
cudaError_t cudaMalloc(void** devPtr, size_t size);host和device之间数据通信
cudaError_t cudaMemcpy(void* dst, const void* src, size_t count, cudaMemcpyKind kind) 其中src指向数据源,而dst是目标区域,count是复制的字节数,其中kind控制复制的方向:cudaMemcpyHostToHost, cudaMemcpyHostToDevice, cudaMemcpyDeviceToHost及cudaMemcpyDeviceToDevice,如cudaMemcpyHostToDevice将host上数据拷贝到device上。
参考资料
CUDA基础(1):操作流程与kernel概念 – hankeyyh – 博客园 (cnblogs.com)
CUDA-cudaEvent记录事件_武泗海的博客-CSDN博客_cuda event
(Cuda)流Stream(三)_沤江一流的专栏-CSDN博客_cuda默认流
如何设置CUDA Kernel中的grid_size和block_size?-低调大师优秀的个人博客 (xujun.org)
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/100795.html

