
集合类
重点:
常见的集合类(List集合、Set集合、Map集合)
各种集合的特点,重点掌握集合的遍历、添加对象、删除对象的方法
要求:
会使用集合类
集合类是干什么的?
集合类是一种容器,类似于数组,但又与数组不同。
不同体现在:
数组的长度是固定的,集合类的长度是可变的。
数组中主要存放的是基本类型的数据,也可以存放对象引用;集合类只能存放的是对象引用(如果使用基本数据类型,那么需要使用对应的包装类)。
数组中的数据类型必须是相同的,集合不需要一定相同。
注意:集合类由接口实现,接口所在的包是java.util
集合的分类?
集合可以分为List集合、Map集合、Set集合。
为什么又这么多不同类型的集合?
集合可以存储多个元素,但是我们对于元素的需求不一定相同,所以出现了很多类型的集合。有如下几种不同的需求,
多个元素,元素不可以相同(Set集合中不允许有相同的元素)
多个元素,元素按照一定的顺序排列(Set集合和Map集合的实现类TreeXxx排列是有顺序的)
多个元素,增加、删除速度需求(Set集合和Map集合的实现类HashXxx的增加、删除速度快,根本的原因在于底层数据结构不同)
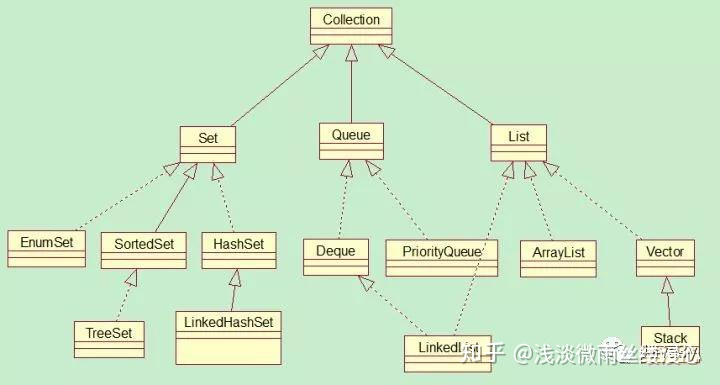
集合类的继承关系?
Collection接口是继承结构中的顶级接口;
Collection接口是Set接口、List接口、Queue接口的父接口,我们常用到的是Set接口和List接口;
Map接口不继承Collection接口;
Collection接口
-
什么是Collection接口?
Collection接口是层次结构中的根接口。 -
有关Collection接口的概念?
元素:构成Collection的单位称为元素。 -
Collection接口的特点?
Collection接口是不可以直接使用的,但是Collection接口提供了以下几种功能:
添加功能(add(Object o)、addAll(Collection c))
删除功能(remove(Object o)、removeAll(Collection c)、clear())
判断功能(contains(Object o)、containsAll(Collection c)、isEmpty())
获取功能(iterator())
长度功能(size())
交集功能(retainAll(Collection c))
因为List接口和Set接口都是继承了Collection接口,所以可以使用Collection接口的功能。具体的方法如下:
方法返回值功能描述add(Object o)boolean添加一个元素到指定的集合中addAll(Collection c)boolean添加一个集合的元素到指定的集合中remove(Object o)boolean将指定的元素从指定集合中移除removeAll(Collection c)boolean移除一个集合中的元素,只要一个元素被移除了,那么返回true,相当于clear()clear()void移除集合中所有元素contains(Object o)boolean判断集合是否包含该元素,满足条件返回true,否则返回falsecontainsAll(Collection c)boolean判断集合中是否包含指定集合中的所有元素,满足条件返回true,否则返回falseisEmpty()boolean判断当前集合是否为空,为空返回true,否则返回falseiterator()Iterator返回在此Collection的元素上进行迭代的迭代器,用于遍历集合中的对象方法返回值功能描述size()int获取该集合中元素的个数,返回int型值retainAll(Collection c)boolean求两个集合的交集,返回值表示调用方法的集合是否发生变化,如果发生变化返回true,否则返回false
为什么Collection中有Iterator()方法?
因为Collection继承了Iterator。
为什么遍历集合时候需要使用iterator()方法,创建集合迭代器
回答:类似于数组,数组需要下标索引才能遍历,创建集合迭代器的作用就是获得集合的索引,用于集合的遍历。
什么是迭代器,有什么作用?
迭代器(Iterator)模式,又叫做游标模式,它的含义是,提供一种方法访问一个容器对象中各个元素,而又不需暴露该对象的内部细节,用于集合遍历。
hasNext()、next()方法如何使用?
方法返回值功能描述hasNext()boolean判断是否有元素迭代, 如果仍有元素可以迭代,则返回 true,否则返回falsenext()返回迭代的下一个元素
迭代器中的方法是如何实现的呢?
迭代器是在ArrayList以内部类的方式实现的!并且,从源码可知:Iterator实际上就是在遍历集合。
我们遍历集合(Collection)的元素都可以使用Iterator,至于它的具体实现是以内部类的方式实现的!
实例化集合类对象的语法规则?
基本语法:集合接口 对象引用名 = new 接口实现类<>()
代码实现
package cn.wells;
import java.util.*;
public class Muster {
public static void main(String[] args) {
Collection<String> list = new ArrayList<>(); //实例化集合类对象
//用于向上转型
//ArrayList类是Collection的子接口List的实现类
list.add("a"); //向集合类中添加数据
list.add("b");
list.add("c");
Iterator<String> it = list.iterator(); //创建迭代器,用于遍历集合
while(it.hasNext()) { //判断是否有下一个元素
String str = (String)it.next(); //获取集合中的元素
System.out.println(str);
}
}
}
List集合
List集合包括什么?
List集合包括List接口以及List接口所有实现类。
List集合的特点?
List集合中的元素允许重复,各元素的顺序就是对象插入的顺序(有顺序)。这样的特点类似于数组,可以通过索引来访问集合中的元素。
List接口
因为List接口继承了Collection接口,所以继承了Collection中的所有的方法。其中有两个独有的,比较重要的方法:
方法功能描述get(int index)获取指定索引位置的元素set(int index, Object o)将集合中指定索引位置的对象修改为指定的对象
Collection返回的是Iterator迭代器接口,那么List中有什么自己对应的实现吗?
ListIterator接口
Iterator迭代器接口和ListLterator接口有什么不一样吗?
ListIterator接口比Iterator接口的几个方法,主要的功能是遍历、添加元素和设置元素
List接口实现类
List接口常用实现类有ArrayList类与LinkedList类
List集合的继承关系
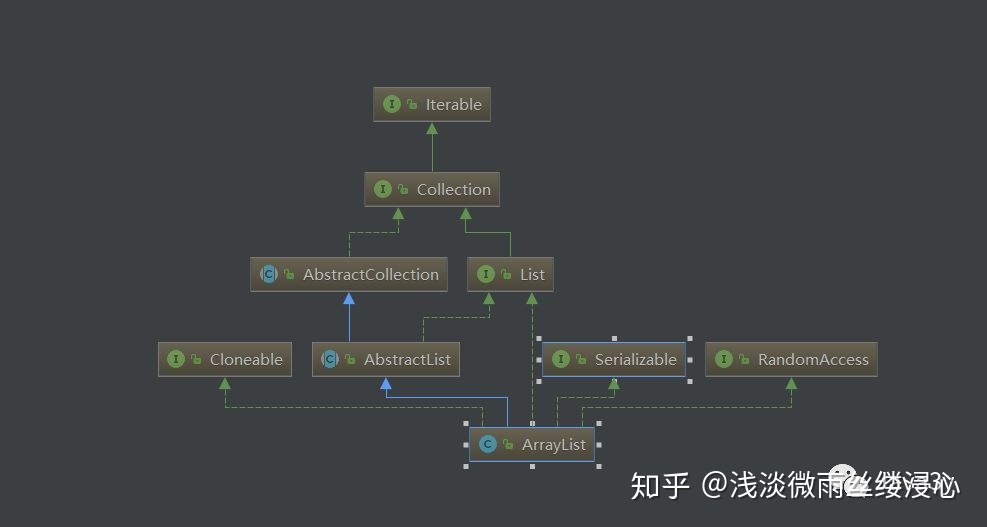
注意:ArrayList因为有扩容这个概念,所以可以实现动态增长
ArrayList类的缺点和优点?
优点:
ArrayList类实现了可变数组,允许保存所有的元素,包括null。根据索引位置对集合进行快速的随机访问。因为ArrayList的底层是数组。
缺点:
向指定的索引位置插入对象或删除对象速度较慢。
LinkedList类的优点和缺点?
优点:
LinkedList类采用链表结构保存对象。优点是便于向集合中插入和删除对象,并且效率较高。因为LinkedList底层是链表。
缺点:
随机访问LinkedList类中对象效率较低。
补充:List实现的子类还有Vector类
List实现的子类的线程安全是怎么样的?
ArrayList类和LinkedList类是不安全的,而Vector类是安全的。
ArrayList类和LinkedList类实例化对象的语法是什么?
类语法ArrayListList list = new ArrayList<>()LinkedListList list = new ArrayList<>()
注意:
语法格式中的E表示Java中合法的数据类型。例如,集合中的元素是字符串类型,那么这里的E就可以修改为String。
与数组相同,集合的索引也是从0开始的
代码实现
package cn.wells;
import java.util.*;
public class Gather {
public static void main(String[] args) {
List<String> list = new ArrayList<>(); //创建集合对象
list.add("a"); //向集合添加元素
list.add("b");
list.add("c");
int i = (int)(Math.random()*list.size()); //获取索引范围内的随机数
System.out.println("随机获取数组中的元素:" + list.get(i)); //获取指定索引的元素
list.remove(2); //使用的是Collection接口中的方法 //将指定索引位置的元素从集合中移除
System.out.println("将索引'2'的元素从数组中移除后,数组中的元素是:");
//遍历集合
for(int j = 0; j < list.size(); j++) {
System.out.println(list.get(j));
}
}
}
Set集合
Set集合的特点?
Set集合中不能包含重复对象。
Set集合中的对象不按特定的方式排列(无顺序),只是简单地把对象加入集合中。
Set集合的组成?
Set集合由Set接口和实现类组成。
和List接口一样,Set接口继承了Collection接口,所以包含Collection接口中的所有方法。
Set集合实际上就是HashMap进行构造的
Set集合必须注意的问题
Set的构造有一个约束条件,传入的Collection对象不能有重复值,必须小心操作可变对象(Mutable Object)。如果Set中的可变元素改变了自身状态导致Object.equals(Object) = true,则会出现某些问题。因为已经不满足Set中不能包含重复对象的基本条件。
Set接口实现类
Set接口常见的实现类是HashSet类和TreeSet类
HashSet类的优缺点?
Hash类由哈希表支持,实际上是一个HashMap实例。
优点:
允许使用null值,因为底层数据结构是哈希表(元素为链表的数组)
缺点:
不保证Set的迭代顺序,特别是它不保证该顺序恒久不变(无顺序)
TreeSet类的优点?
在遍历集合时不仅可以按照自然顺序递增排序,还可以按照指定比较器递增排序,也就是可以通过比较器对用TreeSet类实现的Set集合中的对象进行排序(原因:TreeSet类不仅实现了Set接口,还实现了java.util.SortedSet接口)。
TreeSet类底层结构是红黑树(一个自平衡的二叉树),以此来保证元素的排列方式。
补充:Set集合实现的子类还有LinkedHashSet类,底层由哈希表和链表组成
什么时比较器?
一个对象中有多个属性,选择器就是选择什么属性进行排序。比较器主要用于对对象的排序。
TreeSet类中独特的方法
方法功能描述first()返回Set中当前第一个(最低)元素last()返回Set中当前最后一个(最高)元素comparator()返回对此Set中的元素进行排序的比较器。如果此Set使用自然排序,则返回nullheadSet(E toElement)返回一个新的Set集合,新集合是toElement(不包含)之前的所有对象subSet(E fromElement, E fromElment)返回一个新的Set集合,是fromElement(包含)对象与fromElement(不包含)之间的所有对象tailSet(E fromElement)返回一个新的Set集合,新集合包含对象fromElement(包含)之后的所有对象
代码实现
package cn.wells;
import java.util.Iterator;
import java.util.TreeSet;
public class UpdateStu implements Comparable<Object> {
String name;
long id;
public UpdateStu(String name, long id) {
this.name = name;
this.id = id;
}
//重写Comparable接口中的compareTo()方法,比较该对象和指定对象的顺序,如果该对象小于、等于、大于指定对象,则返回负整数、0或正整数。
//哪里用到了这个方法,为什么这个方法会影响后面的headSet()方法和subSet()方法
public int compareTo(Object o) {
UpdateStu upstu = (UpdateStu)o;
int result = id > upstu.id ? 1 : (id == upstu.id ? 0 : -1);
return result;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public long getId() {
return id;
}
public void setId(long id) {
this.id = id;
}
public static void main(String[] args) {
UpdateStu stu1 = new UpdateStu("李同学", 01011); //创建UpdateStu对象
UpdateStu stu2 = new UpdateStu("陈同学", 01021);
UpdateStu stu3 = new UpdateStu("王同学", 01051);
UpdateStu stu4 = new UpdateStu("马同学", 01012);
TreeSet<UpdateStu> tree = new TreeSet<>(); //创建TreeSet对象
tree.add(stu1); //向集合中添加对象
tree.add(stu2);
tree.add(stu3);
tree.add(stu4);
Iterator<UpdateStu> it = tree.iterator(); //Set集合中所有对象的迭代器
System.out.println("Set集合中的所有元素:");
while(it.hasNext()) {
UpdateStu stu = (UpdateStu)it.next();
System.out.println(stu.getId() + " " + stu.getName());
}
//会有"java.lang.IllegalArgumentException: fromKey > toKey"异常
it = tree.headSet(stu2).iterator(); //截取排在stu2对象之前的对象
System.out.println("截取前面部分的集合:");
while(it.hasNext()) {
UpdateStu stu = (UpdateStu)it.next();
System.out.println(stu.getId() + " " + stu.getName());
}
//会有"java.lang.IllegalArgumentException: fromKey > toKey"异常
it = tree.subSet(stu2,stu3).iterator(); //截取排在stu2对象与stu3对象之间的对象
System.out.println("截取前面部分的集合:");
while(it.hasNext()) {
UpdateStu stu = (UpdateStu)it.next();
System.out.println(stu.getId() + " " + stu.getName());
}
}
}
问题:headSet()方法和subSet()方法与compareTo()方法有什么联系,为什么返回的值会对headSet()方法和subSet()方法有影响?为什么要重写Comparable接口中的compareTo()方法?
注意:headSet()、subSet()、tailSet()方法截取对象生成新集合时是否包含指定的参数,可通过如下方法进行判断:如果指定参数位于新集合的起始位置,则包含该对象,如subSet()方法的第一个参数和tailSet()方法的参数;如果指定参数是新集合的最终位置,则不包含该参数,如headSet()方法的入口参数和subSet()方法的第二个入口参数。
理解:TreeSet类中的headSet()、subSet()、tailSet()等方法都是用于截取指定集合中的对象,但是有时候可以截取到对象,有的时候不可以。如果从指定参数位置往前截取,那么不包含这个参数所指定的对象。如果从指定参数往后截取,包含这个参数所指定的对象。
Map集合
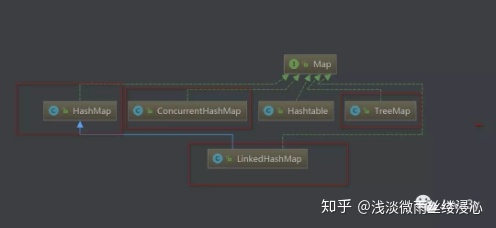
Map集合的继承关系
Map集合的特点?
Map集合没有继承Collection接口,将键映射到值的对象,一个映射不能包含重复的键,每个键最多只能映射一个值
Map集合的组成?
Map集合包含Map接口以及Map接口的所有实现类
我们为什么需要Map集合来存储数据结构呢?
举一个例子,作为学生,我们是根据学好进行区分。只要我们直到学号,那么我们就可以获取学生信息。这就是Map映射的作用。
Map和Collection有什么区别?
Map集合存储元素是成对出现的,Map的键是唯一的,键是可以重复的。
Collection集合存储元素是单独出现的,Collection的子类Set是唯一的,List是课重复的。
其中要注意,Map集合的数据结构针对键有效,与值无关。Collection集合的数据结构针对元素有效。
Map集合中的key和value的特点?
Map中不能包含相同的key,每个key只能映射一个value
key决定了存储对象在映射中的存储位置,不是由key本身决定的,而是由一种”散列技术”进行处理,产生一个散列码的整数值。
无论是Set还是Map,我们可以发现都会有对应的HashMap、HashMap,那么就涉及到了链表的知识。以下是链表的优缺点,
(1)链表和数组都可以按照人们的意愿来排列元素的次序,它们可以说是有序的(存储的顺序和去除的顺序是一致的)
(2)也会带来缺点:如果想要获取某个元素,就需要访问所有的元素,直到找到为止,所以会消耗很多的时间。
散列码是什么?
为了能够快速查找元素的数据,就出现了散列码这种数据。
散列码常用作一个偏移量,该偏移量对应分配给映射的内存区域的起始位置,从而确定存储对象在映射中的存储位置。
散列码的工作原理?
散列码为每个对象计算出一个整数,称为散列码。根据这些计算出来的整数(散列码)保存在对应的位置上。
Map接口
Map接口提供了将key映射到值的对象。一个映射不能包含重复的key,mzgekey最多映射到一个值。
Map接口的功能
1、添加功能(put(K key, V value))
2、删除功能(clear()、remove(Object key))
3、判断功能(containsKey(Object key)、containsValue(Object value)、isEmpty())
4、获取功能(Set<Map.Entry<K key, V value>entrySet()
5、长度功能
方法返回值功能描述put(K key, V value)V向集合中添加指定的key与value的映射关系 ,如果键是第一次存储,就直接存储元素,返回null;如果不是第一次存储,那么把原来的值替换掉,返回以前的值clear()void移除所有的键值对元素remove(Object k)V根据键删除值,然后把值返回containsKey(Object key)boolean判断集合中是否包含指定的键containsValue(Object value)boolean判断集合中是否包含指定的值isEmpty()boolean判断集合是否为空entrySet()Set<Map.Entry<K eky, V value>返回的是键值对对象的集合get(Object key)V如果存在指定的key对象,则返回该对象对应的值,否则返回nullkeySet()Set获取集合中的所有键的集合方法返回值功能描述values()Collection获取集合中所有值的集合size()int返回集合中键值对的对数
代码实现
package cn.wells;
import java.util.*;
public class UpdateStu2 {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>(); //创建Map实例
map.put("01", "李同学"); //向集合中添加对象
map.put("02", "魏同学");
Set<String> set = map.keySet(); //构造Map集合中的所有key对象的集合
Iterator<String> it = set.iterator(); //创建集合迭代器
System.out.println("key集合中的元素:");
while(it.hasNext()) { //遍历集合
System.out.println(it.next());
}
Collection<String> coll = map.values();
it = coll.iterator();
System.out.println("value集合中的元素:");
while(it.hasNext()) { //遍历集合
System.out.println(it.next());
}
}
}
注意:Map集合中允许值对象是null,而且没有个数限制,例如,可通过map.put(“05”, null)语句向集合中添加对象。
Map接口的实现类
Map接口的实现类有哪些?
Map接口实现的类有HashMap类和TreeMap类
为什么推荐使用HashMap类实现Map集合?
HashMap类实现的Map集合添加和删除映射关系效率更高(原因:HashMap是基于哈希表的Map接口的实现,HashMap通过哈希表对其内部的映射关系进行快速查找)
什么情况下使用TreeMap类实现Map集合?
希望Map集合中的对象存在一种顺序(原因:TreeMap的映射关系存在一定的顺序)
HashMap类的特点?
HashMap基于哈希表的Map接口实现,提供了可选的映射操作。在保证键的唯一性下,允许使用null值和null键。
HashMap通过哈希表对其内部的映射关系进行快速查找
HashMap不保证映射的顺序,特别是它不保证该顺序恒久不变
TreeMap类的特点?
TreeMap类不仅实现了Map接口,还实现了java.util.sortedMap接口,因此,集合中的映射关系具有一定的顺序
在添加、删除或定位映射关系时,TreeMap类比HashMap类差
由于TreeMap类实现的Map集合钟的映射关系是根据对象按照一定顺序排列的,因此键对象不会是null
代码实现
package cn.wells;
public class Emp {
private String e_id;
private String e_name;
public Emp(String e_id, String e_name) {
this.e_id = e_id;
this.e_name = e_name;
}
public String getE_Id() {
return e_id;
}
public void setE_Id(String e_id) {
this.e_id = e_id;
}
public String getE_Name() {
return e_name;
}
public void setE_Name(String e_name) {
this.e_name = e_name;
}
}
package cn.wells;
import java.util.*;
public class MapTest {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>(); //由HashMap实现Map对象
Emp emp = new Emp("351", "张三"); //创建Emp对象
Emp emp2 = new Emp("512", "李四");
Emp emp3 = new Emp("853", "王一");
Emp emp4 = new Emp("125", "赵六");
Emp emp5 = new Emp("341", "黄七");
map.put(emp.getE_Id(), emp.getE_Name()); //将对象添加到集合中
map.put(emp2.getE_Id(), emp2.getE_Name());
map.put(emp3.getE_Id(), emp3.getE_Name());
map.put(emp4.getE_Id(), emp4.getE_Name());
map.put(emp5.getE_Id(), emp5.getE_Name());
Set<String> set = map.keySet(); //获取Map集合中的key对象集合
Iterator<String> it = set.iterator();
System.out.println("HashMap类实现的Map集合,无序:");
while(it.hasNext()) {
String str = (String)it.next(); //获取集合中的key对象
String name = (String)map.get(str); //获取集合中的values对象
System.out.println(str + " " + name);
}
TreeMap<String, String> treemap = new TreeMap<>();
treemap.putAll(map);
Iterator<String> iter = treemap.keySet().iterator();
System.out.println("TreeMap类实现的Map集合,键对象升序:");
while(iter.hasNext()) {
String str = (String)iter.next(); //获取集合中的key对象
String name = (String)treemap.get(str); //获取集合中的values对象
System.out.println(str + " " + name);
}
}
}
发现:如果是TreeXxx类,那么就是有顺序的,如果是HashXxx类,就是没有顺序的,但是添加元素、删除元素会更加方便。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/101319.html

