
我还记得,当年拿到双 11 技术架构的命题时,我脑袋中一片空白,后面通过向前辈们学习才慢慢了解:双 11 技术本质上其实就一个问题,如何用有限的资源解决更多的问题,核心其实是一个平衡。
我们的资源有哪些?业务资源、开发资源、硬件资源。业务资源我要投钱,投到什么地方产生更大的效果,这是业务要去考虑的事。开发资源是什么?双 11 的需求真的是非常非常多,要做什么、不做什么,需要脑袋中非常清晰。**一定要有优先级,一定要有取舍,什么需求我投 100 个人我也必须做,哪个需求哪怕一个人就能做完,但我也不会去投入人力。**这个取舍的根源就是要去平衡,要想到怎么样解决资源的问题。怎么用有限的预算解决更多的事?应该保什么?如果出问题,应对措施是什么?
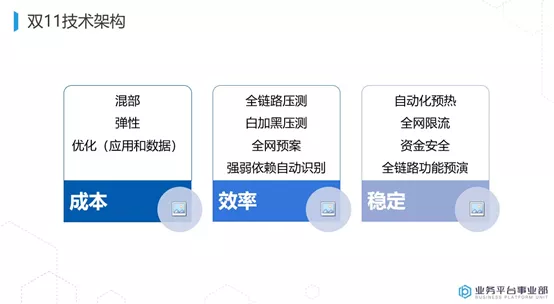
下沉到技术里面去看,有成本、有效率、有稳定。双11我们会谈很多,但归结到根源其实就是4个词——容量、预案、预热、限流。
容量
容量是非常关键的。比如说今年定好双 11 交易 60 万的目标,交易 60 万,那导购多少万,把它定义清楚,然后去编排我们这么多核心应用,应该需要的机器数。
编排好以后,肯定有些地方是捉襟见肘的,有些地方差距很大。大家也会面临这个问题,第一个是硬核措施性能优化。性能优化在阿里一直在提,从 2017 年开始我们提的特别多,最后证实新的优化带来的效果是非常好的。我给大家举个例子,以电商为例,如果你的整个交易呈现了一个大 V 字型,那么营销整个 Load 偏高,因为被打爆了。营销 Load 高了以后,反向的造成了购物车、数据库打爆,购物车数据库打爆以后再反向造成重复下单,其实它是一个循环过程。
出现这个问题的原因是什么?本质上就是容量没有设计到位。
遇到容量问题后,很多同学想到的是扩容,那是最后迫不得已的手段。如果你对数据库了解,你就能想出不一样的策略来解决这个问题。用成本解决问题都是比较原始的,**要换一种思路,真正能用技术解决问题,同时再辅助一点成本,我觉得这是最好的。**数据库我们当时做了一个优化,到现在为止都特别好。
预热
预热就是技术的容量预案,预热限流。双 11 为什么要做预热?其实跟我们的流量模型有关。很多时候我们的流量模型是自然上去慢慢的下来,但双 11 不是,双 11 可能从 2000 多直接到 60 万,然后维持住,慢慢下来。这个过程就相当于短跑。其他业务按照自然流量都是长跑,短跑你必须得热身,没有热身,起步阶段可能就出大问题。比如说抽筋等各种各样的问题。
预热要预热什么?我们当时做了很多预热,数据的预热,应用的预热,连接的预热。
先讲数据的预热。我们访问一个数据,它的数据链路太长了,其实离应用越近可能效果越好。数据预测要看什么数据,该怎么预热?首先把量特别大的数据,跟用户相关的数据,就是购物车、红包、卡券,做数据库的预热。
**第一步:模拟用户查询,查询这个数据库,把它的数据放到我们的 BP 里面。**我们提前做了这个动作,不要到脉冲时再去查磁盘,磁盘永远跟不上我们的内存。
第二步:很多应用都是靠 Tair 挡住的,Tair 一旦失效数据库就挂掉,因为数据库挡不住,这时要提前把数据预热到 Tair 里面。今年大概五六十个应用做了 Tair 的预热,包括 IC、UIC,包括我们的库存,包括我们的履约,非常多的 Tair 预热。
**第三步骤:要做一个 Java 本地内存的预热, UMP 的 GCH 做的本地预热。**UMP 机器特别多,要预热的机器可能 2 万多台,你怎么能做到每一台预热上去?
首先你要有地方生成这个文件,因为文件的一致性是最好的,我要么全加载,要么没加载,我们采用的是用文件方式加载。
然后会有 100 台机器左右,可能现在只有 60 台机器来生成这个文件,生成一个个小的文件,用 MapReduce 的思想,通过一两台机器 Reduce 出一个大文件出来,通过蜻蜓,用 P2P 的方式分发到每台机器上。你这么大的文件,最大大概有 5 个 G 的文件,2 万多台机器分发,整个网络会被打爆的。
现在我们改成用流式的方式,就是生成 25 个文件,然后流式的去做这个事,最终做完了以后 Check,每一个做完的结果都要校验。优惠数据是不能出任何问题,出问题的话用户的购买就会出很大的问题。
还有一个最关键的预热。我们很多代码里面你们翻一翻会写一个代码叫 IF 双 11,然后括号,这段叫双 11 特殊逻辑,平时都用不到的,只有双11的时候才能用到。
今天我跟大家完整的讲一遍预热为什么要做。到现在为止,2020年双11过完了,双12也过完了,我们早已经能比较体系化的做预热,有专门的产品解决所有的预热问题。预热可能也只有在阿里才能遇到,因为有足够大的业务场景和不一样的流量模型,这些复杂的场景在别的公司可能都不太会有。
春晚支付宝做过,淘宝做过,当主持人说“3、2、1 抢红包”,全国人民开始拿出手机抢红包时,如果你不考虑预热场景,系统就雪崩,那是崩的非常快。这个时候像支付宝,一定会做大量数据预热工作,包括应用的预热工作,你们没有感知到但是已经提前完成了。
如果预热的问题没解决好依然会遇到雪崩。雪崩是很可怕的一件事情,你救都救不回来了,眼睁睁的看着它一个个没掉,你只能做前面的限流。
限流
限流是一门很深的学问,如果限流做的好,系统是打不爆的,只是说处于一个限流状态,返回前端,比如说“系统繁忙”,但如果系统出现了白屏,白屏代表系统直接雪崩了,这就是限流的问题。大家吃过亏就知道限流里面非常多的学问。**你限什么,什么时候限,你要保证自己不挂,还要保证别人不要挂。**限流限多了会出现各种各样的状态,所以限流大家应该好好去看一下。
预案
在交易系统中大概有七八千个预案了。预案多了以后,就像飞行员驾驶舱里面的按钮。但预案是一定要做,很多预案是跟用户体验、跟性能相关的。我们日常为了埋点、拿到系统更多的数据,在系统里做了很多跟业务无关的功能,等到大促时这些功能都必须关闭,要通过预案系统去做。
还有一些业务,比如说双 11 的时候,把立项降级掉,有些门槛必须降低,有些门槛必须提高,这都是业务预案。预案分业务预案和系统预案。系统预案我们都可以把它提前降掉,业务预案是根据业务预测的需求做一些配置。
今年我们遇到一些预案影响用户体验的问题。我们做了价格一致性,从淘宝首页和推荐页看到的券后价,到你的购物车和详情,最后下单,价格是一致的。
我们当时考虑到一些其他的因素,因为容量的问题我们提前降级了,恢复成一个单品优惠,这时用户看到的价格可能是不太一致的,比如可能在搜索推荐里面看到的是 600,下单可能看到的是 550 或者是 650,反而影响了用户体验。明年的双 11 我们会针对用户体验的预案做一些控制,尽量通过技术确保用户体验。
双 11 跟大家的应用有关系时,除了注意本身的功能开发以外,**包括功能测试、安全测试、资损测试。需求完成以后,跟稳定性相关的就四个词—容量、预案、预热、限流。每个都很讲究,把每个点做到位,整个系统就会非常的平稳。**现在这四个词基本上都有工具的方式来支撑大家。
比如:应用高可用服务 AHAS 提供应用架构探测感知、故障注入式高可用能力评测和流控降级高可用防护能力;性能测试 PTS 可以真实模拟多用户高并发访问业务场景,结合监控(ARMS)、流控等产品提供一站式高可用能力,高效检验和管理业务性能。这些都是做预案、预热、限流的很好用的云原生产品,是经过阿里内部大规模实践验证过的,也是对外商业化口碑不错的产品。
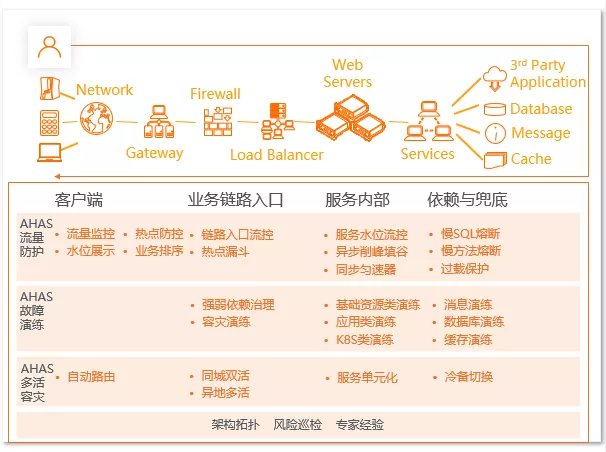
单元化架构(异地多活、同城容灾)
这是阿里一位技术大牛毕玄的代表作:单元化。我们用的比较多,我对它有新的认识后,发现还可以做一些更多不一样的优化,也给大家介绍一下单元化架构到底解决什么样的问题。
单元化架构本身就是解决一个地域装不下阿里的所有业务,必须要搬到其他地方,然后才能解决阿里现有的问题。
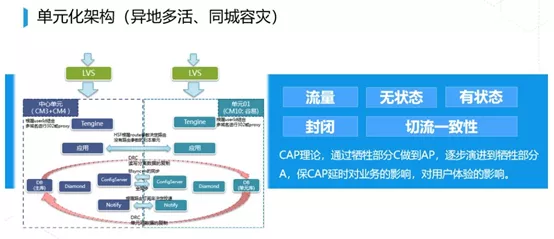
这个东西是 2013 年开始,2014 年就逐步的上线,到 2015 年单元化二期彻底的做完终于解决了这个问题。
我们现在整体的架构通过一个中心两个单元的方式来支撑阿里的整个流量。要能做到用户体验基本不受太大的影响,单元化才能算比较大的成功。同时单元化里面带来了一个新的东西叫同城容灾。同城容灾难度不大,单元化容灾难度非常大。
我跟大家分享这里面的难度,我们的应用只有两种,一种叫有状态应用,一种叫无状态应用。无状态应用在哪边部署,你就近接入就可以了。有状态应用必须取决于有状态的那个点在哪,其他的地方只能回到这个有状态的地方来进行访问。我们哪些地方是有状态的?数据库有状态, LDB 有状态,消息有状态,只要带持久化和存储的都是有状态的。
同城容灾时,我们的数据库其实是单边运行的,消息也是单边运行的,LDB 也是单边运行的。在同城的情况下,应用是两边可以同时接受流量,但我的有状态是单边的,当 A 出现问题的时候,我把它切换到 B,然后我上面还是对外统一提供服务,就是同城比较简单。同城比较简单还有一个延时,因为是同城,延时基本上都在一毫秒甚至一毫秒以内。所以你即使从 A 切到 B,应用到 B 之间的整个 RT 都非常短,整个没有太大的影响。
传统的行业、政府、运营商、金融基本上都是同城容灾的模式,甚至是同个地方有 3 个机房,有 4 个机房,5 个机房,其实没有关系,都叫同城。同城好做,就是 RT 短,变成异地单元化以后就特别难做了,就是因为 RT 太长了。
前段时间跟某客户去沟通,客户说自己是单元化的。我说你们的机房相隔有多远?他说可能也就 30 公里到 50 公里,我说能不能把机房搬到 300 公里以外甚至 500 公里以外?他说搬过去以后可能就会受到比较大的影响了,这就是一个非单元化的架构,它就是个同城。同城和单元化的区别就是 RT,你能不能把你的机房搬到 1000 公里以外,搬了 1000 公里以外还能正常的运行,你就是单元化的。
单元化讲究的是什么?封闭。我这个单元化里面存在30%的用户流量,这30%的用户流量不会乱窜,都是在本地进行的,所以这叫单元化。
本地进行代表了什么?有可能状态不太一致。比如说 A 用户我在中心的时候下单了,这时候单元化切流把那部分 A 的用户切到了单元去。切过去单元的时候,单元看不到这笔订单,用户他会比较慌的,说白了就是订单丢失了。所以需要针对整个单元化的数据,进行一个全网的 DRC 的环状复制。在C处产生的数据要回到中心,同时中心要把这部分数据发到D处,就每个点都能看到全量的数据,这样你的流量才能飘,否则你飘不掉了,你只能固定在某个地方,这是跟用户相关的,包括购物车、订单、用户的红包、卡券,都是这么做的。
还有部分是飘不掉的,比如说商家类的,商家的商品,商家的库存,这个跟商家紧密相关,跟消费者没关系。比如商家发布一个商品都是在中心发布的,这个时候单元怎么办?我们就通过复制的方式让单元看到这个商品的数据,所以大家会有一个大概 30~50 毫秒的延迟,包括库存。库存是严格要求一致性的,我们扣库存的时候必须跨长传链路到中心去扣。
这个是我们整个单元化交易里面最大的挑战。
所有的都可以封闭在一个单元内部,包括交易、用户的购物车订单、资金、红包都可以在一个单元内封闭掉,商品查询时也查本地,从中心把数据同步过来,但库存是在中心扣的,这是我们现在单元化面临的挑战。今年我们也在尽力解决这个问题,其实难度很大。
还有一个问题我们也在解决,阿里是个生态,外面还有商家,有 ISV,有很多下游的 ERP 供应链,他们都是跟阿里的系统连接起来的。我们会面临第二个问题:怎么能把阿里生态外的系统也做到容灾。这就挑战更大了,因为商家的系统不像阿里这么灵活,商家系统对于网络要求都是用防火墙的配置来配置 IP 的,如果我飘到别的地方,我的公告 IP 一定发生变化,我的 RT 一定也会发生变化,这样它的系统就要改变很多配置。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/101324.html

