
一、网络爬虫是什么?
网络爬虫,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
二、需要用到的库
通过pip命令安装,pip install requests
通过pip命令安装,pip install beautifulsoup4
# 引入库:
import requests
from bs4 import BeautifulSoup三、爬取资源步骤
1.从开发者工具中找到你想要获取资源的位置
F12 呼出 开发者工具 –>选择元素栏–>查找你要的资源的位置
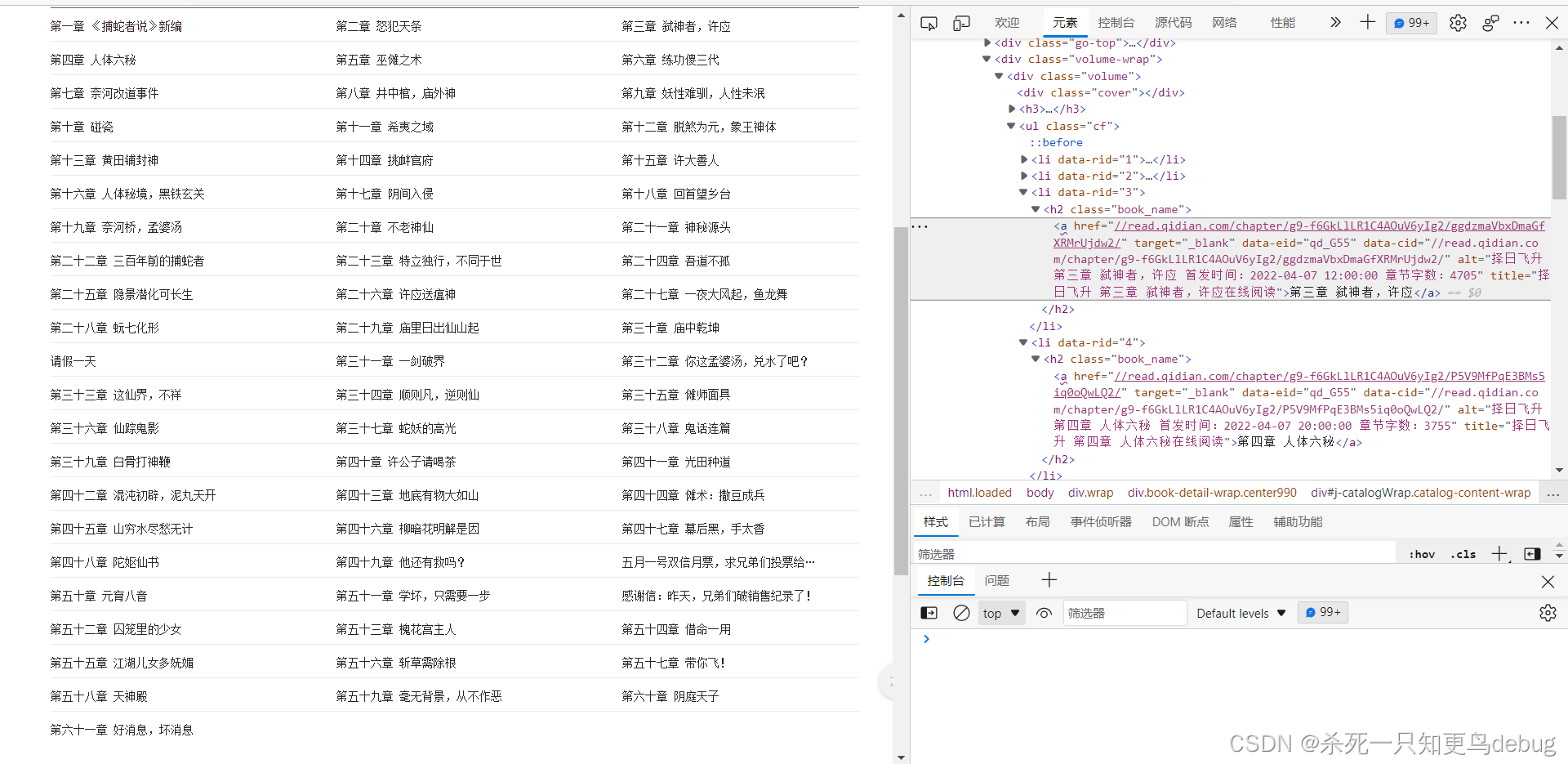
查看一下文字资源的位置。

资源已经查找完毕,可以开始写代码了。
2.代码部分
import requests
from bs4 import BeautifulSoup
def getRep():
# 伪装标准请求头
headers = {"User-Agent": "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1;Trident / 5.0;"}
# 网站地址
url = 'https://book.qidian.com/info/1032778366/#Catalog'
response = requests.get(url, headers)
if response.status_code!=200:
print("未能成功响应")
elif response.status_code==200:
print("成功响应")
# 设定响应编码,
response.encoding = "utf-8"
# 获取字符文本结构
respTxt = response.text
# 通过beautifulsoup对象来获取它的树结构
soup1 = BeautifulSoup(respTxt,'html.parser')
# 获取 章节列表资源 --<h2 class="book_name"><a data-cid="xxx"></a></h2>
chapterBox = soup1.find_all("h2",class_="book_name")
for cpd in chapterBox:
cpList = cpd.a
cpUrl = 'https:' +cpList['data-cid']
secondLink(cpurl=cpUrl)
def secondLink(cpurl):
secLink = cpurl
headers = {"User-Agent": "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1;Trident / 5.0;"}
response2 = requests.get(secLink,headers)
if response2.status_code!=200:
print("章节响应失败")
elif response2.status_code==200:
print("章节响应成功")
# 设定响应编码,
response2.encoding = "utf-8"
# 获取字符文本结构
resp2Txt = response2.text
# 获取每个章节盒子
soup2 = BeautifulSoup(resp2Txt,'html.parser')
# 章节标题 <span class="content-wrap">章节标题<span>
# 段落内容 <div class="read-content j_readContent">文字内容</div>
title = soup2.find("span", class_="content-wrap").text
readBoxs = soup2.find("div", class_="read-content j_readContent").text
print(title)
f = open("d:/t1.txt", 'a',encoding='utf-8')
f.write(title)
f.write(readBoxs) # 将字符串写入文件中
f.write("\n")
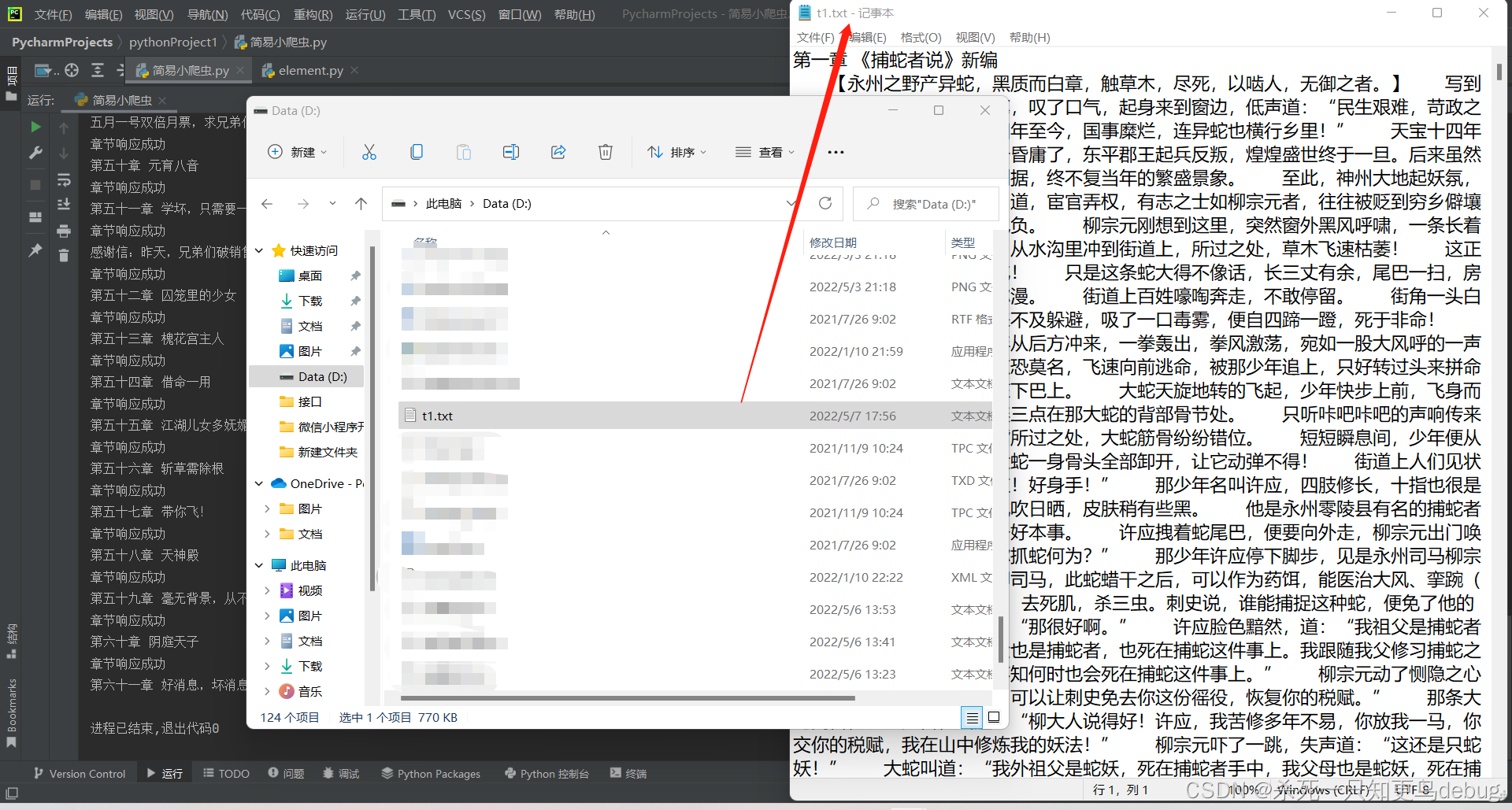
getRep()4.运行结果
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/105205.html

