
来来来,给俏如来扎起。感谢老铁们对俏如来的支持,2021一路有你,2022我们继续加油!你的肯定是我最大的动力
博主在参加博客之星评比,点击链接 , https://bbs.csdn.net/topics/603957267 疯狂打Call!五星好评 ⭐⭐⭐⭐⭐ 感谢。
前言
上一篇文章我们分析了一下Mybatis的初始化流程,跟踪了一下Mybatis的配置解析过程,SqlSessionFactory和SqlSession的创建过程,这篇文章我们来分析一下SqlSession的执行流程
Mybatis的执行流程
下面这个图是在上一章《Mybatis初始化》有分析过的Mybatis的执行流程
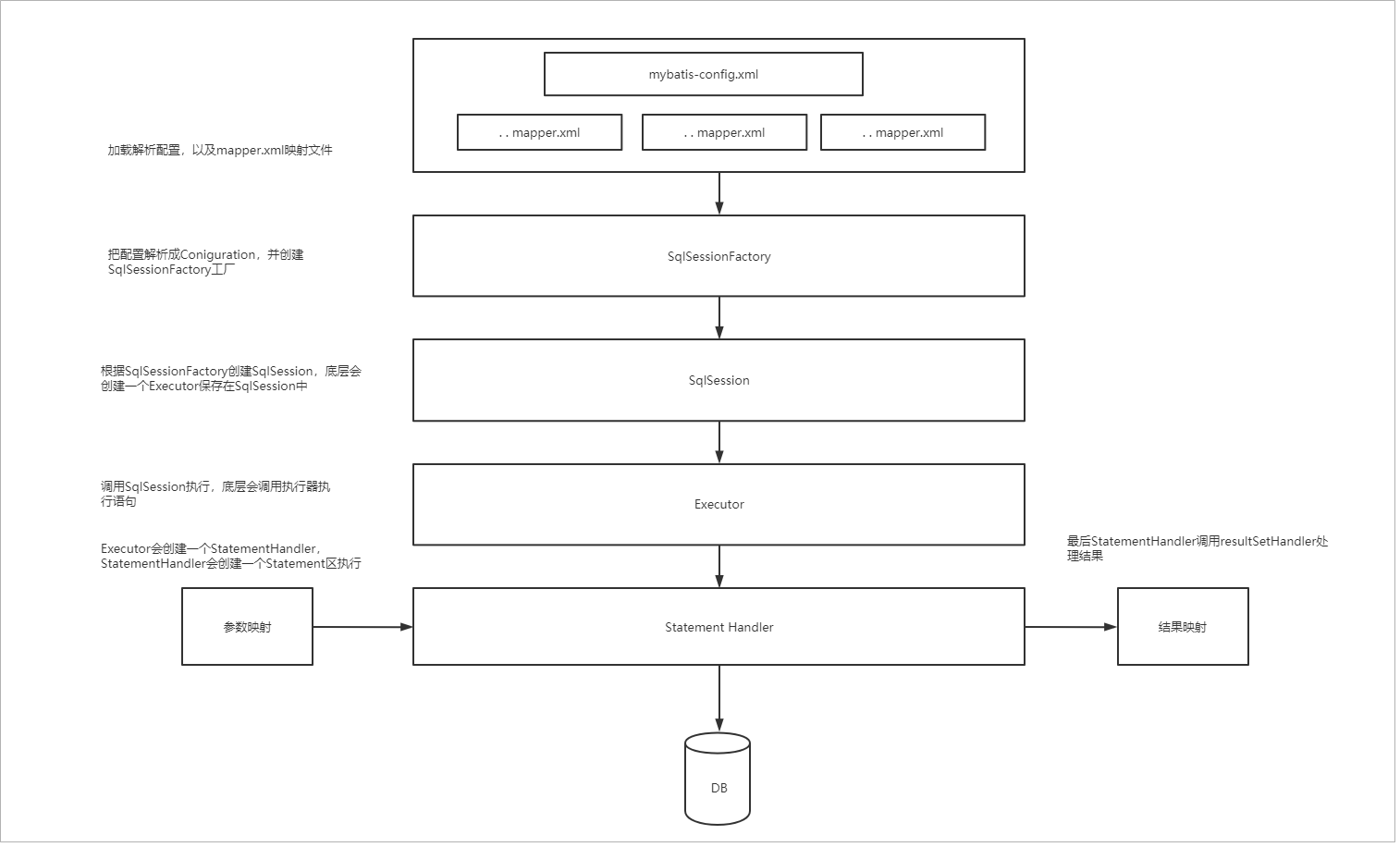

Mybatis执行流程如下
- 初始化阶段,加载配置文件
- 根据配置文件,创建SqlSessionFactoryBuider,执行build方法来创建SqlSessionFactory,build方法会解析配置文件,然后封装到一个Configuration对象中。Configuration会保存在创建的SqlSessionFactory
- 通过SqlSessionFactory来创建SqlSesion,底层会创建一个Executor执行器保存在SqlSession中
- 然后就是SqlSesson的执行了,SqlSession会调用 executor 执行器去执行
- 执行器中会创建一个StatementHandler,调用StatementHandler去执行Statement语句,当然执行Statement语句前涉及到参数的处理
- 执行完成之后使用ResultSetHandler映射结果为实体对象并返回
我们将接着分析sqlSession.selectOne("cn.whale.mapper.StudentMapper.selectAll",1L); 的执行流程。见:org.apache.ibatis.session.defaults.DefaultSqlSession#selectOne(java.lang.String, java.lang.Object)
@Override
public <T> T selectOne(String statement) {
return this.<T>selectOne(statement, null);
}
@Override
public <T> T selectOne(String statement, Object parameter) {
//1.调用selectList方法查询
List<T> list = this.<T>selectList(statement, parameter);
if (list.size() == 1) {
//2.拿到结果返回
return list.get(0);
} else if (list.size() > 1) {
throw new TooManyResultsException("Expected one result (or null) to be returned by selectOne(), but found: " + list.size());
} else {
return null;
}
}
这里我们看到, selectOne 方法 使用的是 selectList来查询结果,接着看selectList,见:org.apache.ibatis.session.defaults.DefaultSqlSession#selectList(java.lang.String, java.lang.Object)
@Override
public <E> List<E> selectList(String statement, Object parameter) {
return this.selectList(statement, parameter, RowBounds.DEFAULT);
}
@Override
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
//1.从配置中拿到MappedStatement ,其中维护了SQL,mapper接口映射器,二级缓存cache,ParameterMap参数,ResultMap结果映射等等。
MappedStatement ms = configuration.getMappedStatement(statement);
//调用执行器执行 MappedStatement
//wrapCollection(parameter)处理参数,如果是集合会用一个map以collection为key存储。如果是数组会用一个map以array为key存储
//紧接着代码会执行到CachingExecutor#query 方法,这里使用了装饰模式
return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
上面代码首先从configuration中拿到了MappedStatement ,MappedStatement其中维护了SQL,mapper接口映射器,二级缓存cache,ParameterMap参数,ResultMap结果映射等等。
然后会通过wrapCollection(parameter)对集合或者数组参数做处理,如果是集合会用一个map以collection为key存储。如果是数组会用一个map以array为key存储,这就是为什么我们可以在mapper.xml直接使用’collection’或者‘array’取集合或数组了。
处理好参数后就会走到CachingExecutor#query 方法,我们之前就分析过,执行器默认使用的是SimpleExecutor,而SimpleExecutor有装饰到CachingExecutor中,这里使用了装饰模式。代码来到org.apache.ibatis.executor.CachingExecutor#query
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
//1.从MappedStatement中拿到BoundSql,其中包括SQL和参数
BoundSql boundSql = ms.getBoundSql(parameterObject);
//2.为缓存创建key,以namespace+statementid 加 分页数据 加 SQL 一起作为缓存的key
CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
//3.执行查询
return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
这个方法里面做了三个事情
-
从MappedStatement中拿到BoundSql,BoundSql其中包括未替换占位符?的SQL和 参数,parameterObject就是参数,以及类型处理器typeHandler,下面是截图
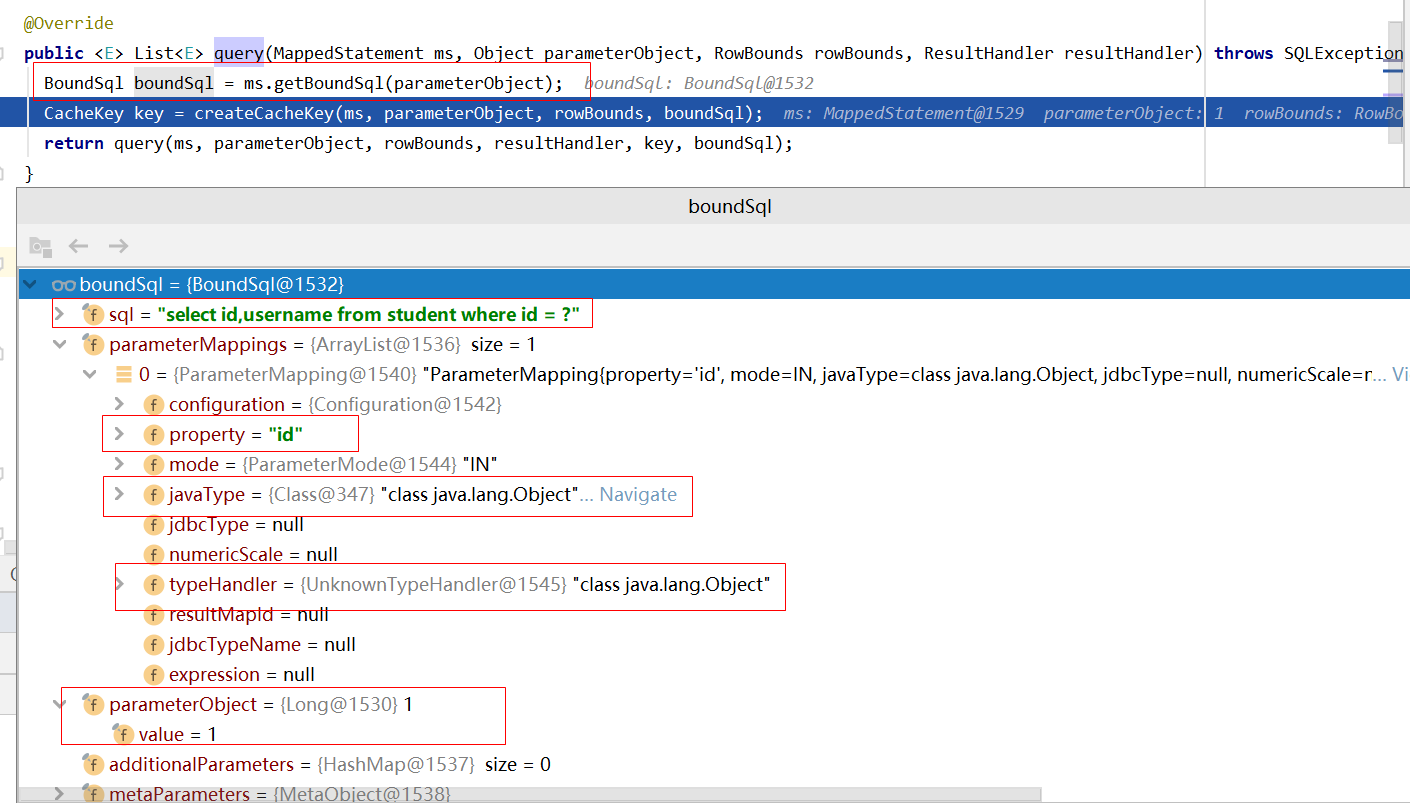
看一下 BoundSql的源码public class BoundSql { //SQL 如:select * from student where id = ? private final String sql; private final List<ParameterMapping> parameterMappings; //参数 private final Object parameterObject; private final Map<String, Object> additionalParameters; private final MetaObject metaParameters; public BoundSql(Configuration configuration, String sql, List<ParameterMapping> parameterMappings, Object parameterObject) { this.sql = sql; this.parameterMappings = parameterMappings; this.parameterObject = parameterObject; this.additionalParameters = new HashMap<String, Object>(); this.metaParameters = configuration.newMetaObject(additionalParameters); } -
创建缓存key,一级缓存和二级缓存的key构架方式都是一样的,下面是创建key的代码,见org.apache.ibatis.executor.BaseExecutor#createCacheKey
@Override public CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) { if (closed) { throw new ExecutorException("Executor was closed."); } CacheKey cacheKey = new CacheKey(); //1.SQL的ID,如 ; cn.whale.mapper.StudentMapper.selectById cacheKey.update(ms.getId()); //2.分页开始位置: 0 cacheKey.update(rowBounds.getOffset()); //3.分页查询条数,默认 2147483647 (Integer.MAX_VALUE;) cacheKey.update(rowBounds.getLimit()); //4.SQL如:select id,username from student where id = ? cacheKey.update(boundSql.getSql()); List<ParameterMapping> parameterMappings = boundSql.getParameterMappings(); TypeHandlerRegistry typeHandlerRegistry = ms.getConfiguration().getTypeHandlerRegistry(); // mimic DefaultParameterHandler logic for (ParameterMapping parameterMapping : parameterMappings) { if (parameterMapping.getMode() != ParameterMode.OUT) { Object value; String propertyName = parameterMapping.getProperty(); if (boundSql.hasAdditionalParameter(propertyName)) { value = boundSql.getAdditionalParameter(propertyName); } else if (parameterObject == null) { value = null; } else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) { value = parameterObject; } else { MetaObject metaObject = configuration.newMetaObject(parameterObject); value = metaObject.getValue(propertyName); } //5.参数也作为缓存key的一部分 cacheKey.update(value); } } if (configuration.getEnvironment() != null) { // issue #176 cacheKey.update(configuration.getEnvironment().getId()); } return cacheKey; }所以缓存的key是 statementId ; 分页 ;SQL ,参数值 一起组成的,也就是说只要是同一SQL,分页条件也相同,参数也相同的话,就可以命中缓存。
-
第三个动作就是执行query方法了,
接下来我们继续分析query方法,此时的代码还是在CachingExecutor中,见:org.apache.ibatis.executor.CachingExecutor#query
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
//1.拿到缓存,这个是二级缓存,如果在mapper.xml 中配置了 <cache/> 就会创建Cache对象
Cache cache = ms.getCache();
if (cache != null) {
//下面在走二级缓存流程
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, boundSql);
//2.从缓存中拿值,二级缓存通过tcm,也就是TransactionalCacheManager来管理的
@SuppressWarnings("unchecked")
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
//3.如果二级缓存中没有,就会走数据库查询
list = delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
//查到之后放入二级缓存
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
//4.如果没有开启二级缓存,直接走数据库查询
return delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
这个方法主要涉及到二级缓存的查询,如果我们开启了二级缓存,且在mapper.xml中配置了<cache/> Mybatis就会创建一个Cache对象。即查询的时候就会走二级缓存中去尝试拿数据。如果有直接返回,如果没有会从数据库查询,然后放入二级画出来。需要说明的是二级缓存是通过 TransactionalCacheManager 来管理的。
二级缓存我们先不管,继续跟踪query方法,即代码来到了org.apache.ibatis.executor.BaseExecutor#query
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
queryStack++;
//1.这里会先从一级缓存获取数据,一级缓存在BaseExecutor.PerpetualCache 中
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
//2.如果一级缓存没有获取到数据库,就走数据库查询
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
return list;
}
上面方法会走一级缓存查询,一级缓存在BaseExecutor.PerpetualCache 中以HashMap<Object, Object> 结构存储的默认开启,如果一级缓存没有就走数据库查询,此时代码来到org.apache.ibatis.executor.BaseExecutor#queryFromDatabase
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
//1.走数据库查询
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);
}
//2.把数据查询出来的数据库写入一级缓存
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
上面代码走数据库查询数据,然后把数据写入一级缓存,最后返回数据。这里我们跟深一点,继续来到org.apache.ibatis.executor.SimpleExecutor#doQuery方法中,我们来看一下到底是怎么从数据库查询的
@Override
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
//1.从MappedStatement中拿到coniguration对象
Configuration configuration = ms.getConfiguration();
//2.创建StatementHandler ,StatementHandler也会加入Configuration总的 interceptorChain拦截器链
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
//3.创建一个Statement,方法中会从Transaction总拿到Connection,通过Connection创建一个PrepareStatement
stmt = prepareStatement(handler, ms.getStatementLog());
//4.调用StatementHandler去执行Statement语句
return handler.<E>query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
}
上面方法先是通过Connection创建一个PrepareStatement,然后调用StatementHandler#query去执行PrepareStatement,最终代码会来到:org.apache.ibatis.executor.statement.PreparedStatementHandler#query
@Override
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
//1.执行语句,调用 PreparedStatement 的execute方法
ps.execute();
return resultSetHandler.<E> handleResultSets(ps);
}
到这里就差不多了,代码最后回调用PreparedStatement#execute方法去执行,执行的结果会保存到PreparedStatement中,然后通过ResultSetHandler去处理结果集,默认实现为DefaultResultSetHandler,代码来到org.apache.ibatis.executor.resultset.DefaultResultSetHandler#handleResultSets
public List<Object> handleResultSets(Statement stmt) throws SQLException {
ErrorContext.instance().activity("handling results").object(mappedStatement.getId());
final List<Object> multipleResults = new ArrayList<Object>();
int resultSetCount = 0;
//1.把statement中的结果集交给 ResultSetWrapper中
ResultSetWrapper rsw = getFirstResultSet(stmt);
//2.从mappedStatement中拿到ResultMap,也就是我们在mapper.xml总定义的<resultMap/>结果集映射器
List<ResultMap> resultMaps = mappedStatement.getResultMaps();
int resultMapCount = resultMaps.size();
validateResultMapsCount(rsw, resultMapCount);
while (rsw != null && resultMapCount > resultSetCount) {
ResultMap resultMap = resultMaps.get(resultSetCount);
//3.处理结果集映射
handleResultSet(rsw, resultMap, multipleResults, null);
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
resultSetCount++;
}
String[] resultSets = mappedStatement.getResultSets();
if (resultSets != null) {
while (rsw != null && resultSetCount < resultSets.length) {
ResultMapping parentMapping = nextResultMaps.get(resultSets[resultSetCount]);
if (parentMapping != null) {
String nestedResultMapId = parentMapping.getNestedResultMapId();
ResultMap resultMap = configuration.getResultMap(nestedResultMapId);
handleResultSet(rsw, resultMap, null, parentMapping);
}
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
resultSetCount++;
}
}
return collapseSingleResultList(multipleResults);
}
上面代码会先从mappedStatement中拿到ResultMap,也就是我们在mapper.xml总定义的结果集映射器,然后调用handleResultSet方法处理结果,方法底层默认回使用DefaultResultHandler结果处理器来处理。
在DefaultResultHandler方法中会拿到ResultMap说指定的type也就是<resultMap id="resultMap" type="cn.whale.domian.Student"> 使用 ObjectFactory 对象工厂利用反射通过无参构造器创建对应的实体类实例。
然后会拿到根据ResultMap结果映射的每一个column , 使用对应的TypeHandler从结果集中取出对应的值,使用反射赋值给对象的实例。到此结果集映射成对象完毕。最后返回结果。最后关闭Statement。
总结
文章也是挺长了,我们来总结一下Mybatis的执行流程
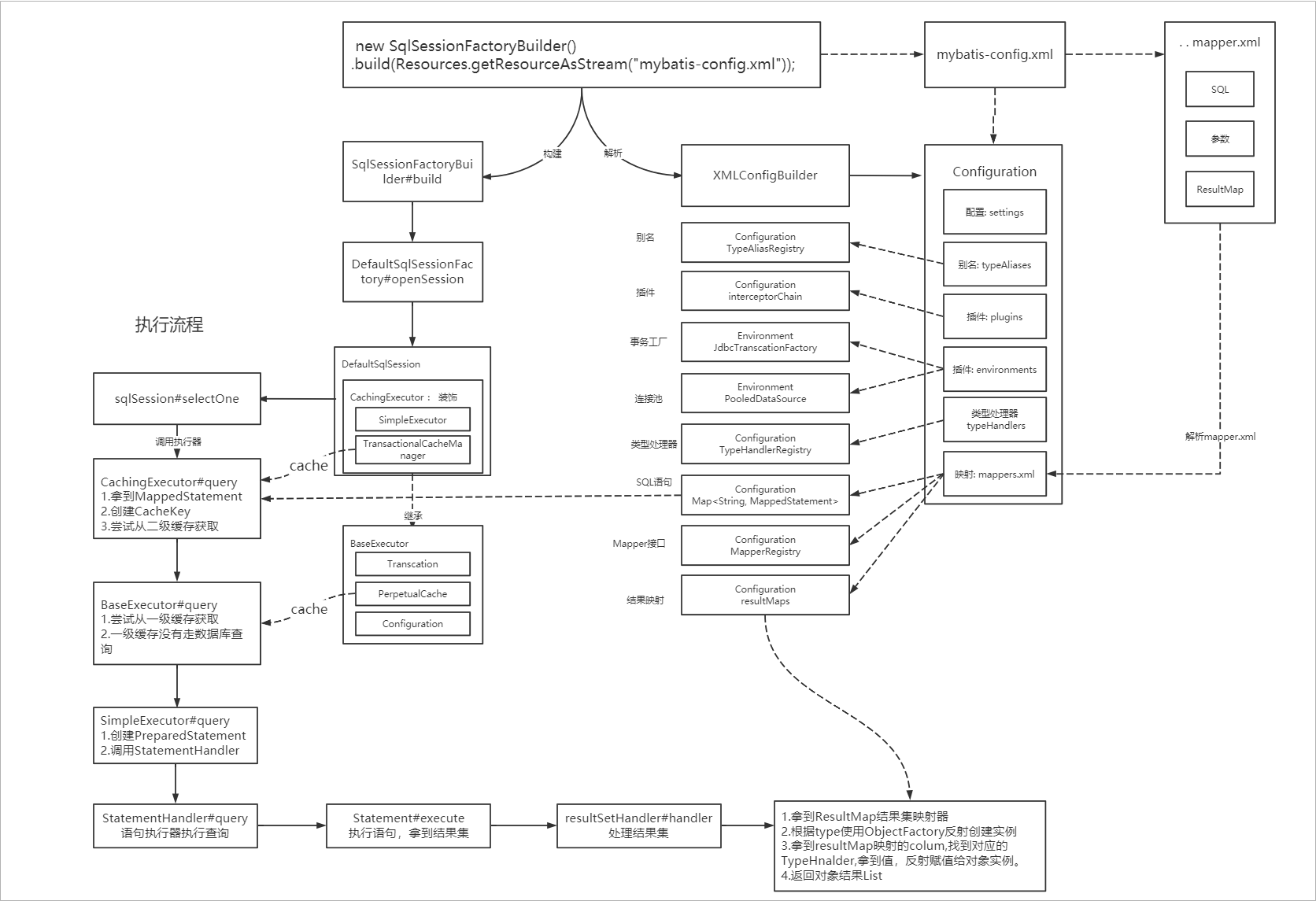
- 当我们执行SqlSession的select方法时,会从Configuration中拿到MappedStatement(包括SQL,参数映射,结果集映射等)。然后调用executor去执行query方法
- 接着代码来到executor执行器,它会先创建CacheKey缓存的key,缓存的key是 statementId ; 分页 ;SQL ,参数值 一起组成的,也就是说只要是同一SQL,分页条件也相同,参数也相同的话,就可以命中缓存。
- 如果有开启二级缓存的话,会尝试执行二级缓存,有就返回,没有就从数据库查询,然后再把结果添加到二级缓存。二级缓存在TransactionalCacheManager中管理起来的。
- 假设没有二级缓存,尝试从数据库查询此刻会尝试从一级缓存查询数据,有就返回,没有就从数据库查询。一级缓存在SqlSession中的BaseExecutor.PerpetualCache 中,所以是先执行二级缓存再执行一级缓存。
- 如果还是没有命中缓存,就会通过Connection创建一个PrepareStatement,然后调用StatementHandler#query去执行PrepareStatement。
- 紧接着StatementHandler方法底层会调用PrepareStatement#execute查询结果,然后调用ResultSetHandler处理结果。
- ResultSetHandler会先拿到结果集,然后找到配置的ResultMap。根据ResultMap中配置的type也就是实体类的权限定名,使用ObjectFactory对象工厂使用反射创建对象实例。
- 再接着就会拿到ResultMap总映射的列,找到对应的TypeHanlder拿到值,使用反射赋值给对象实例。最后返回对象列表。
最后我花了一个流程图
如果文章对你有所帮助,请一定去给我一个五星好评,博主在参加博客之星评比,点击链接 , https://bbs.csdn.net/topics/603957267 疯狂打Call!五星好评 ⭐⭐⭐⭐⭐ 感谢。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/10609.html

