

文章目录
- **一、基础知识:**
-
- **1、yarn:资源调度框架**
- **2、hdfs(Hadoop Distribute File System),基于“磁盘”的**
- **3、Hadoop MR:map ->shuffle -> reducer**
- **4、Hive:是一个数据仓库**
- **5、spark与MR区别?**
- **6、java中SparkConf设置参数介绍**
- **7、RAM = 内存**
- 8、Spark任务提交**
- **9、spark任务流程及算子**
- **11、算子**
- 12、standalone
- **13、yarn**
- **15、spark pipeline计算模式**
- **16、spark资源调度和任务调度**
- **17、ETL?= 抽取+转换+加载**
- **20、kafka**
- **21、spark历史**
- **22、spark内置模块**
- **23、Spark WordCount**
- **24、Spark RDD**
- **25、** **sparkSQL**
- **26、SparkStream**
- **二、面试题**
-
-
- 1.概述一下spark中常用算子区别(map,mapPartitions, foreach, foreachPartition)
- 2.map与flatMap的区别
- 3.RDD有哪些缺陷?
- 4.spark有哪些组件?
- 5.什么是粗粒度,什么是细粒度,各自的优缺点是什么?
- 6.driver的功能是什么?
- 7.spark中worker的主要工作是什么?
- 8.Spark shuffle时,是否会在磁盘上存储
- 9.spark中的数据倾斜的现象,原因,后果
- 10.spark数据倾斜的处理
- 11.spark有哪些聚合类的算子,我们应该避免什么类型的算子?
- 12.spark中数据的位置是被谁管理的?
- 13.RDD有几种操作类型?
- 14.spark作业执行流程
- 15.spark 的standalone模式和yarn模式的区别?
- 16.spark如何避免数据倾斜?
-
一、基础知识:
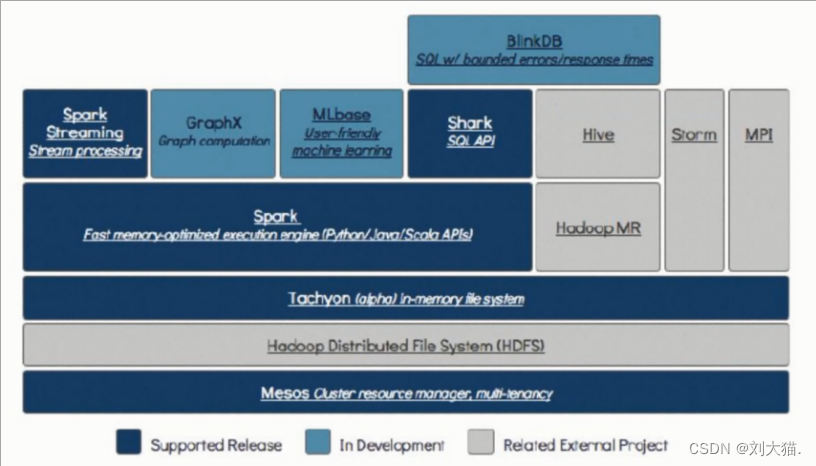
1、yarn:资源调度框架
2、hdfs(Hadoop Distribute File System),基于“磁盘”的
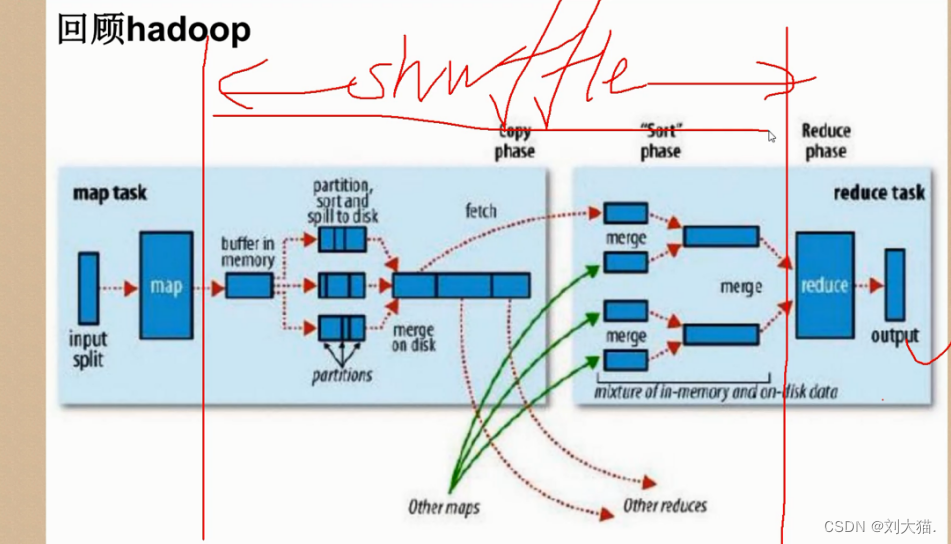
3、Hadoop MR:map ->shuffle -> reducer
注意:有shuffle就会有磁盘IO,就会有不同节点传输
4、Hive:是一个数据仓库
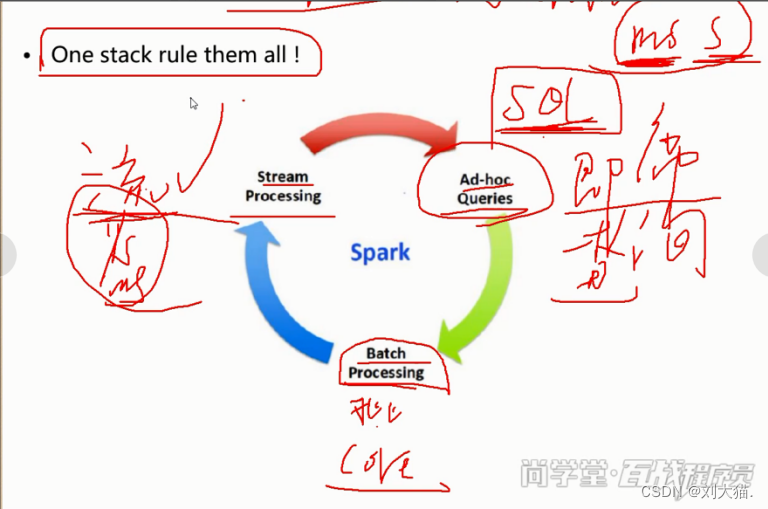
5、spark与MR区别?
1)MR基于磁盘,spark基于内存(指某些步骤基于内存,而不是全部基于内存)
2)spark有DAG(有向无环图),eg:一个蛋糕分10块,用10人去吃,或者1个job划分很多小块儿,每一个用小块儿一组task去处理
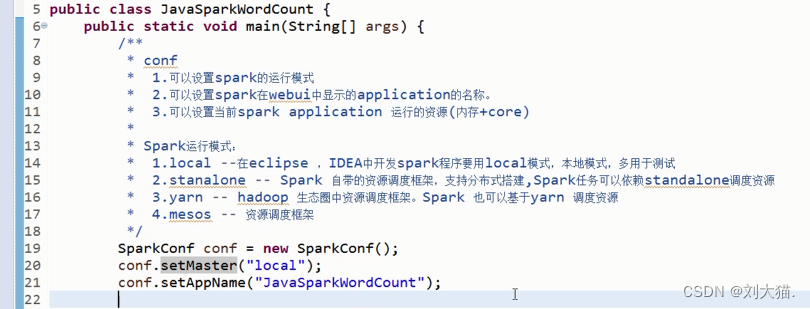
6、java中SparkConf设置参数介绍
7、RAM = 内存
8、Spark任务提交**
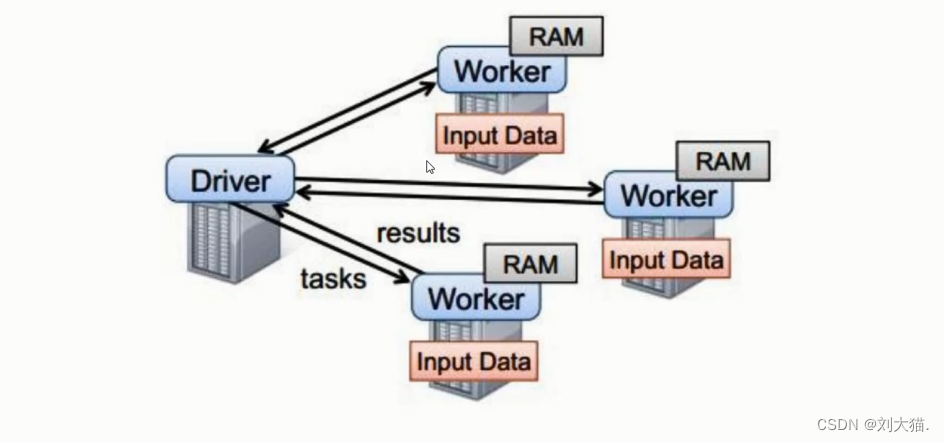
Yarn是hadoop圈里的资源调度框架,它的主节点是resourManager,从节点是nodeManager,standalone是spark自带的资源调度框架,worker就是它的从节点,主节点是master,主节点管理worker从节点。
注意:无论是master还是work都是一个jvm进程
1个application会去创建一个driver的jvm进程 -> 然后driver会向集群中worker发送task并回收results,结果保存在driver的JVM内存中,如果results过大,不建议存回收到driver中,会出现OOM问题(Out Of Memory:内存溢出问题)。
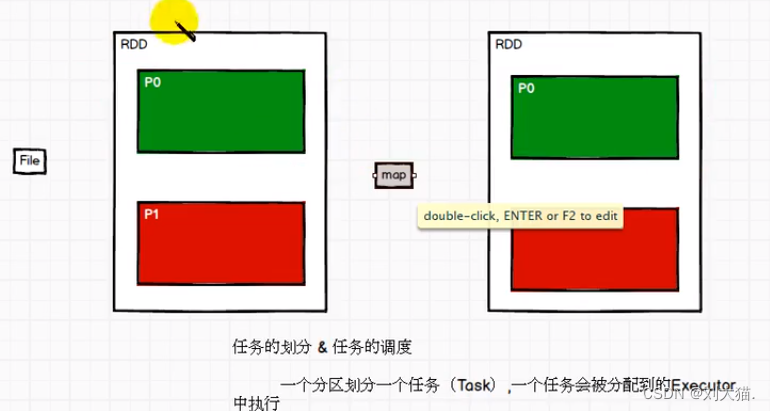
9、spark任务流程及算子

总结上图:Transformation算子 RDD -> RDD
Action算子 RDD -> 非RDD
流程:
sparkConf -> sparkContext(是通往集群的唯一通道) -> 加载RDD -> 对RDD使用Transformation算子对数据进行转换 -> Action触发执行Transformation算子 -> 最后关闭
注意:Transformation算子属于“懒加载”,其中“懒加载”算子指的是它不会去执行,必须由Action触发执行。
(Action算子:foreach()、count()、first(0、take(int)),take(x)用于取前x行
一个application包含多个job,其中job数量决定于Action算子多少。
11、算子


Persist():可以设置持久化级别


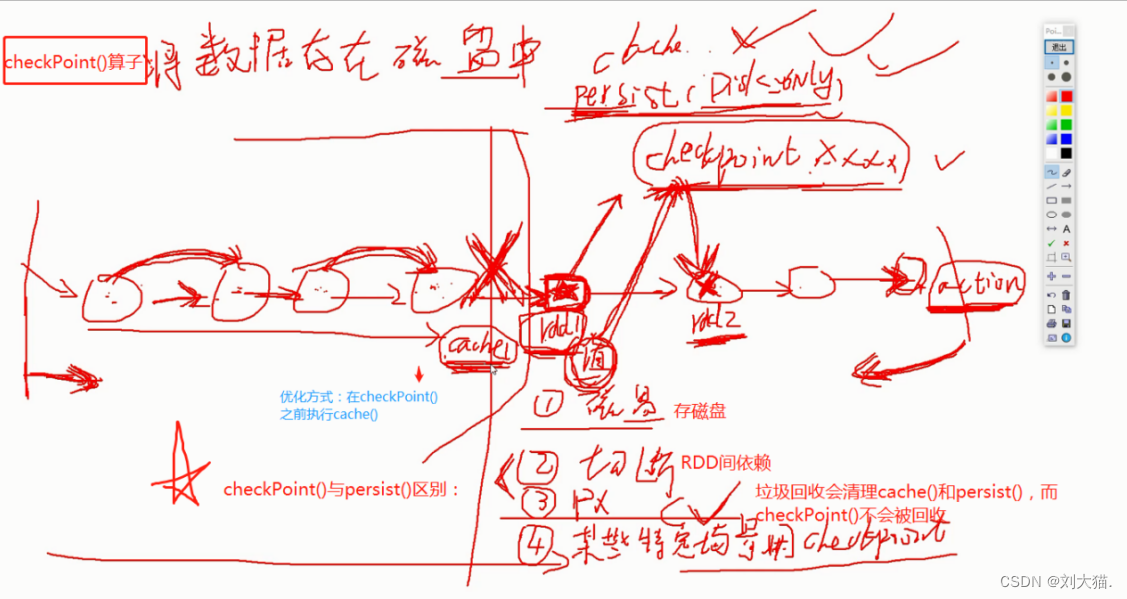
注意:cache()、persist()、checkPoint()都是懒加载算子,需要Action算子触发执行
12、standalone
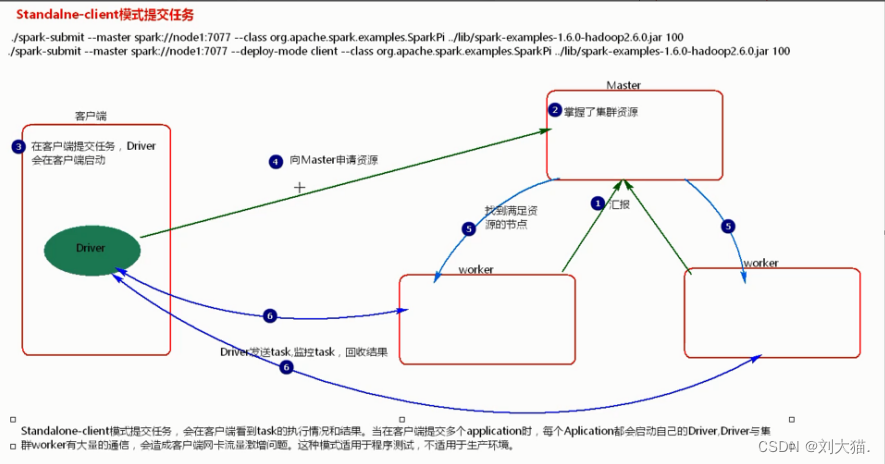
12.1 standalone-clent模式提交任务流程
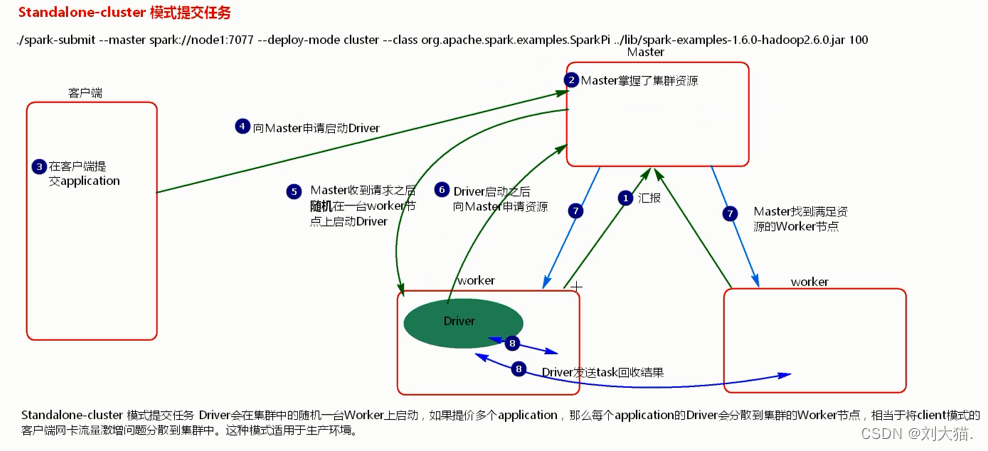
12.2 standalone-cluster 模式提交任务流程
13、yarn
13.1 yarn-client模式提交任务流程
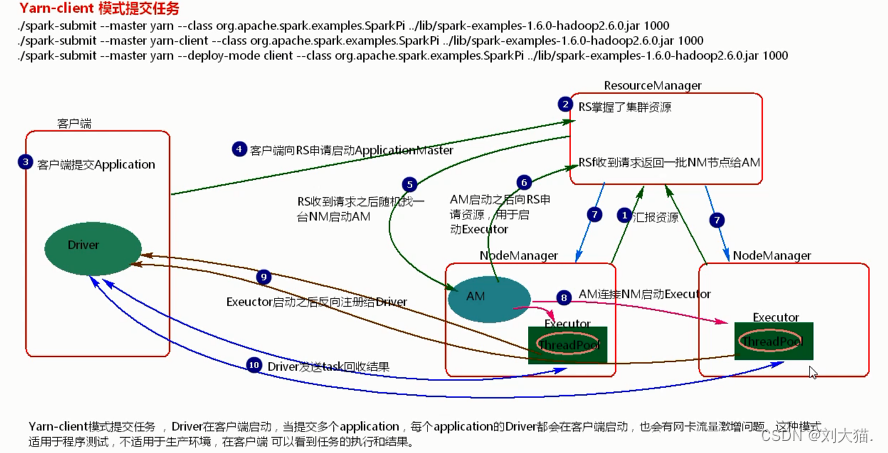
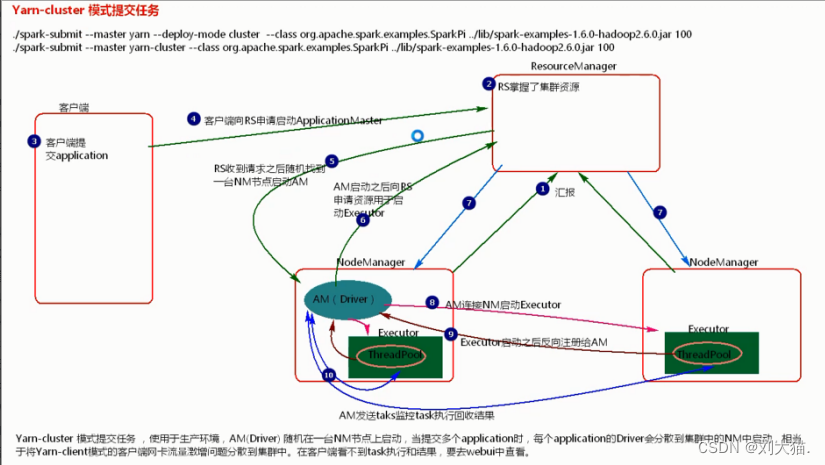
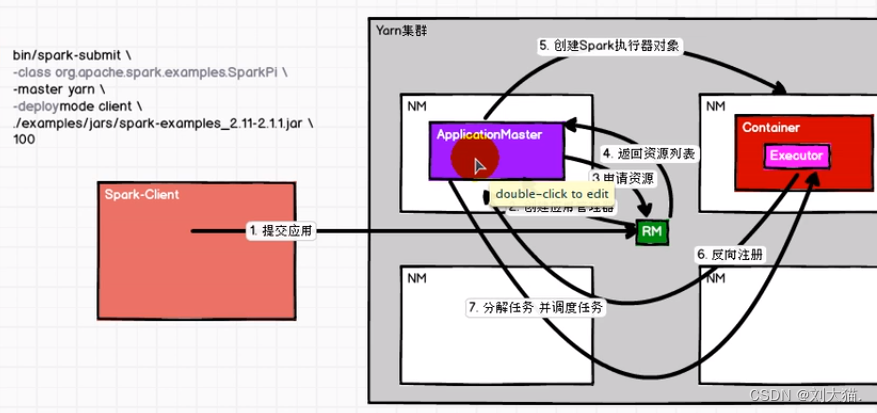
13.2 yarn-cluster模式提交任务流程
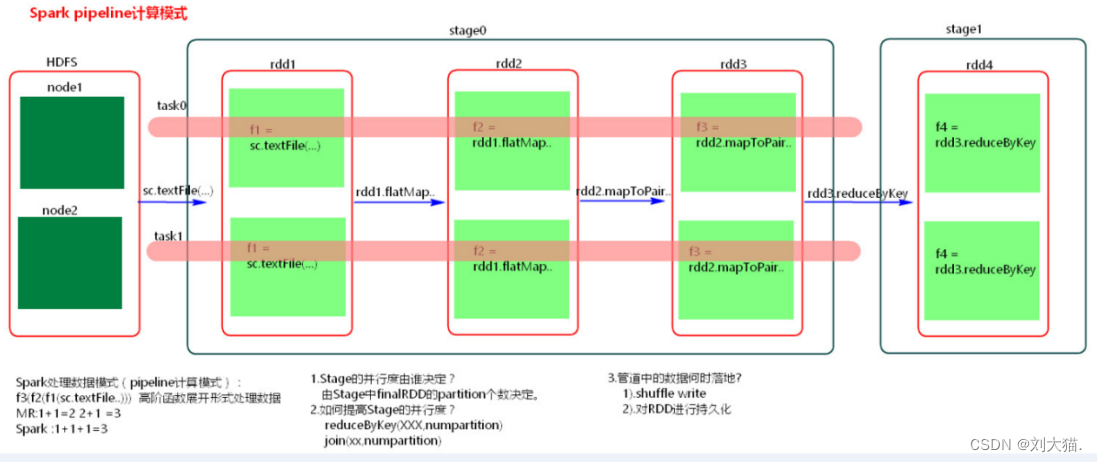
15、spark pipeline计算模式
16、spark资源调度和任务调度
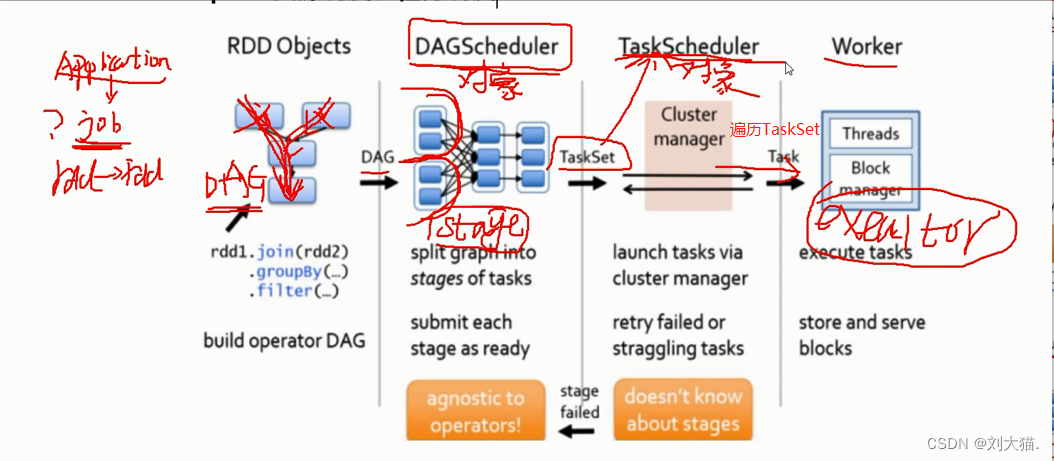
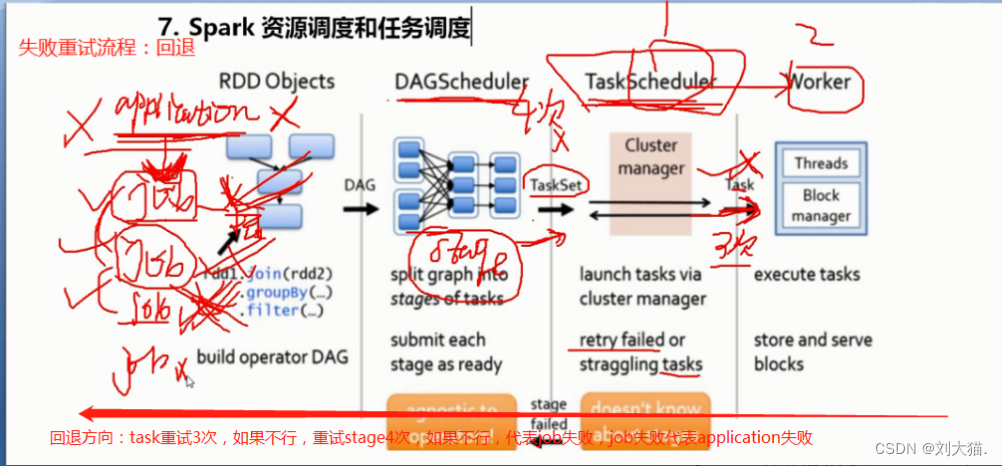
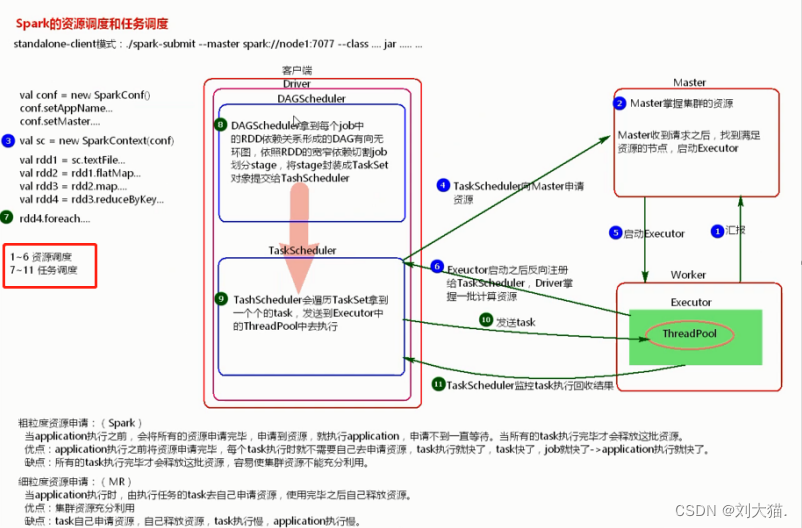
17、ETL?= 抽取+转换+加载
ETL = extract + transform + load
用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程。
20、kafka
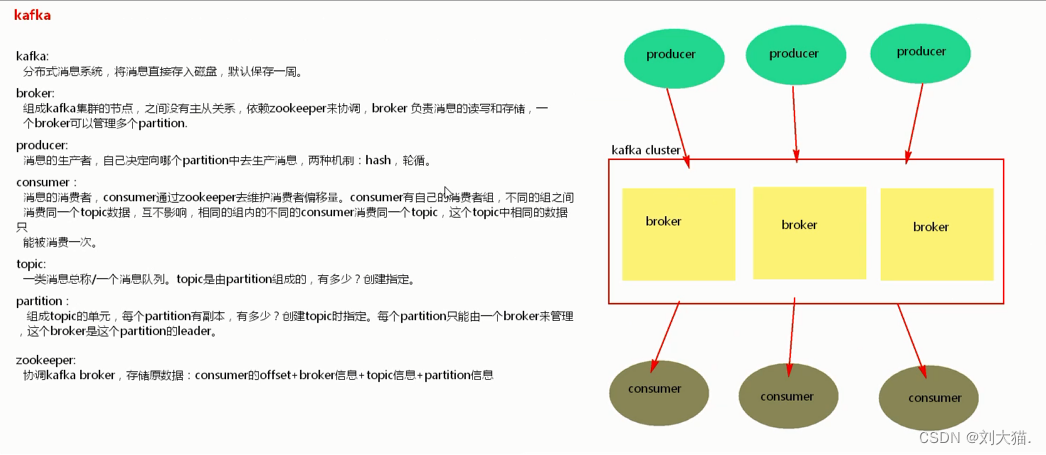
20.1 kafka概述
20.2 定义

20.3 消息队列
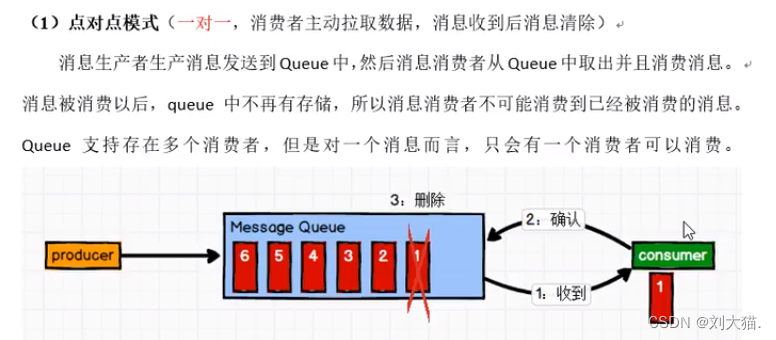
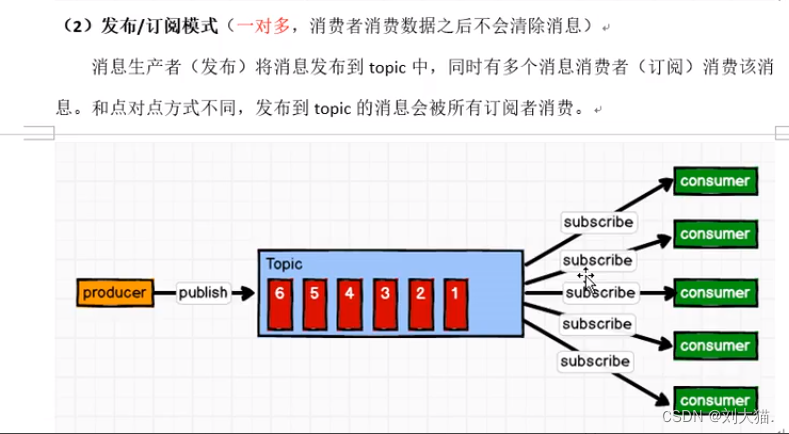
20.4 kafka架构
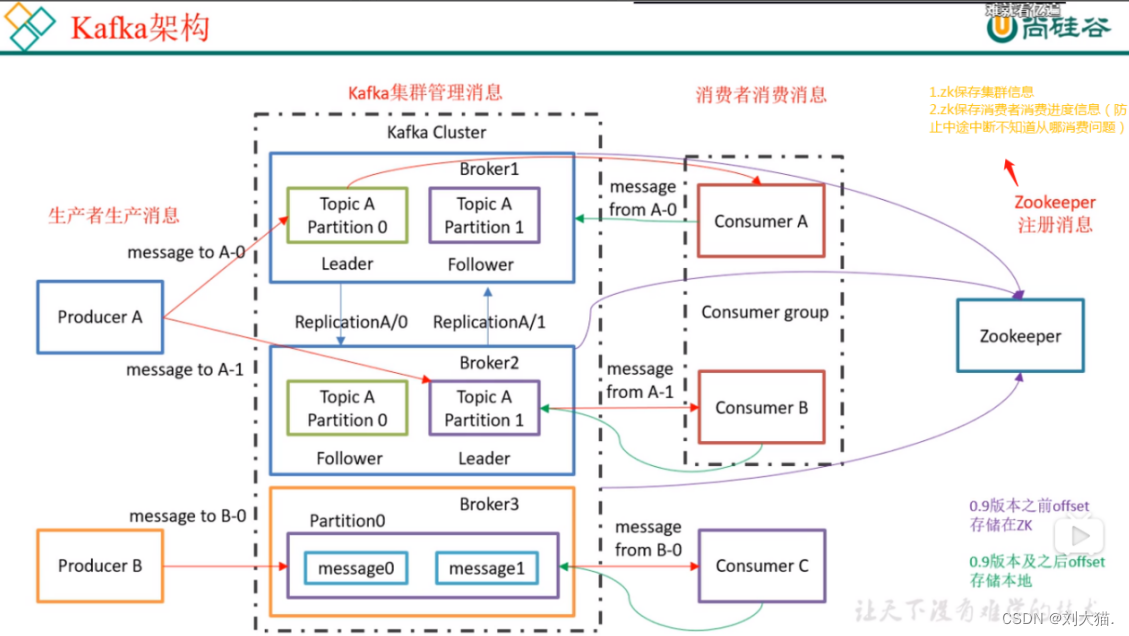
20.5 kafka生产者
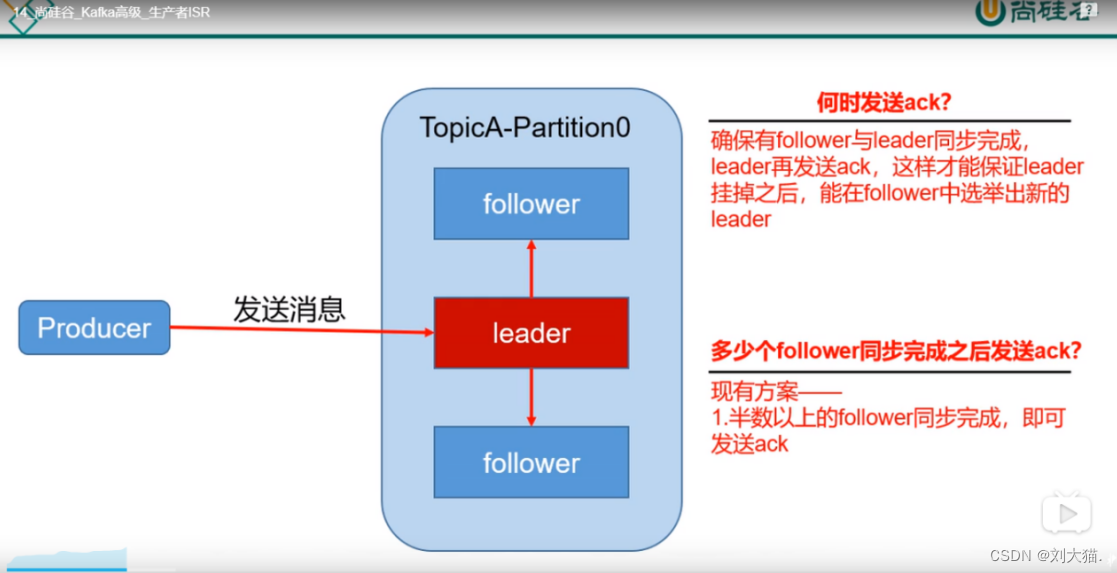
20.6 ack和isr
Ack:决定数据丢不丢,分0/1/-1 3个级别
Isr:存储和消费一致性 hw 和leo
ISR全称是“In-Sync Replicas”,也就是保持同步的副本,他的含义就是,跟Leader始终保持同步的Follower有哪些。
spring.kafka.producer.acks=1
https://blog.csdn.net/zhongqi2513/article/details/90476219
21、spark历史
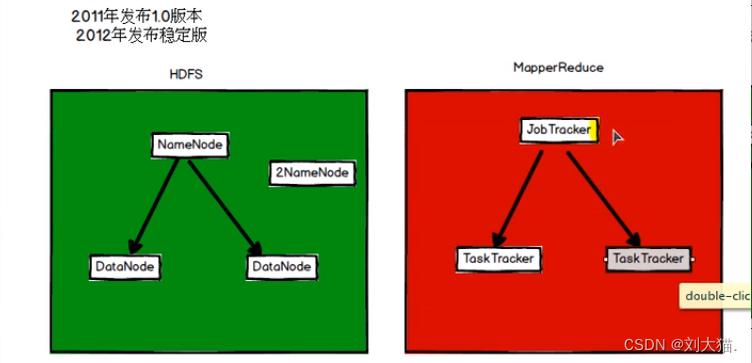

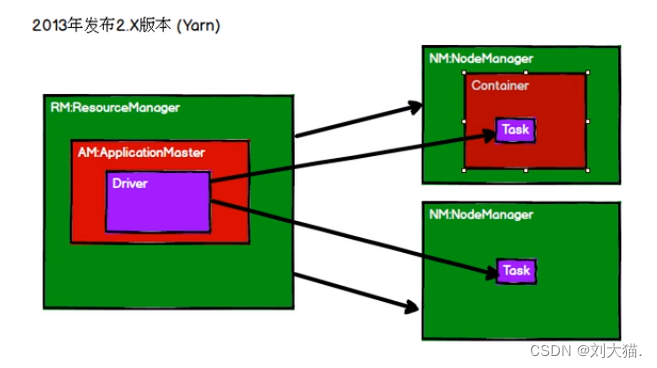


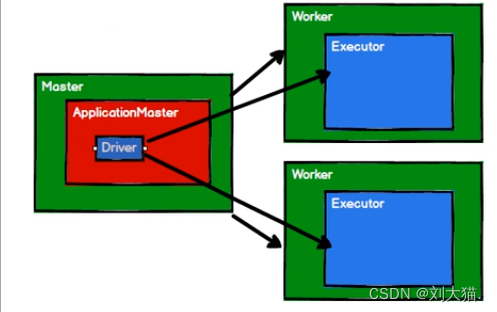
22、spark内置模块
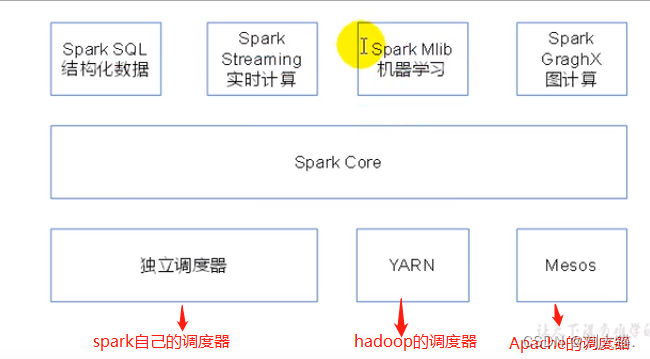
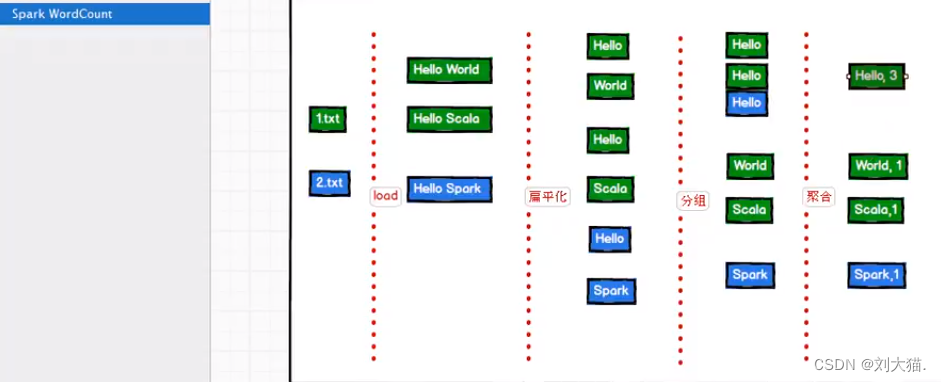
23、Spark WordCount
24、Spark RDD
24.1 介绍流
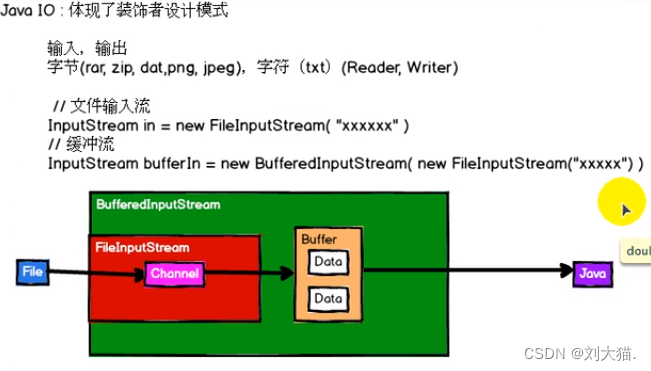
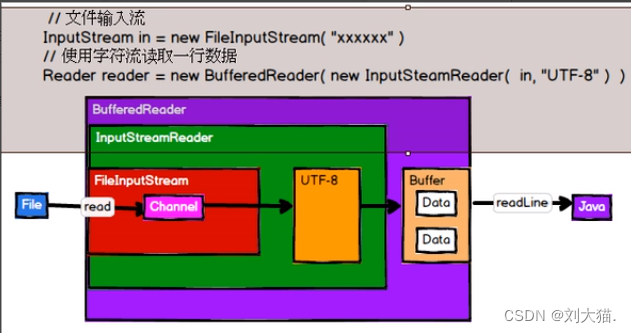
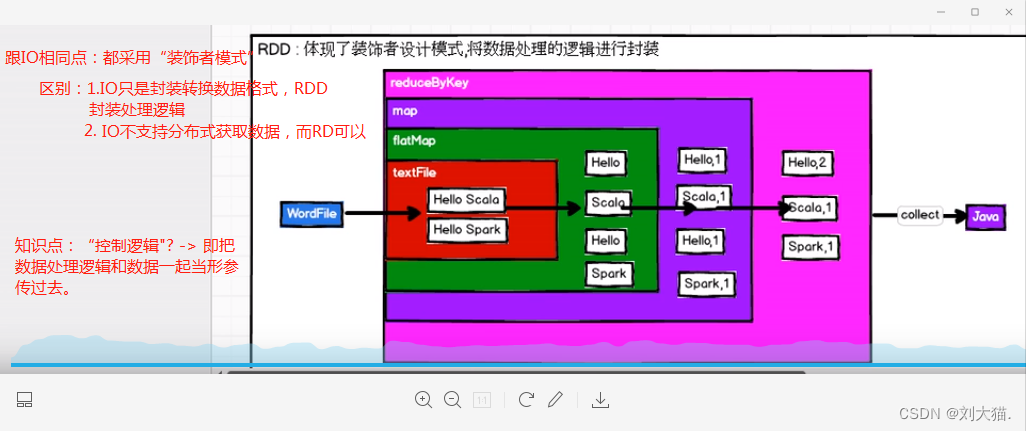
24.2什么是RDD

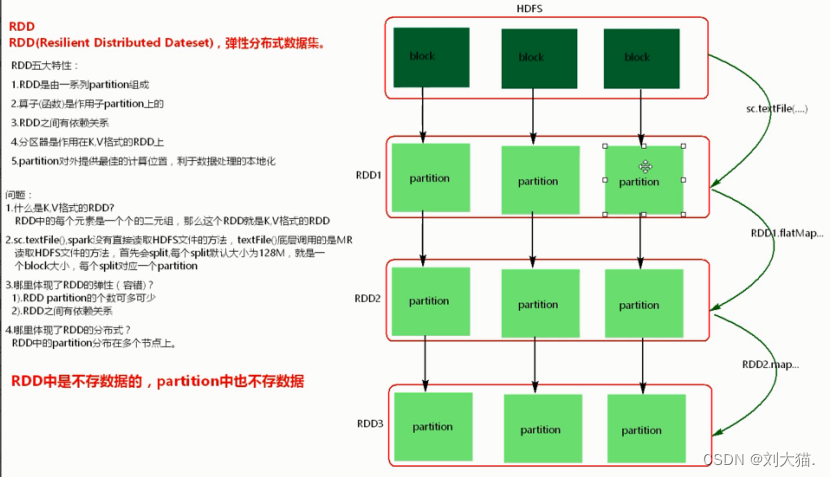
注意:RDD中partition的数量由父类的bolck数量决定,而RDD2的partition数量由父类RDD1的partition数量决定

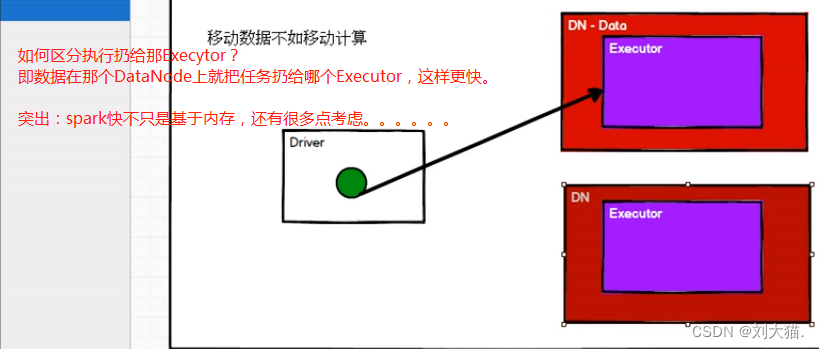
24.3 RDD属性

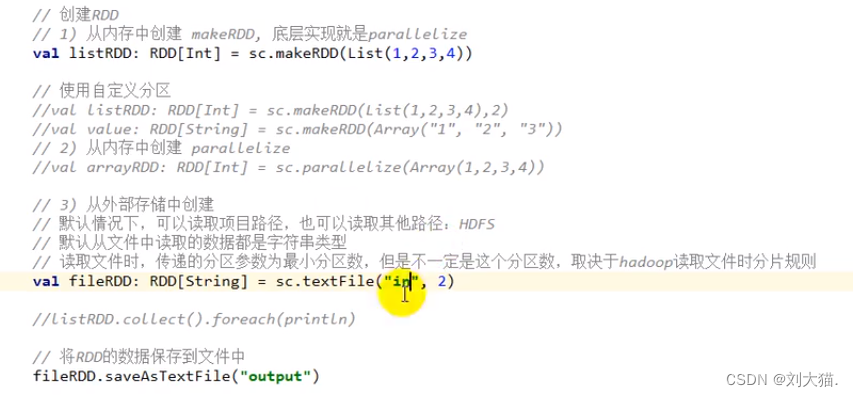
24.4 RDD创建

24.5 RDD的转换
第一种: Value类型交互
map算子



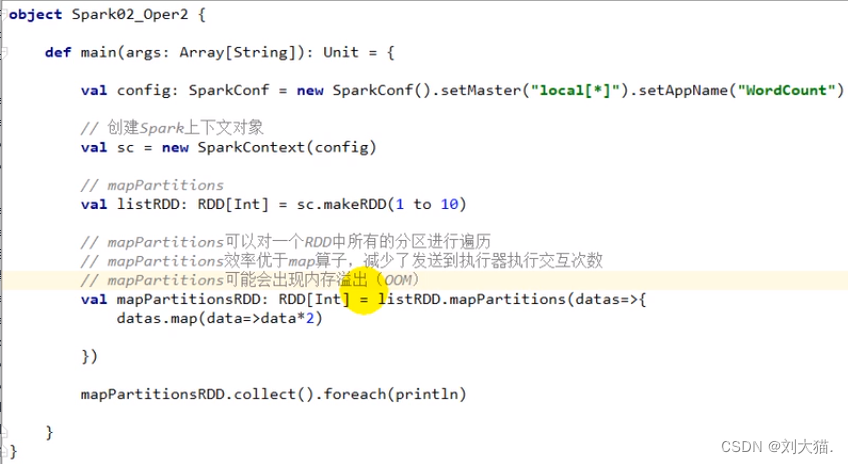
mapPartitions算子

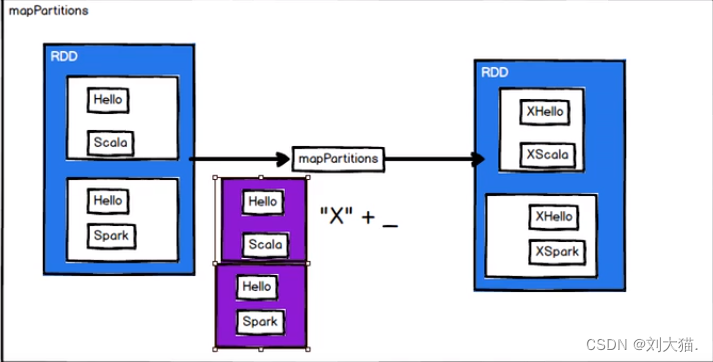
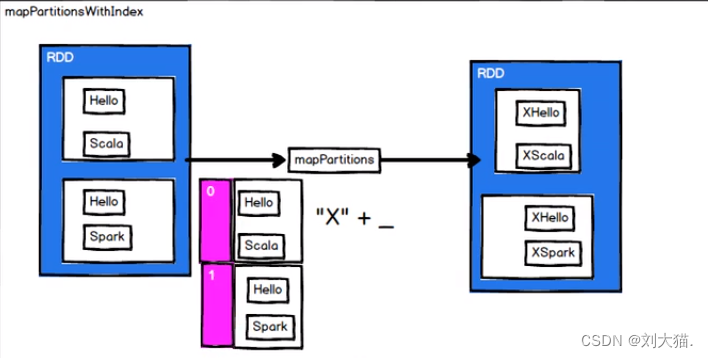
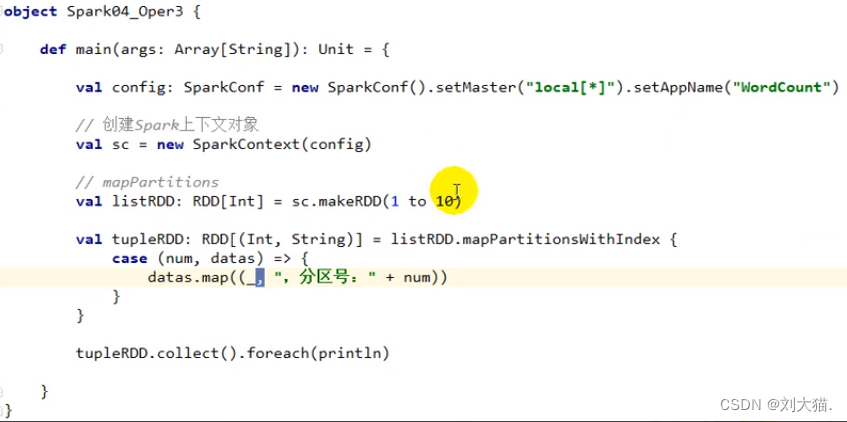
mapPartitionsWithIndex(分区索引)

flatMap

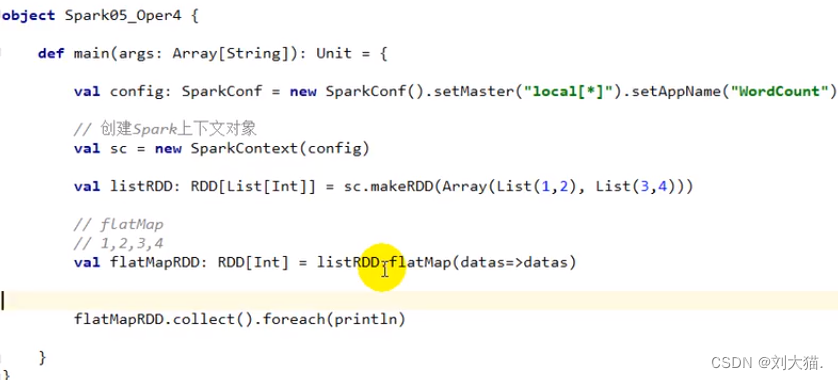
glom算子

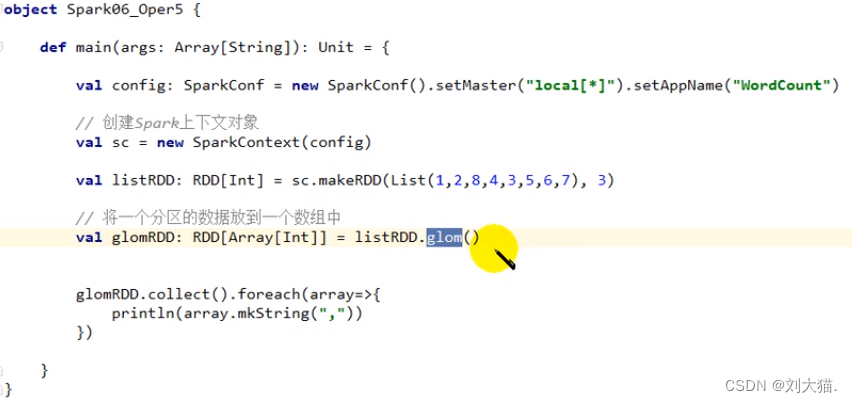
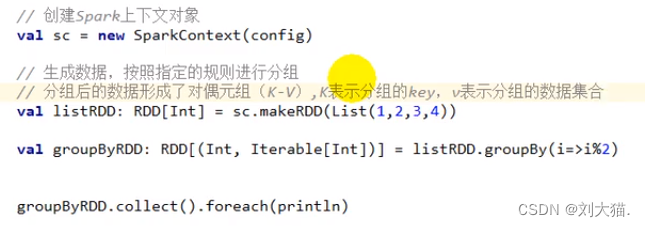
groupBy算子

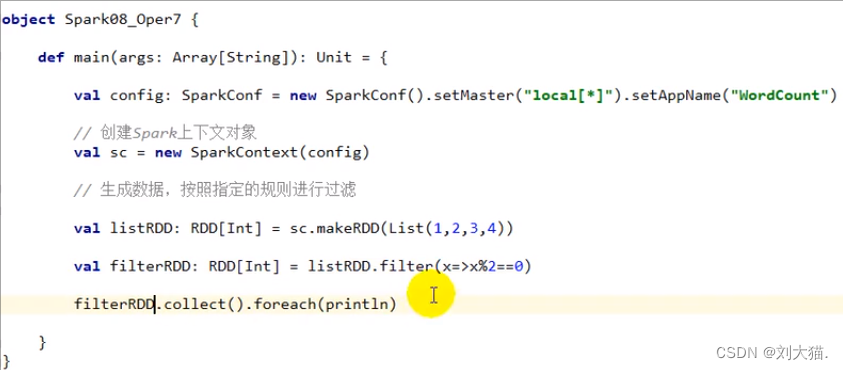
filter算子

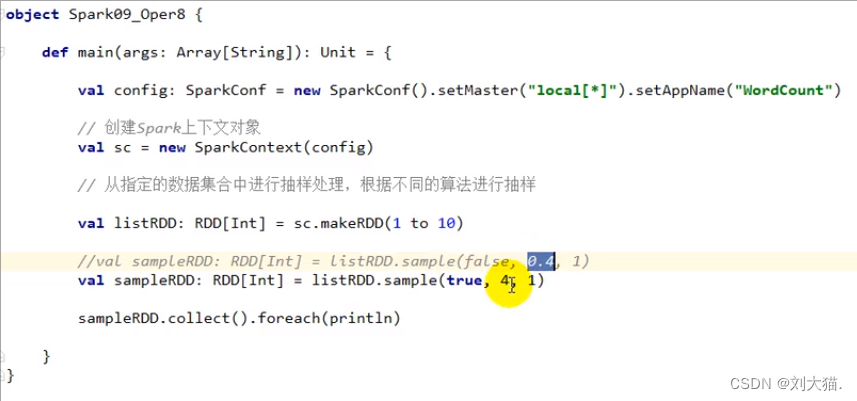
sample算子
注意:seed可理解给数随机打分,fraction代表标准,大于标准留下小于标准舍弃。

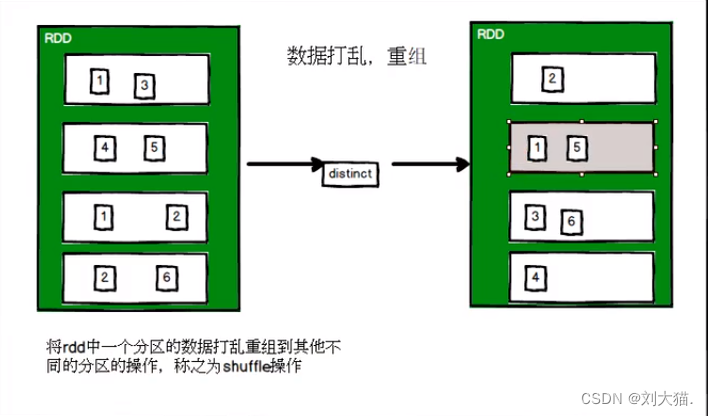
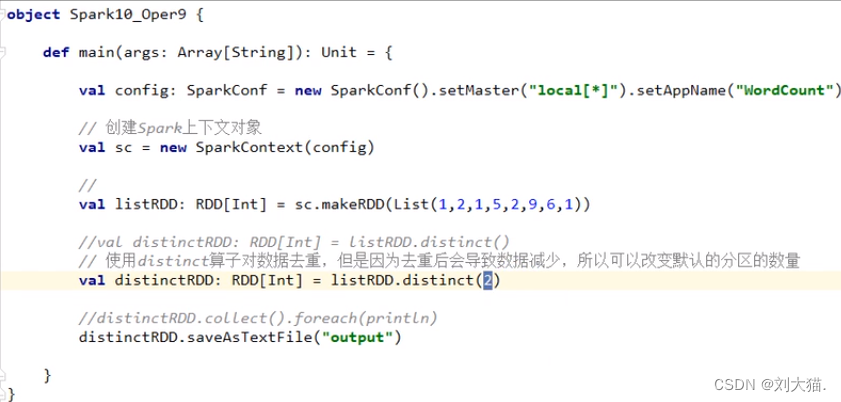
distinct算子

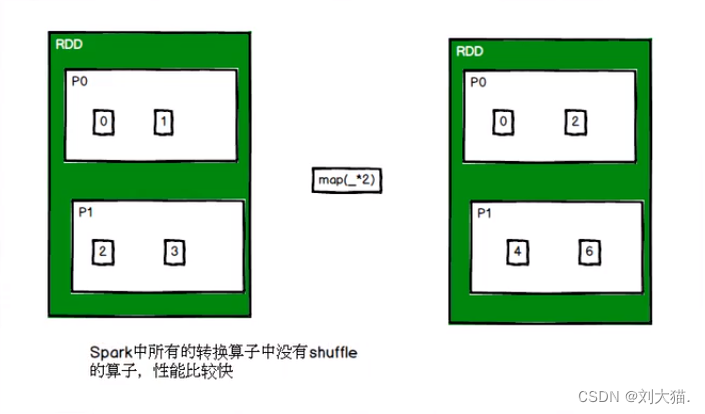
coalesce算子

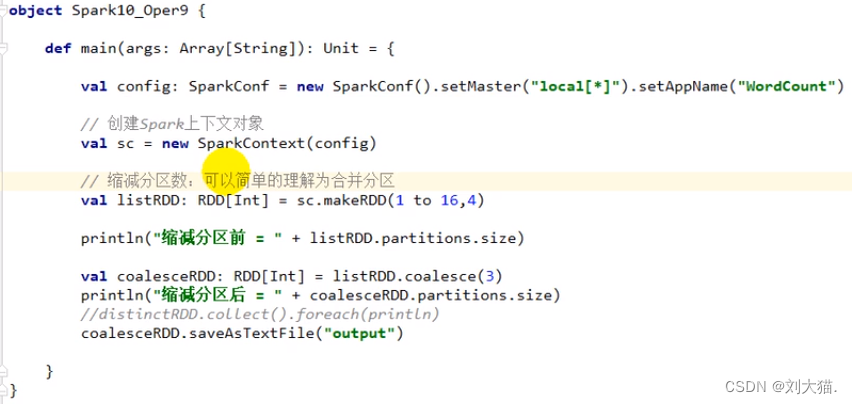
区别partition & task
repartition算子

coalesce 和repartition区别

第二种:双Value类型交互
union算子

subtract算子

intersection算子

zip算子

partitionBy算子


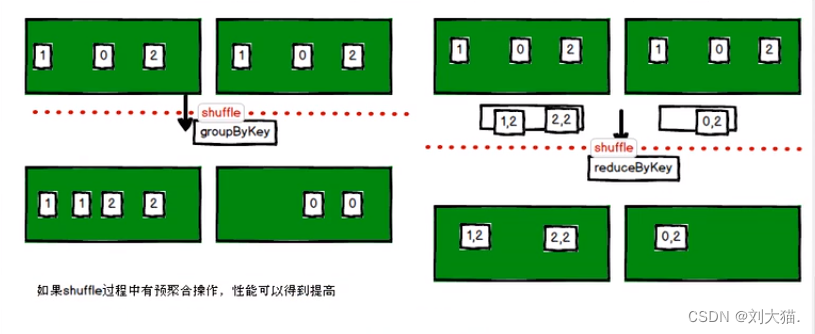
groupByKey算子

reduceByKey算子

区别reduceByKey和groupByKey


aggregateByKey算子


foldByKey算子

combinByKey算子

sortByKey算子

mapValues算子

cogroup算子

第三种:action算子
reduce算子

collect算子

count算子

first算子

take算子

takeOrdered算子

aggregate算子

fold算子

saveAsTextFile算子

SaveAsSequenceFile算子

saveAsObjectFile算子

countByKey算子

foreach算子

24.6 RDD编程进阶
1.累加器


举例求和,思考为什么?
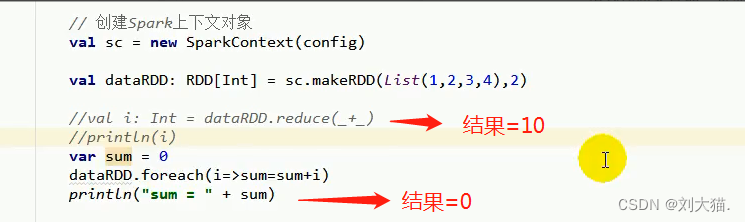
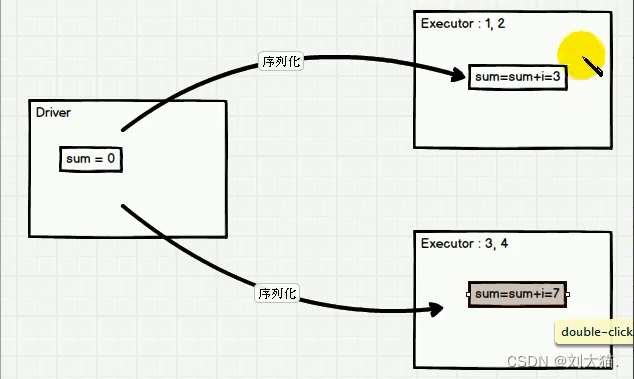
答案:因为没有回传,所以sum一直为0
另一种实现方式 -> 创建累加器

2.广播变量

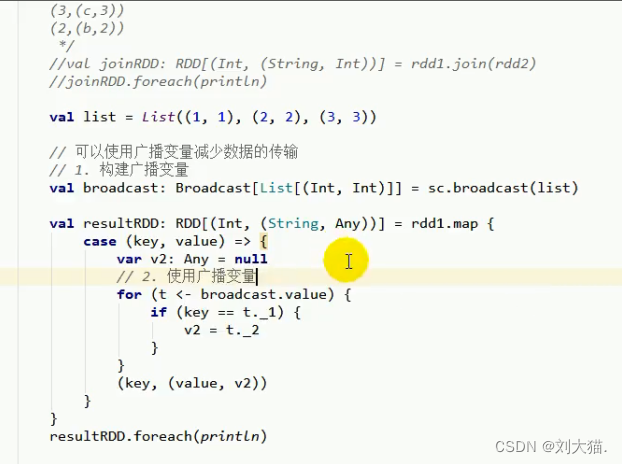
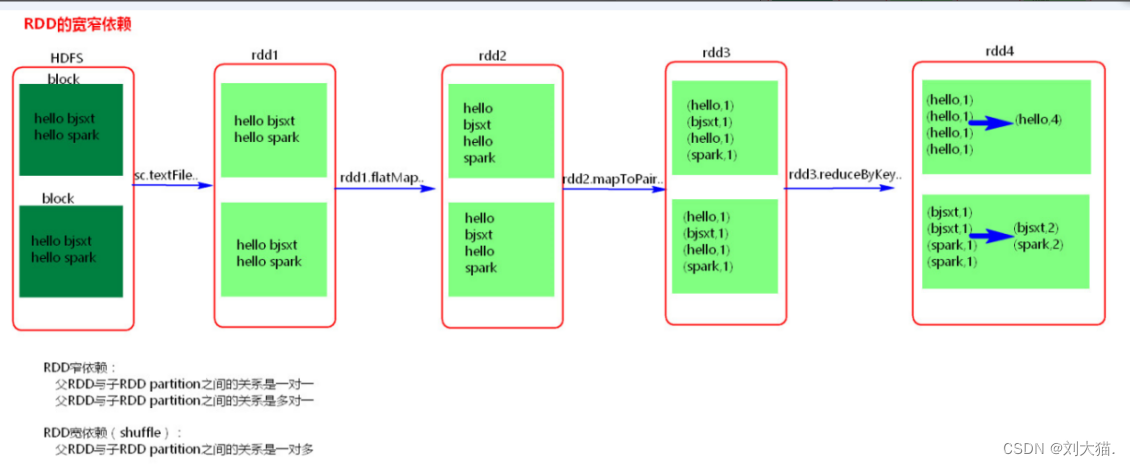
24.7 RDD的宽窄依赖
25、 sparkSQL
25.1 什么是sparkSQL

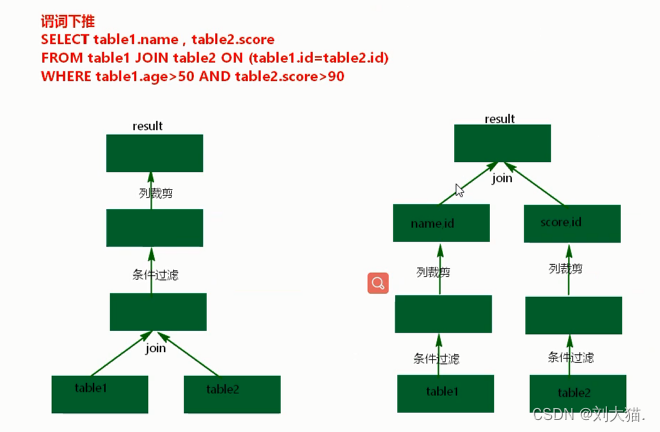
25.2 谓词下推
25.3 创建DataFrame
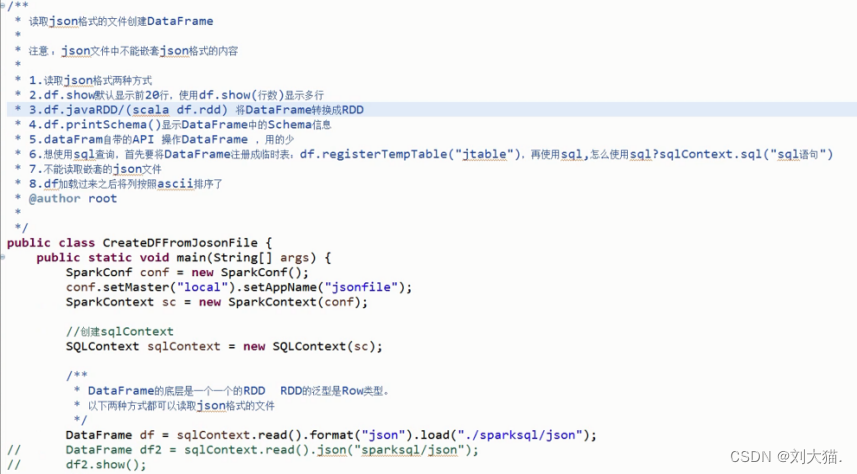

25.4 scala中RDD、DataFrame、DataSet转换
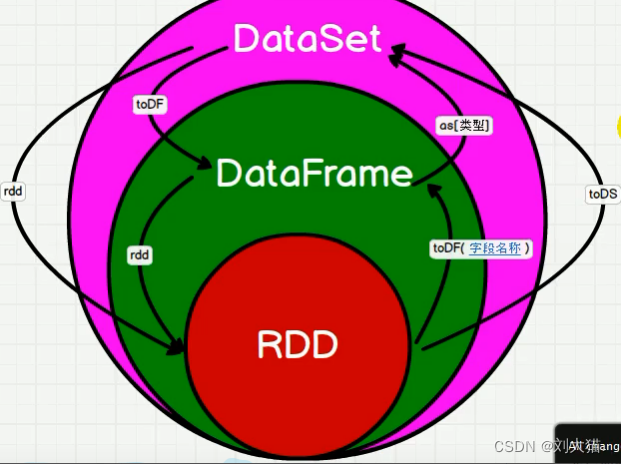




25.5 java中RDD、DataFrame、DataSet转换
rdd -createDataFrame()-》df -as(personEncoder)-》ds -toDf()-》df -rdd()-》rdd
public static void main(String[] args) throws AnalysisException {
SparkSession spark = SparkSession
.builder()
.master("local")
.appName("SparkSQL")
.getOrCreate();
JavaSparkContext sc = JavaSparkContext.fromSparkContext(spark.sparkContext());
User user1 = new User("damao", 20);
User user2 = new User("cat", 18);
List<User> list = Arrays.asList(user1, user2);
//创建RDD
JavaRDD<User> userRDD = sc.parallelize(list);
//1.rdd<User> -> dataset<Row>
/*
createDataFrame 必须RDD泛型为对象而不是row
*/
Dataset<Row> datasetRow = spark.createDataFrame(userRDD, User.class);
datasetRow.show();
//2.Dataset<Row> -》 RDD<Row>
RDD<Row> rdd = datasetRow.rdd();
/*
使用createDataset 必须RDD泛型为对象而不是row
*/
Encoder<User> personEncoder = Encoders.bean(User.class);
Dataset<User> dataset = spark.createDataset(userRDD.rdd(), personEncoder);
dataset.show();
//Dataset<Row> -> Dataset<User>
Dataset<User> datasetUser = datasetRow.as(personEncoder);
//3.Dataset<User> -》 RDD<User>
RDD<User> rddUser = datasetUser.rdd();
//4.Dataset<User> -》 Dataset<Row>
Dataset<Row> datasetRow2 = datasetUser.toDF();
spark.stop();
}
25.6 sparkSQL数据源
1.通用加载/保存方法




2. JSON 文件

3.Parquet文件

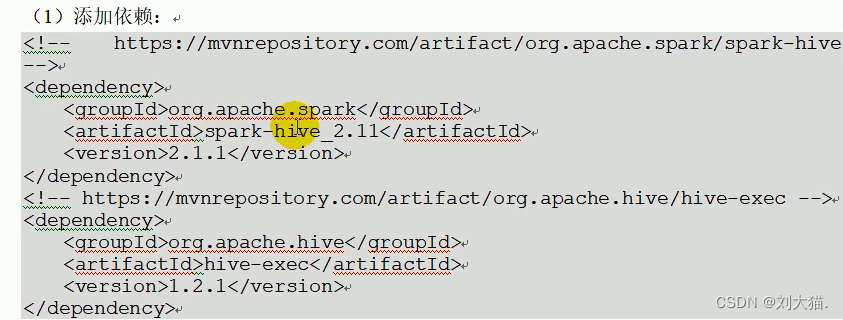
4.JDBC
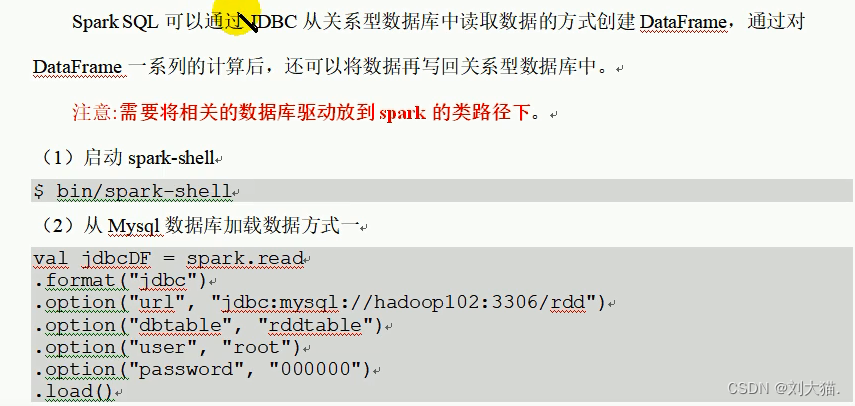
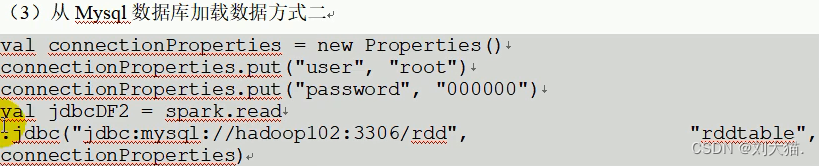
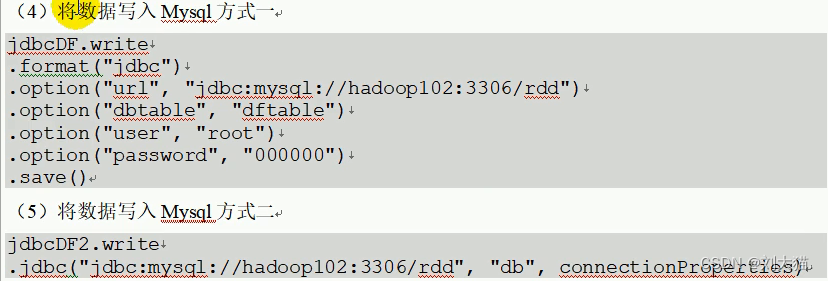
5.Hive数据库

26、SparkStream
26.1 SparkStream是什么


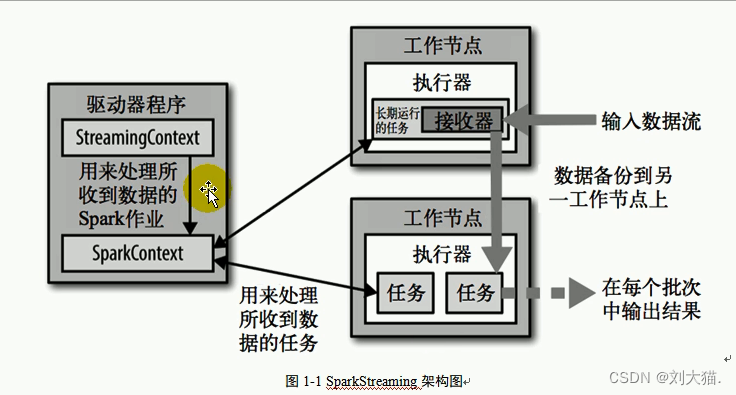
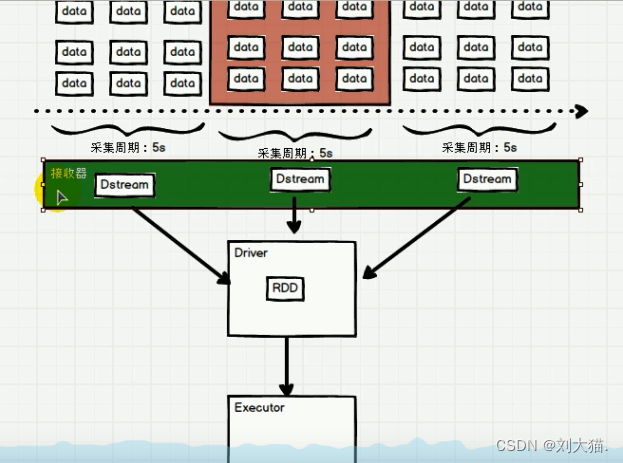
26.2架构
26.3 sparkStream 初始化
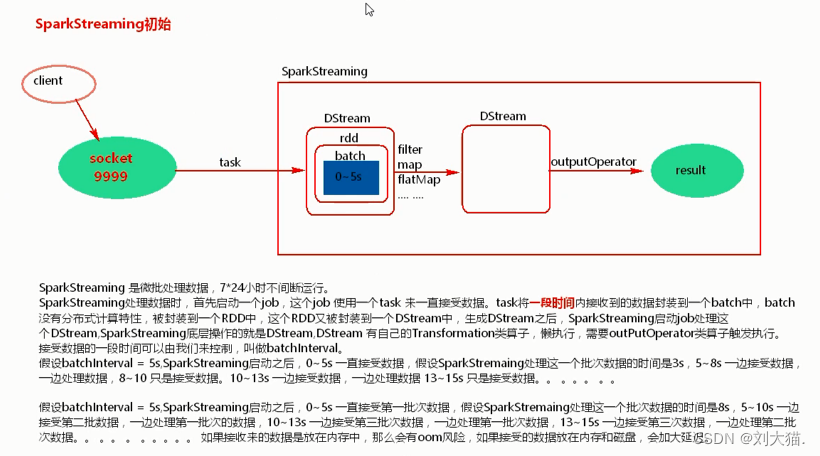
26.4 Dstream创建
1.文件数据源

2.RDD队列

3.自定义数据源

26.4 Dstream转换





二、面试题
1.概述一下spark中常用算子区别(map,mapPartitions, foreach, foreachPartition)

2.map与flatMap的区别


3.RDD有哪些缺陷?

4.spark有哪些组件?

5.什么是粗粒度,什么是细粒度,各自的优缺点是什么?

6.driver的功能是什么?

7.spark中worker的主要工作是什么?

8.Spark shuffle时,是否会在磁盘上存储
答:会
9.spark中的数据倾斜的现象,原因,后果

10.spark数据倾斜的处理

11.spark有哪些聚合类的算子,我们应该避免什么类型的算子?


12.spark中数据的位置是被谁管理的?

13.RDD有几种操作类型?

14.spark作业执行流程

15.spark 的standalone模式和yarn模式的区别?

16.spark如何避免数据倾斜?
原因3点:1.null或者无效数据 2.无意义值,大量重复数据 3.有效数据
→ https://www.cnblogs.com/weijiqian/p/14013292.html
如果是前两种处理数据或者过滤即可,如果是第三种,则详细讨论,
方案一:提高suffle并行度

方案二:自定义Partitioner


方案三:将Reduce side Join转变为Map side Join

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/106305.html

