
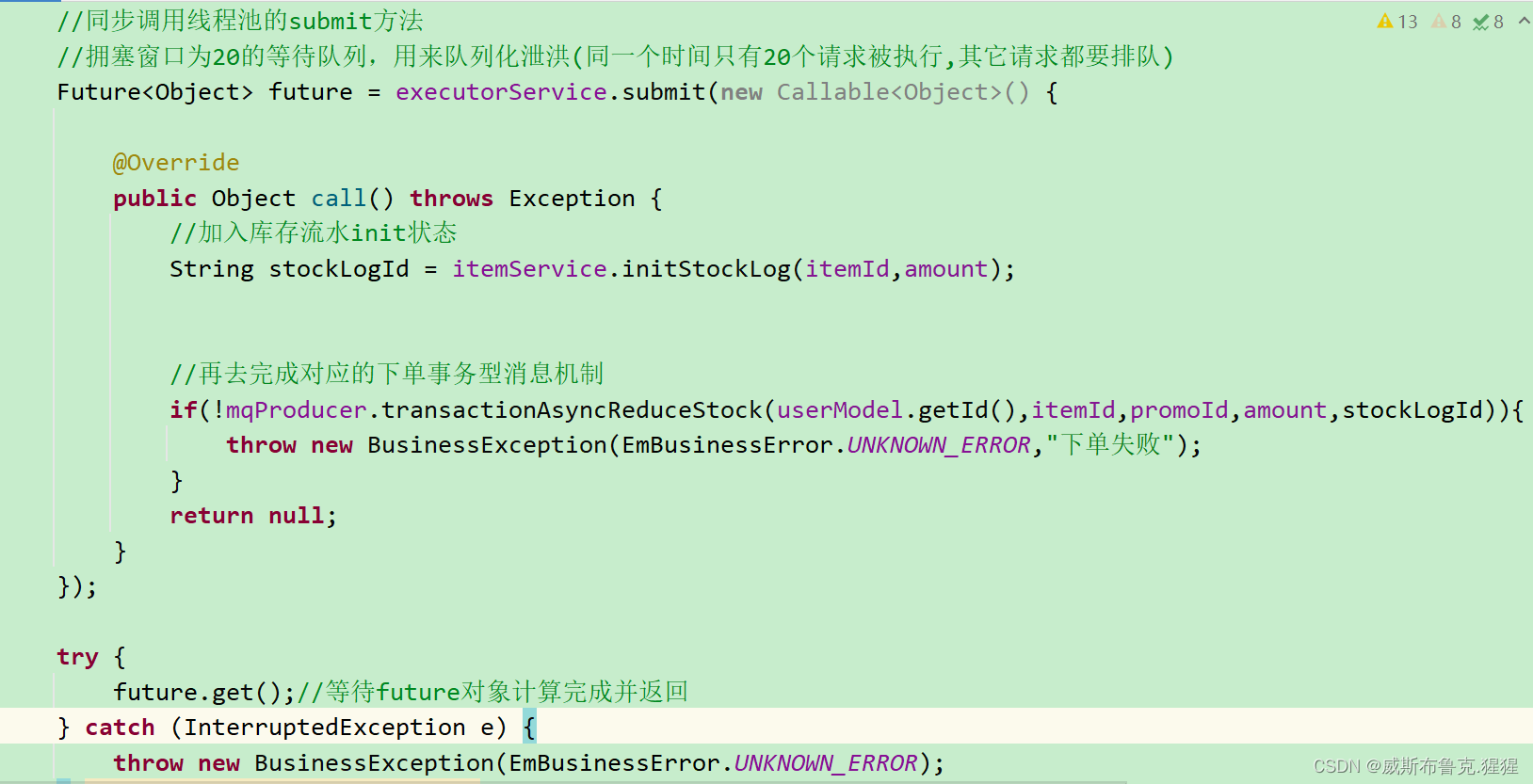
线程池
项目中使用Executors的方式创建定长为20的线程,意味着使用了线程池后同一个时刻只能处理20个请求,其余的请求都会放入阻塞队列中进行排队;在此系统的设计中如果请求量超出了阻塞队列承受范围,多出的这些请求如果系统都无法承载这些量,如果不拒绝处理系统就挂了,所以设计上秉承着宁可拒绝保证系统正常运行也不能让系统挂掉。
具体的分析:线程池中有一个等待队列,就是用blockqueue实现的,将任务提交给线程池,线程池中可执行线程沾满后会将任务放到等待队列中,这样做就等于是限制了用户并发的流量,使得其在线程池的等待队列中排队处理。
代码解析:
在这里使用Future是为了让前端用户在调用Controller后可以同步的获得执行的结果;因为Callable是可以异步的返回计算结果。具体的代码实现是将要下单处理的流程使用
submit()方法向线程池中添加任务;submit()有返回值,返回值对象是Future。submit执行的任务,可以通过Future对象的get方法接收抛出的异常,再抛出到异常处理层(本项目对所有异常集中统一处理)。
查看Executors的源码可知,实际还是调用了ThreadPoolExecutor类去构造线程池。
后续对线程池的深层次理解:
如何创建线程池
在《阿里巴巴Java开发手册》中,明确禁止使用Executors创建线程池,并要求开发者直接使用ThreadPoolExector或ScheduledThreadPoolExecutor进行创建。这样做是为了强制开发者明确线程池的运行策略,使其对线程池的每个配置参数皆做到心中有数,以规避因使用不当而造成资源耗尽的风险。
面试官:为什么《阿里巴巴Java开发手册》上要禁止使用Executors来创建线程池 – 掘金
就本项目而言,设置了拥塞窗口的为20的等待队列,在秒杀场景下,很容易堆积大量的请求,系统设计上秉承着宁可拒绝保证系统正常运行也不能让系统挂掉,所以当并发量很大时,现在的秒杀设计其实很容易出现问题的。
本项目中关于线程池中使用不好的点:
FixedThreadPool线程池里的BlockQueue是无界队列,要是线程执行的接口被阻塞会导致BlockQueue无限增加导致内存OOM;具体看下面的文章。
更好的做法:
自定义ThreadPoolExecutor中的corePoolSize,maximumPoolSize,keepAliveTime,还有阻塞队列大小这些参数一般没有固定公式,需要根据硬件、压测情况等的测试结论不断修正的数值
ThreadPoolExecutor pool = new ThreadPoolExecutor(10,30,1, TimeUnit.MINUTES,newArrayBlockingQueue<>(20));线程池在业务中的实践
场景1:快速响应用户请求
描述:用户发起的实时请求,服务追求响应时间。比如说用户要查看一个商品的信息,那么需要将商品维度的一系列信息如商品的价格、优惠、库存、图片等等聚合起来,展示给用户。
分析:从用户体验角度看,结果响应的越快越好,如果一个页面半天都刷不出,用户可能就放弃查看这个商品了。而面向用户的功能聚合通常非常复杂,伴随着调用与调用之间的级联、多级级联等情况,业务开发同学往往会选择使用线程池这种简单的方式,将调用封装成任务并行的执行,缩短总体响应时间。另外,使用线程池也是有考量的,这种场景最重要的就是获取最大的响应速度去满足用户,所以应该不设置队列去缓冲并发任务,调高corePoolSize和maxPoolSize去尽可能创造多的线程快速执行任务。
场景2:快速处理批量任务
描述:离线的大量计算任务,需要快速执行。比如说,统计某个报表,需要计算出全国各个门店中有哪些商品有某种属性,用于后续营销策略的分析,需要查询全国所有门店中的所有商品,并且记录具有某属性的商品,然后快速生成报表。
分析:这种场景需要执行大量的任务,希望任务执行的越快越好。这种情况下,也应该使用多线程策略,并行计算。但与响应速度优先的场景区别在于,这类场景任务量巨大,并不需要瞬时的完成,而是关注如何使用有限的资源,尽可能在单位时间内处理更多的任务,也就是吞吐量优先的问题。所以应该设置队列去缓冲并发任务,调整合适的corePoolSize去设置处理任务的线程数。在这里,设置的线程数过多可能还会引发线程上下文切换频繁的问题,也会降低处理任务的速度,降低吞吐量。
实际问题及方案思考
线程池使用面临的核心的问题在于:线程池的参数并不好配置。一方面线程池的运行机制不是很好理解,配置合理需要强依赖开发人员的个人经验和知识;另一方面,线程池执行的情况和任务类型相关性较大,IO密集型和CPU密集型的任务运行起来的情况差异非常大,这导致业界并没有一些成熟的经验策略帮助开发人员参考。看下面美团技术团队的文章。
面试必备:Java线程池解析 – 掘金 (juejin.cn)——-确实是面试必备
线程池没你想的那么简单(续) – 掘金 (juejin.cn)—->>>
- 执行带有返回值的线程。
- 异常处理怎么办?
- 所有任务执行完怎么通知我?




库存行锁优化
库存行锁优化的好处:
行锁相较于表锁,行锁的的粒度更细,并发度更高,但也意味着更大的锁开销。对于没有行锁的引擎,例如MyISAM来说,同一时间对一个表的更新只能有一个执行。显而易见,处于对秒杀业务高并发度的要求,行锁的出现是必要的。
回顾之前减库存的操作:
<update id="decreaseStock"> update item_stock set stock = stock - #{amount} where item_id = #{itemId} and stock >= #{amount} </update>库存的数量就是stock-amount,条件是商品itemId和stock的大于amount,当给item_id加上唯一索引,这样查询的时候为数据库加上行锁,否则是数据库表锁
为啥给item_id加上唯一索引,查询的时候为数据库就是行锁?
InnoDB和MyISAM的最大不同点有两个:
一:InnoDB支持事务(transaction);
二:默认采用行级锁加锁,这样可以保证事务的一致性;
InnoDB的行锁是针对索引加的锁,不是针对记录加的锁。并且该索引不能失效,否则都会从行锁升级为表锁。
行锁介绍:
行锁的劣势:开销大;加锁慢;会出现死锁
行锁的优势:锁的粒度小,发生锁冲突的概率低;处理并发的能力强
加锁的方式:InnoDB默认采用行级锁加锁。对于UPDATE、DELETE和INSERT语句,InnoDB会自动给涉及数据集加排他锁;对于普通SELECT语句,InnoDB不会加任何锁;当然程序员也可以显示的加锁;
唯一索引存在的快慢问题
唯一索引有个很大的好处,就是查询数据时会比普通索引效率更高,因为基于普通索引的字段查询数据时,当查询到一条数据后,会继续走完整个索引树,因为可能会存在多条字段值相同的数据。 但如果字段上建立的是唯一索引,当找到一条数据后就会立马停下检索,因此本身建立唯一索引的字段值就具备唯一性。
但插入数据时就不同了,因为要确保数据不重复,所以插入前会检查一遍表中是否存在相同的数据。但普通索引则不需要考虑这个问题,因此普通索引的数据插入会快一些。但秒杀场景下更多的是查询操作,所以唯一索引很适合。
唯一索引在创建时,需要通过UNIQUE关键字创建
CREATE UNIQUE INDEX indexName ON tableName (columnName(length));
主键索引其实是一种特殊的唯一索引,但主键索引却并不是通过UNIQUE关键字创建的,而是通过PRIMARY关键字创建:
ALTER TABLE tableName ADD PRIMARY KEY indexName(columnName);
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/110900.html

