
tomcat容器配置优化
tomcat连接池
连接池有两个最重要的配置:
最小连接数和最大连接数,
它们控制着从连接池中获取连接的流程:如果当前连接数小于最小连接数,则创建新的连接处理数据库请求;如果连接池中有空闲连接则复用空闲连接;如果空闲池中没有连接并且当前连接数小于最大连接数,则创建新的连接处理请求;如果当前连接数已经大于等于最大连接数,则按照配置中设定的时间等待旧的连接可用; 如果等待超过了这个设定时间则向用户抛出错误。池化技术,减少频繁创建数据库连接的性能损耗:
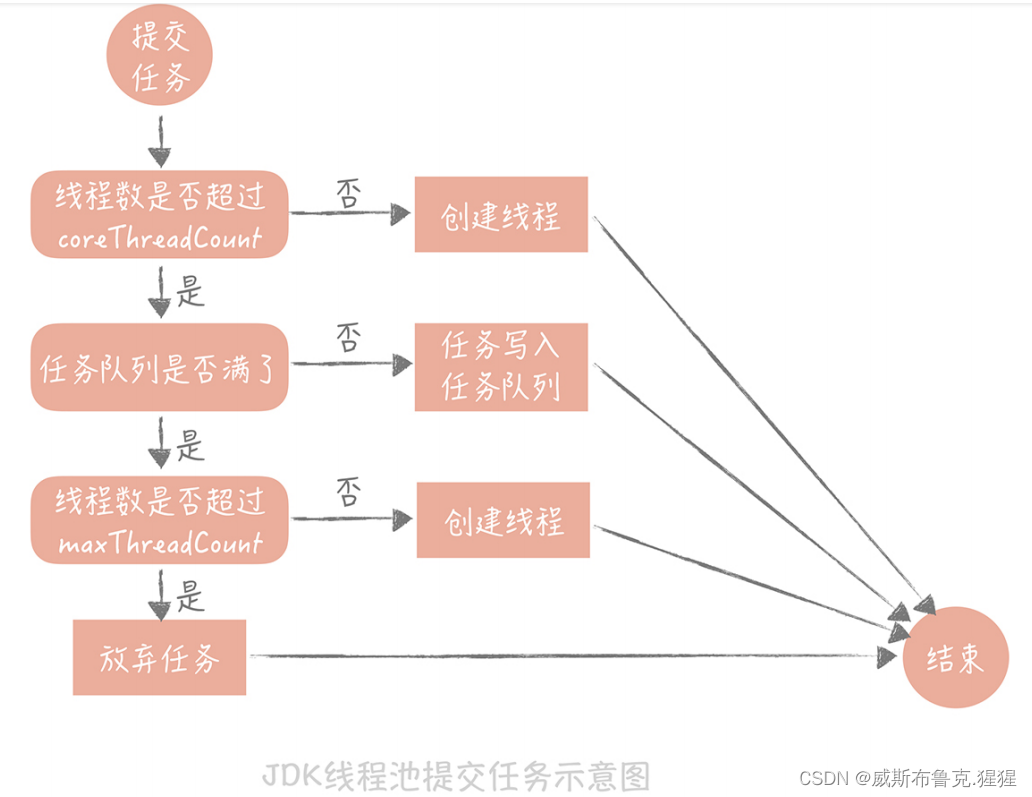
在高并发阶段,频繁创建线程的开销也会很大, 使用线程池预先创建线程;JDK 1.5 中引入的 ThreadPoolExecutor 就是一种线程池的实现,它有两个重要的参数:coreThreadCount 和 maxThreadCount,这两个参数控制着线程池的执行过
程:如果线程池中的线程数少于 coreThreadCount 时,处理新的任务时会创建新的线程;如果线程数大于 coreThreadCount 则把任务丢到一个队列里面,由当前空闲的线程执行;当队列中的任务堆积满了的时候,则继续创建线程,直到达到 maxThreadCount;当线程数达到 maxTheadCount 时还有新的任务提交,那么就不得不将它们丢弃了。
这个任务处理流程看似简单,实际上有很多坑,在使用的时候一定要注意。
首先,
JDK 实现的这个线程池优先把任务放入队列暂存起来,而不是创建更多的线程,它比较适用于执行 CPU 密集型的任务,也就是需要执行大量 CPU 运算的任务。这是为什么
呢?因为执行CPU 密集型的任务时 CPU 比较繁忙,因此只需要创建和 CPU 核数相当的线程就好了,多了反而会造成线程上下文切换,降低任务执行效率。所以当当前线程数超过核心线程数时,线程池不会增加线程,而是放在队列里等待核心线程空闲下来。但是,平时开发的 Web 系统通常都有大量的 IO 操作(系统是IO密集型),比方说查询数据库、查询缓存等等。任务在执行 IO 操作的时候 CPU 就空闲了下来,这时如果增加执行任务的线程数而不是把任务暂存在队列中,就可以在单位时间内执行更多的任务,大大提高了任务执行的吞吐量。所以Tomcat 使用的线程池就不是 JDK 原生的线程池,而是做了一些改造,当线程数超过 coreThreadCount 之后会优先创建线程,直到线程数到达maxThreadCount,这样就比较适合于 Web 系统大量 IO 操作的场景了
。其次,
线程池中使用的队列的堆积量也是需要监控的重要指标,对于实时性要求比较高的任务来说,这个指标尤为关键。在实际项目中曾经有过任务被丢给线程池之后,长时间都没有被执行的诡异问题。
最初,研发人员认为这是代码的 Bug 导致的,后来经过排查发现,是因为线程池的coreThreadCount 和 maxThreadCount 设置的比较小,导致任务在线程池里面大量的堆积,在调大了这两个参数之后问题就解决了。跳出这个坑之后,然后把重要线程池的队列任务堆积量,作为一个重要的监控指标。最后,
如果使用线程池请一定记住不要使用无界队列(即没有设置固定大小的队列)。也许会觉得使用了无界队列后,任务就永远不会被丢弃,只要任务对实时性要求不高,反正早晚有消费完的一天。但是,大量的任务堆积会占用大量的内存空间,一旦内存空间被占满就会频繁地触发 Full GC,造成服务不可用,可能一次 GC 引起的宕机,起因就是系统中的一个线程池使用了无界队列。为啥要对tomcat配置进行优化
发现容量问题
server端并发线程数上不去,导致整个的tps的容量上不去,导致客户端被拒绝连接之后,发生了各种各样的问题
查看SpringBoot配置:
要对tomcat容器配置优化,首先要知道容器配置在哪;
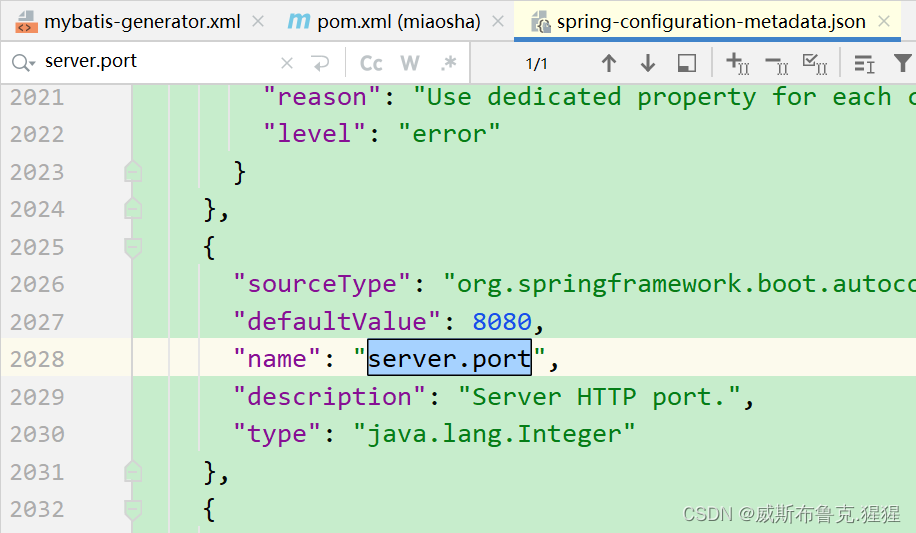
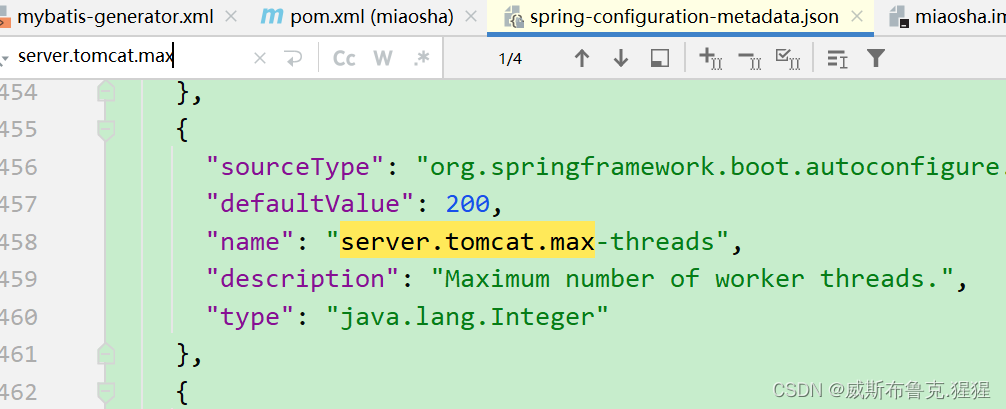
spring-configuration-metadata.json文件下,查看各个节点的配置
内嵌的tomcat默认的启动端口8080
tomcat的默认支持线程数最大是200
其他默认参数
最大线程数:tomcat能创建来处理请求的最大线程数
acceptCount:最大等待队列数 ,请求并发大于tomcat线程池的处理能力,则被放入等待队列等待被处理。
maxIdleTime:最大空闲时间,超过这个空闲时间,且线程数大于最小空闲数的,都会被回收
maxSpareTHreads:最大空闲线程数,在最大空闲时间内活跃过,但现在处于空闲,若空闲时间大于最大空闲时间,则回收,小于则继续存活,等待被调度。
minSpareTHreads:最小空闲线程数,无论如何都会存活的最小线程数
实际开发中,一般都是在不断的实际环境测试中寻找最佳值;所有的系统都是要根据不同的硬件能力、环境做调节,然后不断压测验证的,没有固定的方案。
定制化内嵌tomcat开发
配置
keepAliveTimeOut:多少毫秒后不响应的断开keepalive
maxKeepAliveRequests:多少次请求后keepalive断开失效
关于keepAlive
在使用Jmeter的Http请求中默认是开启KeepAlive的,Http的KeepAlive请求为当客户端向服务器发送Http请求的时候,若带上了KeepAlive的请求头,则表明Http客户端希望跟服务端之间建立一个KeepAlive的连接,这个连接对应的用处就是说,向服务端发送完对应的响应之后,服务端不要立马断开连接,而是等待尝试复用连接。
此解决方案是用来解决Http的一个响应,无状态,每次都要断开连接,新建连接所带来的一个耗时问题。
但如果每个网页请求打开之后都跟服务端保持一个长连接,那服务端的连接数很快就会被用完了,因此再最早的Http1.0的时候是没有设计KeepAlive的请求的,但是现在的Http1.1加上KeepAlive请求,目的就是越来越多的移动端的设备,甚至于一些很复杂的网页交互,需要在用户浏览的过程当中,频繁的向服务端发送请求,因此,建立一个KeepAlive连接,并非为了压测的目的,而是真正的在应用场景上是有一些性能的好处的,无论是客户端还是服务端,在做一些网络通信的交互上面,无需每次都新建连接,断开连接,耗费Tcp/Ip建连的时间,而仅仅只需要发送数据即可。
但是这样的设计也会带来一些问题,如果说我们的服务端对KeepAlive的操作没有做任何限制
1.连接不做任何操作,不做任何响应,那这条连接对服务端来说就是一条费连接
2.有一些攻击者恶意利用KeepAlive连接向服务端发送DDOS的攻击,那服务端对应的连接只会成为攻击者攻击的后门,因此,为了安全,我们需要定制化Tomcat开发//当spring容器内没有TomcatEmbeddedServletContainerFactory这个bean时,会把bean加载进spring容器 @Configuration public class WebServerConfiguration implements WebServerFactoryCustomizer<ConfigurableWebServerFactory> { @Override public void customize(ConfigurableWebServerFactory factory) { //使用对应工厂类提供给我们的接口定制化我们的tomcat connector ((TomcatServletWebServerFactory)factory).addConnectorCustomizers(new TomcatConnectorCustomizer() { @Override public void customize(Connector connector) { Http11NioProtocol protocol= (Http11NioProtocol) connector.getProtocolHandler(); //定制KeepAliveTimeout,设置30秒内没有请求则服务器自动断开keepalive连接 protocol.setKeepAliveTimeout(30000); //当客户端发送超过10000个请求则自动断开keepalive连接 protocol.setMaxKeepAliveRequests(10000); } }); } }keepalive用于和前面的nginx代理之间保持长链接关系;避免每次被代理后都需要新建一个链接,损伤性能。
项目中设计模式的应用
工厂模式,定义一个创建对象的接口,让其子类自己决定实例化哪一个工厂类,工厂模式使其创建过程延迟到子类进行。
使用对应工厂类提供给的接口定制化tomcat连接,这里应用到了工厂模式的设计思想。
发现容量问题
响应时间变长,TPS上不去
单Web容器上限
线程数量:4核CPU 8G内存单进程调用线程数800-1000,1000以上后即花费巨大的时间在CPU调度上
等待队列长度:队列做缓冲池用,但也不能无限长,消耗内存,出队入队也耗CPU
Mysql数据库QPS容量问题
大量的CPU耗费在mysql的查询上面
主键查询:千万级别数据 = 1-10毫秒
唯一索引查询:千万级别数据 = 10-100毫秒
非唯一索引查询:千万级别数据 = 100-1000毫秒
无索引:百万条数据 = 1000毫秒+非插入更新删除操作:同查询
注:查询相当于全表扫描
对于插入操作的效率提升主要有3个方面
使用批量插入的sql语句,而不要用for循环逐个插入
使用事务包裹所有的插入语句,而不要每一个查询都起一个事务
插入的时候尽量保证插入的条目顺序是按照索引的递增顺序插入的,这样可以避免频繁的调整索引
插入的总数据量大小不要小于innodb_log_buffer_size这个选项的大小,超过这个大小则会发生频繁的磁盘内存切换。可以分批插入事务提交
JMeter在云端压测的过程中不可避免的会有公网带宽的网络消耗,如何避免对应的情况?
将 JMeter 运行在另外一台云端机器,通过私网 IP 连通进行压力测试。



版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/110902.html

