
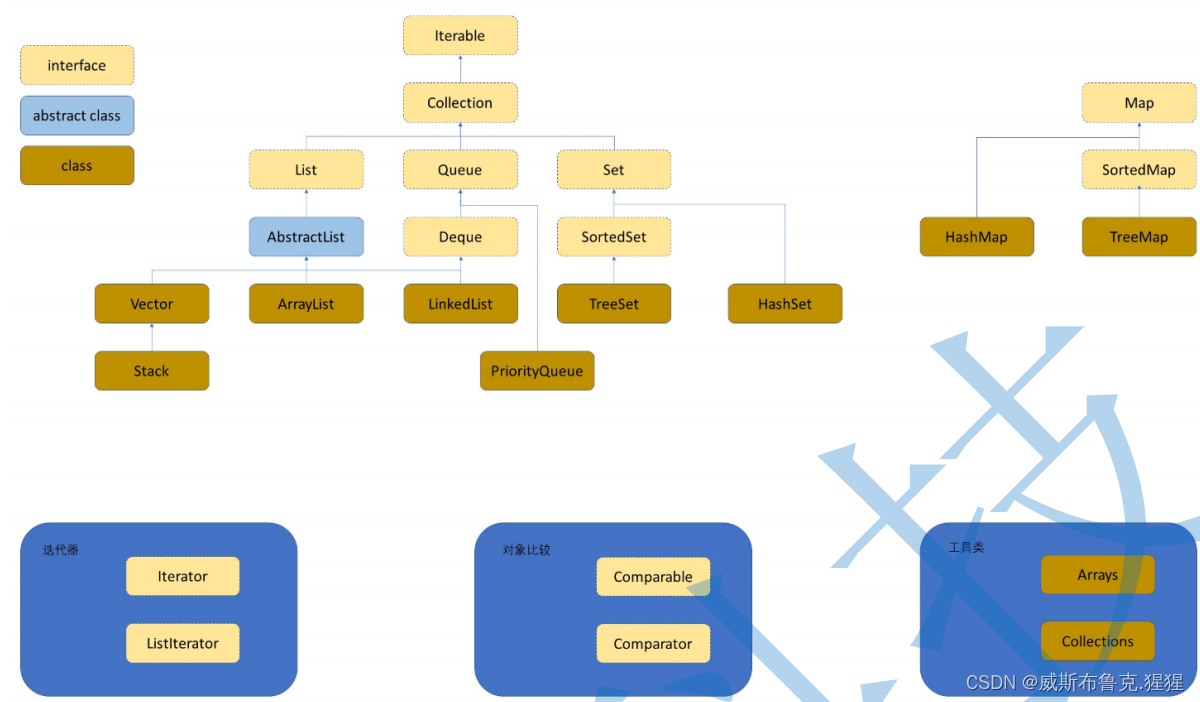
Collection接口
public interface Collection<E> extends Iterable<E> {源码中方法

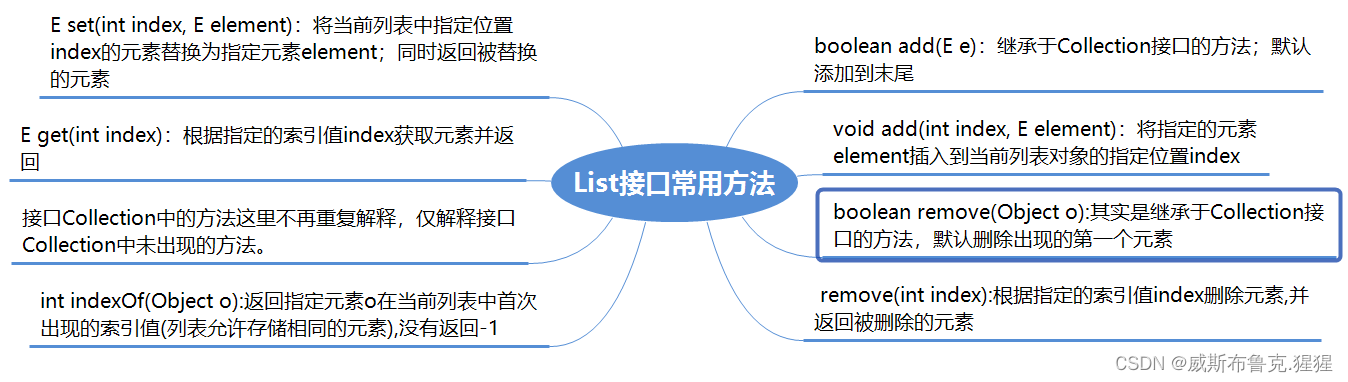
List接口
public interface List<E> extends Collection<E> {
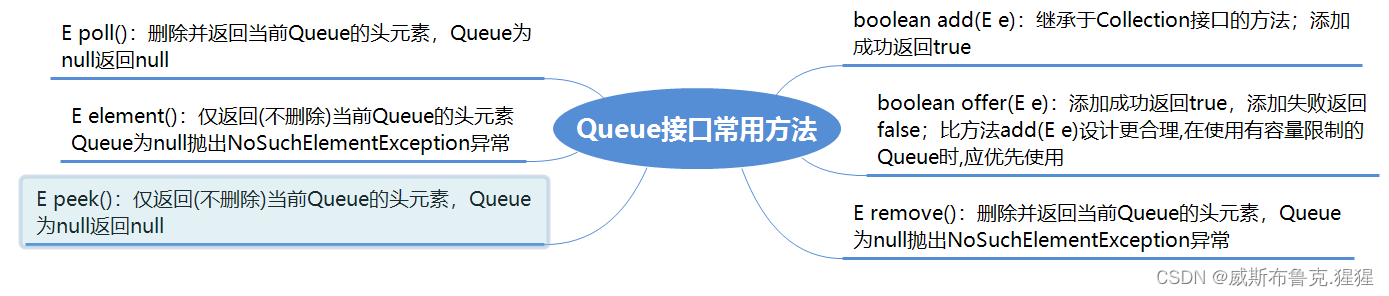
Queue接口
public interface Queue<E> extends Collection<E> { 
Deque接口
public interface Deque<E> extends Queue<E> {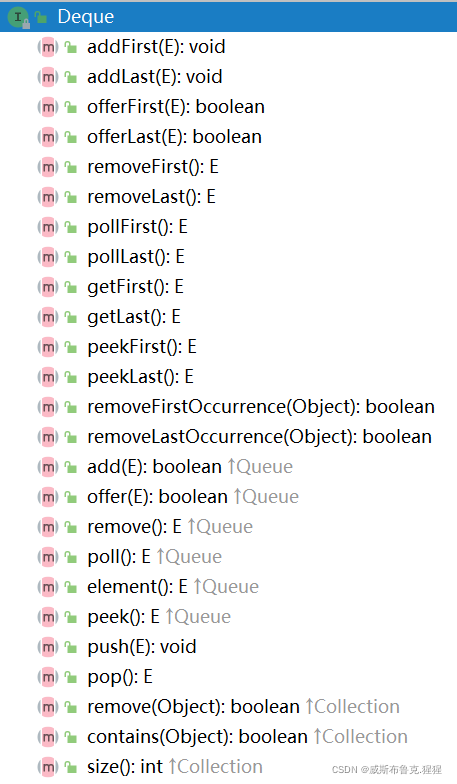

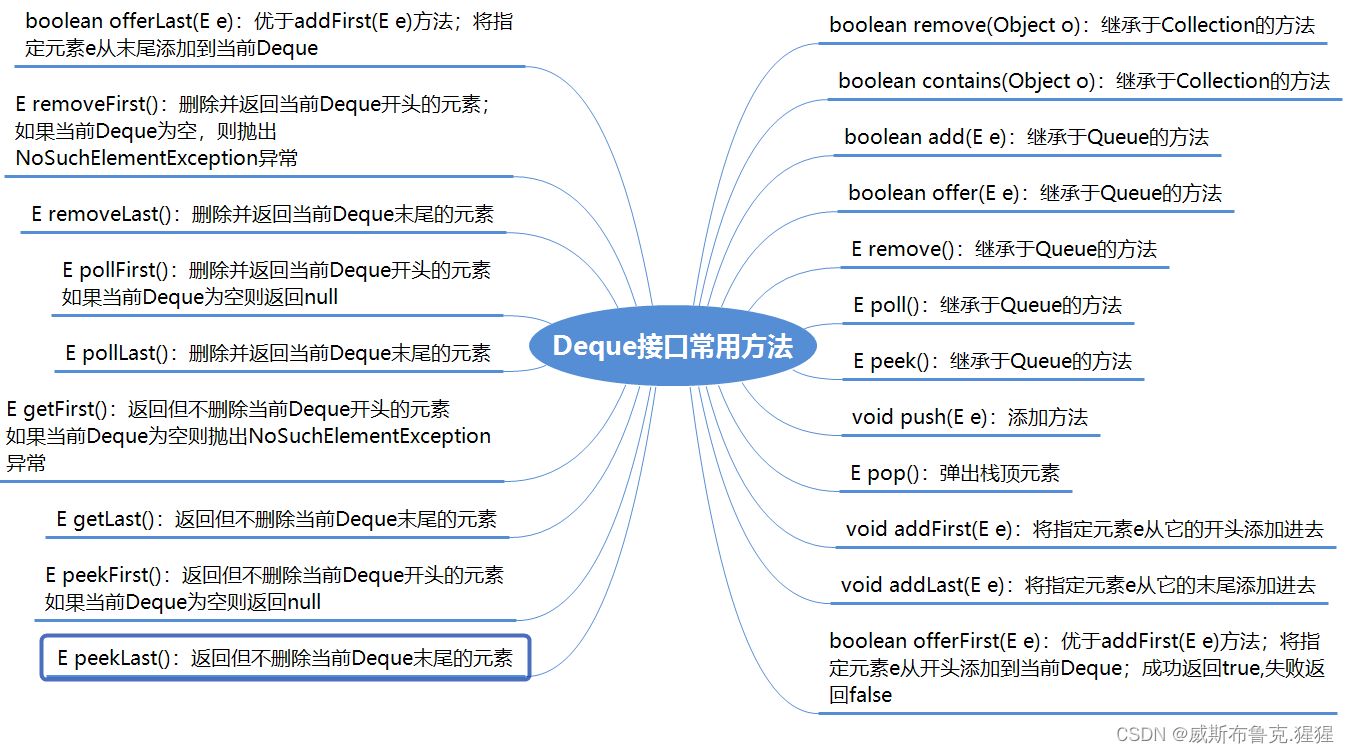
Map接口
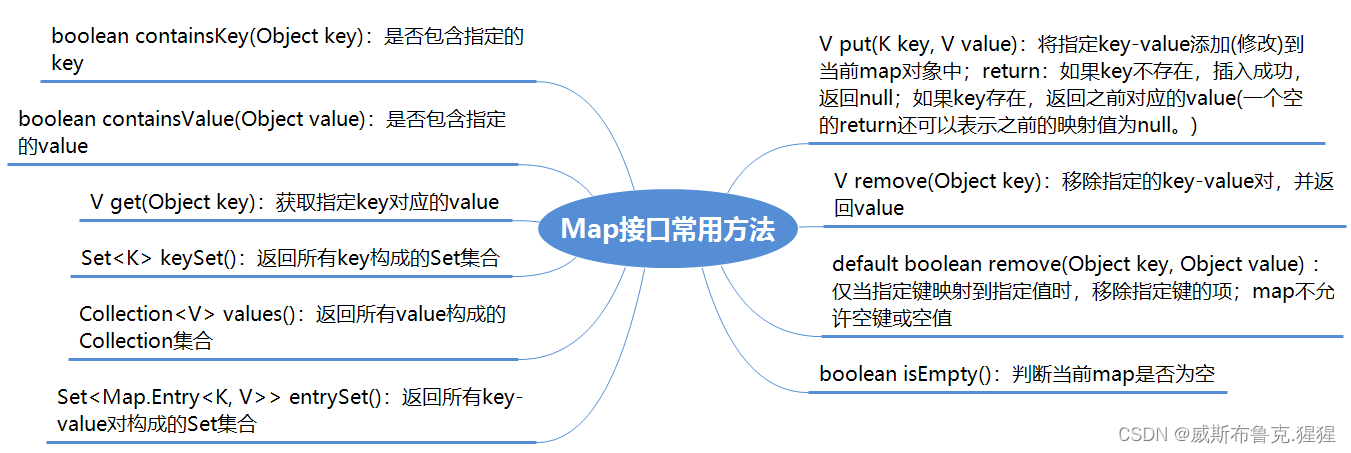
public interface Map<K,V> {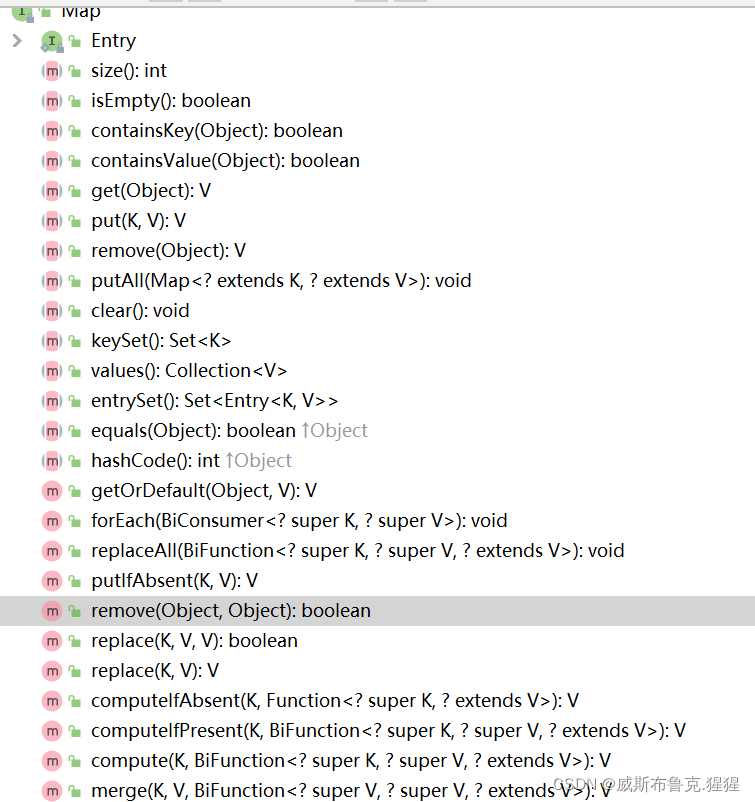
Set接口

Set集合是没有修改元素的方法的!只能把这个元素删除再添加一个新的元素
栈是一个线性表,底层即可使用数组,也可使用链表
基于数组实现的栈 – 顺序栈(数组尾部的添加和删除,时间复杂度为o(1),栈顶实际上就是数组末尾)
基于链表实现的栈 – 链式栈(尾插和尾删)
栈的实际应用:
1、无处不在的撤销操作(undo)一般在任意的编辑器ctrl + z(每次ctrl + z实际上就是一个栈的pop)
2、浏览器的前进后退,浏览器维护了一个栈结构
3、开发中程序的”调用栈”操作系统栈底层就是栈的实现
Collection总结
Collection:代表了一个独立元素的序列,这些元素都服从一条或多条规则。比如
①、List:必须按照插入的顺序保存元素。
②、Set:不能有重复的元素。
③、Queue:只能从一端插入元素,或者只能从一端去除元素,也就是说,所有的操作都在”端”上,而不必遍历这个容器的其它位置。
JDK没有提供接口Collection的直接实现(在JDK中,没有任何一个类直接implements接口Collection,都是一个接口或一个抽象类extends/implements Collection,然后具体的类再extends/implements这些接口或抽象类)。
接口Collection存在的最大意义是参数传递,如果某个方法需要一个代表集合类型的形式参数,没有比接口Collection更合适的了。当需要传入实际参数时再传入具体的子类,这是多态的典型应用。但多态的一个限制是父类对象无法调用子类新增的方法,一旦使用了多态,那么只能调用父接口/父类的方法,所以,接口Collection需要保证拥有集合类型的最大通用性。
如果需要实现这样一个集合类:它的对象可以存储无序并且重复的元素,那么应该直接implements接口Collection,同时使用单独的package进行管理,因为目前的JDK中并没有提供这样的集合类。JDK目前现有的集合类都是无序与重复二选一。
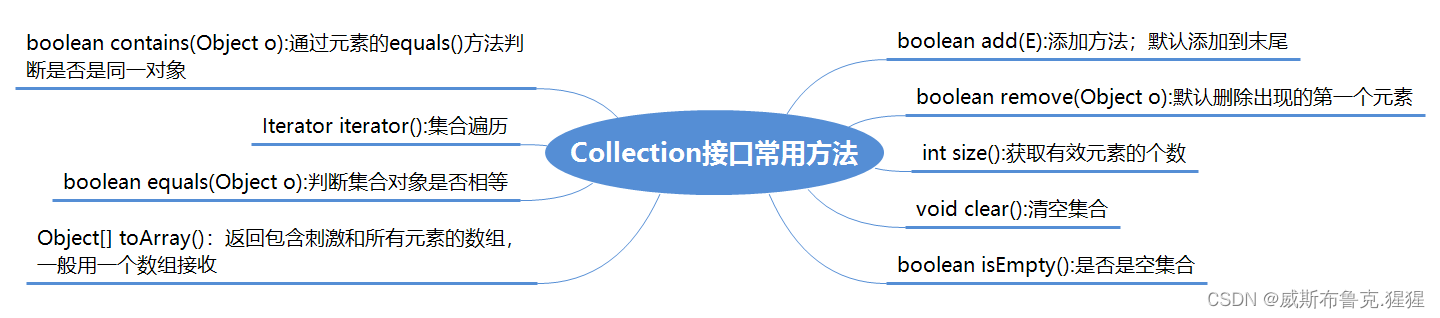
接口Collection包含了许多类Object的方法,比如方法contains(Object o),它的标准作用是当且仅当集合对象中包含至少一个元素e使得o.equals(e)返回true,大部分的实现都是直接遍历当前集合对象,然后使用e与每个元素进行等值比较。实际上,更合理的途径是将方法equals(Object o)与方法hashCode()结合使用。比较两个对象的哈希码可以避免直接的等值比较(直接的等值比较效率低下,而哈希码比较可以大大提高程序执行效率。)。所以,最理想的操作模式是,先比较两个对象的哈希码(hashCode()),再进行等值比较(equals())。
方法add()的名称就表明它是要将一个新元素放置到Collection中。但是,在Java的API文档中非常仔细地叙述到:要确保这个Collection包含指定的元素,这是因为考虑到了Set的含义,因为在Set中只有当前元素不存在的情况下才会被添加进去。而ArrayList或者是其他的List,方法add()总是表示”把它放进去”,因为List不关心元素是否重复。
也就是说,只要你调用了Collection的方法add()添加了某个元素,那么就能确保这个Collection里面一定能包含这个元素(List就可能是多个,Set肯定就是一个,不管怎么样,都保证至少有一个)。
Set和List总结
的底层是使用Map来实现的,其使用key与Object的一个默认对象作为键值对插入到Map中的
Set
接口的常用类有
TreeSet
和
HashSet
,还有一个
LinkedHashSet
,
LinkedHashSet是在HashSet的基础上维护了一个双向链表来记录元素的插入次序。
中的Key不能修改,如果要修改,先将原来的删除掉,然后再重新插入Set中不能插入null的key
。
①、HashSet使用的是非常复杂的方式来存储元素的(最快获取元素的方式,因此,存储的顺序看起来并无实际的意义,你只会关心某个对象是否是Set的成员,而不会关心它在Set中的顺序)。
②、TreeSet可以保证元素按照某种顺序存储(如果存储顺序很重要,比如按照比较结果的升序保存对象,就需要使用它)。
③、LinkedList:按照元素的添加顺序保存它们。
⑴、接口List代表了所有的有序集合类(也称列表),它可以精确地控制所有元素的位置(也称索引),通过索引可以直接访问或操作元素。
在面向某些数据结构的List时(比如LinkedList),直接通过索引访问元素并不是最优的解决办法,因为可能非常耗时,效率也不高。所以,如果在不知道具体实现的情况话,首选的解决办法是使用迭代器(每种数据结构的集合都有对应的最优迭代器实现)。
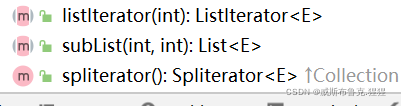
⑸、在接口Collection的迭代器Iterator的基础上,接口List还提供了另一种特殊的迭代器ListIterator(List拥有两种迭代器类,Iterator和ListIterator),它比Iterator效率更高,不但能迭代、插入、替换以及双向访问遍历元素,还能从指定位置开始迭代元素(Iterator只能从索引为0的元素开始迭代)。
⑹、接口List提供了两种方法来查找指定的元素,从性能的角度来看,使用这些方法应该提高警惕,尽量避免出现代价高昂的线性查找(比如要查找的元素恰好在列表的末尾,那可能会遍历整个List)。
LinkedList最大的好处在于头尾和已知节点的插入和删除时间复杂度都是O(1).但是涉及到先确定位置再操作的情况,则时间复杂度会变为O(n)。
动态数组(ArrayList)优点:根据index索引查找/修改元素快O(1)
缺点:数组定长问题,需要扩容,扩容牵扯到大量的元素搬移操作(耗时)
在数组头部的删除和插入都需要搬移N个元素->耗时
ArrayList的使用相当简单:创建一个对象实例,用方法add()插入对象,用方法get()访问对象(此时需要索引,就像数组一样,但是不需要方括号)。ArrayList还有一个size()方法,你可以通过它了解目前已经有多少个对象添加了进来,从而不会不小心因索引越界而引发错误。
因为ArrayList是有序的容器类,什么顺序放入的,就按照什么顺序保存,所以访问的顺序和放入的顺序是完全一致的

Queue总结
⑴、Queue具有如下特点:
①、只能在Queue的端(头部)访问、操作元素(不能随机访问、操作)。
②、Queue体现了优先处理的概念(priority):先经过端(头部)的元素优先处理。
③、除集合根接口Collection提供的添加、删除、返回操作之外,Queue还提供了额外的添加、删除、返回操作(参考以下表格),这些操作均以两种形式存在:一种在操作失败时抛出异常,另一种返回特殊值(方法offer(E e)专门用于容量受限的Queue,大多数实现的添加操作不会失败) 。
⑵、Queue有两种策略:
①、FIFO(先进先出,添加元素在一端(尾部),删除、返回元素在另一端(头部))
②、LIFO(后进先出,添加、删除、返回元素在同一端(头部))
Queue通常会按照以上两种策略对元素排序,但没有强制要求。除非是优先队列(PriorityQueue),优先队列强制要求一定要对它的所有元素排序(根据比较器或元素的自然顺序)。不论使用了哪种排序方式,方法remove()和方法poll()删除的都是Queue的端(头部)元素,每一种Queue的实现都必须提供它的排序规则。
⑶、方法offer(E e)添加元素成功返回true,否则返回false,它与接口Collection的方法add(E e)不同(添加元素失败抛出异常),固定容量的Queue添加元素使用add(E e),其它情况使用offer(E e)。
offer与add的区别:
offer属于offer in interface Deque
add属于add in interface Collection.
当队列为空时候,使用add方法会报错,而offer方法会返回false.
作为List使用时,一般采用add/get方法来压入/获取对象。
作为Queue使用时,才会使用offer/poll/take等方法;作为链表对象时,offer等方法相对来说没有什么意义;这些方法是用于支持队列使用的。
⑷、方法remove()和poll()删除并返回Queue的端(头部)元素,具体删除的元素由Queue的排序策略决定(每种Queue的排序策略都可能不同),当Queue为空时,方法remove()抛出异常而方法poll()返回null。
⑸、方法element()和方法peek()仅仅返回Queue的端(头部)元素而不会进行删除。
⑹、接口Queue没有定义有关阻塞队列(blocking queue)的方法,阻塞队列在并发编程中非常常见,它包括以下两种类型的方法:
①、有关目标元素出现如何处理(目标元素未出现时阻塞)
②、有关Queue出现可用空间如何处理(Queue无可用空间时阻塞)
阻塞队列的方法定义在java.util.concurrent.BlockingQueue接口中,它继承自接口Queue。
⑺、Queue的实现一般不允许添加null元素,尽管某些实现允许,比如LinkedList,就算如此,也不应将null添加到Queue中,因为方法poll()会返回null以表示当前Queue不包含任何元素。
⑻、Queue的实现类通常不会为方法equals()和方法hashCode()提供实现,主要有以下两个原因:
①、同一个Queue中可能存在两个完全相同的元素。
②、同一个Queue可能会使用不同的排序策略(一旦排序策略改变,方法equals()的代码肯定也要改变)。
Deque总结
⑴、Deque是一个在两端都可以添加和删除元素的线性集合。它是”double ended queue”的缩写,通常发音为”deck”。大多数Deque的实现类对它们可能包含的元素数量没有固定的限制(Deque同时支持容量受限和没有固定大小限制两种双端队列)。
⑵、Deque定义了一些操作双端队列两端元素的方法(添加、删除、返回)。这些方法均以两种形式存在,如果操作失败,其中一个抛出异常,另一个返回特殊值null或false(方法offer(E e)、offerLast(E e)专门用于容量受限的Deque,大多数实现的添加操作不会失败)。下表总结了上述方法:
⑶、Deque扩展了Queue。如果将一个Deque当做Queue使用,默认的策略是FIFO(先进先出):从它的末尾添加元素,开头删除。这时,从Queue继承的方法与Deque本身的扩展方法是等效的,如下表所示:
⑷、如果将一个Deque当做Stack使用(实际上,Deque应优先于旧版Stack类使用),默认的策略是LIFO(后进先出):元素从Deque的开头被压和弹出。这时,部分Deque的方法与Stack的方法是等效的,如下表所示:
注意,无论将Deque当做Queue还是Stack,方法peek()都有效。
⑸、Deque提供了两种删除内部元素的方法:removeFirstOccurrence()和
removeLastOccurrence()。
⑹、Deque不支持通过索引访问元素。
⑺、虽然没有明确禁止Deque添加null元素,但还是强烈建议任何允许添加null元素的Deque不要添加它。因为有部分方法通过返回null表示当前的Deque为空。
⑻、Deque的实现类通常不会为方法equals()和方法hashCode()提供实现,主要有以下两个原因:
①、同一个Deque中可能存在两个完全相同的元素。
②、同一个Deque可能会使用不同的排序策略(一旦排序策略改变,方法equals()的代码肯定也要改变)。
实现Queue和Deque接口的类图
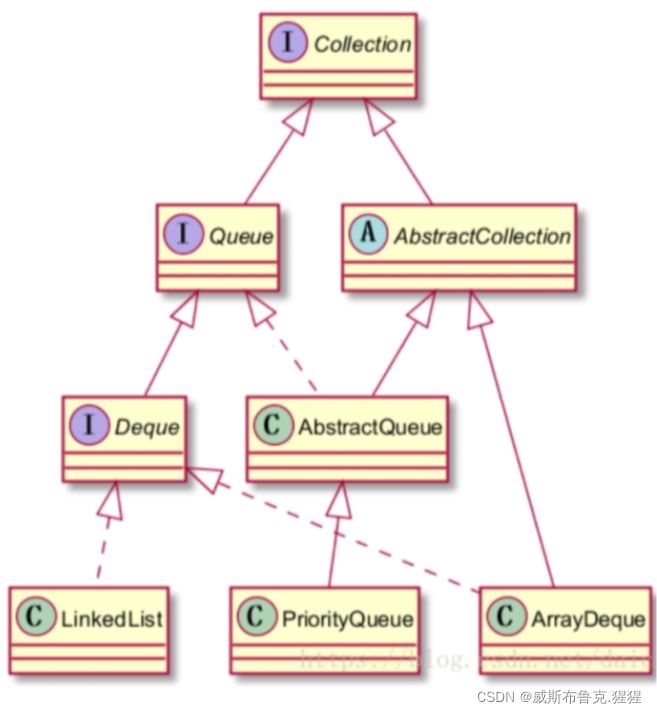
LinkedList类实现了接口Queue和Deque,具备了操作队列的基本方法。通常可以作为队列和双向队列的实现类使用,也是用得比较普遍的队列数据结构。

Java中的双端队列Deque;所谓的双端队列指的是可以从两头进行元素的插入和删除;【addFirst()、pollFirst()、addLast()、pollLast()】
一、ArrayDeque:基于数组实现的双端队列
二、LinkedList:基于链表实现的双端队列
正因为双端队列支持双向操作,现在使用双端队列来代替JDK中Stack类使用,Stack在后续的JDK可能会被废弃掉(Stack是Vector,线程安全,效率低,基于对象锁的实现,JDK1.0古老类)
尾插尾删或者头插头删就是栈
while(!deque.isEmpty()){
System.out.println(deque.pollLast());
}
头插尾删或者尾插头删就是队列
while(!deque.isEmpty()){
System.out.println(deque.pollFirst());
}-
频繁的插入、删除操作:LinkedList
-
频繁的随机访问操作:ArrayDeque
-
未知的初始数据量:LinkedList
Map总结
在Map中插入键值对时,key不能为空,否则就会抛NullPointerException异常,但是value可以为空;Map中键值对的Key不能直接修改,value可以修改,如果要修改key,只能先将该key删除掉,然后再来进行重新插入。
TreeMap和HashMap的区别:

Java中的Collection中的数据类型很多,以下为主要数据类型的时间复杂度:
数组 Array
访问:O(1)
查找(未排序):O(n)
查找(已排序):O(log n)
插入/删除:不支持
数组列表 ArrayList
添加: O(1)
删除:O(n)
查询:O(n)
求长:O(1)
链接列表 LinkedList
插入:O(n)
删除:O(n).
查找:O(n)
双链接列表 Doubly-Linked List
插入:O(n)
删除:O(n)
查找:O(n)
栈 Stack
压栈:O(1)
出栈:O(1)
栈顶:O(1)
查找:O(n)
队列 Queue/Deque/Circular Queue
插入:O(1)
移除:O(1)
求长:O(1)
出队(出最大值) O(N)
二叉搜索树 Binary Search Tree
插入:O(log n)
删除:O(log n)
求长:O(log n)
以上均为平均时间,最坏情况均为O(n)。
红黑树 Red-Black Tree
插入:O(log n)
删除:O(log n)
求长:O(log n)
以上均为平均时间,最坏情况均为O(n)。
堆 Heap/PriorityQueue
插入:O(log n)
删除最大/小值:O(log n)
虽然堆顶就是最大值,但是要删除堆顶元素,还要进行siftDown操作
抽取最大/小值:O(log n)
查找最大/小值:O(1)
查找其他值:O(n)
删除:O(n)
PriorityQueue
插入方法(offer()、poll()、remove() 、add() 方法)时间复杂度为O(log(n)) ;
remove(Object) 和 contains(Object) 时间复杂度为O(n);
检索方法(peek、element 和 size)时间复杂度为常量。
虽然堆顶就是最大值,但是要删除堆顶元素,还要进行siftDown操作
映射 HashMap/Hashtable/HashSet
插入或删除:O(1)
调整容量:O(n)
查询:O(1)
亲测Java集合常用实现类,那些不能存储null
/** * 亲测Java集合常用实现类,那些不能存储null */ public static void main(String[] args) { /** * ArrayDeque不能存储null */ // Deque queue = new ArrayDeque(); // queue.offer(null); // System.out.println(queue); Deque queue1 = new LinkedList(); queue1.offer(null); System.out.println(queue1); List list = new LinkedList(); list.add(null); System.out.println(list); List list1 = new ArrayList(); list1.add(null); System.out.println(list1); Set set = new HashSet(); set.add(null); System.out.println(set); Set set1 = new LinkedHashSet(); set1.add(null); System.out.println(set1); /** * 由于TreeMap的key不能存储null,所以TreeSet不能存储null(详见HashMap源码分析) */ // Set set2 = new TreeSet(); // set2.add(null); // System.out.println(set2); Map map = new HashMap(); map.put(null,null); System.out.println(map); Map map1 = new LinkedHashMap(); map1.put(null,null); System.out.println(map1); Map map2 = new TreeMap(); map2.put(1,null); /** * TreeMap的key不能存储null */ // map2.put(null,null); // map2.put(null,1); System.out.println(map2); }
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/110914.html

