
jvm体系结构
简单学习了一下Jvm的一些知识,小结一下。
深入学习的话就要看书了。《深入理解java虚拟机》

1.jvm的位置
它是整个java实现跨平台的最核心的部分,由Java文件编译来的class文件,只有经过虚拟机解释才能被操作系统执行。
一次编译,多处运行:JVM屏蔽了与具体操作系统平台相关的信息,使得Java程序只需生成在Java虚拟机上运行的class文件(字节码),就可以在多种平台上不加修改地运行。
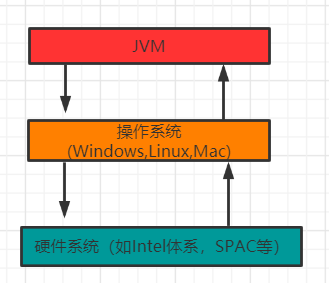
2.JVM,JRE,JDK的关系:
JDK 包含 JRE,
JRE 包含 JVM
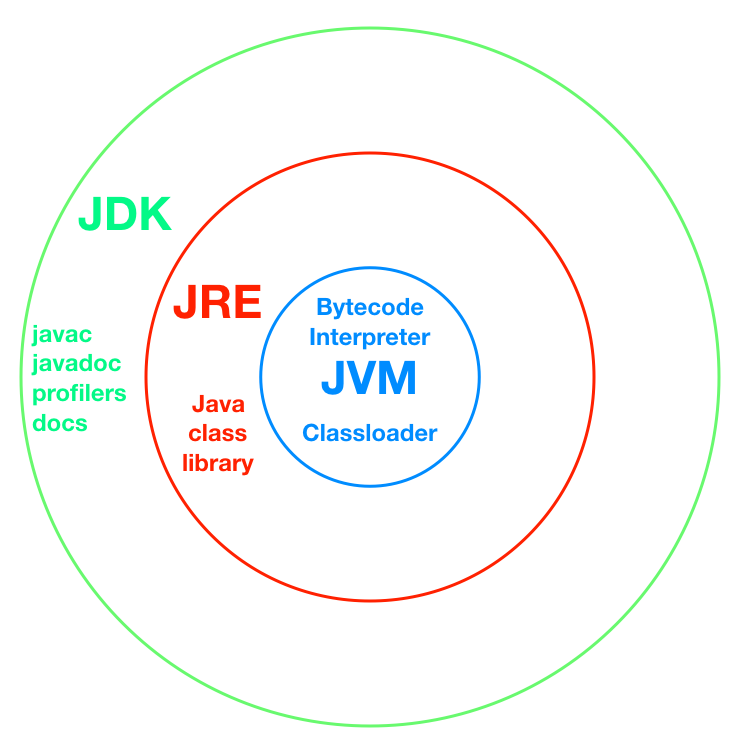
3.类加载器:
Java是运行在Java的虚拟机(JVM)中的,但是它是如何运行在JVM中了呢?我们在IDE中编写的Java源代码被编译器编译成.class的字节码文件。然后由我们得ClassLoader负责将这些class文件给加载到JVM中去执行。
JVM中提供了三层的ClassLoader:
- Bootstrap classLoader:主要负责加载核心的类库(java.lang.*等),构造ExtClassLoader和APPClassLoader。
- ExtClassLoader:主要负责加载jre/lib/ext目录下的一些扩展的jar。
- AppClassLoader:主要负责加载应用程序的主函数类
- 另外还有:User ClassLoader 用户自定义类加载器
4.双亲委派机制
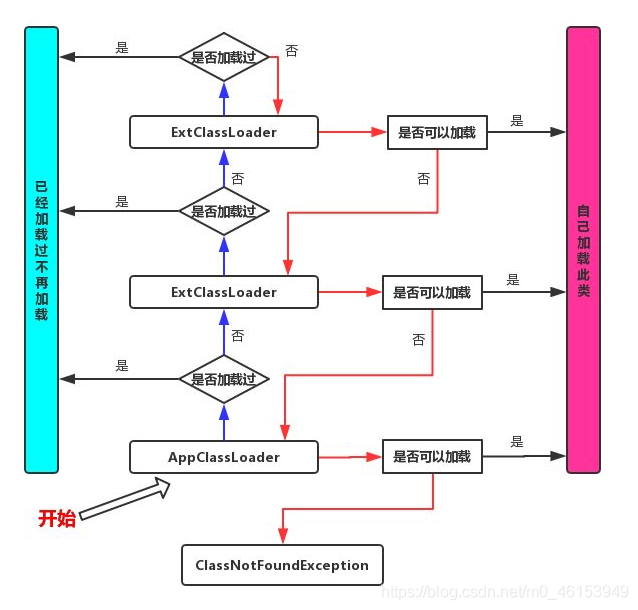
简单来说:就是当某个类加载器需要加载某个.class文件时,它首先把这个任务委托给他的上级类加载器(先找ExtClassLoader,没找到再去Bootstrap classLoader里面找),递归这个操作,如果上级的类加载器没有加载,自己才会去加载这个类。
双亲委派机制的作用:
1、防止重复加载同一个.class。通过委托去上级查看,加载过了,就不用再加载一遍。保证了数据安全。
2、保证核心.class不能被篡改。通过委托方式,不会去篡改核心.clas,即使篡改也不会去加载,即使加载也不会是同一个.class对象了。不同的加载器加载同一个.class也不是同一个Class对象。这样保证了Class执行安全。
5.native关键字
使用native关键字说明这个方法是原生函数,也就是这个方法是用C/C++语言实现的,并且被编译成了DLL,由java去调用。
这些函数的实现体在DLL中,JDK的源代码中并不包含,你应该是看不到的。对于不同的平台它们也是不同的。这也是java的底层机制,实际上java就是在不同的平台上调用不同的native方法实现对操作系统的访问的。
java是跨平台的语言,既然是跨了平台,所付出的代价就是牺牲一些对底层的控制,而java要实现对底层的控制,就需要一些其他语言的帮助,这个就是native的作用了
Java不是完美的,Java的不足除了体现在运行速度上要比传统的C++慢许多之外,Java无法直接访问到操作系统底层(如系统硬件等),为此Java使用native方法来扩展Java程序的功能。
可以将native方法比作Java程序同C程序的接口,其实现步骤:
1、在Java中声明native()方法,然后编译;
2、用javah产生一个.h文件;
3、写一个.cpp文件实现native导出方法,其中需要包含第二步产生的.h文件(注意其中又包含了JDK带的jni.h文件);
4、将第三步的.cpp文件编译成动态链接库文件;
5、在Java中用System.loadLibrary()方法加载第四步产生的动态链接库文件,这个native()方法就可以在Java中被访问了。
6.堆
jvm垃圾回收主要就是在堆区,这里会产生垃圾。
-
Heap 堆,一个JVM实例只存在一个堆内存,堆内存的大小是可以调节的。
-
类加载器读取了类文件后,需要把类,方法,常变量放到堆内存中,保存所有引用类型的真实信息,以方便执行器执行。
-
堆内存分为三部分:
-
新生区 Young Generation Space Young/New
-
养老区 Tenure generation space Old/Tenure
-
永久区 Permanent Space Perm
堆内存逻辑上分为三部分:新生,养老,永久(元空间 : JDK8 以后名称)。

6.1新生区、养老区
- 新生区是类诞生,成长,消亡的区域,一个类在这里产生,应用,最后被垃圾回收器收集,结束生命。
- 新生区又分为两部分:伊甸区(Eden Space)和幸存者区(Survivor Space),所有的类都是在伊甸区被new出来的,幸存区有两个:0区 和 1区,当伊甸园的空间用完时,程序又需要创建对象,JVM的垃圾回收器将对伊甸园区进行垃圾回收(Minor GC)。将伊甸园中的剩余对象移动到幸存0区,若幸存0区也满了,再对该区进行垃圾回收,然后移动到1区,那如果1区也满了呢?(这里幸存0区和1区是一个互相交替的过程)再移动到养老区,若养老区也满了,那么这个时候将产生MajorGC(Full GC),进行养老区的内存清理,若养老区执行了Full GC后发现依然无法进行对象的保存,就会产生OOM异常 “OutOfMemoryError ”。如果出现 java.lang.OutOfMemoryError:java heap space异常,说明Java虚拟机的堆内存不够,原因如下:
- Java虚拟机的堆内存设置不够,可以通过参数 -Xms(初始值大小),-Xmx(最大大小)来调整。
- 代码中创建了大量大对象,并且长时间不能被垃圾收集器收集(存在被引用)或者死循环。
6.2永久区(Perm)
- 永久存储区是一个常驻内存区域,用于存放JDK自身所携带的Class,Interface的元数据,也就是说它存储的是运行环境必须的类信息,被装载进此区域的数据是不会被垃圾回收器回收掉的,关闭JVM才会释放此区域所占用的内存。
- 如果出现 java.lang.OutOfMemoryError:PermGen space,说明是 Java虚拟机对永久代Perm内存设置不够。一般出现这种情况,都是程序启动需要加载大量的第三方jar包,
例如:在一个Tomcat下部署了太多的应用。或者大量动态反射生成的类不断被加载,最终导致Perm区被占满。
注意:
- JDK1.6之前: 有永久代,常量池1.6在方法区;
- JDK1.7: 有永久代,但是已经逐步 “去永久代”,常量池1.7在堆;
- JDK1.8及之后:无永久代,常量池1.8在元空间。
6.3堆内存调优
一些指令:
- -Xms:设置初始分配大小,默认为物理内存的 “1/64”。
- -Xmx:设置最大分配内存,默认为物理内存的 “1/4”。
- -XX:+PrintGCDetails:输出详细的GC处理日志。
IDEA中进行VM调优参数设置,然后启动。
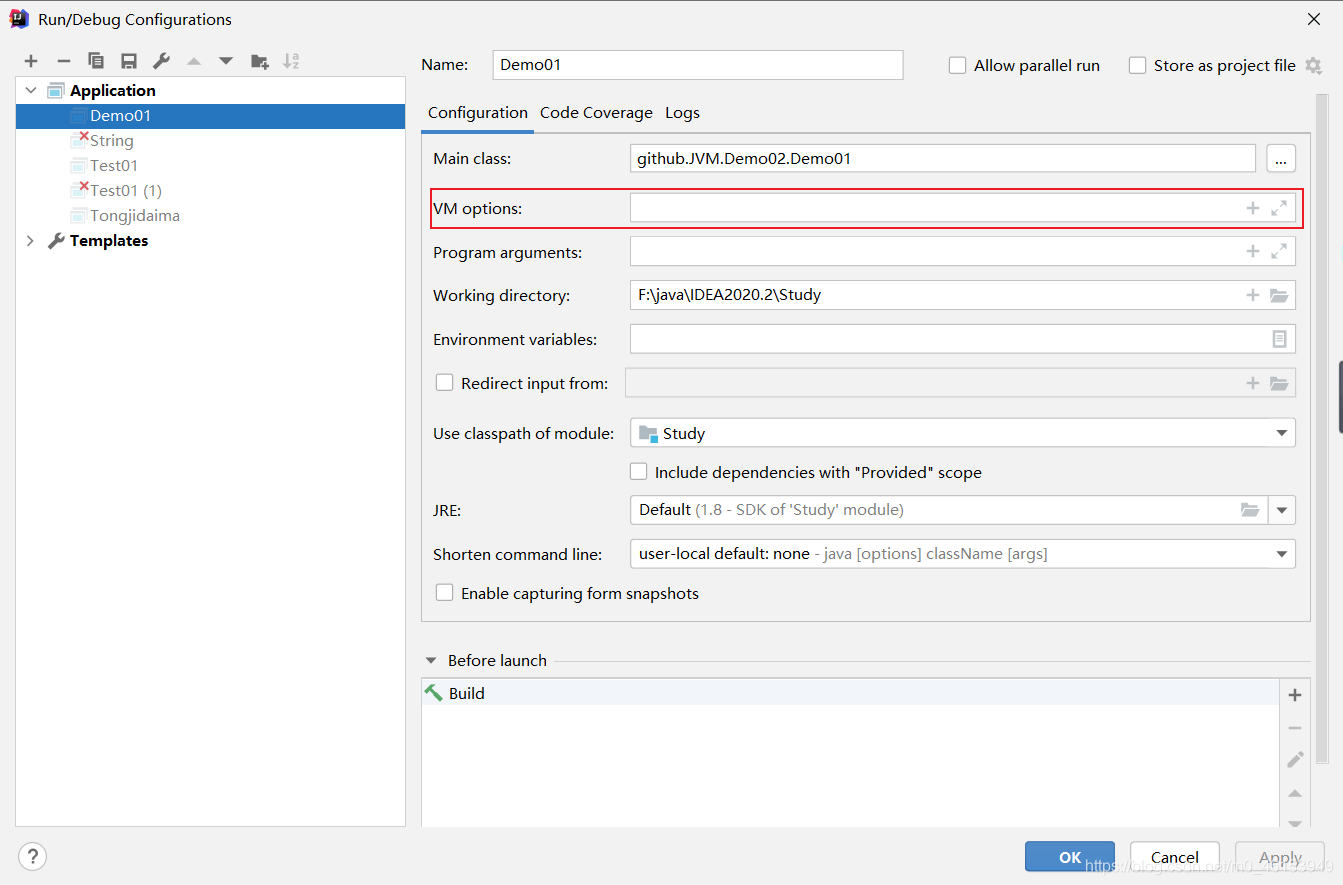
在VM options加入以下参数
-Xms1024m -Xmx1024m -XX:+PrintGCDetails
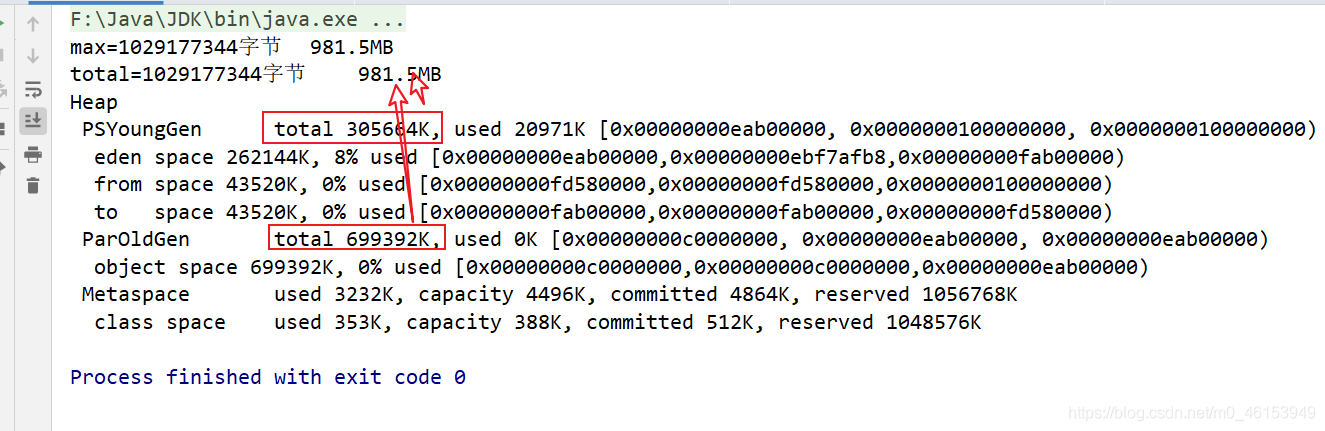
新生区和老年区基本占满了内存
- 元空间并不在虚拟机中,而是使用本地内存。
7.GC
垃圾回收:
当Java虚拟机(VM)或.NETCLR发觉内存资源紧张的时候,就会自动地去清理无用对象(没有被引用到的对象)所占用的内存空间(这里的说法略显粗略,事实上何时清理内存是个复杂的策略)。
如果需要,可以在程序中显式地使用System.gc()/System.GC.Collect()来强制进行一次立即的内存清理。Java提供的GC功能可以自动监测对象是否超过了作用域,从而达到自动回收内存的目的,Java的GC会自动进行管理,调用方法:System.gc()或者Runtime.getRuntime().gc();
7.1Dump内存快照
在运行java程序的时候,有时候想测试运行时占用内存情况,这时候就需要使用测试工具查看了。在eclipse里面有 EclipseMemory Analyzer tool(MAT)插件可以测试,而在idea中也有这么一个插件,就是JProfiler,一款性能瓶颈分析工具!
作用:
- 分析Dump文件,快速定位内存泄漏;
- 获得堆中对象的统计数据
- 获得对象相互引用的关系
- 采用树形展现对象间相互引用的情况
7.2安装JProfiler
1.IDEA插件安装
2.安装JProfiler监控软件
下载地址:jprofiler下载
3.注册
// 注册码仅供参考
L-Larry_Lau@163.com#23874-hrwpdp1sh1wrn#0620
L-Larry_Lau@163.com#36573-fdkscp15axjj6#25257
L-Larry_Lau@163.com#5481-ucjn4a16rvd98#6038
L-Larry_Lau@163.com#99016-hli5ay1ylizjj#27215
L-Larry_Lau@163.com#40775-3wle0g1uin5c1#0674
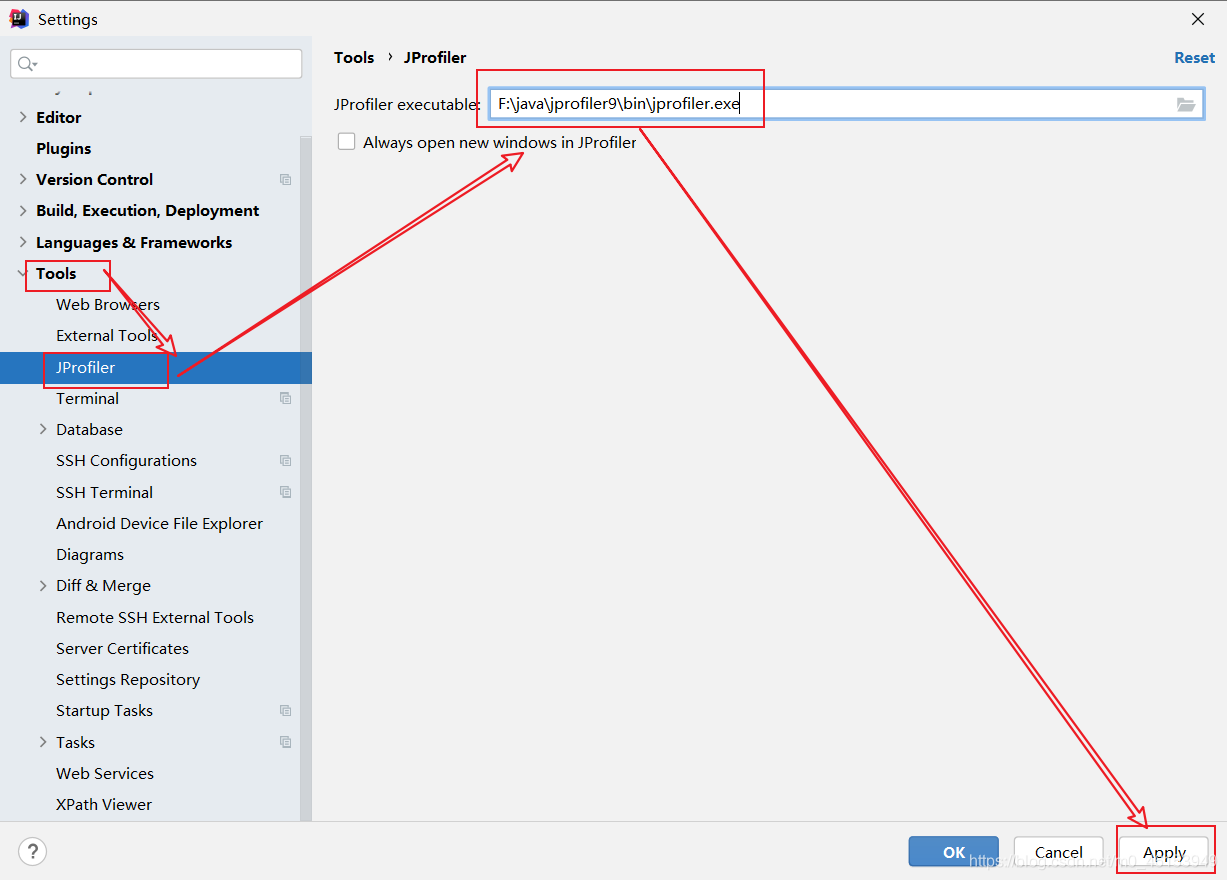
4.配置IDEA运行环境
Settings–Tools–JProflier–JProflierexecutable
选择JProfile安装可执行文件。(如果系统只装了一个版本, 启动IDEA时会默认选择)保存
5.代码测试:
import java.util.ArrayList;
/**
* @author subeiLY
* @create 2021-06-08 11:13
*/
public class Demo03 {
byte[] byteArray = new byte[1*1024*1024]; // 1M = 1024K
public static void main(String[] args) {
ArrayList<Demo03> list = new ArrayList<>();
int count = 0;
try {
while (true) {
list.add(new Demo03()); // 问题所在
count = count + 1;
}
} catch (Error e) {
System.out.println("count:" + count);
e.printStackTrace();
}
}
}
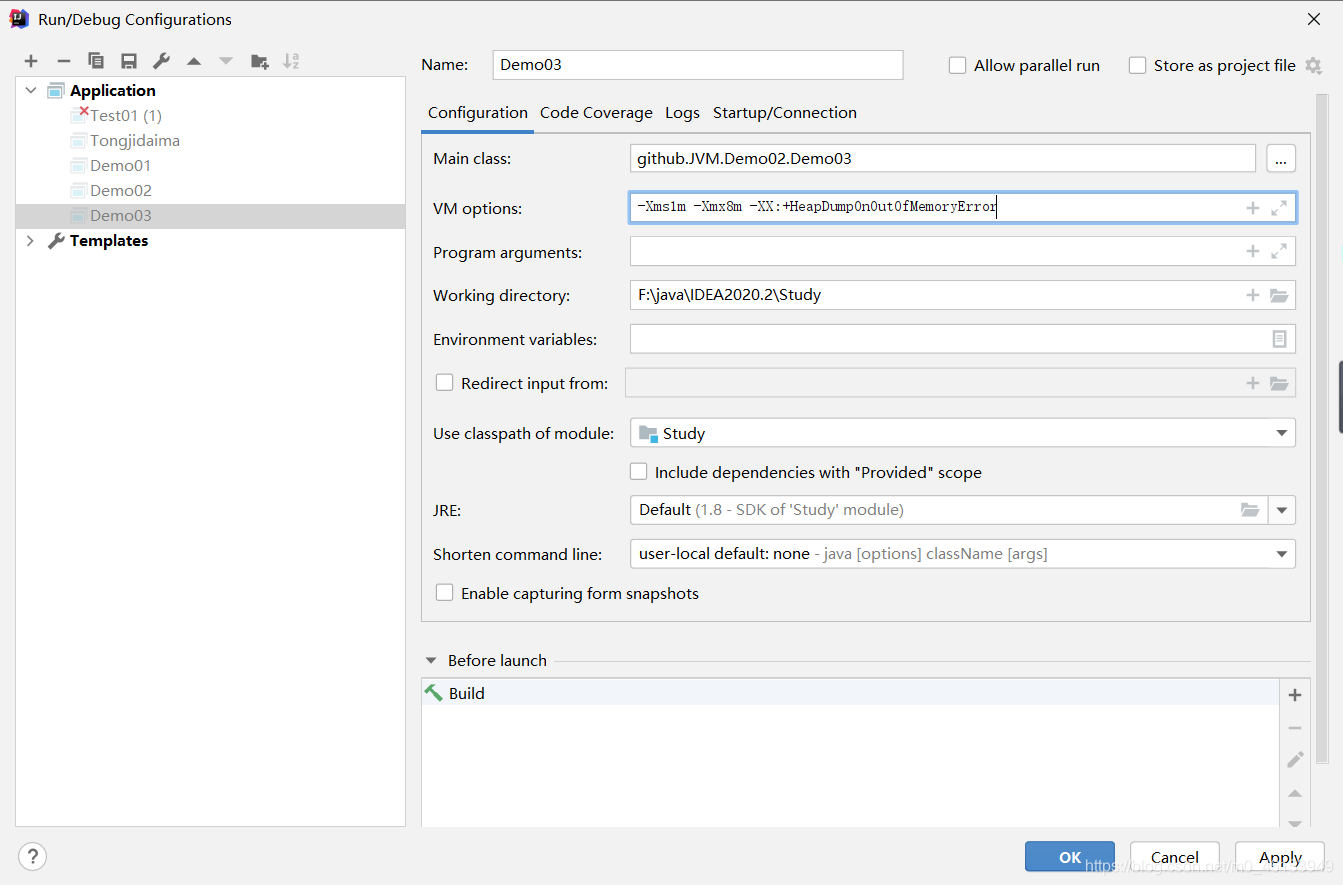
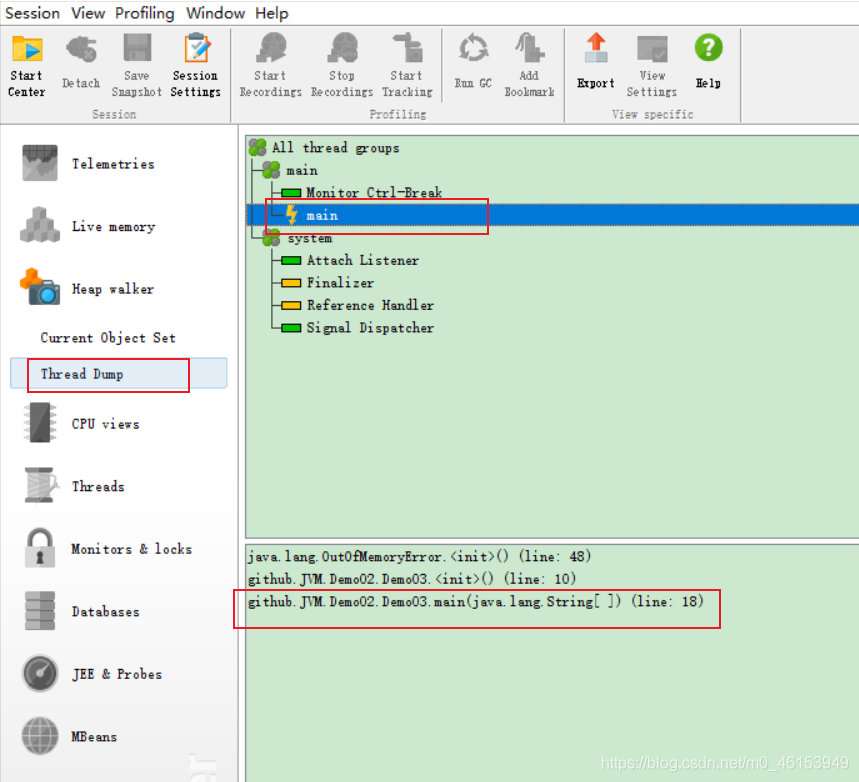
6.设置vm参数 : -Xms1m -Xmx8m -XX:+HeapDumpOnOutOfMemoryError
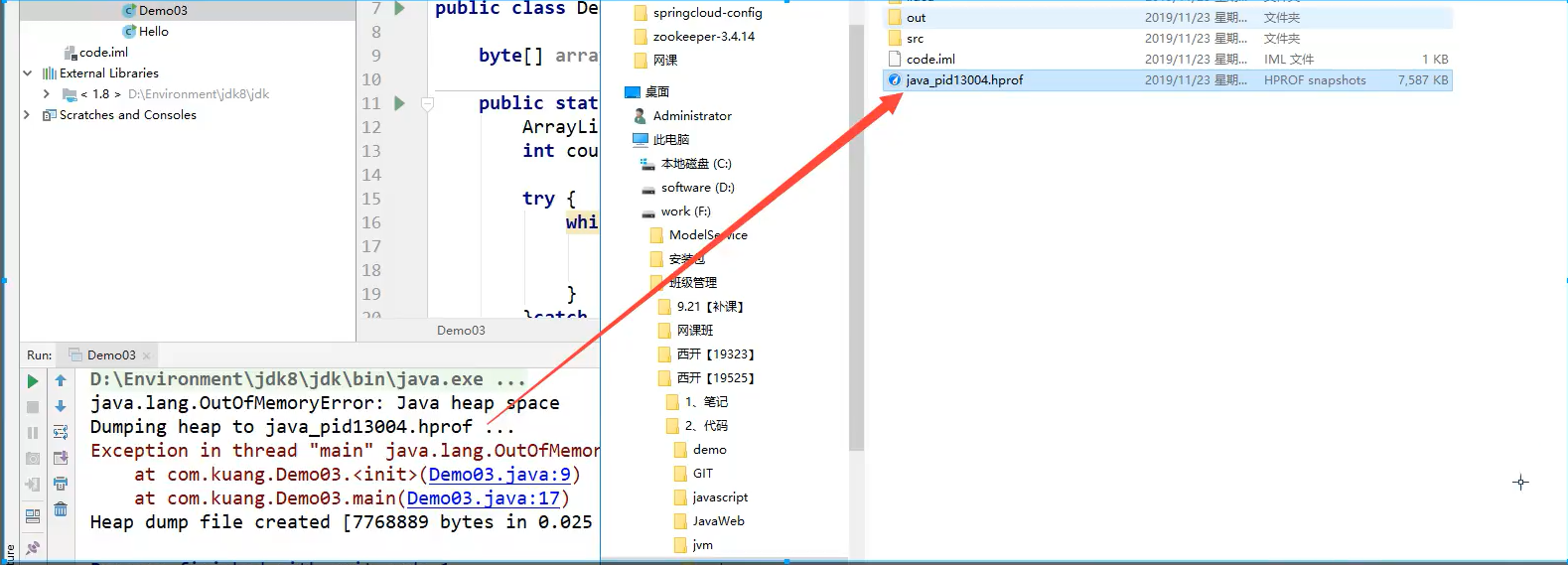
7.在src同级文件下找到生成的文件
8.使用 Jprofiler 工具分析查看
双击这个文件默认使用 Jprofiler 进行 Open的对象!
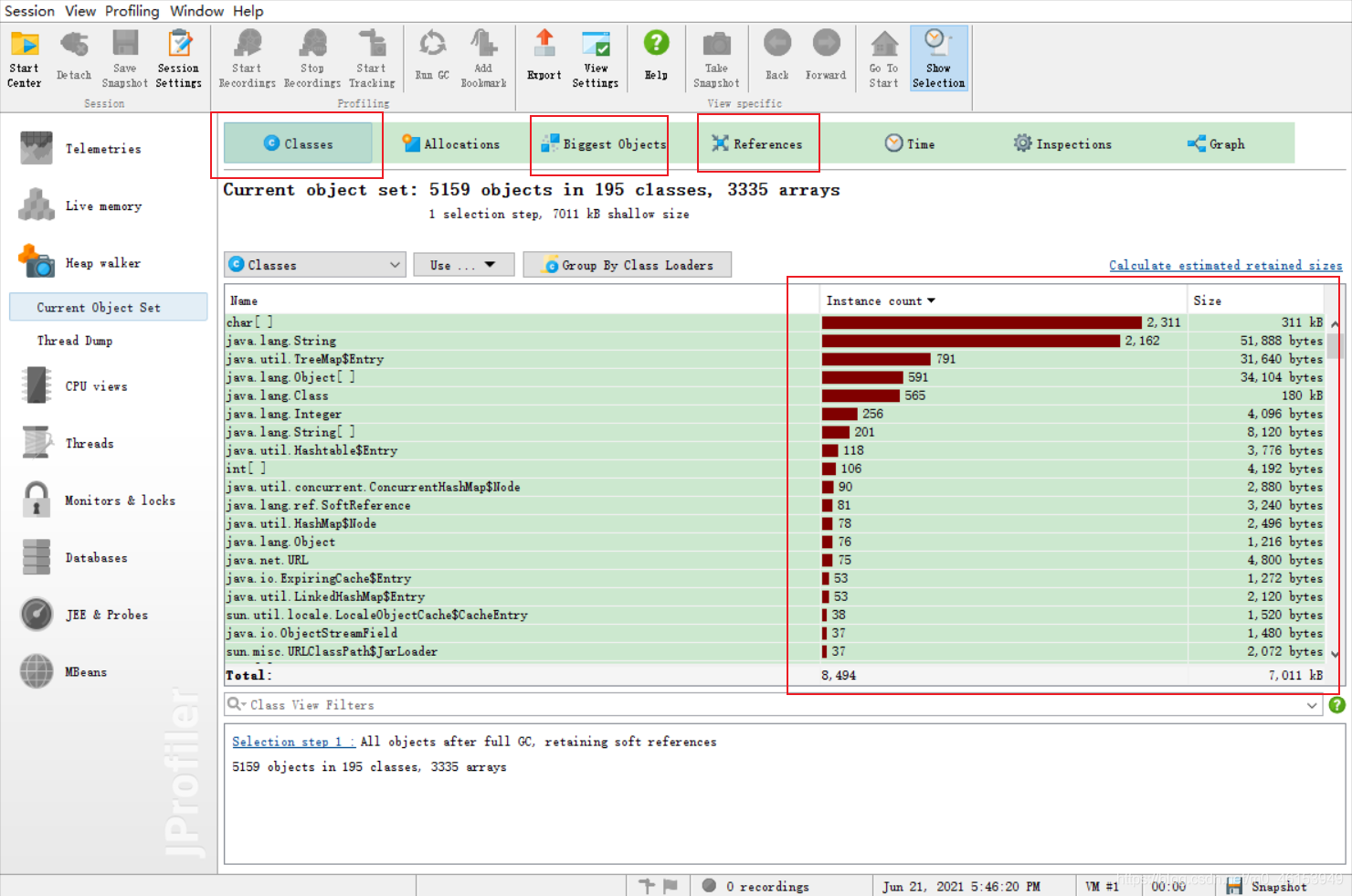
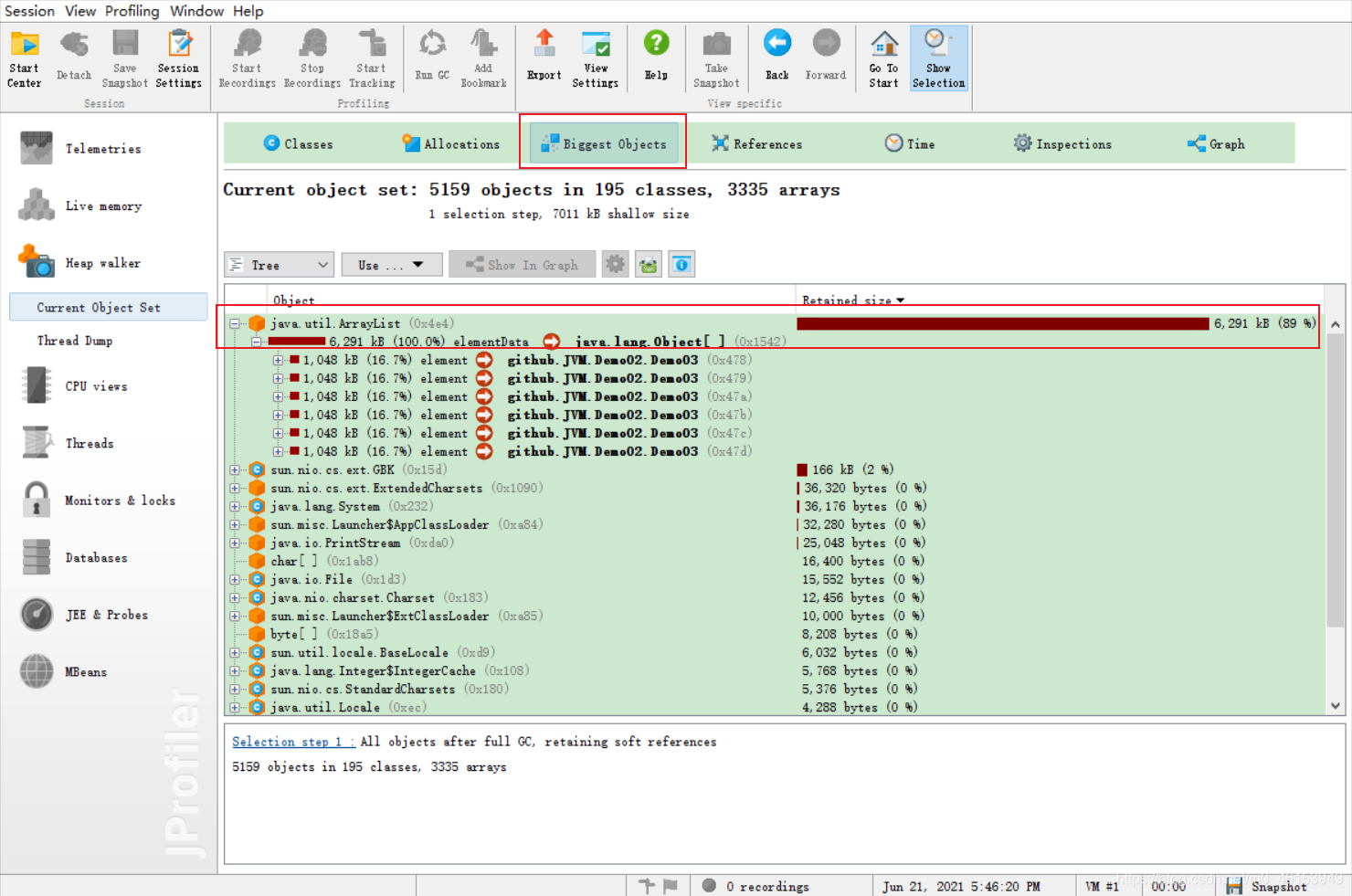
从软件开发的角度上,dump文件就是当程序产生异常时,用来记录当时的程序状态信息(例如堆栈的状态),用于程序开发定位问题。
7.3GC四大算法
7.3.1.引用计数法
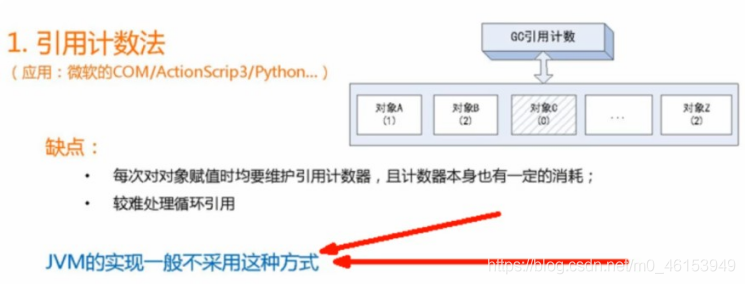
每个对象有一个引用计数器,当对象被引用一次则计数器加1,当对象引用失效一次,则计数器减1,对于计数器为0的对象意味着是垃圾对象,可以被GC回收。
目前虚拟机基本都是采用可达性算法,从GC Roots 作为起点开始搜索,那么整个连通图中的对象边都是活对象,对于GC Roots
无法到达的对象变成了垃圾回收对象,随时可被GC回收。
7.3.2.复制算法
年轻代中使用的是Minor GC,采用的就是复制算法(Copying)。
什么是复制算法?
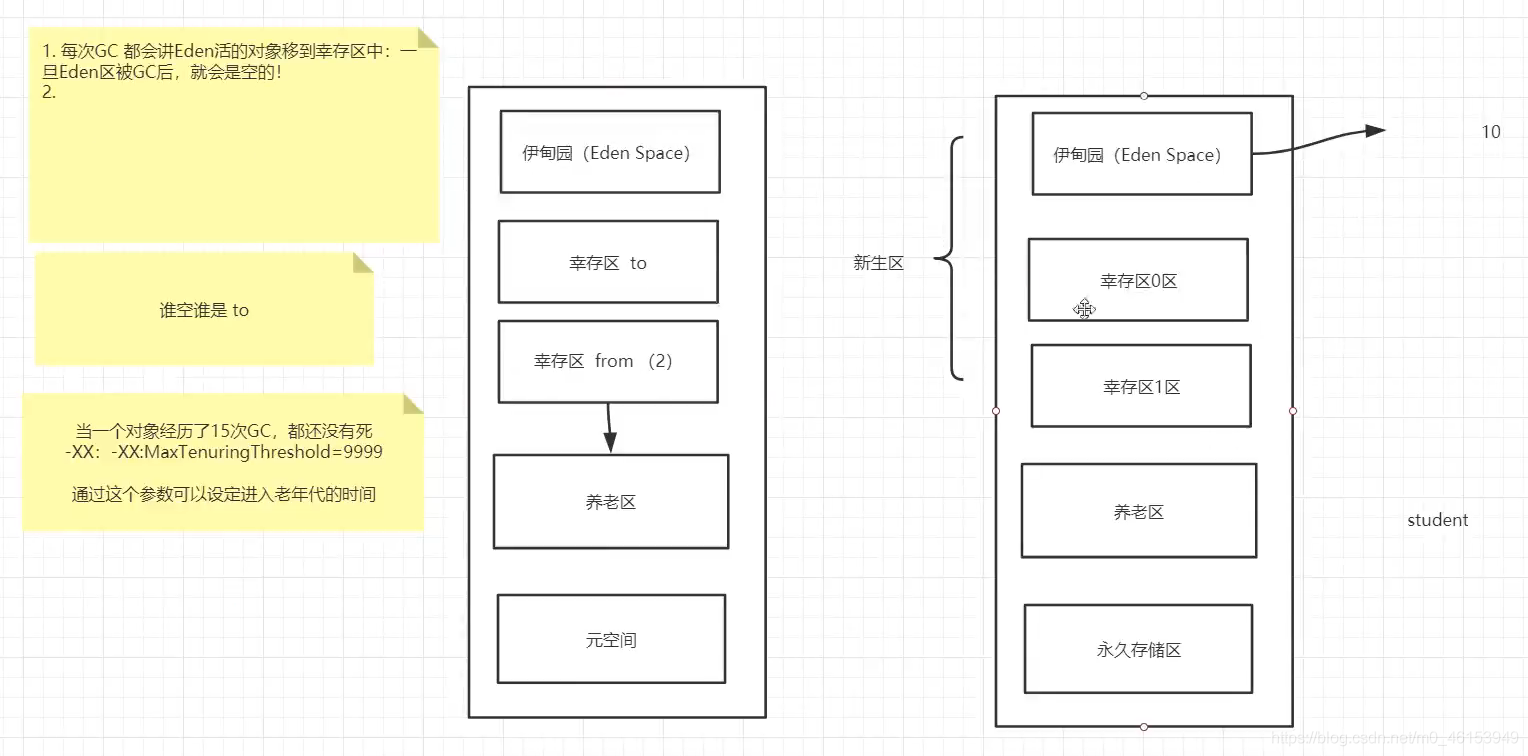
Minor GC会把Eden中的所有活的对象都移到Survivor区域中,如果Survivor区中放不下,那么剩下的活的对象就被移动到Oldgeneration中,也就是说,一旦收集后,Eden就是变成空的了。
当对象在Eden(包括一个Survivor区域,这里假设是From区域)出生后,在经过一次MinorGC后,如果对象还存活,并且能够被另外一块Survivor区域所容纳(上面已经假设为from区域,这里应为to区域,即to区域有足够的内存空间来存储Eden 和 From区域中存活的对象),则使用复制算法将这些仍然还活着的对象复制到另外一块Survivor区域(即 to 区域)中,然后清理所使用过的Eden 以及Survivor区域(即form区域),并且将这些对象的年龄设置为1,以后对象在Survivor区,每熬过一次MinorGC,就将这个对象的年龄 +1,当这个对象的年龄达到某一个值的时候(默认是15岁,通过- XX:MaxTenuringThreshold 设定参数)这些对象就会成为老年代。
-XX:MaxTenuringThreshold任期门槛=>设置对象在新生代中存活的次数
如何判断哪个是to区呢?一句话:谁空谁是to
原理解释:
- 年轻代中的GC,主要是复制算法(Copying)
- HotSpot JVM 把年轻代分为了三部分:一个 Eden 区 和 2 个Survivor区(from区 和 to区)。默认比例为 8:1:1,一般情况下,新创建的对象都会被分配到Eden区(一些大对象特殊处理),这些对象经过第一次Minor GC后,如果仍然存活,将会被移到Survivor区,对象在Survivor中每熬过一次Minor GC , 年龄就会增加1岁,当它的年龄增加到一定程度时,就会被移动到年老代中,因为年轻代中的对象基本上 都是朝生夕死,所以在年轻代的垃圾回收算法使用的是复制算法!复制算法的思想就是将内存分为两块,每次只用其中一块,当这一块内存用完,就将还活着的对象复制到另外一块上面。复制算法不会产 生内存碎片!
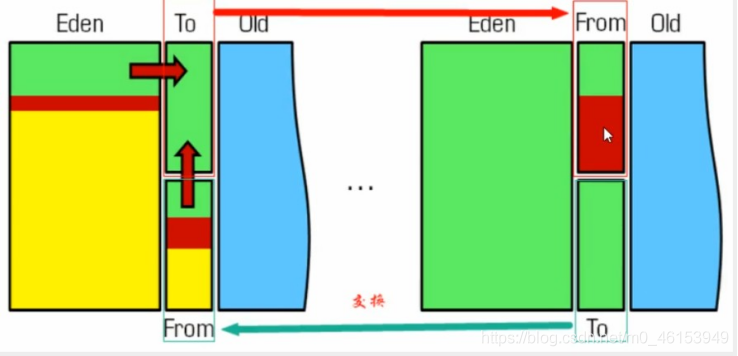
- 因为Eden区对象一般存活率较低,一般的,使用两块10%的内存作为空闲和活动区域,而另外80%的内存,则是用来给新建对象分配内存的。一旦发生GC,将10%的from活动区间与另外80%中存活的Eden 对象转移到10%的to空闲区域,接下来,将之前的90%的内存,全部释放,以此类推;
好处:没有内存碎片;
坏处:浪费内存空间。
劣势:
复制算法它的缺点也是相当明显的。
1、他浪费了一半的内存,这太要命了。
2、如果对象的存活率很高,我们可以极端一点,假设是100%存活,那么我们需要将所有对象都复制一遍,并将所有引用地址重置一遍。复制这一工作所花费的时间,在对象存活率达到一定程度时,将会变的不可忽视,所以从以上描述不难看出。复制算法要想使用,最起码对象的存活率要非常低才行,而且 最重要的是,我们必须要克服50%的内存浪费。
7.3.3.标记清除(Mark-Sweep)
回收时,对需要存活的对象进行标记;
回收不是绿色的对象。
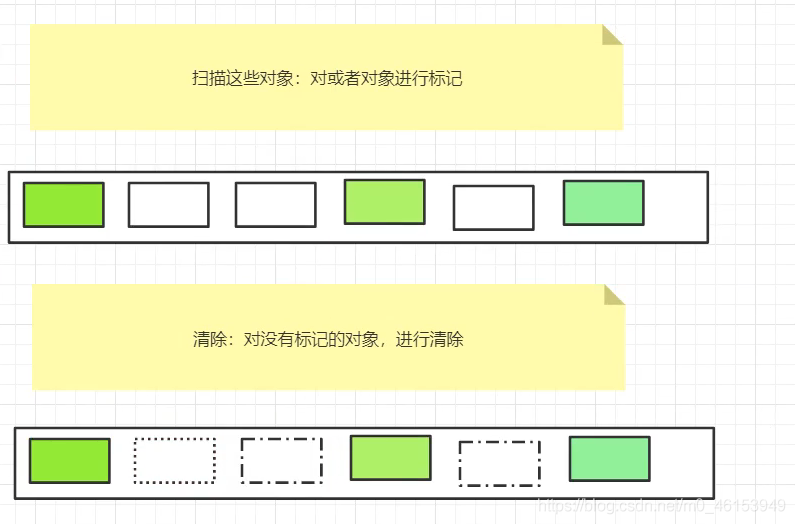
当堆中的有效内存空间被耗尽的时候,就会停止整个程序(也被称为stop the world),然后进行两项工作,第一项则是标记,第二项则是清除。
- 标记:从引用根节点开始标记所有被引用的对象,标记的过程其实就是遍历所有的GC Roots ,然后将所有GC Roots 可达的对象,标记为存活的对象。
- 清除: 遍历整个堆,把未标记的对象清除。
缺点:这个算法需要暂停整个应用,会产生内存碎片。两次扫描,严重浪费时间。
用通俗的话解释一下
标记/清除算法,就是当程序运行期间,若可以使用的内存被耗尽的时候,GC线程就会被触发并将程序暂停,随后将依旧存活的对象标记一遍,最终再将堆中所有没被标记的对象全部清除掉,接下来便让程序恢复运行
7.3.4标记压缩
说明:老年代一般是由标记清除或者是标记清除与标记整理的混合实现。
什么是标记压缩?
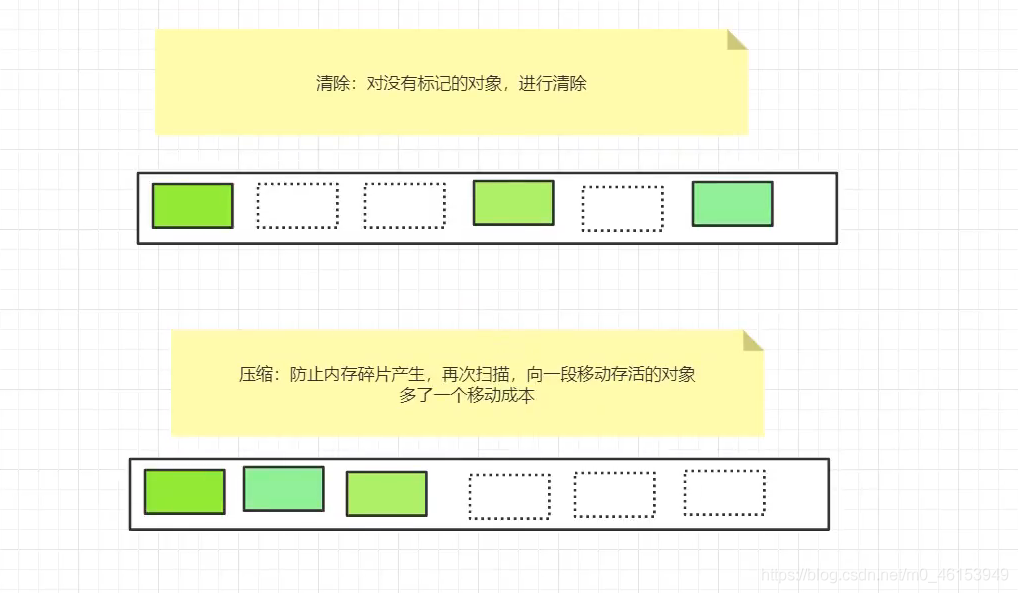

- 在整理压缩阶段,不再对标记的对象作回收,而是通过所有存活对象都像一端移动,然后直接清除边界以外的内存。可以看到,标记的存活对象将会被整理,按照内存地址依次排列,而未被标记的内存会被 清理掉,如此一来,当我们需要给新对象分配内存时,JVM只需要持有一个内存的起始地址即可,这比维护一个空闲列表显然少了许多开销。
- 标记、整理算法 不仅可以弥补 标记、清除算法当中,内存区域分散的缺点,也消除了复制算法当中,内存减半的高额代价;
7.3.5.结合标记清除压缩
先标记清除几次,再压缩。

7.4总结
- 内存效率:复制算法 > 标记清除算法 > 标记压缩算法 (时间复杂度);
- 内存整齐度:复制算法 = 标记压缩算法 > 标记清除算法;
- 内存利用率:标记压缩算法 = 标记清除算法 > 复制算法;
可以看出,效率上来说,复制算法是当之无愧的老大,但是却浪费了太多内存,而为了尽量兼顾上面所 提到的三个指标,标记压缩算法相对来说更平滑一些 , 但是效率上依然不尽如人意,它比复制算法多了一个标记的阶段,又比标记清除多了一个整理内存的过程.
难道就没有一种最优算法吗?
答案: 无,没有最好的算法,只有最合适的算法 。 —————-> 分代收集算法
年轻代:(Young Gen)
- 年轻代特点是区域相对老年代较小,对象存活低。
- 这种情况复制算法的回收整理,速度是最快的。复制算法的效率只和当前存活对象大小有关,因而很适 用于年轻代的回收。而复制算法内存利用率不高的问题,通过hotspot中的两个survivor的设计得到缓解
老年代:(Tenure Gen)
- 老年代的特点是区域较大,对象存活率高!
- 这种情况,存在大量存活率高的对象,复制算法明显变得不合适。一般是由标记清除或者是标记清除与标记整理的混合实现。Mark阶段的开销与存活对象的数量成正比,这点来说,对于老年代,标记清除或 者标记整理有一些不符,但可以通过多核多线程利用,对并发,并行的形式提标记效率。Sweep阶段的 开销与所管理里区域的大小相关,但Sweep “就地处决” 的 特点,回收的过程没有对象的移动。使其相对其他有对象移动步骤的回收算法,仍然是是效率最好的,但是需要解决内存碎片的问题。
8.扩展JMM
1.什么是JMM?
Java内存模型,是java虚拟机规范中所定义的一种内存模型,Java内存模型是标准化的,屏蔽掉了底层不同计算机的区别
2.他的作用
- 作用:缓存一致性协议,用于定义数据读写的规则(遵守,找到这个规则)。
- JMM定义了线程工作内存和主内存之间的抽象关系∶线程之间的共享变量存储在主内存(Main Memory)中,每个线程都有一个私有的本地内存(Local Memory)。
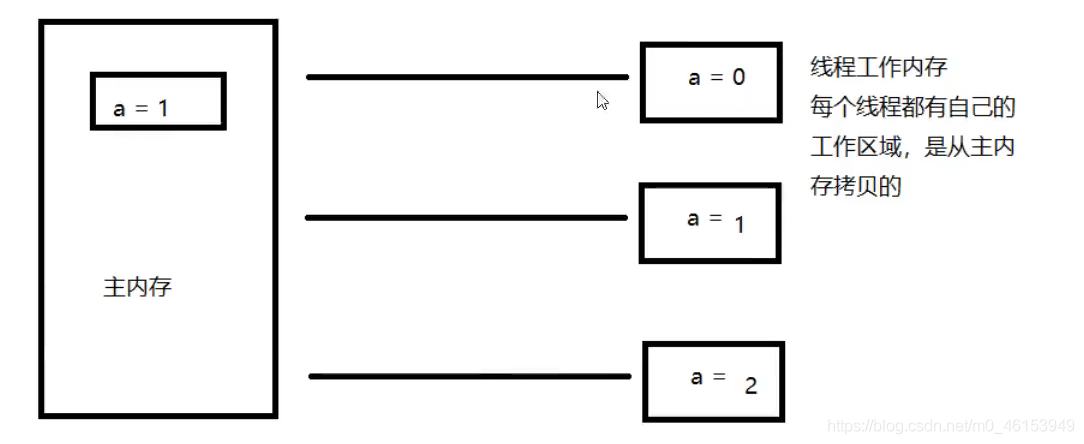
解决共享对象可见性这个问题:volilate
内存交互操作有8种,虚拟机实现必须保证每一个操作都是原子的,不可在分的(对于double和long类型的变量来说,load、store、read和write操作在某些平台上允许例外)
- lock (锁定):作用于主内存的变量,把一个变量标识为线程独占状态
- unlock (解锁):作用于主内存的变量,它把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定
- read (读取):作用于主内存变量,它把一个变量的值从主内存传输到线程的工作内存中,以便随后的load动作使用
- load (载入):作用于工作内存的变量,它把read操作从主存中变量放入工作内存中
- use (使用):作用于工作内存中的变量,它把工作内存中的变量传输给执行引擎,每当虚拟机遇到一个需要使用到变量的值,就会使用到这个指令
- assign (赋值):作用于工作内存中的变量,它把一个从执行引擎中接受到的值放入工作内存的变量副本中
- store (存储):作用于主内存中的变量,它把一个从工作内存中一个变量的值传送到主内存中,以便后续的write使用
- write (写入):作用于主内存中的变量,它把store操作从工作内存中得到的变量的值放入主内存的变量中
JMM对这八种指令的使用,制定了如下规则:
- 不允许read和load、store和write操作之一单独出现。即使用了read必须load,使用了store必须write
- 不允许线程丢弃他最近的assign操作,即工作变量的数据改变了之后,必须告知主存
- 不允许一个线程将没有assign的数据从工作内存同步回主内存
- 一个新的变量必须在主内存中诞生,不允许工作内存直接使用一个未被初始化的变量。就是怼变量实施use、store操作之前,必须经过assign和load操作
- 一个变量同一时间只有一个线程能对其进行lock。多次lock后,必须执行相同次数的unlock才能解锁
- 如果对一个变量进行lock操作,会清空所有工作内存中此变量的值,在执行引擎使用这个变量前,必须重新load或assign操作初始化变量的值
- 如果一个变量没有被lock,就不能对其进行unlock操作。也不能unlock一个被其他线程锁住的变量
- 对一个变量进行unlock操作之前,必须把此变量同步回主内存
这里详细上面规则
JMM对这八种操作规则和对volatile的一些特殊规则就能确定哪里操作是线程安全,哪些操作是线程不安全的了。但是这些规则实在复杂,很难在实践中直接分析。所以一般我们也不会通过上述规则进行分析。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/111683.html

