
目录
前言
中文分词所需要的词典放在公众号,关注文章末尾的公众号,回复“字典”获取!
这篇将使用Java实现基于规则的中文分词算法,一个中文词典将实现准确率高达85%的分词结果。使用经典算法:正向最大匹配和反向最大匹配算法,然后双剑合璧,双向最大匹配。
一、中文分词理论描述
根据相关资料,中文分词概念的理论描述,我总结如下:
中文分词是将一个汉字序列切分成一个一个单独的词,将连续的字序列按照一定的规范重新组合成词序列的过程,把字与字连在一起的汉语句子分成若干个相互独立、完整、正确的单词,词是最小的、能独立活动的、有意义的语言成分。
中文分词应用广泛,是文本挖掘的基础,在中文文本处理中意义重大,对于输入的一段中文,成功的进行中文分词,可以达到电脑自动识别语句含义的效果。目前,常用流行的以及分次效果好的工具库包括:jieba、HanLP、LTP、FudanNLP等。
我们知道,调用工具方便容易,但是如果自己实现写一个算法实现,那不是更加有成就感^_^。
接下来将一步步介绍最容易理解,最简单,效果还很不错的中文分词算法,据说准确率能达到85%!!
二、算法描述
1、正向最大匹配算法
所谓正向,就是从文本串左边正向扫描,取出子串与词典进行匹配。
算法我分为两步来理解:
假设初始化取最大匹配长度为MaxLen,当前位置pos=0,处理结果result=””,每次取词str,取词长度len,待处理串segstr。
- len=MaxLen,取字符串0到len的子串,查找词典,若匹配到则赋值str,加到result,在保证pos+len<=segstr.length()情况下,pos=pos+len,向后匹配,直到字符串扫描完成,结束算法。
- 若词典未找到,若len>1,减小匹配长度同时len=MaxLen-1,执行步骤(1),否则,取出剩余子串,执行步骤(1)。
算法代码如下:
public void MM(String str, int len, int frompos) {
if (frompos + 1 > str.length())
return;
String curstr = "";
//此处可以设置断点
int llen = str.length() - frompos;
if (llen <= len)//句末边界处理
curstr = str.substring(frompos, frompos + llen);//substring获取的子串是下标frompos~frompos+llen-1
else
curstr = str.substring(frompos, frompos + len);
if (dict.containsKey(curstr)) {
result = result + curstr + "/ ";
Len = MaxLen;
indexpos = frompos + len;
MM(str, Len, indexpos);
} else {
if (Len > 1) {
Len = Len - 1;
} else {
result = result + str + "/ ";
frompos = frompos + 1;
Len = MaxLen;
}
MM(str, Len, frompos);
}
}从算法代码看出,很容易理解,细节部分在于边界处理。
测试一下,我输入文本,“我爱自然语言处理,赞赏评论收藏我的文章是我的动力!赶紧关注!”
分词结果:


2、反向最大匹配算法
反向,则与正向相反,从文本串末向左进行扫描。
假设初始化取最大匹配长度为MaxLen,当前位置pos为字符串尾部,处理结果result=””,每次取词str,取词长度len,待处理串segstr。
- len=MaxLen,取字符串pos-len到pos的子串,查找词典,若匹配到则赋值str,加到result,同时pos=pos-len,保证pos-len>=0,向前移动匹配,直到字符串扫描完成,结束算法。
- 若词典未找到,若len>1,减小匹配长度同时len=MaxLen-1,执行步骤(1),否则,取出剩余子串,执行步骤(1)。
算法逻辑类似,取相反方向处理。
public void RMM(String str, int len, int frompos) {
if (frompos < 0)
return;
String curstr = "";
//此处可以设置断点
if (frompos - len + 1 >= 0)//句末边界处理
curstr = str.substring(frompos - len + 1, frompos + 1);//substring获取的子串是下标frompos~frompos+llen-1
else
curstr = str.substring(0, frompos + 1);//到达句首
if (dict.containsKey(curstr)) {
RmmResult = curstr + "/ " + RmmResult;
Len = MaxLen;
indexpos = frompos - len;
RMM(str, Len, indexpos);
} else {
if (Len > 1) {
Len = Len - 1;
} else {
RmmResult = RmmResult + str + "/ ";
frompos = frompos - 1;
Len = MaxLen;
}
RMM(str, Len, frompos);
}
}同样,细节部分在于边界处理,其他基本相同。
3、双剑合璧
这里所说的是正向与反向结合,实现双向最大匹配。
双向最大匹配算法,基于正向、反向最大匹配,对分词结果进一步处理,比较两个结果,做的工作就是遵循某些原则和经验,筛选出两者中更确切地分词结果。原则如下:
- 多数情况下,反向最大匹配效果更好,若分词结果相同,则返回RMM结果;
- 遵循切分最少词原则,更大匹配词为更好地分词结果,比较之后返回最少词的切分结果;
- 根据切分后词长度的大小,选择词长度大者为最终结果。
具体也需要看开始给定的最大匹配长度为多少。以下代码只实现了原则(1)、(2)。
public String BMM() throws IOException {
String Mr = MM_Seg();
String RMr = RMM_Seg();
if (Mr.equals(RMr)) {
return "双向匹配相同,结果为:" + Mr;
} else {
List<String> MStr;
List<String> RStr;
MStr = Arrays.asList(Mr.trim().split("/"));
RStr = Arrays.asList(RMr.trim().split("/"));
if (MStr.size() >= RStr.size()) {//多数情况下,反向匹配正确率更高
return "双向匹配不同,最佳结果为:" + RMr;
} else
return "双向匹配不同,最佳结果为:" + Mr;
}
}另外,这与使用的词典大小有关,是否包含常用词。
三、案例描述
如果上面还不能完全理解,下面的例子可以更好的理解算法执行过程。
正向最大匹配算法:
取MaxLen=3,SegStr=”对外经济技术合作与交流不断扩大”,maxNum=3,len=3,result=””,pos=0,curstr=””.
第一次,curstr=”对外经”,查找词典,未找到,将len-1,得到curstr=”对外”,此时匹配到词典,将结果加入result=”对外/ ”.pos=pos+len.
第二次,curstr=”经济技”,查找词典,未找到,将len-1,得到curstr=”经济”,此时匹配到词典,将结果加入result=”对外/ 经济/ ”.pos=pos+len.
以此类推…
最后一次,边界,pos=13,因为只剩下”扩大”两个字,所以取出全部,查找词典并匹配到,将结果加入result=”对外/ 经济/ 技术/ 合作/ 与/ 交流/ 不断/ 扩大/ ”.此时pos+1>SegStr.length(),结束算法。
反向最大匹配算法:
取MaxLen=3,SegStr=”对外经济技术合作与交流不断扩大”,maxNum=3,len=3,result=””,pos=14,curstr=””.
第一次,curstr=”断扩大”,查找词典,未找到,将len-1,得到curstr=”扩大”,此时匹配到词典,将结果加入result=”扩大/ ”.pos=pos-len.
第二次,MaxLen=3,curstr=”流不断”,查找词典,未找到,将len-1,得到curstr=”不断”,此时匹配到词典,将结果加入result=”不断/ 扩大/ ”.pos=pos-len.
以此类推…
最后一次,边界,pos=1,因为只剩下”对外”两个字,所以取出全部,查找词典并匹配到,将结果加入result=”对外/ 经济/ 技术/ 合作/ 与/ 交流/ 不断/ 扩大/ ”.此时pos-1<0,结束算法。
四、JAVA实现完整代码
除了分词算法实现,还需要读入词典,对词典进行预处理,具体
package ex1;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.*;
public class seg {
String result;
String RmmResult;
String segstring;
int MaxLen;
int Len;
int indexpos;
Map<String, String> dict;
public seg(String inputstr, int maxlen) {//构造函数
segstring = inputstr;
MaxLen = maxlen;
Len = MaxLen;
indexpos = 0;
result = "";
RmmResult = "";
dict = new HashMap<String, String>();
}
public void ReadDic() throws FileNotFoundException, IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream("chineseDic.txt"), "GBK"));
String line = null;
while ((line = br.readLine()) != null) {
String[] words = line.trim().split(",");//词典包含词性标注,需要将词与标注分开,放入列表
String word = words[0];
String cx = words[1];
dict.put(word, cx);
}
br.close();
}
public String MM_Seg() throws IOException {//正向最大匹配算法
try {
ReadDic();//读入字典
MM(segstring, MaxLen, 0);//正向最大分词
return result;
} catch (IOException e) {
return "Read Error!";
}
}
public void MM(String str, int len, int frompos) {
if (frompos + 1 > str.length())
return;
String curstr = "";
//此处可以设置断点
int llen = str.length() - frompos;
if (llen <= len)//句末边界处理
curstr = str.substring(frompos, frompos + llen);//substring获取的子串是下标frompos~frompos+llen-1
else
curstr = str.substring(frompos, frompos + len);
if (dict.containsKey(curstr)) {
result = result + curstr + "/ ";
Len = MaxLen;
indexpos = frompos + len;
MM(str, Len, indexpos);
} else {
if (Len > 1) {
Len = Len - 1;
} else {
result = result + str + "/ ";
frompos = frompos + 1;
Len = MaxLen;
}
MM(str, Len, frompos);
}
}
public String RMM_Seg() throws IOException {//正向最大匹配算法
try {
ReadDic();//读入字典
RMM(segstring, MaxLen, segstring.length() - 1);//正向最大分词
return RmmResult;
} catch (IOException e) {
return "Read Error!";
}
}
public void RMM(String str, int len, int frompos) {
if (frompos < 0)
return;
String curstr = "";
//此处可以设置断点
if (frompos - len + 1 >= 0)//句末边界处理
curstr = str.substring(frompos - len + 1, frompos + 1);//substring获取的子串是下标frompos~frompos+llen-1
else
curstr = str.substring(0, frompos + 1);//到达句首
if (dict.containsKey(curstr)) {
RmmResult = curstr + "/ " + RmmResult;
Len = MaxLen;
indexpos = frompos - len;
RMM(str, Len, indexpos);
} else {
if (Len > 1) {
Len = Len - 1;
} else {
RmmResult = RmmResult + str + "/ ";
frompos = frompos - 1;
Len = MaxLen;
}
RMM(str, Len, frompos);
}
}
public String BMM() throws IOException {
String Mr = MM_Seg();
String RMr = RMM_Seg();
if (Mr.equals(RMr)) {
return "双向匹配相同,结果为:" + Mr;
} else {
List<String> MStr;
List<String> RStr;
MStr = Arrays.asList(Mr.trim().split("/"));
RStr = Arrays.asList(RMr.trim().split("/"));
if (MStr.size() >= RStr.size()) {//多数情况下,反向匹配正确率更高
return "双向匹配不同,最佳结果为:" + RMr;
} else
return "双向匹配不同,最佳结果为:" + Mr;
}
}
public String getResult() {
return result;
}
public static void main(String[] args) throws IOException, Exception {
seg s = new seg("我爱自然语言处理,赞赏评论收藏我的文章是我的动力!赶紧关注!", 3);
// String result = s.MM_Seg();
String result = s.RMM_Seg();
System.out.println(result);
}
}五、组装UI
我是用的开发软件为是IDEA,一个方便之处可以拖动组件组装UI界面。也可以自行写JavaFX实现简单布局。
这是简单页面的设计:
UI界面可以有更好的用户体验,通过UI界面的元素调用方法,减少每次测试运行算法脚本的繁琐。
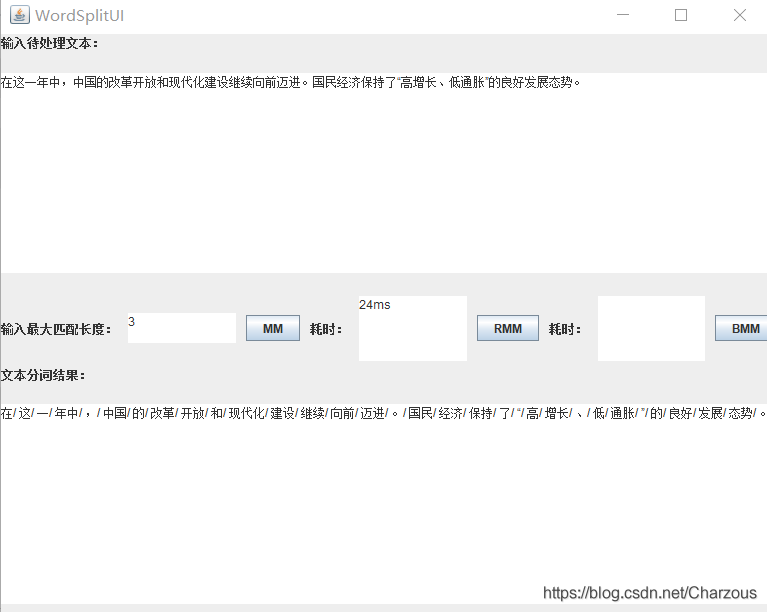
实验演示:
每次可以观察不同最大匹配长度分词后的结果。
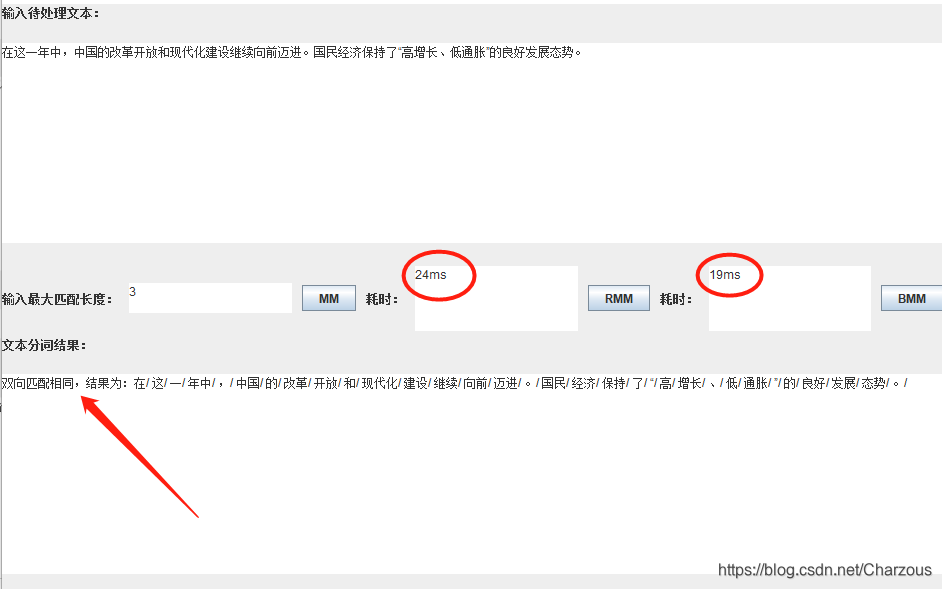
“年中”词语解析:
在词典中,是这样的,可以发现满足最大匹配。


双向最大匹配算法,结果提示:
六、总结
这篇介绍了使用Java实现基于规则的中文分词算法,使用经典算法:正向最大匹配和反向最大匹配算法,然后双剑合璧,双向最大匹配。最后设计简单UI界面,实现稍微高效的中文分词处理,结果返回。
- 双向最大匹配算法原则,希望句子最长词保留完整、最短词数量最少、单字词问题,目前只解决了句子切分最少词问题。
- 正向反向匹配算法可以进一步优化结构,提高执行效率,目前平均耗时20ms。
- UI界面增加输入输出提示语,方便用户使用,在正确的区域输入内容。
- 将最大匹配长度设置为可输入,实现每次可以观察不同MaxLen得到的切分结果。
-
双向最大匹配按钮点击之后,返回结果同时返回MM和RMM结果是否一样的提示,方便查看。
中文分词所需要的词典放在公众号,关注文章末尾的公众号,回复“字典”获取!
我的CSDN博客: 双向最大匹配算法——基于词典规则的中文分词(Java实现)_陆海潘江小C的博客-CSDN博客_双向匹配算法
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/11352.html

