
项目代码已上传git
https://gitee.com/gangye/springboot_kafka
一.首先安装zookeeper,kafka的启动需要依赖zookeeper
1.下载安装包
http://zookeeper.apache.org/releases.html#download
2.解压文件进入ZooKeeper目录,本人加压路径: F:\server\apache-zookeeper-3.6.1-bin\conf,将“zoo_sample.cfg”重命名为“zoo.cfg”
3. 打开“zoo.cfg”找到并编辑dataDir=F:\server\Kafka\apache-zookeeper-3.6.1-bin\data
4.配置环境变量,在path中添加F:\server\Kafka\apache-zookeeper-3.6.1-bin\bin
5.在zoo.cfg文件中修改默认的Zookeeper端口(默认端口2181)
6.在cmd指令中输入“zkServer”,运行Zookeeper
二.安装Kafka
1.下载安装包
http://kafka.apache.org/downloads
注意:下载二进制版本


2. 解压并进入Kafka目录,本人:F:\server\Kafka\kafka_2.12-0.11.0.0,进入config目录找到文件server.properties并打开
3.找到并编辑配置日志路径:log.dirs=F:\server\Kafka\kafka_2.12-0.11.0.0\kafka-logs
4.找到并编辑zooKeeper的连接地址端口zookeeper.connect=localhost:2181
5. Kafka会按照默认,在9092端口上运行,并连接zookeeper的默认端口:2181
6.进入Kafka安装目录F:\server\Kafka\kafka_2.12-0.11.0.0,按下Shift+右键,选择“打开命令窗口”选项,打开命令行,输入:
.\bin\windows\kafka-server-start.bat .\config\server.properties三.测试
1、 创建主题,进入Kafka安装目录F:\server\Kafka\kafka_2.12-0.11.0.0,打开命令窗口,打开命令行,输入:
.\bin\windows\kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test结果:

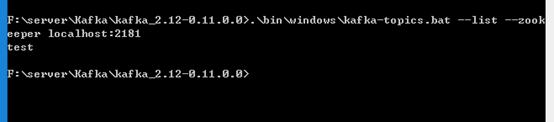
查看主题输入:
.\bin\windows\kafka-topics.bat --list --zookeeper localhost:2181结果:
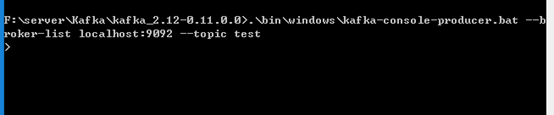
2.创建生产者,进入Kafka的安装目录F:\server\Kafka\kafka_2.12-0.11.0.0,打开命令窗口选项,打开命令行,输入:
.\bin\windows\kafka-console-producer.bat --broker-list localhost:9092 --topic test结果:
3.创建消费者,进入Kafka的安装目录F:\server\Kafka\kafka_2.12-0.11.0.0,打开命令窗口选项,打开命令行,输入:
.\bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test --from-beginning结果:

四.回归正题,Kafka结合SpringBoot
1.创建项目,引入pom依赖
<dependencies>
<!--spring-boot-starter-actuator(健康监控)配置和使用
在生产环境中,需要实时或定期监控服务的可用性。
Spring Boot的actuator(健康监控)功能提供了很多监控所需的接口,可以对应用系统进行配置查看、相关功能统计等。
-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
2.配置生产者的配置文件
#============== kafka ===================
# 指定kafka server的地址,集群配多个,中间,逗号隔开
spring.kafka.bootstrap-servers=127.0.0.1:9092
#=============== provider =======================
# 写入失败时,重试次数。当leader节点失效,一个repli节点会替代成为leader节点,此时可能出现写入失败,
# 当retris为0时,produce不会重复。retirs重发,此时repli节点完全成为leader节点,不会产生消息丢失。
spring.kafka.producer.retries=0
# 每次批量发送消息的数量,produce积累到一定数据,一次发送
spring.kafka.producer.batch-size=16384
# produce积累数据一次发送,缓存大小达到buffer.memory就发送数据
spring.kafka.producer.buffer-memory=33554432
#procedure要求leader在考虑完成请求之前收到的确认数,用于控制发送记录在服务端的持久化,其值可以为如下:
#acks = 0 如果设置为零,则生产者将不会等待来自服务器的任何确认,该记录将立即添加到套接字缓冲区并视为已发送。在这种情况下,无法保证服务器已收到记录,并且重试配置将不会生效(因为客户端通常不会知道任何故障),为每条记录返回的偏移量始终设置为-1。
#acks = 1 这意味着leader会将记录写入其本地日志,但无需等待所有副本服务器的完全确认即可做出回应,在这种情况下,如果leader在确认记录后立即失败,但在将数据复制到所有的副本服务器之前,则记录将会丢失。
#acks = all 这意味着leader将等待完整的同步副本集以确认记录,这保证了只要至少一个同步副本服务器仍然存活,记录就不会丢失,这是最强有力的保证,这相当于acks = -1的设置。
#可以设置的值为:all, -1, 0, 1
spring.kafka.producer.acks=1
# 指定消息key和消息体的编解码方式
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
注:
- bootstrap.servers:kafka server的地址
- acks:写入kafka时,leader负责一个该partion读写,当写入partition时,需要将记录同步到repli节点,all是全部同步节点都返回成功,leader才返回ack。
- retris:写入失败时,重试次数。当leader节点失效,一个repli节点会替代成为leader节点,此时可能出现写入失败,当retris为0时,produce不会重复。retirs重发,此时repli节点完全成为leader节点,不会产生消息丢失。
- batch.size:produce积累到一定数据,一次发送。
- buffer.memory:produce积累数据一次发送,缓存大小达到buffer.memory就发送数据。
- linger.ms:当设置了缓冲区,消息就不会即时发送,如果消息总不够条数、或者消息不够buffer大小就不发送了吗?当消息超过linger时间,也会发送。
- key/value serializer:序列化类。
3.生产者香kafka发送消息
@Slf4j
@RestController
@RequestMapping(value = "kafkaProducer")
public class KafkaProducerController {
@Autowired
private KafkaTemplate<String ,Object> kafkaTemplate;
private Gson gson = new GsonBuilder().create();
@GetMapping(value = "/sendMessage")
public Response sendMessage(){
Response response = Response.newResponse();
Message message = new Message();
message.setId(System.currentTimeMillis());
message.setMessage(UUID.randomUUID().toString());
message.setSendTime(new Date());
log.info("+++++++++++++++++++++ message = {}", gson.toJson(message));
kafkaTemplate.send("testTopic",gson.toJson(message));
return response.OK();
}
}
4.在消费者项目中配置文件信息
#============== kafka ===================
# 指定kafka server的地址,集群配多个,中间,逗号隔开
spring.kafka.bootstrap-servers=127.0.0.1:9092
#=============== consumer =======================
# 指定默认消费者group id --> 由于在kafka中,同一组中的consumer不会读取到同一个消息,依靠groud.id设置组名
spring.kafka.consumer.group-id=testGroup
# smallest和largest才有效,如果smallest重新0开始读取,如果是largest从logfile的offset读取。一般情况下我们都是设置smallest
spring.kafka.consumer.auto-offset-reset=earliest
# enable.auto.commit:true --> 设置自动提交offset
spring.kafka.consumer.enable-auto-commit=true
#如果'enable.auto.commit'为true,则消费者偏移自动提交给Kafka的频率(以毫秒为单位),默认值为5000。
spring.kafka.consumer.auto-commit-interval=100
# 指定消息key和消息体的编解码方式
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
5.消费者监听topic=testTopic的消息
@Slf4j
@Component
public class ConsumerListener {
@KafkaListener(topics = "testTopic")
public void consumeMessage(ConsumerRecord<?,?> record){
Optional<?> kafkaMessage = Optional.ofNullable(record.value());
if (kafkaMessage.isPresent()){
Object message = kafkaMessage.get();
log.info("----------------- record =" + record);
log.info("----------------- message =" + message);
}
}
}
6.启动生产者和消费者项目
注:启动项目之前,必须确保zooKeeper和kafka服务启动成功
首先生产一个记录,由于是get请求,直接可在浏览器测试

可以在生产者以及消费者的项目看到消息日志:
生产者:
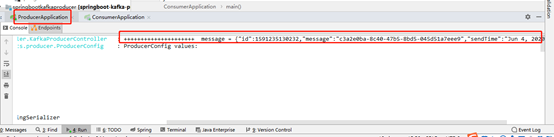
消费者:

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/12317.html

