
1.Apache Kafka – 简介
Apache Kafka是一个分布式发布 – 订阅消息系统和一个强大的队列,可以处理大量的数据,并使您能够将消息从一个端点传递到另一个端点。 Kafka适合离线和在线消息消费。 Kafka消息保留在磁盘上,并在群集内复制以防止数据丢失。 Kafka构建在ZooKeeper同步服务之上。 它与Apache Storm和Spark非常好地集成,用于实时流式数据分析。Kafka专为分布式高吞吐量系统而设计。 Kafka往往工作得很好,作为一个更传统的消息代理的替代品。 与其他消息传递系统相比,Kafka具有更好的吞吐量,内置分区,复制和固有的容错能力,这使得它非常适合大规模消息处理应用程序。Kafka的具体理论知识可以查看官方文档介绍,http://kafka.apache.org/。
2.Kafka的安装
首先确保已经安装过java环境,如果没有可以去官网下载对应版本的jdk。我用的是jdk-8u161-linux-x64.tar.gz,zookeeper-3.4.10.tar.gz,kafka_2.11-1.1.0.tgz。
然后需要安装zookeeper,
tar -zxf zookeeper-3.4.10.tar.gz
cd zookeeper-3.4.10
mkdir data
vi conf/zoo.cfg
tickTime=2000
dataDir=/opt/zookeeper-3.4.10/data
clientPort=2181
initLimit=5
syncLimit=2
启用zookeeper:bin/zkServer.sh start
最后就是Kafka的安装:
cd /opt
tar -zxf kafka_2.11-1.1.0.tgz
cd kafka_2.11-1.1.0
启动: bin/kafka-server-start.sh config/server.properties,你将看到如下信息

关闭的话输入 bin/kafka-server-stop.sh config/server.properties 即可。
后台启动命令,bin/kafka-server-start.sh config/server.properties 1>/dev/null 2>&1 &
3.代码实现生产者
新建一个maven项目(当然java项目或SpringBoot项目也可以),引入所需jar包,pom.xml如下。
1 <?xml version="1.0" encoding="UTF-8"?> 2 <project xmlns="http://maven.apache.org/POM/4.0.0" 3 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" 4 xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> 5 <modelVersion>4.0.0</modelVersion> 6 7 <groupId>cn.sp</groupId> 8 <artifactId>kafka-demo</artifactId> 9 <version>1.0-SNAPSHOT</version> 10 11 <dependencies> 12 <!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka --> 13 <dependency> 14 <groupId>org.apache.kafka</groupId> 15 <artifactId>kafka_2.12</artifactId> 16 <version>1.1.0</version> 17 </dependency> 18 19 <!-- https://mvnrepository.com/artifact/org.slf4j/slf4j-log4j12 --> 20 <dependency> 21 <groupId>org.slf4j</groupId> 22 <artifactId>slf4j-log4j12</artifactId> 23 <version>1.7.25</version> 24 <!--<scope>test</scope>--> 25 </dependency> 26 27 <!-- https://mvnrepository.com/artifact/log4j/log4j --> 28 <dependency> 29 <groupId>log4j</groupId> 30 <artifactId>log4j</artifactId> 31 <version>1.2.17</version> 32 </dependency> 33 34 </dependencies> 35 36 37 38 </project>
消息生产者代码:
1 import org.apache.kafka.clients.producer.KafkaProducer; 2 import org.apache.kafka.clients.producer.Producer; 3 import org.apache.kafka.clients.producer.ProducerRecord; 4 5 import java.util.Properties; 6 7 /** 8 * Created by 2YSP on 2018/4/3. 9 */ 10 public class ProducerTest { 11 12 public static void main(String[] args) { 13 if (args.length == 0) { 14 System.out.println("Enter topic name"); 15 return; 16 } 17 18 //Assign topicName to string variable 19 String topicName = args[0]; 20 21 //create instance for properties to access producer configs 22 Properties props = new Properties(); 23 24 //Assign localhost id 192.168.75.132 25 props.put("bootstrap.servers","192.168.75.132:9092"); 26 27 props.put("acks","all"); 28 29 //If the request fails, the producer can automatically retry, 30 props.put("retries",0); 31 32 //Specify buffer size in config 33 props.put("batch.size",16384); 34 35 props.put("buffer.memory",33554432); 36 37 props.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer"); 38 props.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer"); 39 40 Producer<String,String> producer = new KafkaProducer<String, String>(props); 41 for (int i=0;i<10;i++){ 42 producer.send(new ProducerRecord<String, String>(topicName,Integer.toString(i),Integer.toString(i))); 43 44 } 45 System.out.println("message send successfully"); 46 producer.close(); 47 } 48 }
当然,这里也可以弄一个.properties文件,然后代码里加载配置,运行时需要添加主题参数,我用的是idea就比较简单了。
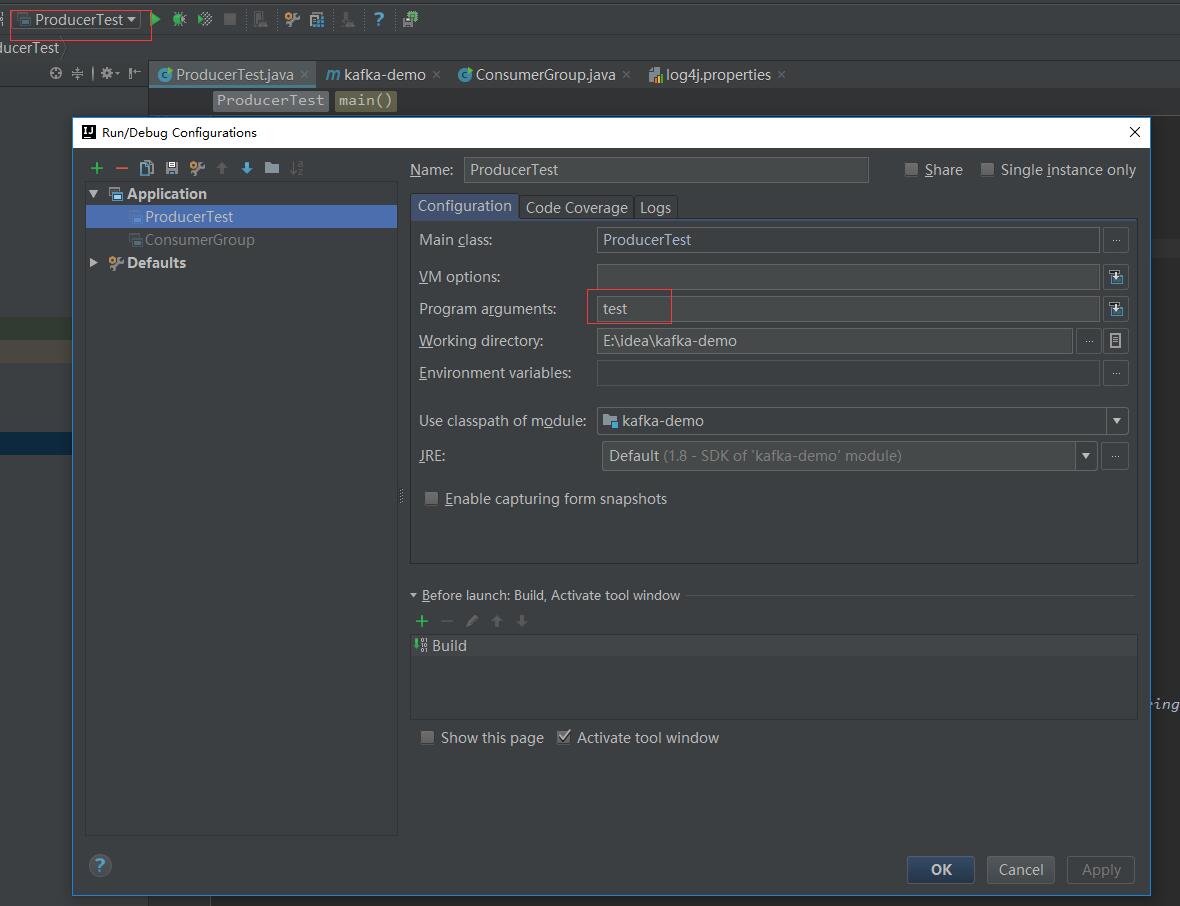
4.代码实现消费者
1 import org.apache.kafka.clients.consumer.ConsumerRecord; 2 import org.apache.kafka.clients.consumer.ConsumerRecords; 3 import org.apache.kafka.clients.consumer.KafkaConsumer; 4 5 import java.util.Arrays; 6 import java.util.Properties; 7 8 /** 9 * Created by 2YSP on 2018/4/3. 10 */ 11 public class ConsumerGroup { 12 13 public static void main(String[] args) { 14 if (args.length < 2){ 15 System.out.println("Usage: consumer <topic> <groupname> "); 16 return; 17 } 18 19 20 String topic = args[0]; 21 String group = args[1]; 22 23 Properties props = new Properties(); 24 props.put("bootstrap.servers","192.168.75.132:9092"); 25 props.put("group.id",group); 26 props.put("enable.auto.commit","true"); 27 props.put("auto.commit.interval.ms","1000"); 28 props.put("session.timeout.ms","30000"); 29 //当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费 30 props.put("auto.offset.reset", "earliest"); 31 props.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer"); 32 props.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer"); 33 34 KafkaConsumer<String,String> consumer = new KafkaConsumer<String, String>(props); 35 36 consumer.subscribe(Arrays.asList(topic)); 37 while (true){ 38 ConsumerRecords<String, String> records = consumer.poll(200); 39 for(ConsumerRecord<String, String> record:records){ 40 System.out.printf("============offset = %d,key = %s,value=%s\n",record.offset(),record.key(),record.value()); 41 } 42 //提交已经拉取出来的offset,如果是手动模式下面,必须拉取之后提交,否则以后会拉取重复消息 43 consumer.commitSync(); 44 45 try { 46 Thread.sleep(100); 47 } catch (InterruptedException e) { 48 e.printStackTrace(); 49 } 50 } 51 } 52 }
先运行生产者代码,再运行消费者代码,控制台输出如下:
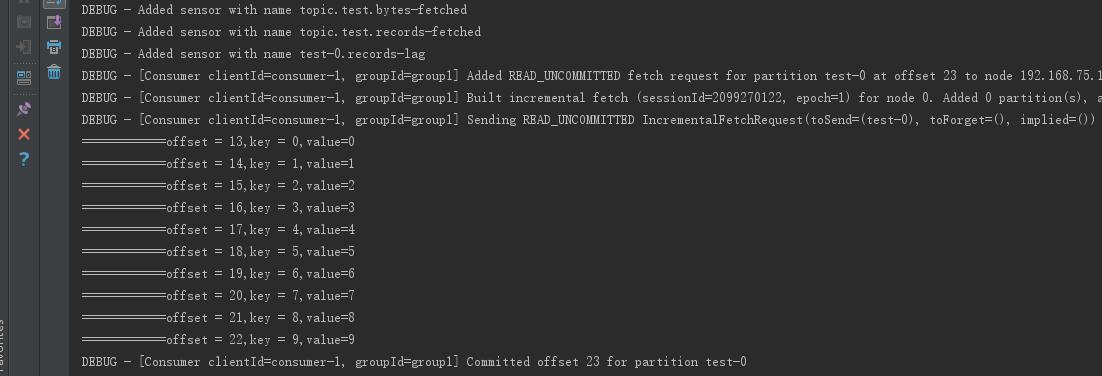
5.遇到的坑
本以为很简单的,结果中间遇到了很多坑,所以想记录下。
坑一:kafka_2.11-0.9.0.0.tgz这个版本的kafka一运行发送消息命令(bin/kafka-console-producer.sh –broker-list localhost:9092 –topic topic-name)就卡死了,弄了半天也找不到原因,无奈换了版本。
坑二:引入日志jar包不全,运行报错,折腾了一会儿。
坑三:一运行代码就报连接不上的错误,抛异常。
解决办法:找到config文件夹下的server.properties文件,修改advertised.listeners=PLAINTEXT://192.168.75.132:9092,其中192.168.75.132是我虚拟机的ip地址,以便外网访问。
再找到consumer.properties文件,bootstrap.servers=192.168.75.132:9092,group.id=group1,这里的group.id也可以不改就用默认的,但是代码配置里的一定要一样。
坑四:然后还是无法连接,想到防火墙问题就准备改端口,发现centos7的/etc/sysconfig文件夹下没有iptables文件。。。
解决办法:照着网上的办法弄好了,连接地址,又觉得改配置麻烦就索性关闭防火墙了。
至此,程序终于跑通了。。。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/13272.html

