
一、概述
什么是ElasticSearch?
ElasticSearch,简称为ES, ES是一个开源的高扩展的分布式全文搜索引擎。
它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。
ES也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
ES核心概念
知道了ES是什么后,接下来还需要知道ES是如何存储数据,数据结构是什么,又是如何实现搜索的呢?
学习这些之前需要先了解一些ElasticSearch的相关概念。
ElasticSearch是面向文档型数据库
相信学习过MySql的同学都知道,MySql是关系型数据库,那么ES与关系型数据库有什么区别呢?
下面做一下简单的对比:
| 关系型数据库(MySql、Oracle等) | ElasticSearch |
|---|---|
| 数据库(database) | 索引(indices) |
| 表(tables) | 类型(types) |
| 行(rows) | 文档(documents) |
| 列(columns) | 字段(fields) |
说明:ElasticSearch(集群)中可以包含多个索引(数据库),每个索引中可以包含多个类型(表),每个类型下又包含多 个文档(行),每个文档中又包含多个字段(列)。
物理设计:
ElasticSearch 在后台把每个索引划分成多个分片,每份分片可以在集群中的不同服务器间迁移。
逻辑设计:
一个索引类型中,包含多个文档,比如说文档1,文档2,文档3。
当我们索引一篇文档时,可以通过这样的一个顺序找到它: 索引 ▷ 类型 ▷ 文档ID ,通过这个组合我们就能索引到某个具体的文档。 注意:ID不必是整数,实际上它是个字符串。
索引
索引是映射类型的容器,elasticsearch中的索引是一个非常大的文档集合。索引存储了映射类型的字段和其他设置。 然后它们被存储到了各个分片上了。 我们来研究下分片是如何工作的。
物理设计 :节点和分片 如何工作
一个集群至少有一个节点,而一个节点就是一个elasricsearch进程,节点可以有多个索引默认的,如果你创建索引,那么索引将会有个5个分片 ( primary shard ,又称主分片 ) 构成的,每一个主分片会有一个副本 ( replica shard ,又称复制分片 )
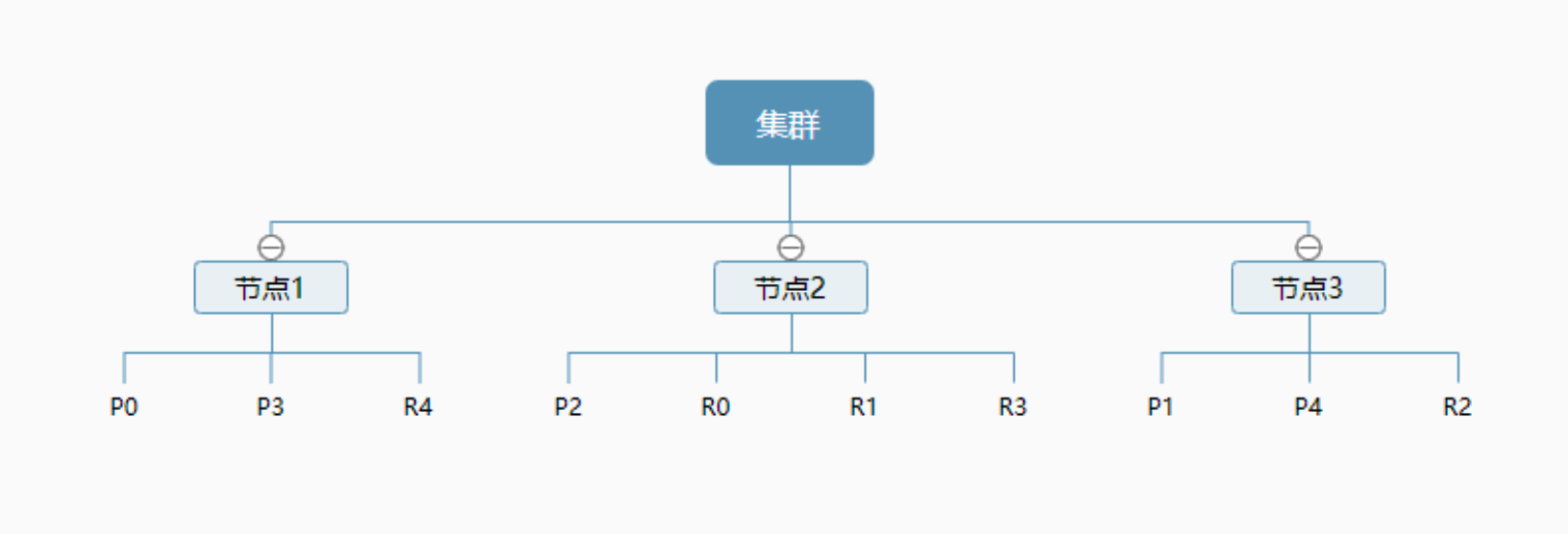

上图是一个有3个节点的集群,可以看到主分片和对应的复制分片都不会在同一个节点内,这样有利于某个节点挂掉 了,数据也不至于丢失。 实际上,一个分片是一个Lucene索引,一个包含倒排索引的文件目录,倒排索引的结构使得elasticsearch在不扫描全部文档的情况下,就能告诉你哪些文档包含特定的关键字。 其中,倒排索引又是什么呢?
倒排索引
elasticsearch使用的是一种称为倒排索引的结构,采用Lucene倒排索作为底层。这种结构适用于快速的全文搜索, 一个索引由文档中所有不重复的列表构成,对于每一个词,都有一个包含它的文档列表。 例如,现在有两个文档, 每个文档包含如下内容:
Study every day, good good up to forever # 文档1包含的内容
To forever, study every day, good good up # 文档2包含的内容
为了创建倒排索引,我们首先要将每个文档拆分成独立的词(或称为词条或者tokens),然后创建一个包含所有不重复的词条的排序列表,然后列出每个词条出现在哪个文档 :
| term | doc_1 | doc_2 |
|---|---|---|
| Study | √ | x |
| To | x | x |
| every | √ | √ |
| forever | √ | √ |
| day | √ | √ |
| study | x | √ |
| good | √ | √ |
| every | √ | √ |
| to | √ | x |
| up | √ | √ |
现在,我们试图搜索 to forever,只需要查看包含每个词条的文档
| term | doc_1 | doc_2 |
|---|---|---|
| to | √ | × |
| forever | √ | √ |
| total | 2 | 1 |
两个文档都匹配,但是第一个文档比第二个匹配程度更高。如果没有别的条件,现在,这两个包含关键字的文档都将返回。
再来看一个示例,比如我们通过博客标签来搜索博客文章。那么倒排索引列表就是这样的一个结构 :
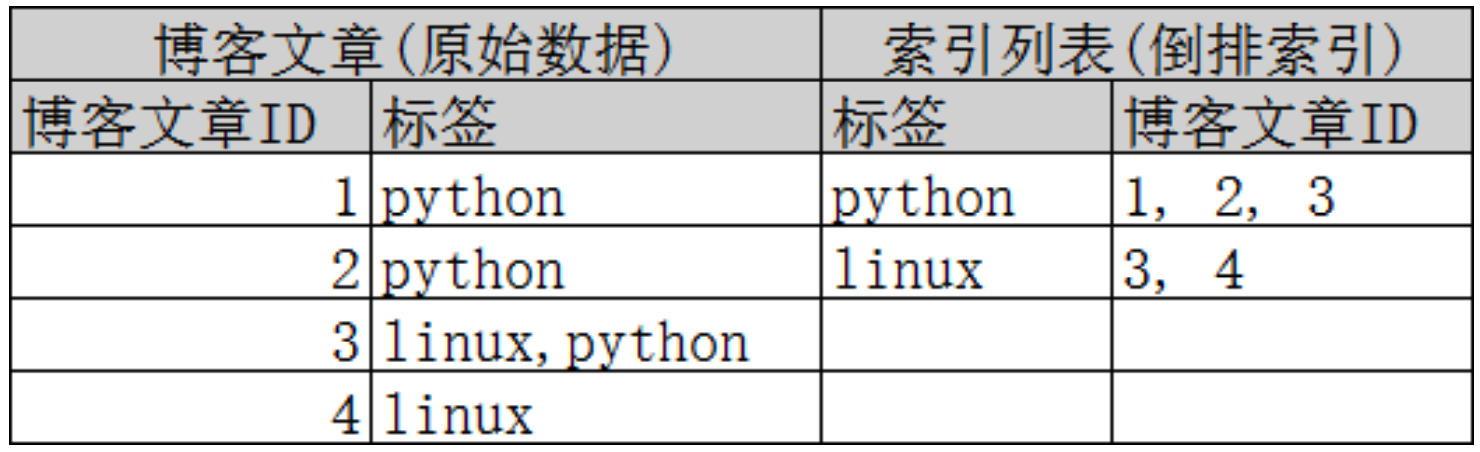
如果要搜索含有 python 标签的文章,那相对于查找所有原始数据而言,查找倒排索引后的数据将会快的多。只需要 查看标签这一栏,然后获取相关的文章ID即可。
ElasticSearch的索引和Lucene的索引对比
在elasticsearch中, 索引这个词被频繁使用,这就是术语的使用。 在elasticsearch中,索引被分为多个分片,每份分片是一个Lucene的索引。所以一个elasticsearch索引是由多个Lucene索引组成的。
类型
类型是文档的逻辑容器,就像关系型数据库一样,表格是行的容器。 类型中对于字段的定义称为映射,比如 name 映射为字符串类型。
我们说文档是无模式的,它们不需要拥有映射中所定义的所有字段,比如新增一个字段,那么elasticsearch是怎么做的呢?elasticsearch会自动的将新字段加入映射,但是这个字段的不确定它是什么类型,elasticsearch就开始猜,如果这个值是18,那么elasticsearch会认为它是整形。 但是elasticsearch也可能猜不对, 所以最安全的方式就是提前定义好所需要的映射,这点跟关系型数据库殊途同归了,先定义好字段,然后再使用。
文档
之前说elasticsearch是面向文档的,那么就意味着索引和搜索数据的最小单位是文档。
elasticsearch中,文档有几个重要属性 :
- 自我包含,一篇文档同时包含字段和对应的值,也就是同时包含 key:value!
- 可以是层次型的,一个文档中包含自文档,复杂的逻辑实体就是这么来的!
- 灵活的结构,文档不依赖预先定义的模式,我们知道关系型数据库中,要提前定义字段才能使用,在elasticsearch中,对于字段是非常灵活的,有时候,我们可以忽略该字段,或者动态的添加一个新的字段。
尽管我们可以随意的新增或者忽略某个字段,但是,每个字段的类型非常重要,比如一个年龄字段类型,可以是字符串也可以是整形。因为elasticsearch会保存字段和类型之间的映射及其他的设置。这种映射具体到每个映射的每种类型,这也是为什么在elasticsearch中,类型有时候也称为映射类型。
二、ES基础操作
IK分词器插件
什么是IK分词器?
分词:即把一段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作。
默认的中文分词是将每个字看成一个词,比如 “我爱学习” 会被分为”我”,”爱”,”学”,”习”,这显然是不符合要求的,所以我们需要安装中文分词器ik来解决这个问题。
IK分词器安装步骤
1、下载ik分词器的包,Github地址:https://github.com/medcl/elasticsearch-analysis-ik/ (版本要对应)
2、下载后解压,并将目录拷贝到ElasticSearch根目录下的 plugins 目录中。
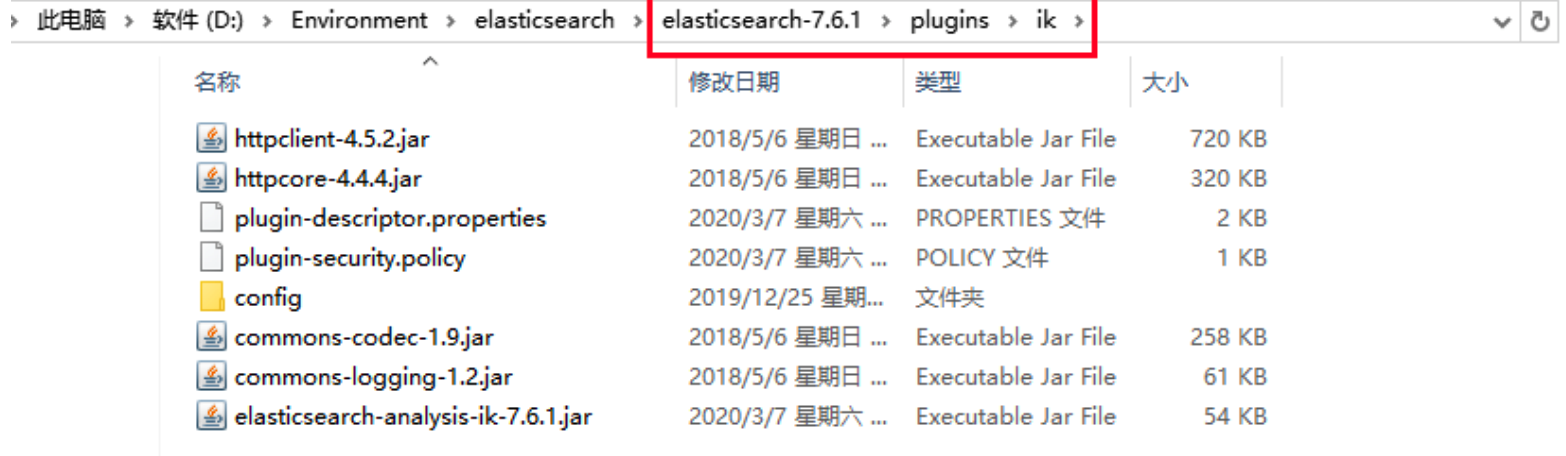
3、重新启动 ElasticSearch 服务,在启动过程中,你可以看到正在加载”analysis-ik”插件的提示信息,服务启动后,在命令行运行elasticsearch-plugin list 命令,确认 ik 插件安装成功。

IK提供了两个分词算法:ik_smart 和 ik_max_word,其中 ik_smart为最少切分,ik_max_word为最细粒度划分!
ik_max_word: 细粒度分词,会穷尽一个语句中所有分词可能。ik_smart: 粗粒度分词,优先匹配最长词,只有1个词!
如果某些词语,在默认的词库中不存在,比如我们想让“我爱学习”被识别是一个词,这时就需要我们编辑自定义词库。
步骤:
(1)进入elasticsearch/plugins/ik/config目录
(2)新建一个my.dic文件,编辑内容:
我爱学习
(3)修改IKAnalyzer.cfg.xml(在ik/config目录下)
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!-- 用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">my.dic</entry>
<!-- 用户可以在这里配置自己的扩展停止词字典 -->
<entry key="ext_stopwords"></entry>
</properties>
注意:修改完配置后,需要重新启动elasticsearch。
增删改查基本命令
Rest风格说明
一种软件架构风格,而不是标准,只是提供了一组设计原则和约束条件。它主要用于客户端和服务器交互类的软件。基于这个风格设计的软件可以更简洁,更有层次,更易于实现缓存等机制。
基本Rest命令说明(增、删、改、查命令):
| method | ur地址 | 描述 |
|---|---|---|
| PUT | localhost:9200/索引名称/类型名称/文档id | 创建文档(指定文档id) |
| POST | localhost:9200/索引名称/类型名称 | 创建文档(随机文档id) |
| POST | localhost:9200/索引名称/类型名称/文档id/_update | 修改文档 |
| DELETE | localhost:9200/索名称/类型名称/文档id | 删除文档 |
| GET | localhost:9200/索引名称/类型名称/文档id | 查询文档通过文档id |
| POST | localhost:9200/索引名称/类型名称/_search | 查询所有数据 |
三、SpringBoot集成ES
1、新建项目
新建一个springboot(2.2.5版)项目 elasticsearch-demo ,导入web依赖即可。
2、配置依赖
配置elasticsearch的依赖:
<properties>
<java.version>1.8</java.version>
<!-- 这里SpringBoot默认配置的版本不匹配,我们需要自己配置版本! -->
<elasticsearch.version>7.6.1</elasticsearch.version>
</properties>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
3、编写配置类
编写elasticsearch的配置类,提供RestHighLevelClient这个bean来进行操作。
package com.hzx.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class ElasticsearchClientConfig {
@Bean
public RestHighLevelClient restHighLevelClient() {
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("127.0.0.1", 9200, "http")));
return client;
}
}
4、配置工具类
封装ES常用方法工具类
package com.hzx.utils;
import com.alibaba.fastjson.JSON;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.action.support.master.AcknowledgedResponse;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.action.update.UpdateResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.CreateIndexResponse;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.rest.RestStatus;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.FetchSourceContext;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.stereotype.Component;
import java.io.IOException;
import java.util.List;
import java.util.concurrent.TimeUnit;
@Component
public class EsUtils<T> {
@Autowired
@Qualifier("restHighLevelClient")
private RestHighLevelClient client;
/**
* 判断索引是否存在
*
* @param index
* @return
* @throws IOException
*/
public boolean existsIndex(String index) throws IOException {
GetIndexRequest request = new GetIndexRequest(index);
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
return exists;
}
/**
* 创建索引
*
* @param index
* @throws IOException
*/
public boolean createIndex(String index) throws IOException {
CreateIndexRequest request = new CreateIndexRequest(index);
CreateIndexResponse createIndexResponse = client.indices()
.create(request, RequestOptions.DEFAULT);
return createIndexResponse.isAcknowledged();
}
/**
* 删除索引
*
* @param index
* @return
* @throws IOException
*/
public boolean deleteIndex(String index) throws IOException {
DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest(index);
AcknowledgedResponse response = client.indices()
.delete(deleteIndexRequest, RequestOptions.DEFAULT);
return response.isAcknowledged();
}
/**
* 判断某索引下文档id是否存在
*
* @param index
* @param id
* @return
* @throws IOException
*/
public boolean docExists(String index, String id) throws IOException {
GetRequest getRequest = new GetRequest(index, id);
//只判断索引是否存在不需要获取_source
getRequest.fetchSourceContext(new FetchSourceContext(false));
getRequest.storedFields("_none_");
boolean exists = client.exists(getRequest, RequestOptions.DEFAULT);
return exists;
}
/**
* 添加文档记录
*
* @param index
* @param id
* @param t 要添加的数据实体类
* @return
* @throws IOException
*/
public boolean addDoc(String index, String id, T t) throws IOException {
IndexRequest request = new IndexRequest(index);
request.id(id);
//timeout
request.timeout(TimeValue.timeValueSeconds(1));
request.timeout("1s");
request.source(JSON.toJSONString(t), XContentType.JSON);
IndexResponse indexResponse = client.index(request, RequestOptions.DEFAULT);
RestStatus Status = indexResponse.status();
return Status == RestStatus.OK || Status == RestStatus.CREATED;
}
/**
* 根据id来获取记录
*
* @param index
* @param id
* @return
* @throws IOException
*/
public GetResponse getDoc(String index, String id) throws IOException {
GetRequest request = new GetRequest(index, id);
GetResponse getResponse = client.get(request,RequestOptions.DEFAULT);
return getResponse;
}
/**
* 批量添加文档记录
* 没有设置id ES会自动生成一个,如果要设置 IndexRequest的对象.id()即可
*
* @param index
* @param list
* @return
* @throws IOException
*/
public boolean bulkAdd(String index, List<T> list) throws IOException {
BulkRequest bulkRequest = new BulkRequest();
//timeout
bulkRequest.timeout(TimeValue.timeValueMinutes(2));
bulkRequest.timeout("2m");
for (int i = 0; i < list.size(); i++) {
bulkRequest.add(new IndexRequest(index).source(JSON.toJSONString(list.get(i))));
}
BulkResponse bulkResponse = client.bulk(bulkRequest,RequestOptions.DEFAULT);
return !bulkResponse.hasFailures();
}
/**
* 更新文档记录
* @param index
* @param id
* @param t
* @return
* @throws IOException
*/
public boolean updateDoc(String index, String id, T t) throws IOException {
UpdateRequest request = new UpdateRequest(index, id);
request.doc(JSON.toJSONString(t));
request.timeout(TimeValue.timeValueSeconds(1));
request.timeout("1s");
UpdateResponse updateResponse = client.update(request, RequestOptions.DEFAULT);
return updateResponse.status() == RestStatus.OK;
}
/**
* 删除文档记录
*
* @param index
* @param id
* @return
* @throws IOException
*/
public boolean deleteDoc(String index, String id) throws IOException {
DeleteRequest request = new DeleteRequest(index, id);
//timeout
request.timeout(TimeValue.timeValueSeconds(1));
request.timeout("1s");
DeleteResponse deleteResponse = client.delete(request, RequestOptions.DEFAULT);
return deleteResponse.status() == RestStatus.OK;
}
/**
* 根据某字段来搜索
*
* @param index
* @param field
* @param key 要收搜的关键字
* @throws IOException
*/
public void search(String index, String field, String key, Integer
from, Integer size) throws IOException {
SearchRequest searchRequest = new SearchRequest(index);
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(QueryBuilders.termQuery(field, key));
//控制搜素
sourceBuilder.from(from);
sourceBuilder.size(size);
//最大搜索时间。
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
searchRequest.source(sourceBuilder);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(JSON.toJSONString(searchResponse.getHits()));
}
}
5、工具类API测试
测试创建索引:
@Test
void testCreateIndex() throws IOException {
CreateIndexRequest request = new CreateIndexRequest("test_index");
CreateIndexResponse createIndexResponse=restHighLevelClient.indices()
.create(request,RequestOptions.DEFAULT);
System.out.println(createIndexResponse);
}
测试获取索引:
@Test
void testExistsIndex() throws IOException {
GetIndexRequest request = new GetIndexRequest("test_index");
boolean exists = restHighLevelClient.indices()
.exists(request,RequestOptions.DEFAULT);
System.out.println(exists);
}
测试删除索引:
@Test
void testDeleteIndexRequest() throws IOException {
DeleteIndexRequest deleteIndexRequest = new
DeleteIndexRequest("test_index");
AcknowledgedResponse response = restHighLevelClient.indices()
.delete(deleteIndexRequest,
RequestOptions.DEFAULT);
System.out.println(response.isAcknowledged());
}
测试添加文档记录:
创建一个实体类User
@Data
@AllArgsConstructor
@NoArgsConstructor
@Component
public class User {
private String name;
private int age;
}
测试添加文档记录
@Test
void testAddDocument() throws IOException {
// 创建对象
User user = new User("zhangsan", 3);
// 创建请求
IndexRequest request = new IndexRequest("test_index");
// 规则
request.id("1");
request.timeout(TimeValue.timeValueSeconds(1));
request.timeout("1s");
request.source(JSON.toJSONString(user), XContentType.JSON);
// 发送请求
IndexResponse indexResponse = restHighLevelClient.index(request,
RequestOptions.DEFAULT);
System.out.println(indexResponse.toString());
RestStatus Status = indexResponse.status();
System.out.println(Status == RestStatus.OK || Status ==
RestStatus.CREATED);
}
测试:判断某索引下文档id是否存在
@Test
void testIsExists() throws IOException {
GetRequest getRequest = new GetRequest("test_index","1");
// 不获取_source上下文 storedFields
getRequest.fetchSourceContext(new FetchSourceContext(false));
getRequest.storedFields("_none_");
// 判断此id是否存在!
boolean exists = restHighLevelClient.exists(getRequest,
RequestOptions.DEFAULT);
System.out.println(exists);
}
测试:根据id获取文档记录
@Test
void testGetDocument() throws IOException {
GetRequest getRequest = new GetRequest("test_index","3");
GetResponse getResponse = restHighLevelClient.get(getRequest,RequestOptions.DEFAULT);
// 打印文档内容
System.out.println(getResponse.getSourceAsString());
System.out.println(getResponse);
}
测试:更新文档记录
@Test
void testUpdateDocument() throws IOException {
UpdateRequest request = new UpdateRequest("test_index","1");
request.timeout(TimeValue.timeValueSeconds(1));
request.timeout("1s");
User user = new User("zhangsan", 18);
request.doc(JSON.toJSONString(user), XContentType.JSON);
UpdateResponse updateResponse = restHighLevelClient.update(request, RequestOptions.DEFAULT);
System.out.println(updateResponse.status() == RestStatus.OK);
}
测试:删除文档记录
@Test
void testDelete() throws IOException {
DeleteRequest request = new DeleteRequest("test_index","3");
//timeout
request.timeout(TimeValue.timeValueSeconds(1));
request.timeout("1s");
DeleteResponse deleteResponse = restHighLevelClient.delete(
request, RequestOptions.DEFAULT);
System.out.println(deleteResponse.status() == RestStatus.OK);
}
测试:批量添加文档
@Test
void testBulkRequest() throws IOException {
BulkRequest bulkRequest = new BulkRequest();
//timeout
bulkRequest.timeout(TimeValue.timeValueMinutes(2));
bulkRequest.timeout("2m");
ArrayList<User> userList = new ArrayList<>();
userList.add(new User("zhangsan1",3));
userList.add(new User("zhangsan2",3));
userList.add(new User("zhangsan3",3));
userList.add(new User("lisi1",3));
userList.add(new User("lisi2",3));
userList.add(new User("lisi3",3));
for (int i =0;i<userList.size();i++){
bulkRequest.add(new IndexRequest("test_index").id(""+(i+1))
.source(JSON.toJSONString(userList.get(i)),XContentType.JSON));
}
// bulk
BulkResponse bulkResponse = restHighLevelClient.bulk(bulkRequest,RequestOptions.DEFAULT);
System.out.println(!bulkResponse.hasFailures());
}
查询测试:
/**
* 使用QueryBuilder
* termQuery("key", obj) 完全匹配
* termsQuery("key", obj1, obj2..) 一次匹配多个值
* matchQuery("key", Obj) 单个匹配, field不支持通配符, 前缀具高级特性
* multiMatchQuery("text", "field1", "field2"..); 匹配多个字段, field有通配符忒行
* matchAllQuery(); 匹配所有文件
*/
@Test
void testSearch() throws IOException {
SearchRequest searchRequest = new SearchRequest("test_index");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("name","zhangsan1");
MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
sourceBuilder.query(matchAllQueryBuilder);
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
searchRequest.source(sourceBuilder);
SearchResponse response = restHighLevelClient.search(searchRequest,RequestOptions.DEFAULT);
System.out.println(JSON.toJSONString(response.getHits()));
System.out.println("================查询高亮显示==================");
for (SearchHit documentFields : response.getHits().getHits()) {
System.out.println(documentFields.getSourceAsMap());
}
}
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/13303.html

