
前言
Mybatis小编已经陆续出了两篇博客了,之前我们讲解了Executor处理器,缓存体系,却没有讲解与jdbc交互的相关操作,这其实就是Mybatis的StatementHandler做的事情,一个SQL请求会经过会话,然后是执行器, 由StatementHandler执行jdbc最终到达数据库。今天小编带大家详细认识一下StatementHandler他是怎样的结构以及如何发挥作用的。
StatementHandler
定义
JDBC处理器,基于JDBC构建JDBC Statement,并设置参数,然后执行Sql。每调用会话当中一次sql,都会有与之相对应的且唯一的Statement实例(命中缓存除外)。
结构
StatementHandler 接口源码:
public interface StatementHandler {
//基于JDBC声明statement
Statement prepare(Connection connection, Integer transactionTimeout)
throws SQLException;
//为statement设置方法
void parameterize(Statement statement)
throws SQLException;
//添加批处理
void batch(Statement statement)
throws SQLException;
//执行update 方法
int update(Statement statement)
throws SQLException;
//执行query 方法
<E> List<E> query(Statement statement, ResultHandler resultHandler)
throws SQLException;
//查询游标
<E> Cursor<E> queryCursor(Statement statement)
throws SQLException;
//获取动态sql
BoundSql getBoundSql();
//获取参数处理器
ParameterHandler getParameterHandler();
}
StatementHandler 有三个子类
- SimpleStatementHandler:对应JDBC中的Statement
- PreparedStatementHandler:对应JDBC中的PreparedStatement
- CallableStatementHandler:对应JDBC中的CallableStatement。
下面是结构图:
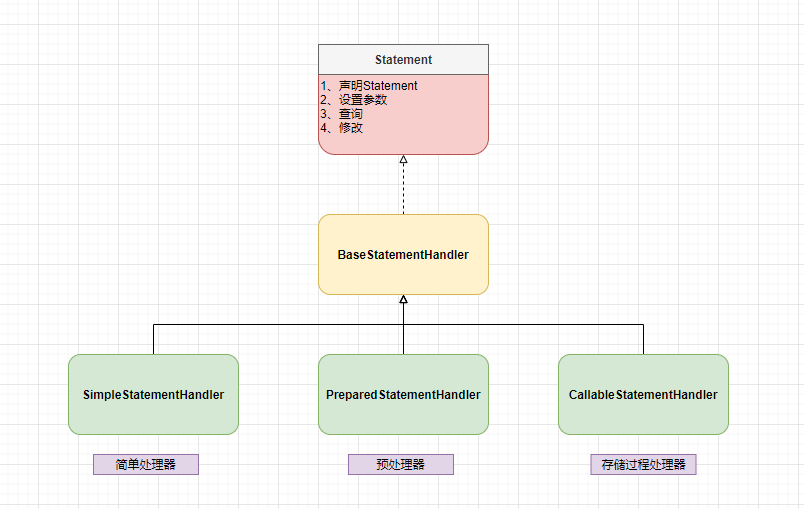
大部分情况下都是预处理器,所以接下小编就针对PreparedStatementHandler来讲解其流程。(其他的大家自行研究)
PreparedStatementHandler处理流程
首先看一下调用的时序图:

总共执行过程分为三个阶段:
- 预处理:这里预处理不仅仅是通过Connection创建Statement,还包括设置参数。
- 执行:包含执行SQL和处理结果映射两部分。
- 关闭:直接关闭Statement。
源码阅读
假设使用SimpleExecutor来调用的
@Override
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
//根据配置来创建StatementHandler最终调用的地方RoutingStatementHandler
//为什么使用configuration创建,这里第一可以理解为简单工厂,统一创建,第二是对插件做拦截
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
//创建statement然后是参数处理
stmt = prepareStatement(handler, ms.getStatementLog());
//执行查询操作
return handler.query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
}
使用RoutingStatementHandler来创建的根据StatementType来new一个相应的statementHandler(小编觉得这个好像没什么特别大的作用,可能当初作者还想再这个Handler里面做其他操作吧),里面statementType默认为PREPARED,可以通过@Options(statementType = StatementType.PREPARED)来配置。@Options放在对应接口的方法上。
public RoutingStatementHandler(Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
switch (ms.getStatementType()) {
case STATEMENT:
delegate = new SimpleStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case PREPARED:
delegate = new PreparedStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case CALLABLE:
delegate = new CallableStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
default:
throw new ExecutorException("Unknown statement type: " + ms.getStatementType());
}
}
创建statement并且参数处理
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
//获取连接
Connection connection = getConnection(statementLog);
//获取具体的StatementHandler这里就是PreparedStatementHandler的instantiateStatement方法,
//然后再base里面做了超时时间以及设置返回行数,设置的参数可以做mappedStatement配置
stmt = handler.prepare(connection, transaction.getTimeout());
//参数处理,具体参加后续参数部分怎么进行参数映射
handler.parameterize(stmt);
return stmt;
}
PreparedStatementHandler的instantiateStatement方法
protected Statement instantiateStatement(Connection connection) throws SQLException {
String sql = boundSql.getSql();
if (mappedStatement.getKeyGenerator() instanceof Jdbc3KeyGenerator) {
String[] keyColumnNames = mappedStatement.getKeyColumns();
if (keyColumnNames == null) {
return connection.prepareStatement(sql, PreparedStatement.RETURN_GENERATED_KEYS);
} else {
return connection.prepareStatement(sql, keyColumnNames);
}
} else if (mappedStatement.getResultSetType() == ResultSetType.DEFAULT) {
return connection.prepareStatement(sql);
} else {
return connection.prepareStatement(sql, mappedStatement.getResultSetType().getValue(), ResultSet.CONCUR_READ_ONLY);
}
}
具体执行方法:
@Override
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
ps.execute();
//处理结果集,后续详解
return resultSetHandler.handleResultSets(ps);
}
上图涉及到了参数处理以及结果集封装以及源码阅读中小编没有具体讲,这是由于涉及数据库字段和JavaBean之间的相互映射,相对复杂。所以分别使用ParameterHandler与ResultSetHandler两个专门的组件实现。接下来就一起了解一下参数处理与结果集封装的处理流程。
参数处理
参数处理包括了参数转换,参数映射以及参数的赋值,小编先来说一下参数的转换:
参数转换
所有参数转换我们运用的到了一个类:ParamNameResolver,分为两种情况
- 单个参数:假如说没有加@Param注解则不做转换直接交给执行器做对应的查询,如果有注解,就转换成一个map
- 多个参数:按照顺序转换,并且转换成一个map,key按照顺序就是param1,param2,如果假如了@Param,key就为对应参数的名称,jdk8之后基于反射可以用到对应参数的名称(需要打开参数编译),jdk8之前则为arg0,arg1。
ParamNameResolver参数转换类源码阅读
public Object getNamedParams(Object[] args) {
final int paramCount = names.size();
//没有参数,或参数数量为0返回null
if (args == null || paramCount == 0) {
return null;
//如果没有@param注解并且参数数量为1,则直接返回args[0]也就是参数本身
} else if (!hasParamAnnotation && paramCount == 1) {
return args[names.firstKey()];
} else {
//其他都封装成一个map,ParamMap为mybatis自定义的其实就是继承了hashMap,对get方法重写了一下
final Map<String, Object> param = new ParamMap<>();
int i = 0;
for (Map.Entry<Integer, String> entry : names.entrySet()) {
param.put(entry.getValue(), args[entry.getKey()]);
// add generic param names (param1, param2, ...)
final String genericParamName = GENERIC_NAME_PREFIX + String.valueOf(i + 1);
// ensure not to overwrite parameter named with @Param
if (!names.containsValue(genericParamName)) {
param.put(genericParamName, args[entry.getKey()]);
}
i++;
}
return param;
}
}
多个参数情况下运行的结果的
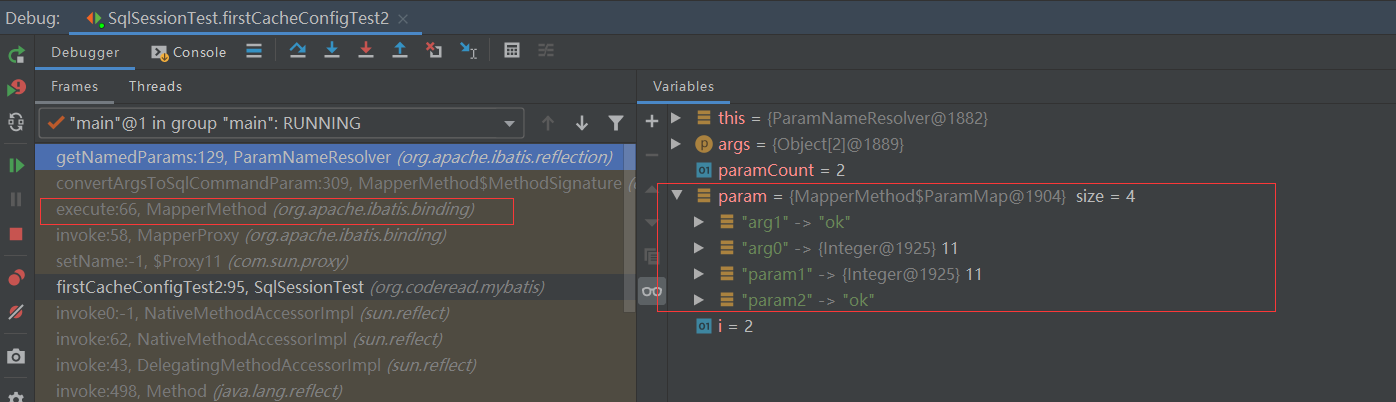
所以在我们接口类上可以这样写:
//这两种都可以,不过得注意顺序同时注意arg是从0开始的param是从1开始的(小编觉得还是加上@Param注解比较好)
@Update("update users set name=#{arg1} where id=#{arg0}")
@Update("update users set name=#{param2} where id=#{param1}")
int setName(Integer id, String name);
对了小编说了可以加入编译参数然后不写注解也可以解析到参数名称,那怎么加呢?请看下图:
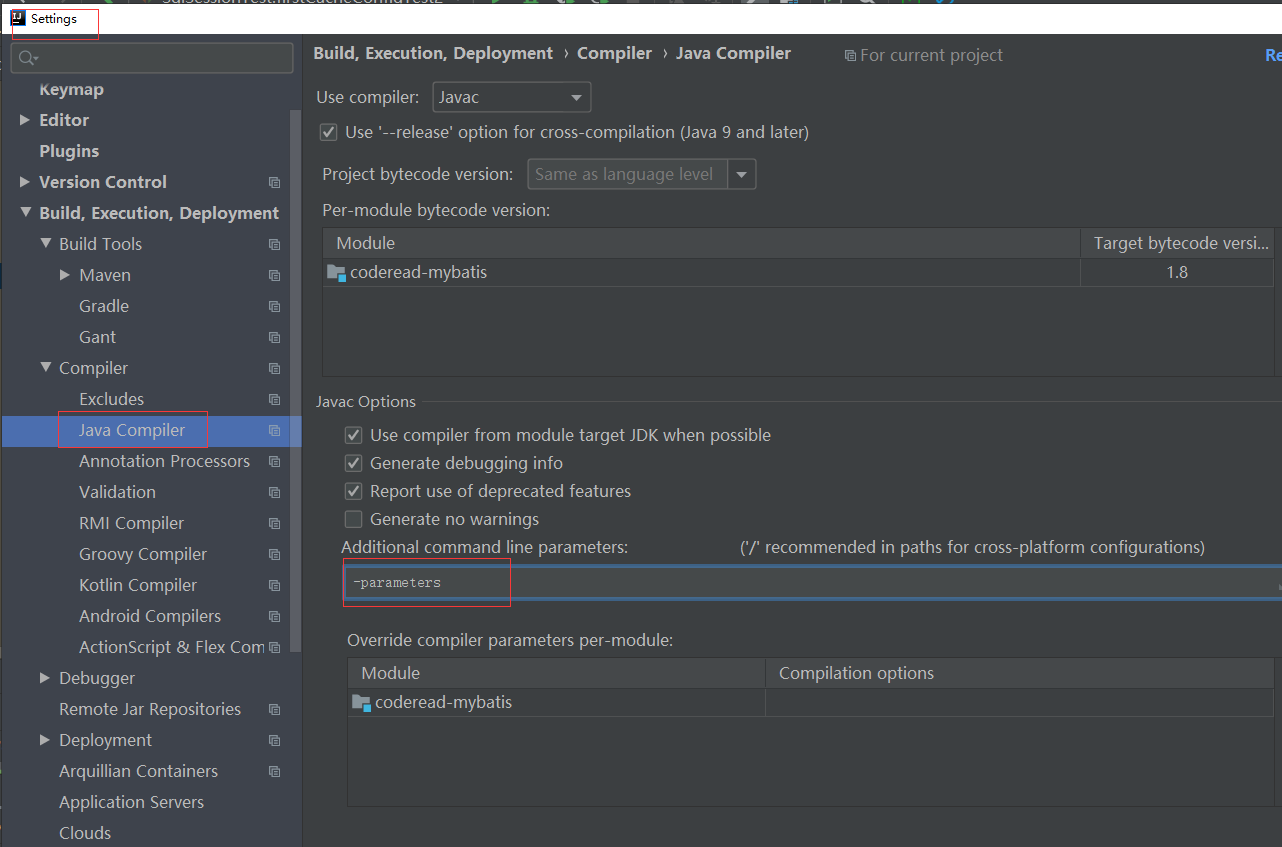
或者在pom的maven配置中 加入
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
<compilerArgs>
<arg>-parameters</arg>
</compilerArgs>
</configuration>
</plugin>
</plugins>
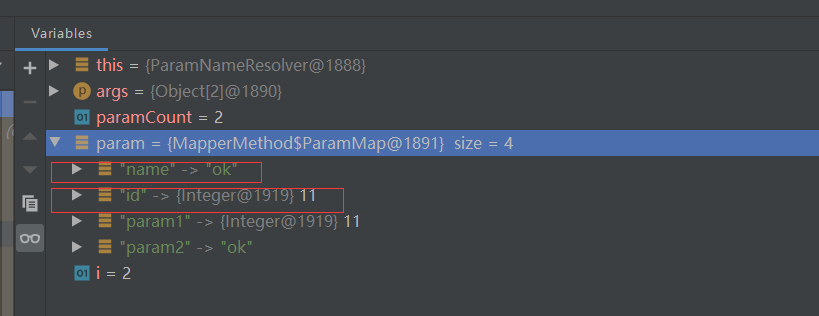
然后记得maven clean一下重新编译。当然不建议这么做。
结果如下图
参数映射与赋值
上面说的一个和多个参数由ParamNameResolver转换,但是无论是一个或多个参数的情况下都会出现参数是JavaBean对象或者是原始类型。这里交由ParameterHandler处理,如果只有一个原始类型的话那参数占用符基本可以随便写,多参的情况下根据map的key映射,如果是JavaBean对象会根据属性的名称进行映射比方说#{user.id}。
ParameterHandler源码阅读实现为DefaultParameterHandler
@Override
public void setParameters(PreparedStatement ps) {
ErrorContext.instance().activity("setting parameters").object(mappedStatement.getParameterMap().getId());
//boundSql中包含了sql,然后参数使用?作为占位符
//原先sql里面的#{param1}等封装为parameterMappings为参数映射,有几个参数就会映射几个
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
//不为空
if (parameterMappings != null) {
for (int i = 0; i < parameterMappings.size(); i++) {
ParameterMapping parameterMapping = parameterMappings.get(i);
//判断是否是存储过程的出参,不需要管
if (parameterMapping.getMode() != ParameterMode.OUT) {
Object value;
//获得属性名称也就是param1或arg0或者是name等
String propertyName = parameterMapping.getProperty();
if (boundSql.hasAdditionalParameter(propertyName)) { // issue #448 ask first for additional params
value = boundSql.getAdditionalParameter(propertyName);
} else if (parameterObject == null) {
value = null;
} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
value = parameterObject;
} else {
//将ParamNameResolver转换出来的参数封装为metaObject,然后就可以直接拿到值了
MetaObject metaObject = configuration.newMetaObject(parameterObject);
value = metaObject.getValue(propertyName);
}
TypeHandler typeHandler = parameterMapping.getTypeHandler();
//获取jdbcType
JdbcType jdbcType = parameterMapping.getJdbcType();
if (value == null && jdbcType == null) {
jdbcType = configuration.getJdbcTypeForNull();
}
try {
//如果没设置jdbc类型则基于值类型做参数设置否则根据jdbc类型转换
//这里需要TypeHandler来处理然后进行赋值
typeHandler.setParameter(ps, i + 1, value, jdbcType);
} catch (TypeException | SQLException e) {
throw new TypeException("Could not set parameters for mapping: " + parameterMapping + ". Cause: " + e, e);
}
}
}
}
}
对于上面小编的注释更直观的图如下:
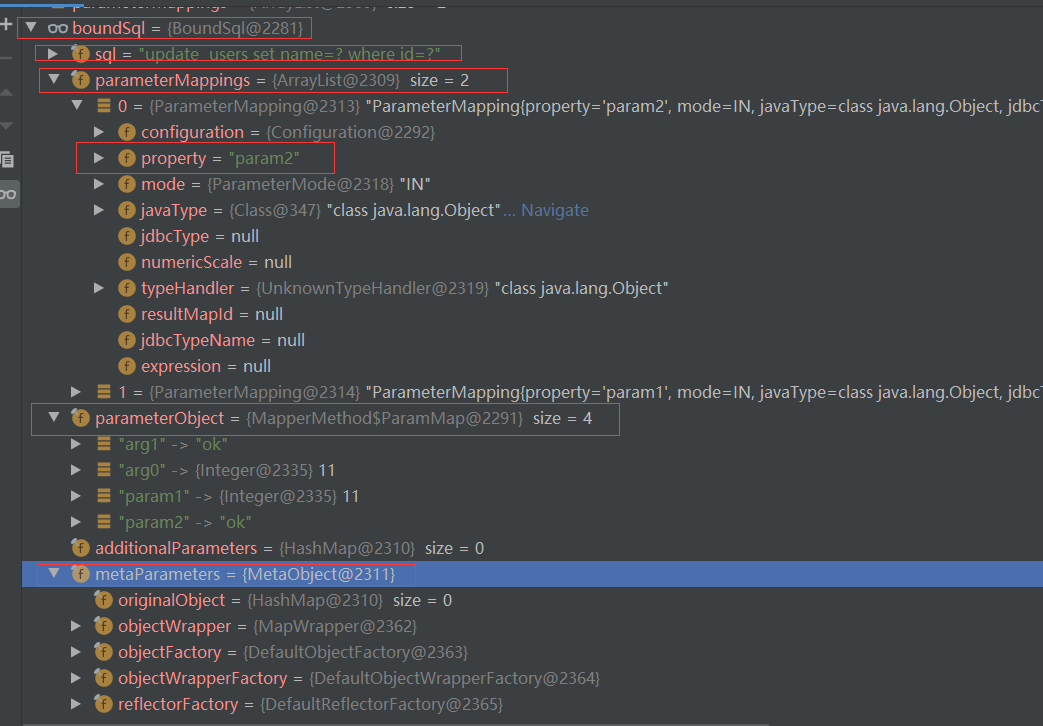
上面MetaObject 是很厉害的可以封装javaBean对象,原始类型还有数组List等等,这边小编后续讲解MetaObject ,因为这个很复杂。
参数的赋值通过TypeHandler 为PrepareStatement设置值,通常情况下一般的数据类型MyBatis都有与之相对应的TypeHandler。
结果集封装
指读取ResultSet数据,并将每一行转换成相对应的对象。用户可在转换的过程当中可以通过ResultContext来控制是否要继续转换。转换后的对象都会暂存在ResultHandler中最后统一封装成list返回给调用方。

结果集封装比较复杂下次讲解。
总结
今天主要讲了与jdbc打交道的statementHandler他有三个主要的子类,也分别封装了jdbc的statement,然后我们根据最常用的PrepareStatement说了一下其主要的流程,分为三个阶段:预处理,执行,关闭。其中有四个主要步骤:准备statement,设置参数,执行以及结果值处理,之后到设置参数的重要组件包括ParamNameResolver(参数转换器),ParameterHandler(参数的映射)以及TypeHandler(参数赋值所需的类型处理)。最后简单说了一下结果集封装,结果集封装是最复杂的下次小编接着为大家详细说明了一下,先到这儿,一起加油努力!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/13562.html

