
前言
大家周末好呢,不知道大家周末在干嘛呢,小编自从上次写了dubbo集群的负载均衡算法之后,紧接着为大家带来dubbo的调用机制以及他的容错机制。好了进入正题。
调用机制
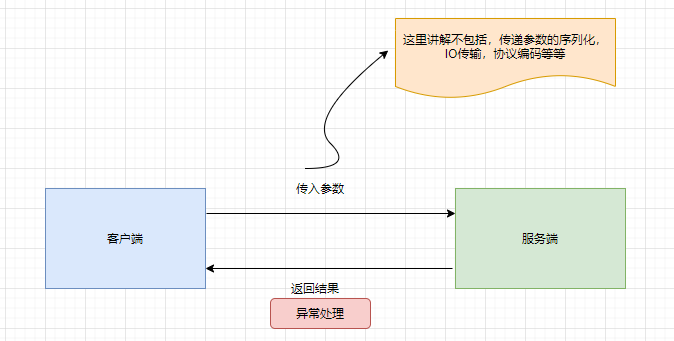
远程调⽤是Dubbo框架的核⼼,基本过程是,向服务端发送参数,并等待获取结果。如果调⽤过程出错则需要对异常进⾏处理。Dubbo调用类别有四种,分别是同步,异步,并行以及广播调用。默认情况下Dubbo是采⽤同步⽅式进⾏调⽤,即发起调⽤后线程将会阻塞,直到结果返回。同时为了提⾼性能,也可采用异⽅式调⽤。另外⼀些特殊的业务场景下,则可以使⽤⼴播⽅式调⽤、以及并⾏调⽤。
这边调用机制,小编只讲客户端层面的,同时不包括传参序列化,IO传输,协议编码等等(涉及netty内容,如果有机会小编单独写一章netty的内容)。如下图所示:

Dubbo调用类别:
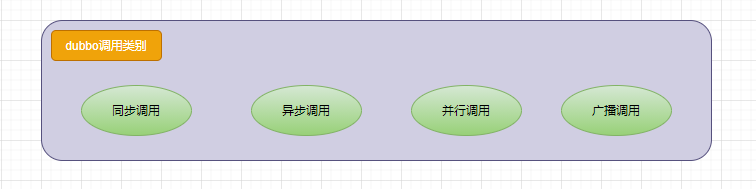
接下来对调用类别一一做出说明。
同步调用
一般情况下我们的企业级应用就是使用同步调用,咱们向远程服务器发送请求,这个请求就是阻塞的,直到服务器返回结果,这里插一句如果服务器处理慢那超出了时间就会报dubbo的超时异常。但其实调用没那么简单,我们用下图来表示:
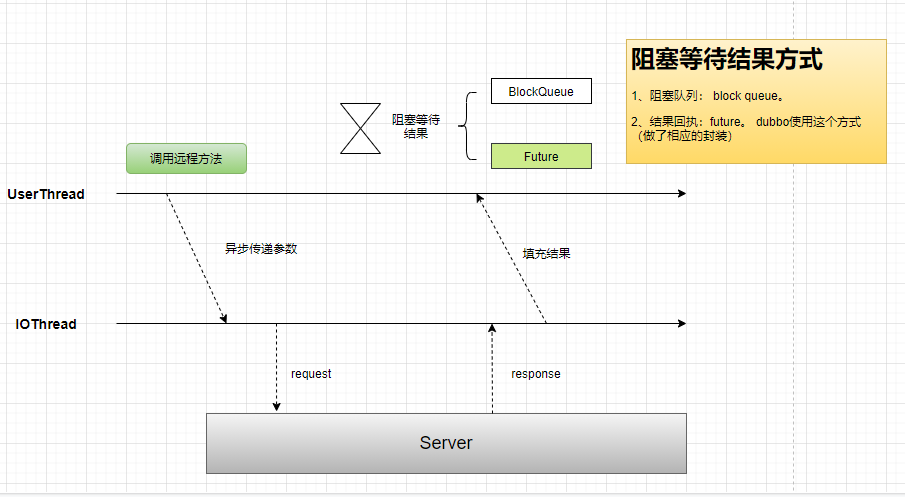
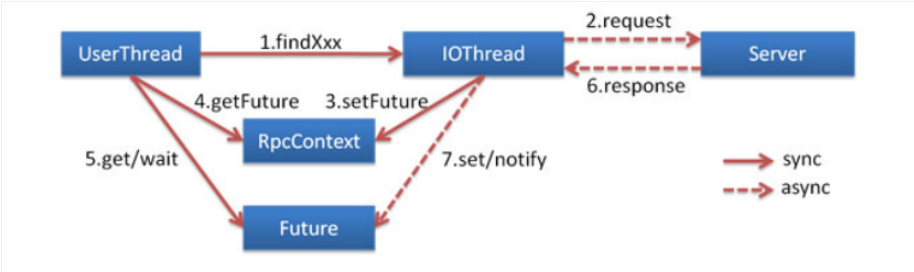
客户端线程发送给服务端时,其实有个专门的io线程完成的,他是异步发送的,如果是异步那返回结果前客户端不就拿不到结果了吗?这时其实dubbo会构建⼀个CompletableFuture,并通过它阻塞当前线程去等待结果返回,当服务端结果返回之后就会为CompletableFuture填充结果,并释放阻塞的调⽤线程。
演示CompletableFuture作用代码:
@Test
public void futureTest() throws ExecutionException, InterruptedException {
CompletableFuture<String> future = new CompletableFuture();
new Thread(()->{
try {
//模拟具体业务调用时间
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
future.complete("complete");
}).start();
String msg = future.get();
System.out.println(msg);
}
当然实际过程中还比较复杂比方说不可能一直阻塞肯定有阻塞时间限制等等,小伙伴有兴趣可以看相关源码。
相关源码:
org.apache.dubbo.remoting.exchange.support.DefaultFuture//结果回执org.apache.dubbo.rpc.protocol.AsyncToSyncInvoker//异步转同步
注意
AsyncToSyncInvoker.invoke方法中,future.get方法中,其实是个永久时间,比较大,所以其实他的超时控制是在DefaultFuture.newFuture的时候创建了一个定时线程去检查,然后再DefaultFuture的静态内部类中TimeoutCheckTask的run方法如果超时就会报错。小伙伴可以自行去看一下。后面有时间小编好好讲一下源代码。不过原理就是如上图所画。
异步调用
在⼀些场景特殊场景下,异步调⽤可有效提⾼性能。⽐如某场景中要远程调⽤接⼝A、B、C,分别⽤时1s,2s,3s。最后这个场景总⽤时就是它们相加后的6s。如果采⽤异步调⽤,同时去执⾏这三个接口,理想情况下总⽤时就是3秒。
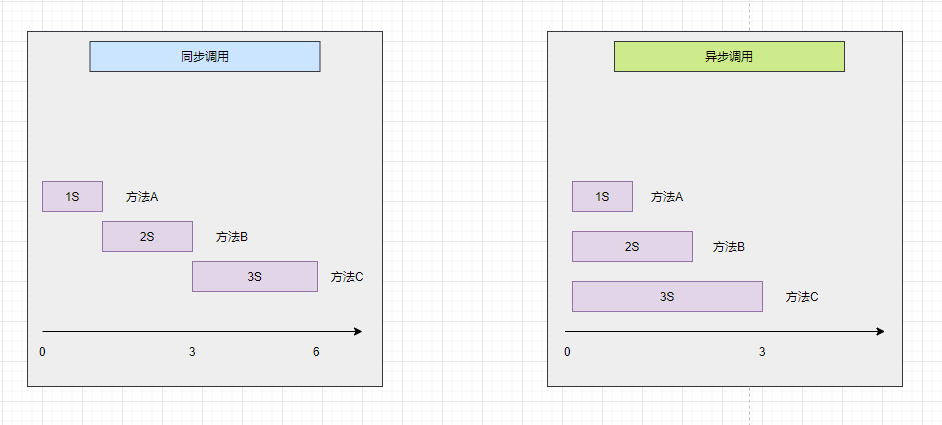
这种调用一般是在三个方法没有参数依赖且没有顺序依赖的时候使用。
配置方法
异步配置仅可配置在接⼝引⽤的⽅法层。示例如下:
//xml形式
<dubbo:referenceid="asyncDemoService"interface="com.tuling.teach.service.async.AsyncDemoService">
<!--异步调async:true异步调用false同步调用-->
<dubbo:methodname="sayHello1"async="true"/>
<dubbo:methodname="sayHello2"async="false"/>
<dubbo:methodname="notReturn"return="false"/>
</dubbo:reference>
//注解形式
@DubboReference(methods = {@Method(name = "sayHello1", async = true)})
示例代码
//客户端controller直接调用调用
@RestController
@RequestMapping(value = "/user")
public class UserController {
@DubboReference(methods = {@Method(name = "getUser", async = true)})
private IUserService userService;
@RequestMapping("/getUser")
public UserDto getUserById(@RequestParam("userId") Long id) {
userService.getUser(id);
//为了拿到值,并且上每次调用后得自己跟上getFuture,这里是基于requestId找到future,并设置值
Future<UserDto> future1 = RpcContext.getContext().getFuture();
userService.getUser(id);
Future<UserDto> future2 = RpcContext.getContext().getFuture();
userService.getUser(id);
Future<UserDto> future3 = RpcContext.getContext().getFuture();
UserDto userDto = null;
try {
userDto = future1.get();
userDto = future2.get();
userDto = future3.get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
return userDto;
}
}
//服务端代码
@DubboService
public class UserService implements IUserService {
@Value("${dubbo.server.name}")
private String serverName;
@Override
public UserDto getUser(Long id) {
try {
Thread.sleep(1000);
System.out.println("调用到了");
} catch (InterruptedException e) {
e.printStackTrace();
}
UserDto userDto = new UserDto();
userDto.setAge(18);
userDto.setId(id);
userDto.setName("Bob");
userDto.setDesc("当前服务:" + serverName);
return userDto;
}
}
调用结果 花费1秒

服务端日志调用三次
实现原理
事实上Dubbo的调⽤本身就是异步的,其常规的调⽤是通过AsyncToSyncInvoker组件,由异步转成了同步。所以异步的实现就是让该组件不去执⾏阻塞逻辑即可。此外为了顺利拿到结果回执(Future),在调⽤发起之后其回执会被填充到RpcContext当中。
相关源码
org.apache.dubbo.rpc.protocol.AbstractInvoker#invoke
这边同步和异步其实有相同性,大家可以看下啊。
并行调用
为了尽可能获得更⾼的性能,以及最⾼级别的保证服务的可⽤性。⾯对多个服务,并不知道哪个处理更快。这时客户端可并⾏发起多个调⽤,只要其中⼀个成功即返回,某个服务异常直接勿略,只有所有服务多出现异常情况下才会判定调⽤出错。
配置使⽤:
集群配置cluster=”forking”指定并⾏调⽤,forks=”2″设置最⼤并⾏数。示例
//这里只写了客户端和服务端xml,其实还有其他地方可以配置
<dubbo:serviceinterface="..."cluster="forking"forks="2"/>
<dubbo:referenceinterface="..."cluster="forking"/>
注意:由于并⾏调⽤特殊性,⽣产环境不建议使⽤,如果⼀定要⽤,请配置在method级别。
这边测试小编启动三个服务并且测试
结果

三台服务里面打印结果,因为并行最大2



原理:
并⾏调⽤原理是通过线程池异步发送远程请求。其流程如下:
- 根据forks数量挑选出服务节点
- 基于线程池(ExecutorService)并⾏发起远程调⽤
- .基于阻塞队列(BlockingQueue)等待结果返回
- 第⼀个结果返回,填充阻塞列,并释放线程
注:并⾏调⽤时,不能同时设置为异步调⽤,即async=true
相关源码:
org.apache.dubbo.rpc.cluster.support.ForkingClusterInvoker#ForkingClusterInvoker
这边小编特别讲一下这里的代码,因为并行场景dubbo代码有bug,这里为什么没解决有可能是实际应用场景中没有用到,第二是我们配置体系太复杂了,一不小心配置错才可能出现。
public Result doInvoke(final Invocation invocation, List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException {
try {
checkInvokers(invokers, invocation);
final List<Invoker<T>> selected;
final int forks = getUrl().getParameter(FORKS_KEY, DEFAULT_FORKS);
//看过小编之前配置的时候大家应该知道客户端方法级别超时时间是权限最大的,但这边并行的代码不是
final int timeout = getUrl().getParameter(TIMEOUT_KEY, DEFAULT_TIMEOUT);
//fork 是否是0 或者设置了大于了当前调用的机子总数,则直接赋值当前机子总数
if (forks <= 0 || forks >= invokers.size()) {
selected = invokers;
} else {
//如果设置了小于当前机子,则需要挑选其中的几台
selected = new ArrayList<>(forks);
while (selected.size() < forks) {
Invoker<T> invoker = select(loadbalance, invocation, invokers, selected);
if (!selected.contains(invoker)) {
//Avoid add the same invoker several times.
selected.add(invoker);
}
}
}
RpcContext.getContext().setInvokers((List) selected);
final AtomicInteger count = new AtomicInteger();
final BlockingQueue<Object> ref = new LinkedBlockingQueue<>();
//这里就是选择挑选好几台服务进行调用,使用线程
for (final Invoker<T> invoker : selected) {
executor.execute(() -> {
try {
//同步调用才能返回结果
Result result = invoker.invoke(invocation);
ref.offer(result);
} catch (Throwable e) {
//这里都失败的情况下才会放入错误信息
int value = count.incrementAndGet();
if (value >= selected.size()) {
ref.offer(e);
}
}
});
}
try {
//检测超时,然而这里返回了一个null,第一是timeout取的不正确,超时后也返回了一个null,然后返回null之后
//后面的调用就会出现nullpointException
Object ret = ref.poll(timeout, TimeUnit.MILLISECONDS);
if (ret instanceof Throwable) {
Throwable e = (Throwable) ret;
throw new RpcException(e instanceof RpcException ? ((RpcException) e).getCode() : 0, "Failed to forking invoke provider " + selected + ", but no luck to perform the invocation. Last error is: " + e.getMessage(), e.getCause() != null ? e.getCause() : e);
}
return (Result) ret;
} catch (InterruptedException e) {
throw new RpcException("Failed to forking invoke provider " + selected + ", but no luck to perform the invocation. Last error is: " + e.getMessage(), e);
}
} finally {
// clear attachments which is binding to current thread.
RpcContext.getContext().clearAttachments();
}
}
广播调用
在分布式环境,⼀个服务通常有多个提供⽅。原则上调⽤任意⼀个服务,结果都应该是⼀样的。但⼀些特殊场景除外,⽐如:“通知缓存更新”,需要通知到每个服务器都要更新各⾃节点缓存。要确保每个服务都被调⽤到。⼴播调⽤⼀次调⽤,会遍历所有提供者并发起调⽤,确保所有节点都被调⽤到。任意⼀台报错就算失败。小编写了测试代码
@RestController
@RequestMapping(value = "/user")
public class UserController {
//这边广播最好是相关方法,小编测试后其实异步也可以
//假如是同步的则有返回结果,但是呢如果有四台机子,A,B,C,D。A,B 成功了,C失败D又成功了就认为失败了。
//这个结果其实并不那么准确,无法精确到具体哪台失败了
@DubboReference(cluster = "broadcast",methods = {@Method(name = "getUser", async = true)})
private IUserService userService;
@RequestMapping("/getUser")
public UserDto getUserById(@RequestParam("userId") Long id) {
return userService.getUser(id);
}
}
测试结果

三台服务分别被调用到了
调用到了tom
调用到了jerry
调用到了sam
配置使⽤
cluster=“broadcast”
原理
⼴播调⽤原理相对简单,⽤⼀个循环遍历所有提供者,然后顺序同步发起调⽤。
相关源码
org.apache.dubbo.rpc.cluster.support.BroadcastClusterInvoker//⼴播调⽤
public Result doInvoke(final Invocation invocation, List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException {
checkInvokers(invokers, invocation);
RpcContext.getContext().setInvokers((List) invokers);
RpcException exception = null;
Result result = null;
for (Invoker<T> invoker : invokers) {
try {
result = invoker.invoke(invocation);
} catch (RpcException e) {
exception = e;
logger.warn(e.getMessage(), e);
} catch (Throwable e) {
exception = new RpcException(e.getMessage(), e);
logger.warn(e.getMessage(), e);
}
}
if (exception != null) {
throw exception;
}
return result;
}
从代码角度来看,这个其实还是可以优化的。
容错机制
容错概念
在发起RPC调⽤过程中如果出现错误之后,框架会对其进⾏补救措施称为容错。这⾥的错误指除业务异常之外的所有异常。异常类型定义在RpcException中。
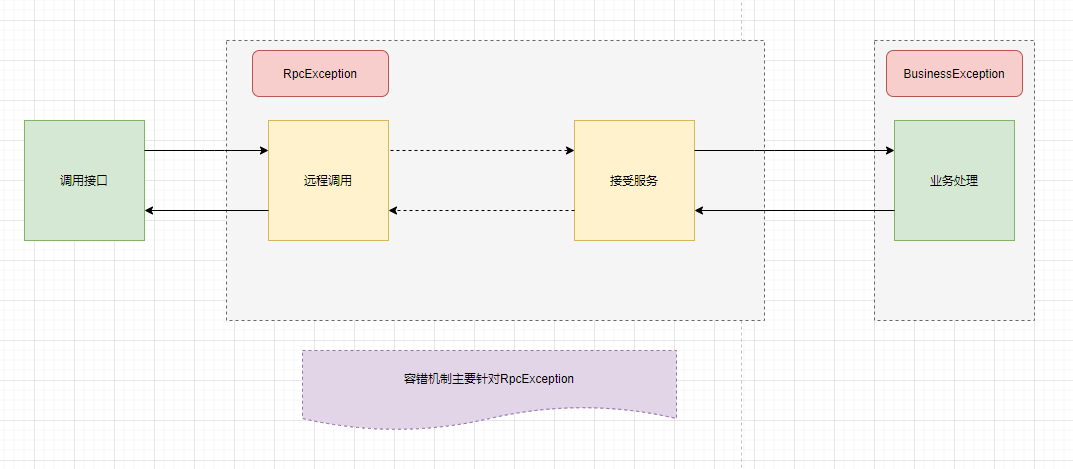
由远程调⽤框架产⽣的异常 org.apache.dubbo.rpc.RpcException
- UNKNOWN_EXCEPTION=0;//未知异常
- NETWORK_EXCEPTION=1;//网络异常
- TIMEOUT_EXCEPTION=2;//超时异常
- FORBIDDEN_EXCEPTION=4;//服务被禁
- SERIALIZATION_EXCEPTION=5;//序列化异常
- NO_INVOKER_AVAILABLE_AFTER_FILTER=6//没有可用的服务
- LIMIT_EXCEEDED_EXCEPTION=7;//超过并发限制
由业务⽅法产⽣的异常
- BIZ_EXCEPTION=3;//业务异常
容错策略
容错指由于调⽤环境原因导⾄调⽤失败,产⽣了⾮业务之时,系统如何补救,以整体提⾼可⽤性。
Dubbo官⽅⽬前⽀持以下容错策略:
- 失败⾃动切换:调⽤失败后基于retries属性重试其它服务器,这是默认的机制,重试默认2次。
- 快速失败:快速失败,只发起⼀次调⽤,失败⽴即报错。
- 勿略失败:失败后勿略,不抛出异常给客户端,并且返回⼀个空。
- 失败重试:失败⾃动恢复,后台记录失败请求,定时重发。通常⽤于消息通知操作
配置
retries=2
<!--Failover失败自动切换retries="2"切换次数
Failfast快速失败
Failsafe勿略失败,返回一个nul
Failback失败重试,5秒后仅重试一次-->
#设置方式支持如下两种方式设置,优先级由低至高
<dubbo:serviceinterface="..."cluster="failback"/>
<dubbo:referenceinterface="..."cluster="failback"/>
相关源码
org.apache.dubbo.rpc.cluster.support.FailoverClusterInvoker//失败自动切换org.apache.dubbo.rpc.cluster.support.FailfastClusterInvoker//快速失败org.apache.dubbo.rpc.cluster.support.FailsafeClusterInvoker//勿略失败
org.apache.dubbo.rpc.cluster.support.FailbackClusterInvoker//失败重试
上面代码非常简单一看就知道了。
总结
今天小编带了的调用机制是重点,其中发现的并行调用的bug以及广播调用的结果可以优化吧。最后小编提出一个问题,当同步调用的时候需要启动一个定时任务的线程,这是为了超时的时候需要关闭客户端的同步调用线程,那是否会很消耗性能?期待大家在讨论区评论。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/13575.html

