
Dubbo服务集群
前言
前几天小编写了Dubbo企业级应用及对应(redis和zookeeper)注册中心的注册机制。今天小编带大家了解Dubbo服务集群负载均衡机制。
负载均衡
概念
负载均衡是分布式架构的标配, 其⽬的是⽤于合理的分发请求,让后端服务处理的更均衡, 更提⾼服务整体承载性。
常见的负载均衡算法
- 轮询权重
- 随机权重
- 最少活跃数
- 最少⽤时
- URL哈希
- IP哈希
- 一致性Hash
Dubbo负载均衡配置
dubbo 官⽅所⽀持负载算共有以下5种:
| 算法名称 | 配置值 |
|---|---|
| 随机 + 权重 | random |
| 轮询 + 权重 | roundrobin |
| 最短响应 | shortestresponse |
| 最少连接 | leastactive |
| 一致性哈希 | consistenthash |
配置地方:
在Service或Reference中的loadbalance属性均可以⽤来设置负载均衡策略,但该配置是使⽤在客户端的,却可以在服务端配置,具体逻辑以及覆盖规则请参见小编写的文章 Dubbo快速上手与spring-boot整合以及配置体系中的配置体系。
<!-- 服务端级别-->
<dubbo:service interface="..." loadbalance="roundrobin" />
<!-- 客户端方法级别-->
<dubbo:reference interface="...">
<dubbo:method name="..." loadbalance="leastactive"/>
</dubbo:reference>
注意:loadbalance 总共有6处可以设置,但最终只会采用⼀个值。具体还是见小白上面的链接
虽然既可以配置在客户端也可以配置在服务端,但一般咱们配置在服务端,因为服务端才能知道自己的性能(虽然不一定知道)。而且一般配置在服务的全局,不太会单独配置在哪种接口或哪些方法中(特殊情况除外)。下面小编通过代码以及源码解读给大家说一下以上几种负载均衡。
1、随机加权重
配置文件
dubbo.application.name=boot-server
dubbo.protocol.name=dubbo
dubbo.protocol.port=-1
dubbo.registry.address=zookeeper://127.0.0.1:2181
dubbo.server.name = server
//随机
dubbo.provider.loadbalance= random
//权重
dubbo.provider.weight= 100
咱们启动两台机子
需要在启动的时候加入对应的参数,测试的dubbo中加入dubbo.server.name的参数配置,这样我们就能看清楚了
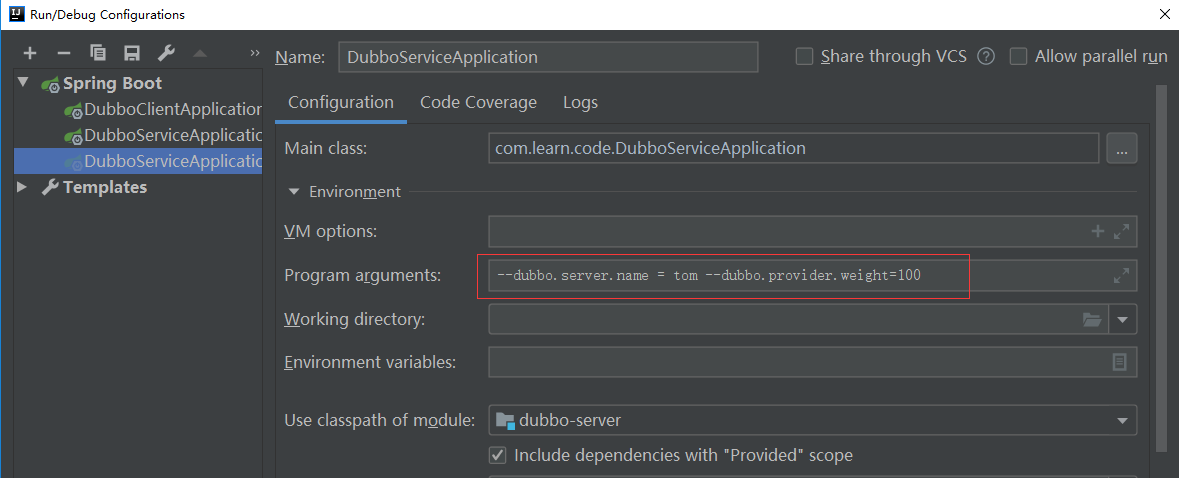
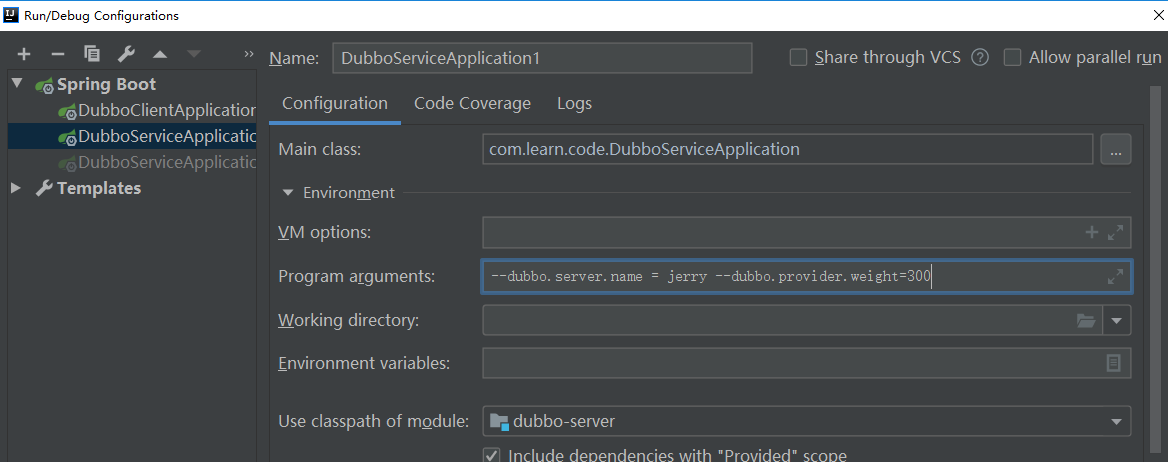
然后我们启动测试,测试结果
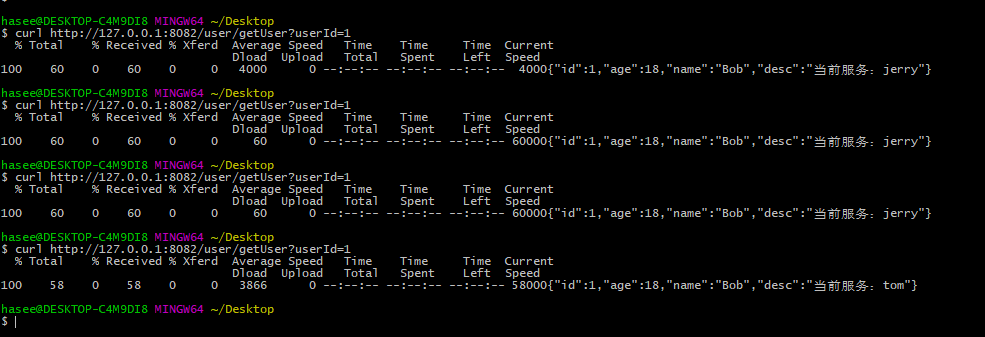
这个其实一目了然,你权重越高当然访问次数过多啊,当然默认就是随机,然后没有设置权重则就是100。
随机加权重源码阅读
负载均衡算法类:org.apache.dubbo.rpc.cluster.loadbalance.RandomLoadBalance#doSelect
@Override
protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {
// Number of invokers
int length = invokers.size();
// Every invoker has the same weight?
boolean sameWeight = true;
// the weight of every invokers
int[] weights = new int[length];
// the first invoker's weight
//核心代码int ww = (int) ( uptime / ((float) warmup / weight)); 已经启动的时间/(预热时间/当前设置的权重)
int firstWeight = getWeight(invokers.get(0), invocation);
weights[0] = firstWeight;
// The sum of weights
int totalWeight = firstWeight;
for (int i = 1; i < length; i++) {
int weight = getWeight(invokers.get(i), invocation);
// save for later use
weights[i] = weight;
// Sum 计算总权重
totalWeight += weight;
if (sameWeight && weight != firstWeight) {
sameWeight = false;
}
}
if (totalWeight > 0 && !sameWeight) {
// If (not every invoker has the same weight & at least one invoker's weight>0), select randomly based on totalWeight.
int offset = ThreadLocalRandom.current().nextInt(totalWeight);
// Return a invoker based on the random value.
for (int i = 0; i < length; i++) {
offset -= weights[i];
if (offset < 0) {
return invokers.get(i);
}
}
}
// If all invokers have the same weight value or totalWeight=0, return evenly.
return invokers.get(ThreadLocalRandom.current().nextInt(length));
}
上面的getWeight(invokers.get(0), invocation)这个方法默认预热时间为10分钟。其里面的方法代码为
int getWeight(Invoker<?> invoker, Invocation invocation) {
int weight;
URL url = invoker.getUrl();
// Multiple registry scenario, load balance among multiple registries.
if (REGISTRY_SERVICE_REFERENCE_PATH.equals(url.getServiceInterface())) {
weight = url.getParameter(REGISTRY_KEY + "." + WEIGHT_KEY, DEFAULT_WEIGHT);
} else {
weight = url.getMethodParameter(invocation.getMethodName(), WEIGHT_KEY, DEFAULT_WEIGHT);
if (weight > 0) {
long timestamp = invoker.getUrl().getParameter(TIMESTAMP_KEY, 0L);
if (timestamp > 0L) {
long uptime = System.currentTimeMillis() - timestamp;
if (uptime < 0) {
return 1;
}
int warmup = invoker.getUrl().getParameter(WARMUP_KEY, DEFAULT_WARMUP);
if (uptime > 0 && uptime < warmup) {
//这个方法就是上面注释的核心方法
weight = calculateWarmupWeight((int)uptime, warmup, weight);
}
}
}
}
return Math.max(weight, 0);
}
static int calculateWarmupWeight(int uptime, int warmup, int weight) {
//为什么不用 (int)(uptime / (float)warmup * weight) 这点令小编很奇怪
int ww = (int) ( uptime / ((float) warmup / weight));
return ww < 1 ? 1 : (Math.min(ww, weight));
}
核心方法很奇怪,因为外面做了判断为什么不是:(已经启动的时间/预热时间*当前设置的权重)来的简便。可能是阿里大神写的吧。不是很懂,怕别人调用??
上面代码的意思很简单
算法步骤:
- 计算总权重
- 在0和总权重之间得到⼀个随机数
- 排列权重,并遍历累加,当累加值⼤于或等于该随机数时表示命中。
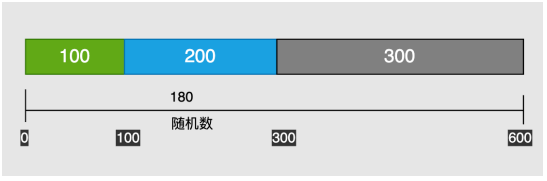
假如三个服务 权重100 200 300,然后总权重为600,0-600取个随机数,每次遍历权重累计,第一个为100 ,第二个为300 第三个为600,如果随机数是180那就是大于100小于300,则调用的权重为200的,原理是这样,但是阿里的代码时往下减去的,可能怕服务器数量过多,无上限所以就用减法。当然如果权重都一样的话,代码中是直接随机。
随机加权重算法优缺点及应用场景
优点:
该算法的优点是其简洁性,和实⽤性。它⽆需记录当前所有连接的状态,所以它是⼀种⽆状态调度。
缺点:
不适⽤于请求服务时间变化⽐较⼤,或者每个请求所消耗的时间不⼀致的情况,此时随机权重算法容易导致服务器间的负载不平衡。
应用场景:
每个请求所占⽤的后端时间基本相同,负载情况最好。快进出的服务。
2、轮询加权重
基于固定权重⽐例分发请求,在总体的处理请求数量跟其权重是等⽐例的。但在访问顺序上是交叉的,这样好处避免请求,在某个时间内完全偏上⼀边。此外Dubbo还引⼊了预热的概念, 其权重值会缓慢上升。直到预热结束,才会变成所设定的权重值。
咱们这次启动三个服务,名称分别为tom,jerry 和sam,权重分别为120,200,300,负载均衡算法配置成roundrobin。并且将预热时间改成0,这个主要是上面所述算法不影响我们设置的权限及测试结果。然后这边tom为什么不设置100小编这边卖个关子,我们直接看结果吧。
配置文件
dubbo.application.name=boot-server
dubbo.protocol.name=dubbo
dubbo.protocol.port=-1
dubbo.registry.address=zookeeper://127.0.0.1:2181
dubbo.server.name = server
dubbo.provider.loadbalance= roundrobin
dubbo.provider.weight= 100
dubbo.provider.warmup=0
测试结果
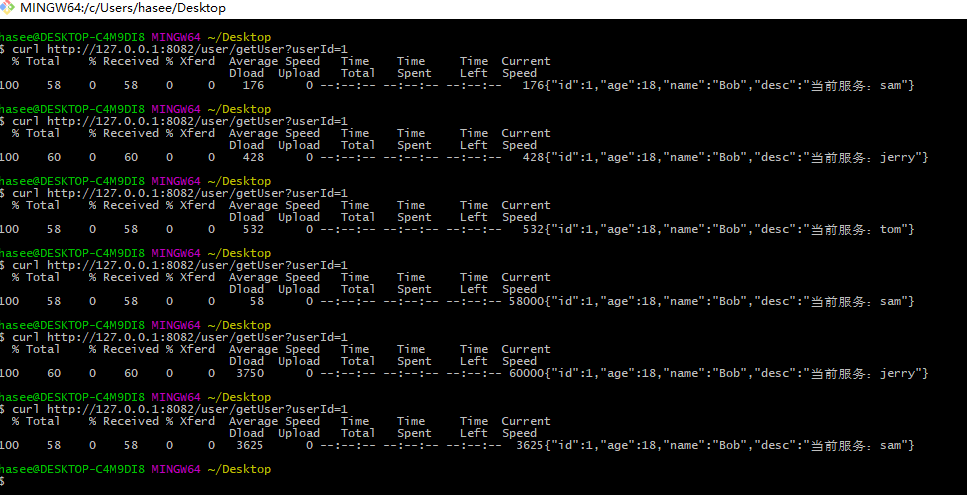
这个结果是怎么来的呢其实是可以算出来的见下面表格
下表中的有三个服务tom\jerry\sam,预设权重分别是120、200、300,随着每次请求结束,当前权重也在发⽣着变化。
| tom(120) | jerry(200) | sam(300) | |
|---|---|---|---|
| 第一次请求 | 120 | 200 | 300-620 |
| 第二次请求 | 240 | 400-620 | -20 |
| 第三次请求 | 360-620 | -20 | 270 |
| 第四次请求 | -140 | 180 | 270-620 |
| 第五次请求 | -20 | 380-620 | -50 |
| 第六次请求 | 100 | -40 | 250-620 |
上面表格大家是否看得懂,就是每次减总权重的服务就是调用到的服务,如上面的打印结果。
那如果小编设置100 200 300 则在第三次调用的时候权限一样,小编就不知道顺序了。
轮询加权重源码阅读
负载均衡算法类:org.apache.dubbo.rpc.cluster.loadbalance.RoundRobinLoadBalance#doSelect
protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {
String key = invokers.get(0).getUrl().getServiceKey() + "." + invocation.getMethodName();
ConcurrentMap<String, WeightedRoundRobin> map = methodWeightMap.computeIfAbsent(key, k -> new ConcurrentHashMap<>());
int totalWeight = 0;
long maxCurrent = Long.MIN_VALUE;
long now = System.currentTimeMillis();
Invoker<T> selectedInvoker = null;
WeightedRoundRobin selectedWRR = null;
for (Invoker<T> invoker : invokers) {
String identifyString = invoker.getUrl().toIdentityString();
int weight = getWeight(invoker, invocation);
WeightedRoundRobin weightedRoundRobin = map.computeIfAbsent(identifyString, k -> {
WeightedRoundRobin wrr = new WeightedRoundRobin();
wrr.setWeight(weight);
return wrr;
});
if (weight != weightedRoundRobin.getWeight()) {
//weight changed
weightedRoundRobin.setWeight(weight);
}
long cur = weightedRoundRobin.increaseCurrent();
weightedRoundRobin.setLastUpdate(now);
if (cur > maxCurrent) {
maxCurrent = cur;
selectedInvoker = invoker;
selectedWRR = weightedRoundRobin;
}
totalWeight += weight;
}
if (invokers.size() != map.size()) {
map.entrySet().removeIf(item -> now - item.getValue().getLastUpdate() > RECYCLE_PERIOD);
}
if (selectedInvoker != null) {
selectedWRR.sel(totalWeight);
return selectedInvoker;
}
// should not happen here
return invokers.get(0);
}
上面代码所述说的是加权⽅式 在Dubbo中每个服务⽅法,都会有⼀个权重状态对象,共记录两个值,⼀个是预设的固定权重值,始终保持不变,另外⼀个是当前的权重,会基于每次的请求发⽣变化。
逻辑如下:
- 每请求⼀次,当前权重都会加上预设置权重。
- 选出当前权重最⼤的服务,⽤于处理请求
- 选出服务的当前权重减去总权重。
- 在等权的情况下,选择最前⾯的那个 。
轮询加权重算法优缺点
优点:
实现简单,请求分布⽐例明确客观。
缺点:
需要记录访问状态,缺少灵活性,当服务负载出现压⼒时,依然会固定发送处理请求。
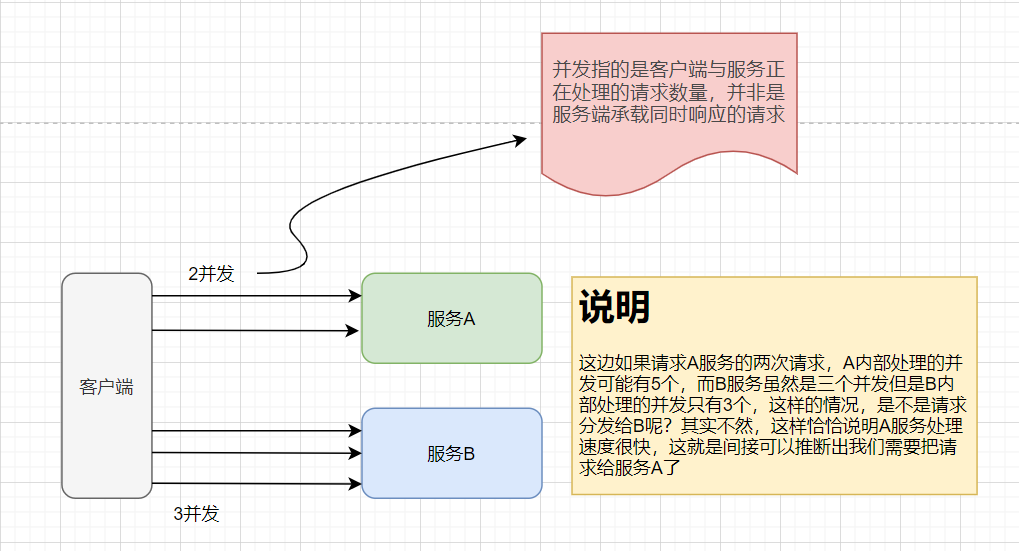
3、最少并发
这里的并发指的是客户端与服务正在处理的请求数量(具体到服务的方法),leastActive指的是当前未完成请求最少的那个服务,就会优先使用该服务。始终让客户端对服务端的请求保持均均匀状态。但有时可有存在多个最少并发的服务,这时就会采用权重随机的方式式处理。
具体规则如下:
- 只有一个最少并发的服务,就使用该服务
- 如果有多个最少并发,则基于权重随机(前提是总权重不等于零,且权重不相同)
- 否则直接在多个最少并发中随机找一个
这里就会涉及到并发统计方式,dubbo是这样统计的在RpcStatus中请求在执行前将请求数加1,请求结束后在减1。
下图是为了更好说明:
代码演示
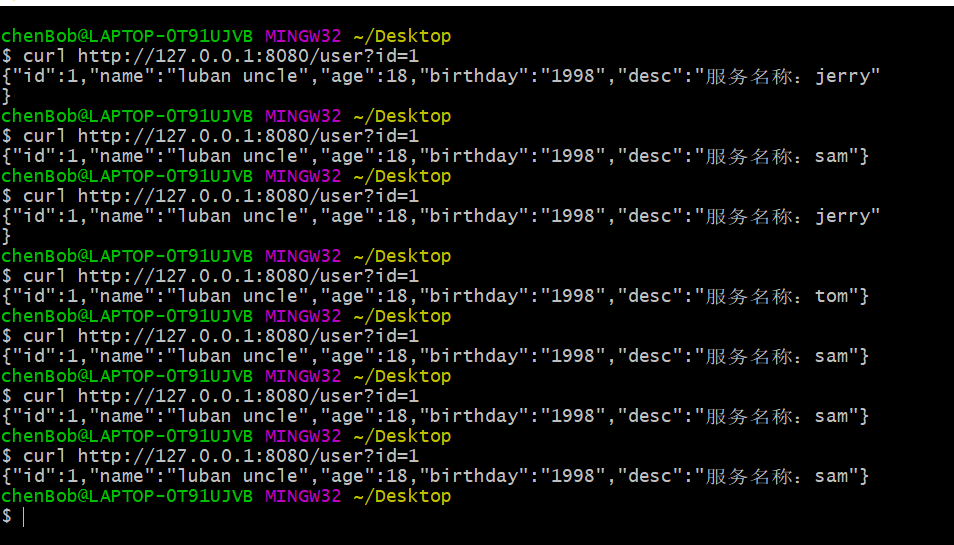
客户端配置项:说明为什么要加fliter是因为在记录RpcStatus请求数的时候要用到,否则默认为0就永远拿不到请求数量了。
dubbo.application.name=boot-client
dubbo.protocol.name=dubbo
dubbo.protocol.port=-1
dubbo.registry.address=zookeeper://127.0.0.1:2181
dubbo.registry.check=false
dubbo.consumer.filter=activelimit
服务端配置项:选择负载均衡算法
dubbo.application.name=boot-server
dubbo.protocol.name=dubbo
dubbo.protocol.port=-1
dubbo.registry.address=zookeeper://127.0.0.1:2181
dubbo.provider.loadbalance=leastactive
这边其实是不好演示的,小编只把结果奉上
最少并发源码阅读
负载均衡算法类:org.apache.dubbo.rpc.cluster.loadbalance.LeastActiveLoadBalance#doSelect
重要类:org.apache.dubbo.rpc.RpcStatus
过滤器:org.apache.dubbo.rpc.filter.ActiveLimitFilter
算法类代码如下:
protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {
// Number of invokers
int length = invokers.size();
// The least active value of all invokers
int leastActive = -1;
// The number of invokers having the same least active value (leastActive)
int leastCount = 0;
// The index of invokers having the same least active value (leastActive)
int[] leastIndexes = new int[length];
// the weight of every invokers
int[] weights = new int[length];
// The sum of the warmup weights of all the least active invokers
int totalWeight = 0;
// The weight of the first least active invoker
int firstWeight = 0;
// Every least active invoker has the same weight value?
boolean sameWeight = true;
// Filter out all the least active invokers
for (int i = 0; i < length; i++) {
Invoker<T> invoker = invokers.get(i);
// Get the active number of the invoker 请求是拿到服务端的请求该方法的活跃数
int active = RpcStatus.getStatus(invoker.getUrl(), invocation.getMethodName()).getActive();
// Get the weight of the invoker's configuration. The default value is 100.
int afterWarmup = getWeight(invoker, invocation);
// save for later use
weights[i] = afterWarmup;
// If it is the first invoker or the active number of the invoker is less than the current least active number
if (leastActive == -1 || active < leastActive) {
// Reset the active number of the current invoker to the least active number
leastActive = active;
// Reset the number of least active invokers
leastCount = 1;
// Put the first least active invoker first in leastIndexes
leastIndexes[0] = i;
// Reset totalWeight
totalWeight = afterWarmup;
// Record the weight the first least active invoker
firstWeight = afterWarmup;
// Each invoke has the same weight (only one invoker here)
sameWeight = true;
// If current invoker's active value equals with leaseActive, then accumulating.
} else if (active == leastActive) {
// Record the index of the least active invoker in leastIndexes order
leastIndexes[leastCount++] = i;
// Accumulate the total weight of the least active invoker
totalWeight += afterWarmup;
// If every invoker has the same weight?
if (sameWeight && afterWarmup != firstWeight) {
sameWeight = false;
}
}
}
// Choose an invoker from all the least active invokers
if (leastCount == 1) {
// If we got exactly one invoker having the least active value, return this invoker directly.
return invokers.get(leastIndexes[0]);
}
//否则就用权重随机负载均衡
if (!sameWeight && totalWeight > 0) {
// If (not every invoker has the same weight & at least one invoker's weight>0), select randomly based on
// totalWeight.
int offsetWeight = ThreadLocalRandom.current().nextInt(totalWeight);
// Return a invoker based on the random value.
for (int i = 0; i < leastCount; i++) {
int leastIndex = leastIndexes[i];
offsetWeight -= weights[leastIndex];
if (offsetWeight < 0) {
return invokers.get(leastIndex);
}
}
}
// If all invokers have the same weight value or totalWeight=0, return evenly.
// 同权重不就随机了
return invokers.get(leastIndexes[ThreadLocalRandom.current().nextInt(leastCount)]);
}
过滤器类:主要是对RpcStatus操作
public Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException {
URL url = invoker.getUrl();
String methodName = invocation.getMethodName();
int max = invoker.getUrl().getMethodParameter(methodName, ACTIVES_KEY, 0);
final RpcStatus rpcStatus = RpcStatus.getStatus(invoker.getUrl(), invocation.getMethodName());
if (!RpcStatus.beginCount(url, methodName, max)) {
long timeout = invoker.getUrl().getMethodParameter(invocation.getMethodName(), TIMEOUT_KEY, 0);
long start = System.currentTimeMillis();
long remain = timeout;
synchronized (rpcStatus) {
while (!RpcStatus.beginCount(url, methodName, max)) {
try {
rpcStatus.wait(remain);
} catch (InterruptedException e) {
// ignore
}
long elapsed = System.currentTimeMillis() - start;
remain = timeout - elapsed;
if (remain <= 0) {
throw new RpcException(RpcException.LIMIT_EXCEEDED_EXCEPTION,
"Waiting concurrent invoke timeout in client-side for service: " +
invoker.getInterface().getName() + ", method: " + invocation.getMethodName() +
", elapsed: " + elapsed + ", timeout: " + timeout + ". concurrent invokes: " +
rpcStatus.getActive() + ". max concurrent invoke limit: " + max);
}
}
}
}
invocation.put(ACTIVELIMIT_FILTER_START_TIME, System.currentTimeMillis());
return invoker.invoke(invocation);
}
@Override
public void onResponse(Result appResponse, Invoker<?> invoker, Invocation invocation) {
String methodName = invocation.getMethodName();
URL url = invoker.getUrl();
int max = invoker.getUrl().getMethodParameter(methodName, ACTIVES_KEY, 0);
RpcStatus.endCount(url, methodName, getElapsed(invocation), true);
notifyFinish(RpcStatus.getStatus(url, methodName), max);
}
上面代码比较易懂大家有空看下。阿里的注释还是蛮全面的,哈哈!这边filter里面其实有时间的算法,这就和下面最短响应算法有关了。
最少并发算法优缺点
优点:
时刻让服务端处理处于更均匀的状态,当服务端压力大时,处理时间将会变长,积累的未完成 请求越多,得到的分配就越少。从而到达背压反馈的效果。
缺点:
实现复杂,需要实时统计并发。
4、最短响应
最短响应是在最少并发的基础之上,加上⼀个平均执⾏时间做为⼀个度量。基于历史平均响应时间乘以当前并发数量,选出最小值。
当结果出现多个时,其选择算法如下:
- 如果只有一个调用程序,则直接使用该调用程序;
- 如果有多个调用者并且权重不相同,则根据总权重随机;
- 如果有多个调用者且权重相同,则将其随机调用。
这个同样不好测试
最短响应源码阅读
配置文件
#服务端配置最短响应负载均衡器
dubbo.consumer.loadbalance=shortestresponse
#在消费端设置统计调用统计过滤器 同样需要配置fliter
dubbo.consumer.filter=activelimit
负载均衡算法类:org.apache.dubbo.rpc.cluster.loadbalance.ShortestResponseLoadBalance#doSelect
protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {
// Number of invokers
int length = invokers.size();
// Estimated shortest response time of all invokers
long shortestResponse = Long.MAX_VALUE;
// The number of invokers having the same estimated shortest response time
int shortestCount = 0;
// The index of invokers having the same estimated shortest response time
int[] shortestIndexes = new int[length];
// the weight of every invokers
int[] weights = new int[length];
// The sum of the warmup weights of all the shortest response invokers
int totalWeight = 0;
// The weight of the first shortest response invokers
int firstWeight = 0;
// Every shortest response invoker has the same weight value?
boolean sameWeight = true;
// Filter out all the shortest response invokers
for (int i = 0; i < length; i++) {
Invoker<T> invoker = invokers.get(i);
RpcStatus rpcStatus = RpcStatus.getStatus(invoker.getUrl(), invocation.getMethodName());
// Calculate the estimated response time from the product of active connections and succeeded average elapsed time.
/总的成功时间/总的成功次数 = 总的成功平均时间
long succeededAverageElapsed = rpcStatus.getSucceededAverageElapsed();
int active = rpcStatus.getActive();
//算法 主要比较这个值
long estimateResponse = succeededAverageElapsed * active;
int afterWarmup = getWeight(invoker, invocation);
weights[i] = afterWarmup;
// Same as LeastActiveLoadBalance
if (estimateResponse < shortestResponse) {
shortestResponse = estimateResponse;
shortestCount = 1;
shortestIndexes[0] = i;
totalWeight = afterWarmup;
firstWeight = afterWarmup;
sameWeight = true;
} else if (estimateResponse == shortestResponse) {
shortestIndexes[shortestCount++] = i;
totalWeight += afterWarmup;
if (sameWeight && i > 0
&& afterWarmup != firstWeight) {
sameWeight = false;
}
}
}
if (shortestCount == 1) {
return invokers.get(shortestIndexes[0]);
}
if (!sameWeight && totalWeight > 0) {
int offsetWeight = ThreadLocalRandom.current().nextInt(totalWeight);
for (int i = 0; i < shortestCount; i++) {
int shortestIndex = shortestIndexes[i];
offsetWeight -= weights[shortestIndex];
if (offsetWeight < 0) {
return invokers.get(shortestIndex);
}
}
}
return invokers.get(shortestIndexes[ThreadLocalRandom.current().nextInt(shortestCount)]);
}
代码还是比较明白的,注释还是挺多的。同样好理解。
最短响应算法优缺点
优点:
在最短并发基础之上,获得了服务的历史表现,对服务处理性能判断更加精准。
缺点:
实现复杂,需要实时统计并发,并实时计算平均响应时间。
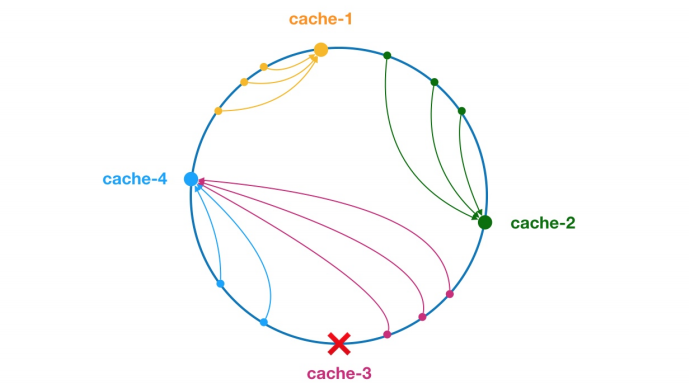
5、一致性哈希
⼀致性 hash 算法,⽤于⼤规模缓存系统的负载均衡。与取模啥希相⽐优势在于,当服务端节点变更时,其影响范围将会缩小。有兴趣大家可以看这篇文章什么是一致性Hash算法
算法机制如下:
- 使⽤ 0到2^32 – 1 数字,构成⼀个⾸尾相连的圆
- 计算多个服务地址的哈希值,并使⽤虚拟节点将期均匀的放分布在圆上
- 当执⾏请求前,先计算参数的啥希值,然后顺时针找到离它最近的节点访问。
下图演示

配置示例
注意:一致性哈希算法⽐较特殊,通常⽤于缓存场景,所以要单独设置。建议统⼀设置在服务 端的⽅法处。
#配置一致性哈希负载均衡器
#hash.arguments 要hash的参数,默认第一个,
#如果方法参数多个就配置多个即可,不建议太多。hash.nodes 虚拟节点数量
#loadbalance = "consistenthash"
@DubboService(parameters = {"hash.arguments", "0,1", "hash.nodes", "320"},
methods = {@Method(name = "xxx",loadbalance = "consistenthash") })
这边打到一个服务的时候就一直在这个服务,除非这台机子挂了。增加机子不会影响到。
测试结果
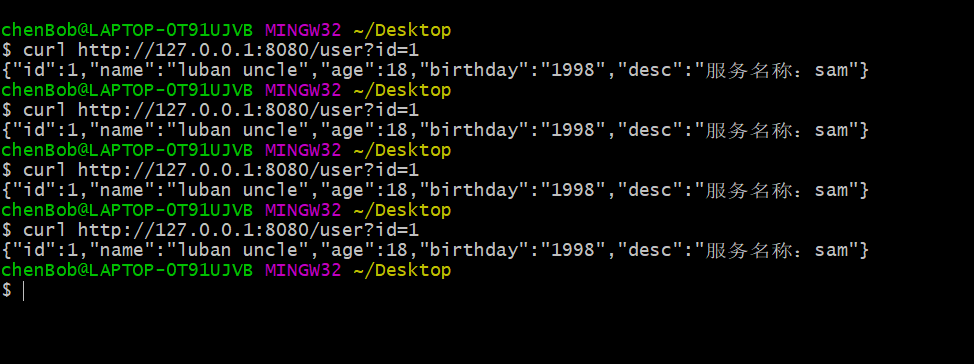
一致性哈希源码阅读
略,代码比较难懂!
一致性哈希算法优缺点
优点:
⽤于将相同的参数映射到固定的服务上,通常⽤于分布式缓存的场景。节点变更时缓存影响范围降⾄最低。
缺点:
实时对参数进⾏md5 以及hash取值,参数值不建议太⼤。
负载均衡算法选择
dubbo提供了五种负载均衡的算法,那应用到企业级服务大家需要怎么选择的。小编扫尾总结了一下,希望对各位有所帮助。
1.客户端并发⼤,服务端并发也⼤,照顾客户端性能 ========>随机+权重 或 轮循加权重
2.服务端数量小,客户端数量极⼤,照顾服务端的性能 ========> 最短连接或最短响应
2.缓存应⽤,保证缓存命中率 ========>⼀⾄性啥希
总结
前面小编的源码阅读,其实需要靠大家好好看一下,对于一致性hash代码比较复杂这边暂且不表了,其他算法细节大家可以自己去仔细看看,阿里大神的思路代码也供大家评论一番。不过注释挺详细的。
好了今天的负载均衡就说到这儿了,不知道小编讲清楚了没,希望再接再厉,加油!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/13576.html

