
背景
Ambari 是 Apache Software Foundation 的一个顶级开源项目,是一个集中部署、管理、监控 Hadoop 分布式集群的工具。
- 部署:自动化部署 Hadoop 软件,能够自动处理服务、组件之间的依赖(比如 HBase 依赖 HDFS,DataNode 启动的时候,需要 NameNode 先启动等)。
- 管理:Hadoop 服务组件的启动、停止、重启,配置文件的多版本管理。
- 监控:Hadoop 服务的当前状态(组件节点的存活情况、YARN 任务执行情况等),当前主机的状态(内存、硬盘、CPU、网络等),而且可以自定义报警事件。
CDH收购HDP后,HDP逐渐闭源,导致开源社区大数据运维越来越需要一款比较优秀平台支撑,首推ambari。但是很多刚接触,难免很难快速入手,因此结合自己多年经验及社区资料,整理如下供大家参考参考,有问题欢迎大家共同探讨。
个人建议开发方向:
1、参照HDP,基于Apache项目做二次开发。
2、支持自定义ambari stack,以便于支撑多种组件包安装(比如:大数据、算法、K8S等等)。
3、移除rpm/deb package安装,建议tar包安装,以便于快速支撑多平台。
4、组件支持mpack模式安装、卸载、更新。
5、增强监控模块。
6、汉化。
7、组建设区统一力量共同参与开发。
项目地址:
https://github.com/apache/ambari


-
Ambari是Hortonworks贡献给社区的、完全开源的、Hadoop生态的集群管理、监控、部署的工具;
-
Ambari Web通过调用Ambari REST API实现对Hadoop生态系统各个组件的操作,同时Ambari REST API也支持与现有的其它外部工具集成,已扩展服务的应用面。可以说,Ambari REST API是唯一暴露给“外部”系统(这里可以指代Ambari Web、Ambari Shell等内部系统和其它外部系统)的操作Ambari的方式。
说起 Ambari ,不得不提下 Hortonworks和它的竞争对手们 。
因为Apache社区版的Hadoop在面对企业级的应用时存在稳定性、可靠性、性能、易用性等方面的限制,许多公司都对其进行了“二次包装”,这些公司被称为Hadoop商业发行版提供商。
大浪淘沙,自从10年前(2006年)Hadoop诞生到今天(2016年)为止,这一市场已被几大公司瓜分,国外比较著名的提供商有Cloudera、MapR、Hortonworks、IBM、Amazon等,国内比较著名的提供商有华为、星环科技等。这里面,目前只有Cloudera和Hortonworks两家国外公司有提供不收费的Hadoop商业发行版,分别叫作Cloudera’s Distribution Including Apache Hadoop(简称“CDH”)和Hortonworks Data Platform(简称“HDP”)。这两家公司也都提供了相应的集群管理、部署、监控的工具,分别是Cloudera Manager和Ambari。apache
值得注意的是,Cloudera Manager要比Ambari在年纪上大三岁,但这并不妨碍Ambari的快速成长,目前来看,Ambari与Cloudera Manager的功能差距正在迅速缩小,且因为Ambari是彻底开源的,社区很是活跃,增长了愈来愈多的企业级的新特性,使得Ambari自己变的愈来愈强大。同时,很多公司也对Apache Ambari进行了“二次包装”,将Ambari从面向运维转变成了面向数据服务,将来说不定还会产生“Ambari商业发行版提供商”这样的称呼。
参考:https://blog.csdn.net/tianbaochao/article/details/72156247
Ambari是一个强大的大数据集群管理平台。在实际使用中,我们使用的大数据组件不会局限于官网提供的那些。如何在Ambari中集成进去其他组件呢?
一、Ambari基本架构

Ambari充分利用了一些已有的优秀开源软件,巧妙地把它们结合起来,使其在分布式环境中做到了集群式服务管理能力、监控能力、展示能力,这些优秀的开源软件有:
(1)、agent端,采用了puppet管理节点。
(2)、在web端,采用ember.js作为前端MVC框架和NodeJS相关工具,用handlebars.js作为页面渲染引擎,在CSS/HTML方面还用了Bootstrap框架。
(3)、在Server端,采用了Jetty、Spring、JAX-RS等。
(4)、同时利用了Ganglia、Nagios的分布式监控能力。
Ambari框架采用的是Server/Client的模式,主要由两部分组成:ambari-agent和ambari-server。ambari依赖其它已经成熟的工具,例如:其ambari-server就依赖python,而ambari-agent还同时依赖ruby,puppet,fecter等工具,还有它也依赖一些监控工具nagios和ganglia用于监控集群状况。其中:
puppet是分布式集群配置管理工具,也是典型的Server/Client模式,能够集中式管理分布式集群的安装配置部署,主要语言是ruby。
facter是用Python写的一个节点资源采集库,用于采集节点的系统信息,例如OS信息,由于ambari-agent 主要是用Python写的,因此用facter可以很好的采集到节点信息。
项目目录介绍
|
目录 |
描述 |
|
ambari-server |
Ambari的Server程序,主要管理部署在每个节点上的管理监控程序 |
|
Ambari-agent |
部署在监控节点上运行的管理监控程序 |
|
Contrib |
自定义第三方库 |
|
ambari-web |
Ambari页面UI的代码,作为用户与Ambari server交互的。 |
|
ambari-views |
用于扩展Ambari Web UI中的框架 |
|
Docs |
文档 |
|
ambari-common |
Ambari-server 和Ambari-agent 共用的代码 |
Ambari系统架构
在ambari-server开放的Rest API中分为主要的两大类 API,其中一类为ambari-web提供监控管理服务,另一类用于与ambari-agent交互,接受ambari-agent向ambari-server发送心跳请求。Master模块接受API和Agent Interface的请求,完成ambari-server的集中式管理监控逻辑,而每个agent节点只负责所在节点的状态采集及维护工作。
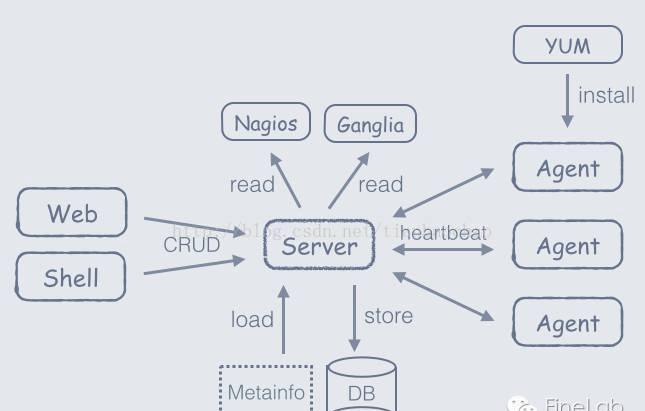
Ambari 整体架构图

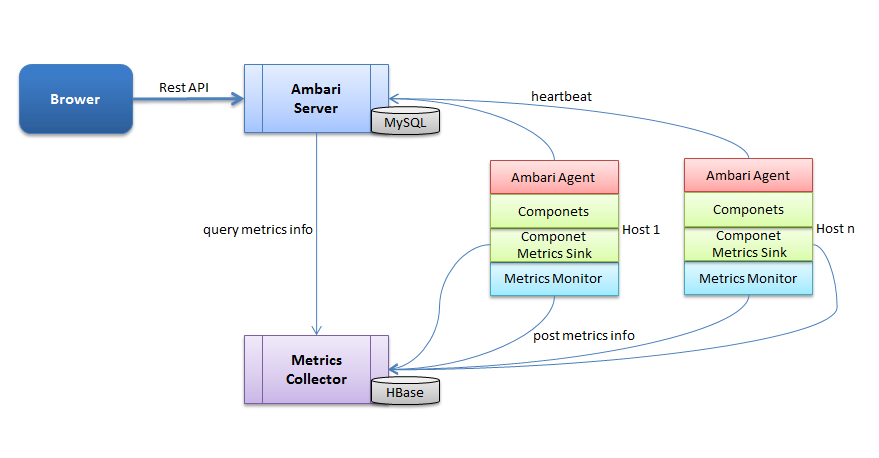
由图中可以看出,主要有4部分:
- Brower:指的是前端,前端通过 HTTP 发送 Rest 指令和 Ambari Server 进行交互。
- Ambari Server:是一个 web 服务器,开放两个端口,分别用来和前端、Agent 进行交互。从图中也可以看出,Ambari Server 的数据存储在 MySQL 中。
- Metrics Collector:是一个 web 服务器,提供两个功能,一方面将 Metrics Monitor 和 Metrics Sink 汇报上来的监控信息存储到 HBase 中,另一方面提供监控信息查询接口,供 Ambari Server 进行查询。
- Host:实际安装大数据服务的主机,可以有多台。从图中可以看出,每台主机都安装有一个 Ambari Agent 服务和 Metrics Monitor 服务,有些组件如果需要更详细和特有的监控信息,可以集成相对应的 Metrics Sink(比如HDFS的 Metrics Sink 可以监控空间的使用情况)。
两条业务线:
- 核心业务:集群的统一部署、管理以及基本的监控(比如组件的存活情况)都是由这条线来完成的,由前端、Ambari Server 和 Ambari Agent 组成。前端提供可视化界面,发送操作指令;Ambari Server 维护着整个集群的状态;Ambari Agent 执行具体的指令去操作服务和组件,而且会通过心跳汇报 Host 和服务的状态信息。
- Metrics 监控业务:提供详细的监控功能,由 Metrics Collector、Metrics Monitor、Metrics Sink 组成。
Metrics Collector 存储监控信息,并提供查询接口;Metrics Monitor 主要负责收集并汇报 Host 相关的指标,比如主机的 CPU、内存、网络等;Metrics Sink 负责收集并汇报组件的相关指标,比如该组件的 CPU 使用率,内存使用情况等。

由图中可以看出,主要有4部分:
Resource Service:资源服务,用来接收前端的 Rest 请求。关于 Resource 的几个基本概念:
- Resource:Ambari Server 定义了各种各样的 Resource,比如 Config、User、Cluster、
- Component、Alert 等都是一种 Resource。
- Resource Type:每种 Resource 都对应一个 ResourceType,标记所属的资源类型。
- Resource Service:每种 Resource 都对应一个 Resource Service,比如ConfigService、UserService等,Service 中定义了相对应 Resource 的 Rest API。
- Resource Provider:每种 Resource 都对应一个 ResourceProvider,比如ConfigResourceProvider、UserResourceProvider等,对 Resource 的具体操作,都封装在 Provider 中。
HeartBeatHandler:处理 Agent 的 Heartbeat 请求。
ActionQueue:每个 Host 都有一个 ActionQueue 记录着需要这台 Host 执行的命令。
FSM:维护组件状态的有限状态机。
简述一下 Ambari Server 的工作流程:
前端请求处理流程:前端提交一个 Rest 请求,相应 Resource 的 Service 处理请求,根据 ResourceType 找到对应的 ResourceProvider 执行具体的操作;如果存在需要 Agent 执行的操作,则把操作存储到相应 Host 的 ActionQueue 中;如果需要改变组件的状态,则需要操作 FSM。
Agent 请求处理流程:Agent Heartbeat 每10秒执行一次,Heartbeat Request 会携带命令的执行情况、组件状态以及 Host 状态等信息,HeartBeatHandler 会根据汇报上来的命令执行情况,去操作 FSM 来维护组件的状态;HeartBeatHandler 会从 ActionQueue 中取出需要 Host 执行的命令、修改的配置、Alert 定义等信息,通过 HeartBeat Response 返回给 Agent 执行。
总体来说由于 Ambari Server 和 Ambari Agent 之间是通过短连接进行通信,所以 Server 无法把需要执行的命令,直接推送给相应的 Agent,所以需要 ActionQueue 来存储命令,然后通过 Heartbeat 把命令下发给 Agent 执行。
Ambari Agent 架构图
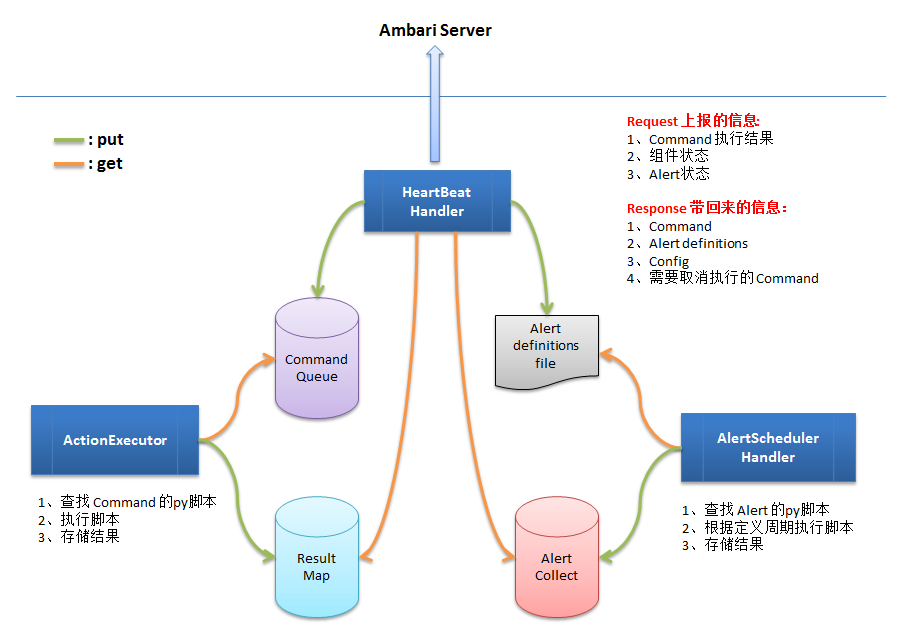
由图中看,主要有3部分:
- HeartBeatHandler:发送 HTTP 请求和 Ambari Server 进行交互。
- ActionExecutor:Command 执行器。
- AlertSchedulerHandler:Alert 处理器。
4个数据容器:
- CommandQueue:存储需要执行的 Command。
- ResultMap:存储 Command 的执行结果。
- Alert definitions file:是一个文件,保存所有的 Alert 定义。
- AlertCollect:存储 Alert 的检查结果。
简一下 Ambari Agent 的工作流程:
- HeartBeatHandler:收集组件当前状态(通过ResultMap)、Command 执行结果(通过ResultMap)、Alert 检查结果(通过 AlertCollect)等,封装到 HTTP Request 当中,发送给 Ambari Server;Ambari Server 响应请求,通过 HTTP Response 带回来需要执行的 Command、需要终止的 Command、发生修改的 Config、发生修改的 Alert 定义等,并把 Comand 和 修改的 Config 封装为 Agent Command 对象,存储到 CommandQueue 中;把修改的 Alert 定义,更新到 Alert definitions 文件中(如果 Alert definitions 文件发生了变化,需要通知 AlertSchedulerHandler 重新加载一遍
- ActionExecutor:定期从 CommandQueue 中加载需要执行的 Command,找到 Command 对应的 Python 脚本,执行脚本,并把结果存储到 ResultMap 中。
- AlertSchedulerHandler:从 Alert definitions 文件中加载所有 Alert 定义,根据 Alert 定义,找到对应的 Python 脚本,周期性执行,并把结果存储到 AlertCollect 中。
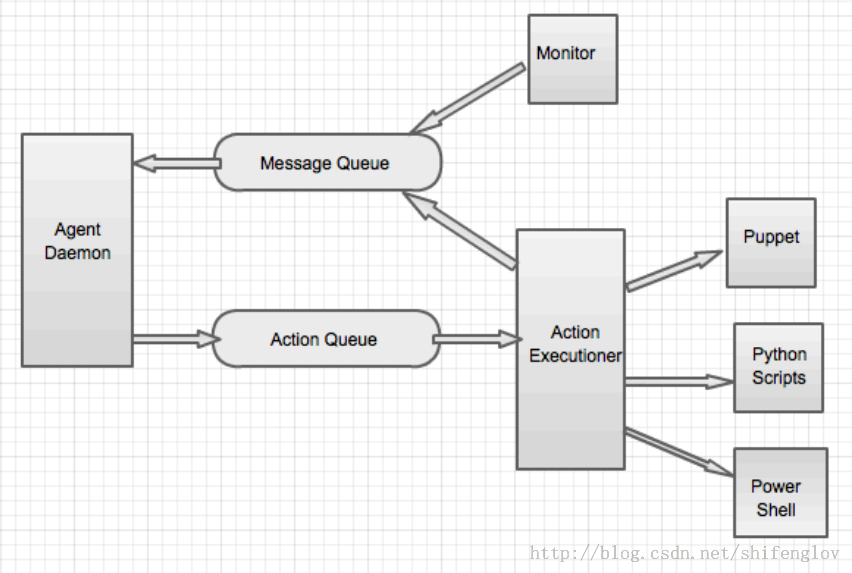
Ambari-agent内部架构
Ambari-agent是一个无状态的,其功能分两部分:
采集所在节点的信息并且汇总发送心跳发送汇报给ambari-server。
处理ambari-server的执行请求。
因此它有两种队列:
(1)、消息队列Message Queue,或称为ResultQueue。包括节点状态信息(包括注册信息)和执行结果信息,并且汇总后通过心跳发送给ambari-server。
(2)、操作队列ActionQueue。用于接收ambari-server发送过来的状态操作,然后交给执行器调用puppet或Python脚本等模块执行任务。
Ambari-server内部架构
Ÿ Live Cluster State:集群现有状态,各个节点汇报上来的状态信息会更改该状态;
Ÿ Desired State:用户希望该节点所处状态,是用户在页面进行了一系列的操作,需要更改某些服务的状态,这些状态还没有在节点上产生作用;
Ÿ Action State:操作状态,是状态改变时的请求状态,也可以看作是一种中间状态,这种状态可以辅助LiveCluster State向Desired State状态转变。
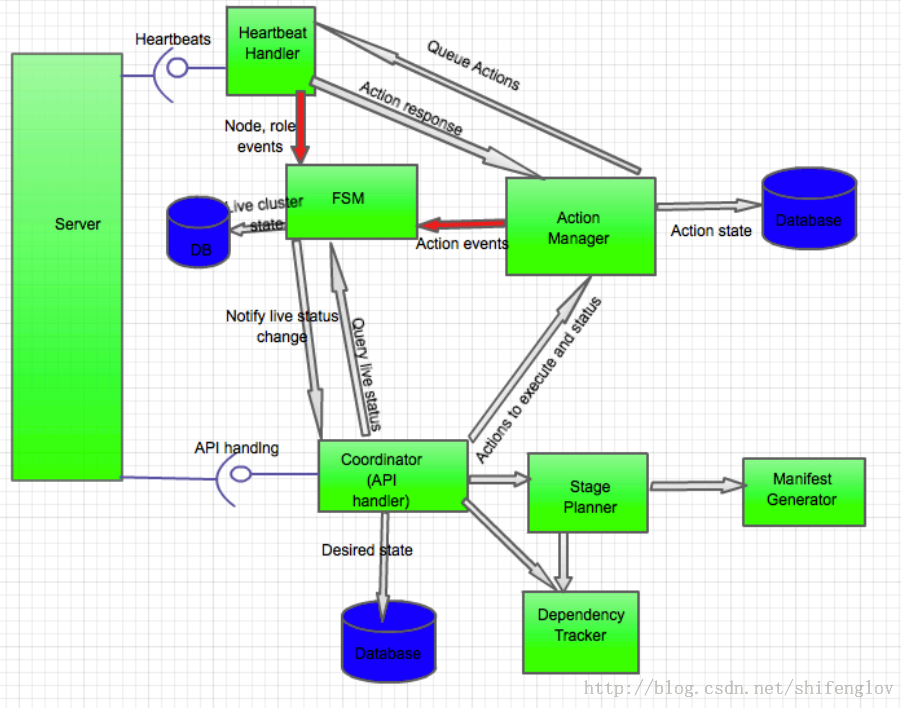
Ambari-server的Heartbeat Handler模块用于接收各个agent的心跳请求(心跳请求里面主要包含两类信息:节点状态信息和返回的操作结果),把节点状态信息传递给FSM状态机去维护着该节点的状态,并且把返回的操作结果信息返回给Action Manager去做进一步的处理。
Coordinator模块又可以称为API handler,主要在接收WEB端操作请求后,会检查它是否符合要求,stageplanner分解成一组操作,最后提供给ActionManager去完成执行操作。
因此,从上图就可以看出,Ambari-Server的所有状态信息的维护和变更都会记录在数据库中,用户做一些更改服务的操作都会在数据库上做一些相应的记录,同时,agent通过心跳来获得数据库的变更历史。
Ambari-web内部架构
Ambari-web使用了一个流行的前端Embar.js MVC框架实现,Embar.js是一个TodoMVC框架,它涵盖了现今典型的单页面应用(single page application)几乎所有的行为。
使用了nodejs
使用brunch 作为项目的构建管理工具
Brunch ,是一个超快的HTML5构建工具。它有如下功能:
(1)、编译你的脚本、模板、样式、链接它们。
(2)、将脚本和模板封装进common.js/AMD模块里,链接脚本和样式。
(3)、为链接文件生成源地图,复制资源和静态文件。
(4)、通过缩减代码和优化图片来收缩输出,看管你的文件更改。
(5)、并通过控制台和系统提示通知你错误。
Nodejs 是一个基于Chrome JavaScript运行时建立的一个平台,用来方便的搭建快速的易于扩展的网络应用,NodeJS借助事件驱动,非阻塞I/O模型变得轻量和高效,非常适合运行在分布式设备的数据密集型的实时应用。
Ambari-web 目录结构
|
目录或文件 |
描述 |
|
app/ |
主要应用程序代码。包括Ember中的view、templates、controllers、models、routes |
|
config.coffee |
Brunch应用程序生成器的配置文件 |
|
package.json |
Npm包管理配置文件 |
|
test/ |
测试文件 |
|
vendor/ |
Javascript库和样式表适用第三方库。 |
Ambari-web/app/
|
目录或文件 |
描述 |
|
assets/ |
静态文件 |
|
controllers/ |
控制器 |
|
data/ |
数据 |
|
mappers/ |
JSON数据到Client的Ember实体的映射 |
|
models |
MVC中的Model |
|
routes/ |
路由器 |
|
styles |
样式文件 |
|
views |
试图文件 |
|
templates/ |
页面模板 |
|
app.js |
Ember主程序文件 |
|
config.js |
配置文件 |
Ambari-server
Ambari-server使用的jetty作为Servlet容器作为内嵌的java服务器,其中相关的代码在server/controller 下的AmbariServer.java中。 其中Session的管理似乎AmbariSessionManager 重写了SessionManager类
(1)、jetty 是一个开源的Servlet容器,它为基于java的web容器,它的API以一组JAR包的形式发布。开发人员可以将Jetty容器实例化成一个对象,可以迅速为一些独立运行的Java应用提供网络和web连接。
(2)、Google Guice 一个google的IOC容器
(3)、Spring
(4)、JAX-RS
Ambari-server依赖于 Ambari-Views 项目
|
包名 |
描述 |
|
org.apache.ambari.server.api.services |
对web接口的入口方法,处理/api/v1/* 的请求 |
|
org.apache.ambari.server.controller |
对Ambari中cluster的管理处理,如新增host,更新service、删除component等 |
|
org.apache.ambari.service.orm.* |
对数据库的操作 |
|
org.apache.ambari.server.agent.rest |
处理与Agent的接口 |
|
org.apache.ambari.security |
是使用Spring Security来做权限管理 |
Ambari Server 会读取 Stack 和 Service 的配置文件。当用 Ambari 创建服务的时候,Ambari Server 传送 Stack 和 Service 的配置文件以及 Service 生命周期的控制脚本到 Ambari Agent。Agent 拿到配置文件后,会下载安装公共源里软件包(Redhat,就是使用 yum 服务)。安装完成后,Ambari Server 会通知 Agent 去启动 Service。之后 Ambari Server 会定期发送命令到 Agent 检查 Service 的状态,Agent 上报给 Server,并呈现在 Ambari 的 GUI 上。

-
每次的REST API的请求都会经过server的请求分发器(Request Dispatcher)分发。若是是操做agent,会经过任务编排器(Orchestrator)生成Stage DAG,依次按顺序下发相应的Stage;若是是对监控、告警的操做,能够经过统一的SPI(Service Provider Interferce)调用完成;
-
Ambari将集群的配置、各个服务的配置等信息持久化在server端的DB中;
server与agent的惟一的交流方式是经过RPC,即agent向server报告心跳,server将command经过response发回给agent,agent本地执行命令,好比:agent端执行相应的服务组件启停的操做。
Ambari最重要的设计思想就是抽象
第一层抽象:资源
在类Unix系统中,咱们确定据说过这样一句话“一切皆是文件”,即普通的文件、目录、块设备、套接字都是以文件被对待,提供统一的操做模型。在Ambari的世界里,“一切皆是资源”。
例子:
Hadoop生态圈的组件被抽象成一个个服务,Ambari Stack能够当作一系列服务的集合,每个Ambari Stack下面对应了适配不一样系统的Ambari Service,好比HDFS、HBase等等;每个Ambari Service一般由不一样的组件构成,好比HDFS包含有不一样的组件Datanode、NameNode;每个组件可能分布在不一样的机器上,好比HDFS的一个DataNode在HostA上,另外一个DataNode在HostB上。Ambari对这些不一样层次的对象作了一层抽象,把它们都看成“资源”来看待:
一个Service由多个ServiceComponent构成,一个ServiceComponent又由多个ServiceComponentHost构成,好比:
-
Service: HDFS, YARN, HBase, etc
-
ServiceComponent: HDFS.NameNode, YARN.ResourceManager, HBase.RegionServer, etc
-
ServiceComponentHost: HDFS.NameNode.HostA, YARN.ResourceManager.HostB, etc
上面的Service、ServiceComponent、ServiceComponentHost都是资源的一种类型,在Ambari中,有多达74种类型(Ambari2.0.0版本)的不一样资源(Resource),每一种类型都有相应的XXXResourceProvider提供相应的操做接口,好比ClusterResourceProvider,又经过XXXService来暴露相应资源的REST API,好比ClusterService。这样一看,对“资源”的增删改查就比较容易理解了。
第二层抽象:操做
对应上面的三种资源,有三种操做的抽象:
-
Operation: Service层面的操做(Install/Start/Stop/Config),一个Operation能够做用于一个或多个Service;
-
Stage: ServicesComponent层面的操做,根据不一样ServicesComponent操做间的依赖关系,一个Operation的全部Task可能被划分红多个Stage,一个Stage内的多个Task相互没有依赖,能够并行执行;
-
Task: ServiceComponentHost层面的操做,为了完成一个Operation,须要为不一样的机器分配一系列的Task去执行;
须要特别说明的是操做的执行顺序,能够将Ambari的Stage DAG类比成Spark计算模型中的RDD DAG:
-
不一样的Stage只能顺序执行。后面的Stage只有在前面Stage执行成功后才会下发给Agent。若是前面Stage失败,后面的Stage将取消;
-
同一个Stage内的多个Task能够并行执行,能够同时下发给Agent,若是某个Task失败,其余的已下发且正执行的Task将被取消;
-
分配给同一个机器的不一样Task只会顺序执行;
下图描述了这三种资源与操做的对应关系:

上述的三个操做抽象是定义态的描述,它们分别对应一个执行态的抽象:
-
StagePlan: 执行态的Operation,是一个Stage DAG;
-
Action:执行态的Stage,由多个Command构成;
-
Command: 执行态的Task,下发给具体的机器执行。主要有如下几种:
-
-
ExecuteCommand: 对服务组件执行INSTALL/START/STOP等操做;
-
StatusCommand: 对服务组件执行死活检查(由Server按期下发);
-
CancelCommand: 取消其余已经下发的Task(当Stage中的某个Task失败时);
-
RegistrationCommand: 要求Agent向Server从新注册(当发现Server维护的心跳序号与Agent上报的不一致时);
-
下图经过一个具体实例(启动HDFS和YARN服务),展现了其Stage DAG的构建逻辑:
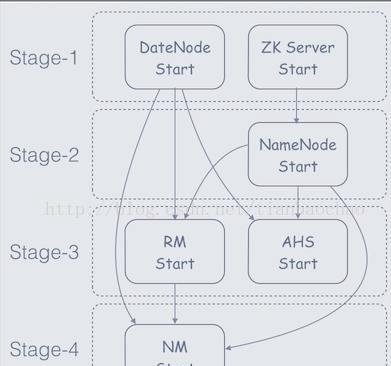
Stage1所有执行完才能够进行Stage2的执行,Stage1里面的Task能够并行执行。
这样的设计模型使得Ambari能够支持几乎全部的组件,作到“包罗万物”。
Ambari目标
解决Hadoop生态系统部署
- 部署:hadoop组件间有依赖,包括配置、版本、启动顺序、权限配置等。
- 部署过程跟踪。能够展示出部署过程中每个步骤的状态及相关信息。
- 多机部署问题,当集群规模增加后,机器出问题机率增加,在部署或更新中可能会出现机器故障
- 组件本身设计:hadoop及其组件需要容忍机器的故障,同时需要防止不兼容版本组件给系统带来的影响
- 部署服务:需要能够容忍某些组件启动、更新失败
配置管理
可以将默认配置写入stack中(stack后续介绍),在开启时ambari将stack中各个版本的config文件读入,在使用blueprint创建集群部署hadoop时,直接生成command-json文件。(blueprint后续介绍)
服务状态展示、监控、报警
Ambari主要概念
资源
ambari将集群及集群中的服务、组件、机器都视为资源,资源的状态都会记录在db中
Hadoop生态
Stack
发行版本的含义,如HDP,可以有若干版本。
Service
服务,属于stack,一个stack下可以有多个service,service也可以分多个版本,版本间可以有继承关系。例如zookeeper就是一项服务。
Component
组件,属于service,一个service下可以有多个component组成。例如HDFS服务下的组件有datanode,namenode等。
角色
Component可以指定部署时的角色,如master、slave等,也可以指定每种角色需要的host个数。例如namenode为单一host组件,可以部署在master机器上,datanode可以部署在多台host上那么可以指定部署datanode的角色为slave
host
host为运行ambari-agent的一台机器,同时也是搭建集群内部的一台机器,可以为host设置对应的角色,例如master,slave等。
Ambari整体流程
restAPI->ambari-server
单步创建
- 通过调用ambari提供的restAPI进行集群的单步创建
- Add cluster:新建集群
- Update cluster:更新集群配置
- Add service for cluster:向集群添加服务
- Add component for service:为每个服务添加对应组件
- Add host for cluster:添加host资源
- Add component on host:设置每个host上运行的组件
- Install/Start/Stop service:安装/开启/关闭 集群的对应服务
Blueprint
调用一次restAPI即可进行集群创建、服务安装、组件部署、服务开始等集群操作,简化了单步创建的调用次数。
ambari-server->ambari-agent
- ambari-server端负责接收rest请求,再向agent端发送命令,发送命令的格式是json,内部包涵部署脚本执行命令(安装/开始/停止服务)所需要的配置信息,这里所指的配置信息一般是手动部署集群需要配置的xml文件,例如hadoop-site.xml文件,在blueprint或单步创建里会有详细说明。
- ambari-agent执行脚本。ambari-agent所执行的脚本存储在ambari-server 机器上的/var/lib/ambari-server/resources/stacks/HDP/2.0.6/下各个service路径下的package路径下的scripts内,脚本的编写语言为python,脚本继承了名为Script的父类,该父类提供了一些函数,例如Script.get_config(),该函数将agent接收来自server端的command-json文件的内容转化为字典格式方便脚本实现部署时对配置的使用。具体anent接收到的command-json保存在了运行agent机器下的/var/lib/ambari-agent/data路径下。
二、基本概念及服务框架
Stacks & Services

Stack为一系列service的集合。可以在Ambari中定义多个不同版本的stacks。比如HDP3.1为一个stack,可以包含Hadoop, Spark等等多个特定版本的service。
- Ambari-stack 表示hadoop某个发行版本,例如HDP-1.0.0,在用ambari创建一个集群时,首先要通过调用restfulAPI设置stack版本。
- stack下包含一个或多个service,例如HDP-2.0.6下包括多个service,分别是 ZOOKEEPER,HDFS,YARN,等。
- 单个service下通过配置service下存储的metainfo.xml来设置构成服务的component(组件)以及部署组件的部署脚本、运行组件的角色名称、部署脚本的文件名称、部署脚本的语言种类等信息。
- stack下package/script/ 存放agent操作相关component(组件)的脚本,ambari-agent会根据脚本的函数名称调用脚本的对应函数。
- stack版本可以通过metainfo.xml设置继承关系。例如HDP-2.1继承了HDP-2.0.6的各个服务。
Ambari stack目录结构

HDP
2.0.6
metainfo.xml (stack的相关信息,包括继承关系等版本层的性质)
services (该路径下存储各个服务)
ZOOKEEPER
metainfo.xml (里面配置了组件名称,操作组件的脚本名称,脚本的语言种类等信息)
configuration
global.xml (服务配置,在blueprint创建集群时使用)
zookeeper-log4j.xml
package
scripts
zookeeper_server.py (组件的操作脚本 包括安装、查询状态、开启组件、关闭组件等操作)
zookeeper_cilent.py
...
templates (在部署时脚本里所用到的模板文件)
...
YARN
...
HDFS
...
...
hooks (在调用脚本前需要执行的脚本,例如为集群各个服务创建linux-user)
...
repos (yum安装所需要的repos配置信息)
...
当写创建好stack后,需要重启ambari-server。可以在浏览器中通过restfulAPI来查看stack创建是否成功。
http://:8080/api/v1/stacks对于服务下的metainfo.xml一定要保证格式、内容的正确性,如果ambari不能正常读取,那将识别不出stack的信息。
Stack和Service的关系
Ambari中stacks相关的配置信息位于:
- 源码包:ambari-server/src/main/resources/stacks
- 安装后:/var/lib/ambari-server/resources/stacks
如果多个stacks需要使用相同的service配置,需要将配置放置于common-services中。common-services目录中存放的内容可供任意版本的stack直接使用或继承。
common-services目录
common-services目录位于源码包的ambari-server/src/main/resources/common-services目录中。如果某个服务需要在多个stacks之中共享,需要将此service定义在common-services中。通常来说common-services中给出了各个service的公用配置。比如下文提到的组件在ambari中的配置项(configuration)部分的配置。
Service目录结构
Service的目录结构如下所示:

HDFS Service目录结构:
root@/var/lib/ambari-server/resources/stacks/HDP$ tree 3.0/services/HDFS/
3.0/services/HDFS/
├── alerts.json
├── configuration
│ ├── core-site.xml
│ ├── hadoop-env.xml
│ ├── hadoop-metrics2.properties.xml
│ ├── hadoop-policy.xml
│ ├── hdfs-log4j.xml
│ ├── hdfs-site.xml
│ ├── ranger-hdfs-audit.xml
│ ├── ranger-hdfs-plugin-properties.xml
│ ├── ranger-hdfs-policymgr-ssl.xml
│ ├── ranger-hdfs-security.xml
│ ├── ssl-client.xml
│ ├── ssl-server.xml
│ └── viewfs-mount-table.xml
├── kerberos.json
├── metainfo.xml
├── metrics.json
├── package
│ ├── alerts
│ │ ├── alert_checkpoint_time.py
│ │ ├── alert_checkpoint_time.pyc
│ │ ├── alert_checkpoint_time.pyo
│ │ ├── alert_datanode_unmounted_data_dir.py
│ │ ├── alert_datanode_unmounted_data_dir.pyc
│ │ ├── alert_datanode_unmounted_data_dir.pyo
│ │ ├── alert_ha_namenode_health.py
│ │ ├── alert_ha_namenode_health.pyc
│ │ ├── alert_ha_namenode_health.pyo
│ │ ├── alert_metrics_deviation.py
│ │ ├── alert_metrics_deviation.pyc
│ │ ├── alert_metrics_deviation.pyo
│ │ ├── alert_upgrade_finalized.py
│ │ ├── alert_upgrade_finalized.pyc
│ │ └── alert_upgrade_finalized.pyo
│ ├── archive.zip
│ ├── files
│ │ ├── checkWebUI.py
│ │ ├── checkWebUI.pyc
│ │ └── checkWebUI.pyo
│ ├── scripts
│ │ ├── balancer-emulator
│ │ │ ├── balancer-err.log
│ │ │ ├── balancer.log
│ │ │ ├── hdfs-command.py
│ │ │ ├── hdfs-command.pyc
│ │ │ └── hdfs-command.pyo
│ │ ├── datanode.py
│ │ ├── datanode.pyc
│ │ ├── datanode.pyo
│ │ ├── datanode_upgrade.py
│ │ ├── datanode_upgrade.pyc
│ │ ├── datanode_upgrade.pyo
│ │ ├── hdfs_client.py
│ │ ├── hdfs_client.pyc
│ │ ├── hdfs_client.pyo
│ │ ├── hdfs_datanode.py
│ │ ├── hdfs_datanode.pyc
│ │ ├── hdfs_datanode.pyo
│ │ ├── hdfs_namenode.py
│ │ ├── hdfs_namenode.pyc
│ │ ├── hdfs_namenode.pyo
│ │ ├── hdfs_nfsgateway.py
│ │ ├── hdfs_nfsgateway.pyc
│ │ ├── hdfs_nfsgateway.pyo
│ │ ├── hdfs.py
│ │ ├── hdfs.pyc
│ │ ├── hdfs.pyo
│ │ ├── hdfs_rebalance.py
│ │ ├── hdfs_rebalance.pyc
│ │ ├── hdfs_rebalance.pyo
│ │ ├── hdfs_snamenode.py
│ │ ├── hdfs_snamenode.pyc
│ │ ├── hdfs_snamenode.pyo
│ │ ├── __init__.py
│ │ ├── __init__.pyc
│ │ ├── __init__.pyo
│ │ ├── install_params.py
│ │ ├── install_params.pyc
│ │ ├── install_params.pyo
│ │ ├── journalnode.py
│ │ ├── journalnode.pyc
│ │ ├── journalnode.pyo
│ │ ├── journalnode_upgrade.py
│ │ ├── journalnode_upgrade.pyc
│ │ ├── journalnode_upgrade.pyo
│ │ ├── namenode_ha_state.py
│ │ ├── namenode_ha_state.pyc
│ │ ├── namenode_ha_state.pyo
│ │ ├── namenode.py
│ │ ├── namenode.pyc
│ │ ├── namenode.pyo
│ │ ├── namenode_upgrade.py
│ │ ├── namenode_upgrade.pyc
│ │ ├── namenode_upgrade.pyo
│ │ ├── nfsgateway.py
│ │ ├── nfsgateway.pyc
│ │ ├── nfsgateway.pyo
│ │ ├── params_linux.py
│ │ ├── params_linux.pyc
│ │ ├── params_linux.pyo
│ │ ├── params.py
│ │ ├── params.pyc
│ │ ├── params.pyo
│ │ ├── params_windows.py
│ │ ├── params_windows.pyc
│ │ ├── params_windows.pyo
│ │ ├── service_check.py
│ │ ├── service_check.pyc
│ │ ├── service_check.pyo
│ │ ├── setup_ranger_hdfs.py
│ │ ├── setup_ranger_hdfs.pyc
│ │ ├── setup_ranger_hdfs.pyo
│ │ ├── snamenode.py
│ │ ├── snamenode.pyc
│ │ ├── snamenode.pyo
│ │ ├── status_params.py
│ │ ├── status_params.pyc
│ │ ├── status_params.pyo
│ │ ├── utils.py
│ │ ├── utils.pyc
│ │ ├── utils.pyo
│ │ ├── zkfc_slave.py
│ │ ├── zkfc_slave.pyc
│ │ └── zkfc_slave.pyo
│ └── templates
│ ├── exclude_hosts_list.j2
│ ├── hdfs.conf.j2
│ ├── hdfs_dn_jaas.conf.j2
│ ├── hdfs_jaas.conf.j2
│ ├── hdfs_jn_jaas.conf.j2
│ ├── hdfs_nn_jaas.conf.j2
│ ├── include_hosts_list.j2
│ ├── input.config-hdfs.json.j2
│ └── slaves.j2
├── quicklinks
│ └── quicklinks.json
├── service_advisor.py
├── service_advisor.pyc
├── service_advisor.pyo
├── themes
│ ├── directories.json
│ └── theme.json
└── widgets.json
9 directories, 135 files
root@/var/lib/ambari-server/resources/stacks/HDP$
如图所示,以HDFS为例,每个service的组成部分解释如下:
- Service ID:通常为大写,为Service名称。
- configuration:存放了service对应的配置文件。该配置文件为XML格式。这些XML文件描述了service的配置项如何Ambari的组件配置页面展示(即service的图形化配置页面的配置文件,配置该页面包含什么配置项)。
- package:该目录包含了多个子目录。其中用service控制脚本(启动,停止和自定义操作等)和组件的配置文件模板。
- alert.json:service的告警信息定义。
- kerberos.json:service和Kerberos结合使用的配置信息。
- metainfo.xml:service最为重要的配置文件。其中定义的service的名称,版本号,简介和控制脚本名称等等信息。
- metrics.json:service的监控信息配置文件。
- widgets.json:service的监控图形界面展示的配置。
以Spark2为例:
- configuration目录下存放的是spark2的属性配置文件,对应Ambari页面的属性配置页面,可以设置默认值,类型,描述等信息
- package/scripts目录下存放服务操作相关的脚本,如服务的启动,服务停止,服务检查等
- package/templates该目录可选,存放的是组件属性的配置信息,和configuration目录下的配置对应,这个关系是若果我们在Ambari页面修改了属性信息,则修改信息会自动填充该目录下文件的属性,所以,这个目录下的属性是最新的,并且是服务要调用的
- package/alerts目录存放告警配置,如程序断掉或者其他原因未运行时会出现告警或者可以定义其他告警
- quicklinks该目录下存放的是快速链接配置,Ambari页面通过该配置可以跳转到我们想要跳转的页面,如HDFS,快速链接页面指向的地址是 http://node:50070
- metrics.json用来配置指标显示
- kerberos.json用来配置kerberos认证
- metainfo.json这个文件很重要,主要是配置服务名,服务类型,服务操作脚本,metrics以及快速链接等
metainfo.xml 详解
不仅service具有metainfo.xml配置文件,stack也会有这个配置文件。对于stack来说,metainfo.xml基本用于指定各个stack之间的继承关系。
service metainfo.xml的基础配置项:
<services>
<service>
<name>HDFS</name>
<displayName>HDFS</displayName>
<comment>Hadoop分布式文件系统。</comment>
<version>2.1.0.2.0</version>
</service>
</services>displayName,comment和version中的内容会展示在安装service的第一步,勾选所需组件的列表中。
component相关配置
component配置组规定了该服务下每个组件的部署方式和控制脚本等内容。举例来说,对于HDFS这个service,它的component包含namenode,datanode,secondary namenode以及HDFS client等。在component配置项中可以对这些组件进行配置。
HDFS的namenode组件配置:
<component>
<name>NAMENODE</name>
<displayName>NameNode</displayName>
<category>MASTER</category>
<cardinality>1-2</cardinality>
<versionAdvertised>true</versionAdvertised>
<reassignAllowed>true</reassignAllowed>
<commandScript>
<script>scripts/namenode.py</script>
<scriptType>PYTHON</scriptType>
<timeout>1800</timeout>
</commandScript>
<logs>
<log>
<logId>hdfs_namenode</logId>
<primary>true</primary>
</log>
<log>
<logId>hdfs_audit</logId>
</log>
</logs>
<customCommands>
<customCommand>
<name>DECOMMISSION</name>
<commandScript>
<script>scripts/namenode.py</script>
<scriptType>PYTHON</scriptType>
<timeout>600</timeout>
</commandScript>
</customCommand>
<customCommand>
<name>REBALANCEHDFS</name>
<background>true</background>
<commandScript>
<script>scripts/namenode.py</script>
<scriptType>PYTHON</scriptType>
</commandScript>
</customCommand>
</customCommands>
</component>其中各个配置项的解释:
- name:组件名称。
- displayName:组件显示的名称。
- category:组件的类型,包含MASTER,SLAVE和CLIENT三种。其中MASTER和SLAVE是有状态的(启动和停止),CLIENT是无状态的。
- cardinality:该组件可以安装几个实例。可以支持如下格式。1:一个实例。1-2:1个至2个实例。1+:1个或多个实例。
- commandScript:组件的控制脚本配置。
- logs:为log search服务提供日志接入。
其中commandScript中的配置项含义如下:
- script:该组件的控制脚本相对路径。
- scriptType:脚本类型,通常我们使用Python脚本。
- timeout:脚本执行的超时时间。
customCommands配置
该配置项为组件的自定义命令,即除了启动,停止等等系统自带命令之外的命令。
下面以HDFS的REBALANCEHDFS命令为例说明下。
<customCommand>
<name>REBALANCEHDFS</name>
<background>true</background>
<commandScript>
<script>scripts/namenode.py</script>
<scriptType>PYTHON</scriptType>
</commandScript>
</customCommand>该配置项会在service管理页面右上方菜单增加新的菜单项。配置项的含义和CommandScript相同。其中background为true说明此command为后台执行。
接下来大家可能有疑问,当点击这个custom command的菜单项之后,ambari调用了namenode.py这个文件的哪个函数呢?
实际上ambari会调用和customCommand的name相同,名称全为小写的python方法。如下所示。
def rebalancehdfs(self, env):
...osSpecifics配置
同一个service的安装包在不同的平台下,名字通常是不一样的。安装包的名称和系统的对应关系是该配置项所负责的内容。
Zookeeper的osSpecifics配置示例
<osSpecifics>
<osSpecific>
<osFamily>amazon2015,redhat6,redhat7,suse11,suse12</osFamily>
<packages>
<package>
<name>zookeeper_${stack_version}</name>
</package>
<package>
<name>zookeeper_${stack_version}-server</name>
</package>
</packages>
</osSpecific>
<osSpecific>
<osFamily>debian7,ubuntu12,ubuntu14,ubuntu16</osFamily>
<packages>
<package>
<name>zookeeper-${stack_version}</name>
</package>
<package>
<name>zookeeper-${stack_version}-server</name>
</package>
</packages>
</osSpecific>
</osSpecifics>注意:该配置中name为组件安装包全名除了版本号以外的部分。需要在系统中使用apt search 或者 yum search能够搜索到。如果包搜索不到,或者说没有当前系统对应的osFamily,service在安装过程不会报错,但是软件包并没有被安装,这点一定要注意。
service的继承关系配置
以HDP这个stack为例,各个版本的HDP存在继承关系,高版本的HDP的各个组件的配置继承自低版本的HDP。这条继承线可以一直追溯至HDP2.0.6。
此时common-services中的配置为何可以共用就得到了解释。common-services中的service配置之所以会生效,是因为在最基础的HDP stack(2.0.6)中,每个service都继承了common-services中的对应配置。
例如AMBARI_INFRA这个service。
<services>
<service>
<name>AMBARI_INFRA</name>
<extends>common-services/AMBARI_INFRA/0.1.0</extends>
</service>
</services>
HDP中的AMBARI_INFRA这个service的配置继承自common-services中的AMBARI_INFRA/0.1.0的配置。其他组件也是类似的,有兴趣可以查看下相关源代码。
禁用service
加入deleted标签,该service在新增service向导的列表中会被隐藏。
<services>
<service>
<name>FALCON</name>
<version>0.10.0</version>
<deleted>true</deleted>
</service>
</services>configuration-dependencies配置
列出了组件依赖的配置类别。如果依赖的配置类更新了配置信息,该组件会被ambari标记为需要重新启动。
其他配置项
更为详细的介绍请参考官方文档:https://cwiki.apache.org/confluence/display/AMBARI/Writing+metainfo.xml
configuration配置文件
configuration包含了一个或多个xml配置文件。其中每一个xml配置文件都代表了一个配置组。配置组名为xml文件名。
每个xml文件中规定了service配置项的名称,value类型和描述。
下面以HDFS的部分配置项为例说明。
<property>
<!-- 配置项名称 -->
<name>dfs.https.port</name>
<!-- 配置的默认值 -->
<value>50470</value>
<!-- 配置的描述,即鼠标移动到文本框弹出的提示 -->
<description>
This property is used by HftpFileSystem.
</description>
<on-ambari-upgrade add="true"/>
</property>
<property>
<name>dfs.datanode.max.transfer.threads</name>
<value>1024</value>
<description>Specifies the maximum number of threads to use for transferring data in and out of the datanode.
</description>
<display-name>DataNode max data transfer threads</display-name>
<!-- 这里规定了属性值的类型为int,最小值为0,最大值为48000 -->
<value-attributes>
<type>int</type>
<minimum>0</minimum>
<maximum>48000</maximum>
</value-attributes>
<on-ambari-upgrade add="true"/>
</property>其他更多的配置项,请参考官方文档:https://cwiki.apache.org/confluence/display/AMBARI/Configuration+support+in+Ambari
在Python脚本中读取配置项的值
举例来说,此处我们需要在控制脚本中读取用户在页面填写的instance_name配置项的值。
配置项的配置文件为: configuration/sample.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>instance_name</name>
<value>instance1</value>
<description>Instance name for samplesrv</description>
</property>
</configuration>在python脚本中的读取方法为:
params.py
from resource_management.libraries.script import Script
config = Script.get_config()
# config被封装为了字典格式,层级为configurations/文件名/属性名
instance_name = config['configurations']['sample']['instance_name']
组件控制脚本的编写
组件的控制脚本位于package/scripts中。脚本必须继承resource_management.Script类。
- package/scripts: 控制脚本
- package/files: 控制脚本使用的文件
- package/templates: 生成配置文件的模板文件,比如core-site.xml, hdfs-site.xml的样板配置文件等。
Ambari-stack 脚本编写规则介绍
Ambari-agent在执行脚本时,会根据脚本的函数名进行调用。以下是基本操作函数。
实现方式是一个组件建一个类,该类可以继承ambari提供的父类Script。该父类提供了一些默认方法例如状态检查,转换json等方法。
install()
在调用ambari-server安装对应服务的restapi时,ambari-server会给ambari-agent发送command-json格式的文件,agent会调用脚本中名为install()函数来进行部署。
函数作用在于在集群内部署该服务的对应组件。
start()
函数作用是开启该服务下对应组件。
注意:该方法需要在install成功后调用。
stop()
该函数作用是停止该服务下的对应组件。
注意:该方法调用的api与install相同且组件状态为STARTED。
status()
在组件开启后,agent会不断检测组件的状态,并把状态通过心跳汇报给server端,server端收到心跳状态后更新当前集群的服务信息,当用户调用install api来停止组件时,server根据更新后的组件信息来向对应的host发出命令,如果某组件异常终止,那么server在发送停止命令时不会向异常终止的组件所在的agent发送停止命令。
status()状态检查可以使用父类提供的一种方式,check_process_status(file_path),该函数针对提供的文件路径检查对应文件内部的组件进程号是否存在,如果不存在,那么agent就通过心跳汇报给server。
main()
操作脚本的main函数直接调用父类的execute()函数即可。一个最简单的控制脚本文件:
import sys
from resource_management import Script
class Master(Script):
def install(self, env):
# 安装组件时执行的方法
print 'Install the Sample Srv Master';
def stop(self, env):
# 停止组件时执行的方法
print 'Stop the Sample Srv Master';
def start(self, env):
# 启动组件时执行的方法
print 'Start the Sample Srv Master';
def status(self, env):
# 组件运行状态检测方法
print 'Status of the Sample Srv Master';
def configure(self, env):
# 组件配置更新时执行的方法
print 'Configure the Sample Srv Master';
if __name__ == "__main__":
Master().execute()ambari为编写控制脚本提供了如下库:
- resource_management
- ambari_commons
- ambari_simplejson
这些库提供了常用的操作命令,无需再引入额外的Python包。
如果需要针对不同的操作系统编写不同的script,需要在继承resource_management.Script之时添加不同的@OsFamilyImpl()注解。
下面给出常用的部分控制脚本片段的写法。
检查PID文件是否存在(进程是否运行)
from resource_management import *
# 如果pid文件不存在,会抛出ComponentIsNotRunning异常
check_process_status(pid_file_full_path)Template 填充配置文件模板
使用用户在service页面配置中填写的值,来填充组件的配置模板,生成最终的配置文件。
# params文件提前将用户在配置页填写的配置项的值读取进来
# 对于config-template.xml.j2所有的模板变量,必须在params文件中定义,否则模板填充会报错,也就是说所有模板内容必须能够正确填充。
import params
env.set_params(params)
# config-template为configuration文件夹中的j2文件名
file_content = Template('config-template.xml.j2')
Python替换配置文件模板使用的是Jinja2模板
InlineTemplate
和Template相同,只不过配置文件的模板来自于变量值,而不是Template中的xml模板
file_content = InlineTemplate(self.getConfig()['configurations']['gateway-log4j']['content'])File
把内容写入文件
File(path,
content=file_content,
owner=owner_user,
group=sample_group)Directory
创建目录
Directory(directories,
create_parents=True,
mode=0755,
owner=params.elastic_user,
group=params.elastic_group
)User
用户操作
# 创建用户
User(user_name, action = "create", groups = group_name)Execute
执行特定的脚本
Execute('ls -al', user = 'user1')Package 安装指定的软件包
Package(params.all_lzo_packages,
retry_on_repo_unavailability=params.agent_stack_retry_on_unavailability,
retry_count=params.agent_stack_retry_count)RPM包制作
更多参考:https://daimajiaoliu.com/daima/479bfe70c900402
Ambari中,组件都是以RPM包的方式安装的,因此我们自定义的组件也需要打包RPM
- 安装rpm-build
yum install rpm-build 2. 编写SPEC文件
SPEC文件关键字
SPEC文件是RPM文件的组织说明,主要配置项如下所述
Name:软件包的名称,后面可以使用%{name}的方式引用
Summary:软件包的内容概要
Version:软件的实际版本号,如,1.1.0,后面可使用%{version}来引用
Release:发布序列号,如,BDP等,标明第几次打包,后面可以使用%{Release}引用
Group: 软件分组,建议使用标准分组
License: 软件授权方式,通常就是GPL
Source: 源代码包,可以带多个用Source1、Source2等源,后面也可以用%{source1}、%{source2}引用
BuildRoot: 这个是安装或编译时使用的“虚拟目录”,考虑到多用户的环境,一般定义为:%{tmppath}/{name}-%{version}-%{release}-root或%{tmppath}/%{name}-%{version}-%{release}-buildroot-%%__id_u} -n}.该参数非常重要,因为在生成rpm的过程中,执行make install时就会把软件安装到上述的路径中,在打包的时候,同样依赖“虚拟目录”为“根目录”进行操作。后面可使用$RPM_BUILD_ROOT 方式引用。
URL: 软件的主页
Vendor: 发行商或打包组织的信息,例如RedFlag Co,Ltd
Disstribution: 发行版标识
Patch: 补丁源码,可使用Patch1、Patch2等标识多个补丁,使用%patch0或%{patch0}引用
Prefix: %{_prefix} 这个主要是为了解决今后安装rpm包时,并不一定把软件安装到rpm中打包的目录的情况。这样,必须在这里定义该标识,并在编写%install脚本的时候引用,才能实现rpm安装时重新指定位置的功能
Prefix: %{sysconfdir} 这个原因和上面的一样,但由于%{prefix}指/usr,而对于其他的文件,例如/etc下的配置文件,则需要用%{_sysconfdir}标识
Build Arch: 指编译的目标处理器架构,noarch标识不指定,但通常都是以/usr/lib/rpm/marcros中的内容为默认值
Requires: 该rpm包所依赖的软件包名称,可以用>=或<=表示大于或小于某一特定版本,例如:libpng-devel >= 1.0.20 zlib ※“>=”号两边需用空格隔开,而不同软件名称也用空格分开,还有例如PreReq、Requires(pre)、Requires(post)、Requires(preun)、Requires(postun)、BuildRequires等都是针对不同阶段的依赖指定
Provides: 指明本软件一些特定的功能,以便其他rpm识别
Packager: 打包者的信息
description 软件的详细说明
SPEC脚本主体
%setup -n %{name}-%{version}** 把源码包解压并放好通常是从/usr/src/asianux/SOURCES里的包解压到/usr/src/asianux/BUILD/%{name}-%{version}中。一般用%setup -c就可以了,但有两种情况:一就是同时编译多个源码包,二就是源码的tar包的名称与解压出来的目录不一致,此时,就需要使用-n参数指定一下了。
%patch 打补丁通常补丁都会一起在源码tar.gz包中,或放到SOURCES目录下。一般参数为:
%patch -p1 使用前面定义的Patch补丁进行,-p1是忽略patch的第一层目
%Patch2 -p1 -b xxx.patch 打上指定的补丁,-b是指生成备份文件
%setup -n %{name}-%{version}** 把源码包解压并放好通常是从/usr/src/asianux/SOURCES里的包解压到/usr/src/asianux/BUILD/%{name}-%{version}中。一般用%setup -c就可以了,但有两种情况:一就是同时编译多个源码包,二就是源码的tar包的名称与解压出来的目录不一致,此时,就需要使用-n参数指定一下了。
%patch 打补丁通常补丁都会一起在源码tar.gz包中,或放到SOURCES目录下。一般参数为:
%patch -p1 使用前面定义的Patch补丁进行,-p1是忽略patch的第一层目
%Patch2 -p1 -b xxx.patch 打上指定的补丁,-b是指生成备份文件
Eg:
Redis RPM包制作
1.到官网下载redis源码包,最新版本为4.0.10,解压并且编译
make PREFIX=/opt/redis install
2.在/opt/redis/bin目录可以看到编译后的文件
3.创建 redis_2_6_2_0_205-4.0.10.2.6.2.0/usr/hdp/2.6.2.0-205/redis/目录
mkdir -p /opt/redis_2_6_2_0_205-4.0.10.2.6.2.0/usr/hdp/2.6.2.0-205/redis/
4.在3中的目录下创建bin,etc/redis及conf软链,r软链指向/etc/redis/conf
mkdir bin,mkdir etc/redis
创建软链是需要注意,由于系统中/etc/redis/conf目录是不存在的,所以先要创建,然后执行 ln /etc/redis/conf conf
创建完成后,可以将/etc/redis/conf删除
5.将2中bin目录下的文件拷贝到 /opt/redis_2_6_2_0_205-4.0.10.2.6.2.0/usr/hdp/2.6.2.0-205/redis/bin目录下,将redis.conf拷贝到/opt/redis_2_6_2_0_205-4.0.10.2.6.2.0/usr/hdp/2.6.2.0-205/redis/etc/redis 目录下
6.将redis_2_6_2_0_205-4.0.10.2.6.2.0压缩成tar.gz
tar zcvf ./redis_2_6_2_0_205-4.0.10.2.6.2.0.tar.gz ./redis_2_6_2_0_205-4.0.10.2.6.2.0
7.创建redis spec文件–redis_2_6_2_0_205-4.0.10.2.6.2.0-205.noarch.rpm.spec
8.创建打包所需要的路径
mkdir -p ~/rpmbuild/{RPMS,SRPMS,BUILD,SOURCES,SPECS,tmp}
9.将spec文件拷贝到创建的SPECS目录下
10.将tar.gz包放到SOURCES目录下
11.执行打包
rpmbuild -bb –target noarch SPECS/redis_2_6_2_0_205-4.0.10.2.6.2.0-205.noarch.rpm.spec
12.安装并验证
验证安装完后,记得要卸载,rpm -e redis_2_6_2_0_205,不然后续安装会出现问题
Ambari官网参考资料
https://cwiki.apache.org/confluence/display/AMBARI/Defining+a+Custom+Stack+and+Services
三、Ambari之自定义Stack和Service
- 可以从/ambari-server/src/main/resources/stacks源码中查找Stack的相关定义;
- 当安装完ambari-server后,可以在/var/lib/ambari-server/resources/stacks目录下查找stack相关定义;
Ambari-stack 表示HDP的某个发行版本,例如HDP-1.0.0,在用ambari创建一个集群时,首先要通过调用restfulAPI设置stack版本
stack下包含一个或多个service,例如HDP-2.6.2下包括 ZOOKEEPER,HDFS,YARN等
单个service下通过配置service下的metainfo.xml来设置构成服务的component(组件)以及部署组件的部署脚本、运行组件的角色名称、部署脚本的文件名称、部署脚本的语言种类等信息。
stack下package/script/ 存放agent操作相关component(组件)的脚本,ambari-agent会根据脚本的函数名称调用脚本的对应函数
stack版本可以通过metainfo.xml设置继承关系。例如HDP-2.6继承了HDP-2.5的各个服务。
使用场景:当我们需要构建属于自己版权的数据平台,定制化数据平台或数据平台作为产品时,修改栈名是有必要的。
Ambari源码中为我们提供了修改栈名的脚本
所有的代码都在ambari-common模块的 pluggable_stack_definition 目录下

- configs目录下是用来定义栈名称,继承关系,栈中所包含的service等
- resources目录,自定义栈名目录,cust_stack_map.js配置自定义栈名的版本范围,custom-ui.less和custom-admin-ui.css配置样式
- GenerateStackDefinition.py 是用来生成新栈的主脚本
执行命令
python GenerateStackDefinition.py -c ./configs/BDP.json -r ../../../../../ambari-server/src/main/resources/ -o ./BDP参数说明: -c 表示指定的皮遏制文件 -r 表示指定的resource目录 -o 表示输出目录
我们以生成BDP(Big data platform)为例来说明如何生成新栈
- 在configs目录下新建BDP.json,并配置版本,版本依赖,包含的service
- 在resource 目录下新建BDP目录,在custom_stack_map.js中配置版本信息,最小版本,最大版本
- 执行生成脚本
- 将生成的BDP目录拷贝到ambari-server 模块的 resource/statcks目录下,重新编译,打包,安装
Stack配置
stack必须包含或者集成以下两个配置: stack_features.json and stack_tools.json,配置目录必须在stack根目录下;
stack_features.json: 该配置包含了在ambari中定义的一些的特征,并包含该特征的版本、描述信息。比如,配置如下:
{
"stack_features": [
{
"name": "rolling_upgrade",
"description": "Rolling upgrade support",
"min_version": "0.1.0.0"
},
{
"name": "config_versioning",
"description": "Configurable versions support",
"min_version": "0.1.0.0"
},
{
"name": "snappy",
"description": "Snappy compressor/decompressor support",
"min_version": "0.1.0.0"
},
{
"name": "ranger_kerberos_support",
"description": "Ranger Kerberos support",
"min_version": "0.1.0.0"
},
{
"name": "ranger_audit_db_support",
"description": "Ranger Audit to DB support",
"min_version": "0.1.0.0"
}
]
}stack_tools.json: 该配置包含了stack_selector和conf_selector安装路径;比如:
{
"stack_selector": ["hdp-select", "/usr/bin/hdp-select", "hdp-select"],
"conf_selector": ["conf-select", "/usr/bin/conf-select", "conf-select"]
}
定义一个stack和component
一个Service中metainfo.xml文件定义了该Service所依赖的组件及该组件的管理脚本等;Service组件的状态可以为: MASTER, SLAVE 或者 CLIENT状态,在metainfo.xml文件中是通过 指定的;
Master install, start, stop, configure, status Slave install, start, stop, configure, status Clinet install, configure, status
Ambari支持基于Python的各种命令, 你也可以通过定义customCommands实现不在lifecycle之内的其他生命周期执行命令;
比如说YARN的metainfo.xml配置如下:
<component>
<name>RESOURCEMANAGER</name>
<category>MASTER</category>
<commandScript>
<script>scripts/resourcemanager.py</script>
<scriptType>PYTHON</scriptType>
<timeout>600</timeout>
</commandScript>
<customCommands>
<customCommand>
<name>DECOMMISSION</name>
<commandScript>
<script>scripts/resourcemanager.py</script>
<scriptType>PYTHON</scriptType>
<timeout>600</timeout>
</commandScript>
</customCommand>
</customCommands>
</component>其中, RESOURCEMANAGER是一个master组件,执行脚本为scripts/resourcemanager.py,该目录位置为services/YARN/package, 该脚本基于Python实现并实现默认生命周期的执行动作。比如说install动作实现如下:
class Resourcemanager(Script):
def install(self, env):
self.install_packages(env)
self.configure(env)在上述配置中还实现了一个默认生命周期以外的一个DECOMMISSION动作,其实现如下
def decommission(self, env):
import params
...
Execute(yarn_refresh_cmd,
user=yarn_user
)
passStack继承
Stack可以继承其他的Stack,以便于共享脚本和配置,可以通过以下几种方式来避免代码的重复:
* 定义Stack的子仓库;
* 定义Stack的自仓库的新Service;
* 重载父Stack的Service;
* 重载父Stack的Service配置;
比如说HDP2.1 Stack继承HDP 2.06 Stack,只需要在metainfo.xml配置中添加以下配置既可:
<metainfo>
<versions>
<active>true</active>
</versions>
<extends>2.0.6</extends>
</metainfo>stacks/BDP/0.1完整的目录结构应该是:
├── configuration
│ └── cluster-env.xml
├── metainfo.xml
├── properties
│ ├── stack_features.json
│ ├── stack_packages.json
│ └── stack_tools.json
├── repos
│ └── repoinfo.xml
└── services
├── stack_advisor.pyconfiguration/cluster-env.xml 和 properties下的这个文件都是需要的,因为我们不集成 HDP 2.0.6,因此这里都需要 。
注意:

(1) 源码:ambari-server/src/main/java/org/apache/ambari/server/api/services/stackadvisor/StackAdvisorHelper.java 这里写ZOOKEEPER,我这边完全自定义的话,需要修改代码

(2)源码:ambari-server/src/main/java/org/apache/ambari/server/controller/internal/AbstractProviderModule.java 这里需要增加一个判断:
四、ambari的服务启动顺序如何设置
1、Role Command Order
角色是组件的另一个名称(例如:NAMENODE,DATANODE,RESOURCEMANAGER,HBASE_MASTER等)。 顾名思义,可以告诉Ambari关于应该为堆栈中定义的组件运行命令的顺序。 例如:“应在启动NameNode之前启动ZooKeeper服务器”。或者“只有在NameNode和DataNodes启动后才能启动HBase Master”。 这可以通过在stack-version文件夹中包含role_command_order.json文件来指定。
在Ambari的Service目录中,存在很多个叫做role_command_order.json的配置文件。这个文件中定义了Service状态以及Action的依赖。
resource目录下的role_command_order.json定义着全局的的依赖。每个Stack目录下也会存在role_command_order.json。相同的配置,Stack下面的会覆盖全局的。不同的配置,Ambari会拼接在一起。高版本的Stack会继承低版本的配置。相同的也会overwrite,不同的merge。
2、Format
该文件以JSON格式指定,包含一个JSON对象。在每个section对象中,键描述了依赖的component-action,值列出了应该在它之前完成的component-actions。
{
"_comment": "Section 1 comment",
"section_name_1": {
"_comment": "Section containing role command orders",
"<DEPENDENT_COMPONENT_1>-<COMMAND>": ["<DEPENDS_ON_COMPONENT_1>-<COMMAND>", "<DEPENDS_ON_COMPONENT_1>-<COMMAND>"],
"<DEPENDENT_COMPONENT_2>-<COMMAND>": ["<DEPENDS_ON_COMPONENT_3>-<COMMAND>"],
...
},
"_comment": "Next section comment",
...
}
3、Sections
general_deps 命令顺序适用于所有情况 optional_glusterfs 当集群没有GLUSTERFS服务实例时,将应用命令顺序 optional_no_glusterfs 当集群具有GLUSTERFS服务的实例时,将应用命令顺序 namenode_optional_ha 安装HDFS服务且存在JOURNALNODE组件时启用命令顺序(启用HDFS HA) resourcemanager_optional_ha 安装YARN服务时存在命令顺序,并且存在多个RESOURCEMANAGER主机组件(启用了YARN HA)
4、COMMAND
Ambari目前支持的命令是
- INSTALL
- UNINSTALL
- START
- RESTART
- STOP
- EXECUTE
- ABORT
- UPGRADE
- SERVICE_CHECK
- CUSTOM_COMMAND
- ACTIONEXECUTE
举例:
“HIVE_METASTORE-START”: [“MYSQL_SERVER-START”, “NAMENODE-START”] 在启动Hive Metastore之前启动MySQL和NameNode组件
“MAPREDUCE_SERVICE_CHECK-SERVICE_CHECK”: [“NODEMANAGER-START”, “RESOURCEMANAGER-START”], MapReduce服务检查需要ResourceManager和NodeManagers启动
“ZOOKEEPER_SERVER-STOP” : [“HBASE_MASTER-STOP”, “HBASE_REGIONSERVER-STOP”, “METRICS_COLLECTOR-STOP”], 在停止ZooKeeper服务器之前,请确保已停止HBase Masters,HBase RegionServers和AMS Metrics Collector。
“ELASTICSEARCH_SERVICE-START”: [“METRICS_COLLECTOR-START”, “METRICS_MONITOR-START”, “METRICS_GRAFANA-START”] 当启动metrics和ES组件时,metrics组件启动在前,ES组件在后
“ELASTICSEARCH_SERVICE_CHECK-SERVICE_CHECK”: [“ELASTICSEARCH_SERVICE-START”] ES check操作在ES start操作之后
“<DEPENDENT_COMPONENT_1>-”: [“<DEPENDS_ON_COMPONENT_1>-“, “<DEPENDS_ON_COMPONENT_1>-”] 组件名-命令 “<DEPENDENT_COMPONENT>-”: [“<服务名称>_SERVICE_CHECK-SERVICE_CHECK” ] 这里要注意,服务检查的命令为:<服务名称>_SERVICE_CHECK-SERVICE_CHECK
5、实例
{
"general_deps" : {
"_comment" : "dependencies for elasticsearch",
"ELASTICSEARCH_SERVICE-START": ["METRICS_COLLECTOR-START", "METRICS_MONITOR-START", "METRICS_GRAFANA-START"],
"ELASTICSEARCH_SERVICE-RESTART": ["METRICS_COLLECTOR-START", "METRICS_MONITOR-START", "METRICS_GRAFANA-START"],
"ELASTICSEARCH_SERVICE_CHECK-SERVICE_CHECK": ["ELASTICSEARCH_SERVICE-START"]
}
}
说明:在执行key命令之前,请先确保value项都被执行。
在执行ELASTICSEARCH_SERVICE启动之前,启动METRICS_COLLECTOR,METRICS_MONITOR,METRICS_GRAFANA
在执行ELASTICSEARCH_SERVICE重启之前,启动METRICS_COLLECTOR,METRICS_MONITOR,METRICS_GRAFANA
在执行ELASTICSEARCH_SERVICE检查操作在ELASTICSEARCH_SERVICE开始操作之后。
参考资料
五、Ambari服务配置以及Alert详解
1.Ambari 告警的基础概念
Ambari 为了帮助用户鉴别以及定位集群的问题,实现了告警(Alert)机制。在 Ambari 中预定了很多的告警,这些告警被用于监测集群的各个模块以及机器的状态。
对于告警来说,主要有两个概念,一个是 Alert Definition,一个是 Alert Instance。
(1)Alert Definition: 告警的定义,Server使用Alert Definition来将alert分配到合适的Ambari Agent中并创建Alert instance。在Alert Definition中会定义alert的检测时间间隔(interval)、类型(type)、以及阈值(threshold)等。
(2)Alert Instance:Ambari 会读取alert definition,然后创建对应的实例(instance)去定期执行这个告警。
终端用户可以在 WEB 中 Alert 的页面,浏览以及组织管理这些告警。如果告警名称太多,用户可以用过滤器筛选想要查找的告警。其实这些 WEB 中的显示,都是 Alert Definition。用户可以点击具体的 Alert name 去查看或者修改 Alert 属性(例如 interval 和阈值)。在详细的告警页面里,可以看到该告警所有的 instance。每个 instance 都会严格的报告该 instance 的检查结果。Alert 的检查结果会以五种级别呈现,分别是 OK、WARNING,CRITICAL、UNKNOW 和 NONE。其中最常见的是前三种。
1.1.Ambari 中 Alert 的类型
Ambari 中的 Alert 分为 5 种类型,分为 WEB、Port、Metric、Aggregate 和 Script。具体的区别见下面的表格。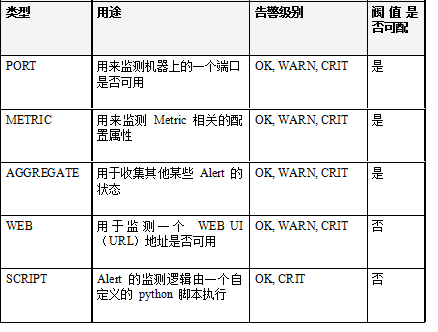
每种类型的alert都具有如下公共属性:
a.id
b.name
c.label
d.cluster_name
e.service_name
f.component_name
g.source
除了一些公共属性外,每种类型的alert还会有一些特殊的属性,下面主要将alert的核心属性:Source及每种类型的alert的source属性应该如何配置。
1.1.1.Script
Script类型的alert的将所有的功能都有其指定的python脚本来说明。Script类型的alert,除了公共属性外,只需要在source属性中指定其python脚本路径。
"source" : {
"path" : "HDFS/2.1.0.2.0/package/alerts/alert_ha_namenode_health.py",
"type" : "SCRIPT" }
1.1.2.Port
返回值通过web请求的响应时间确定,不检查response的返回码。
"source" : {
"default_port" : 2181, #当uri中不包含port时,使用该值
"reporting" : {
"ok" : {#状态码必须小写
"text" : "TCP OK - {0:.3f}s response on port {1}"
},
"warning" : { #text:指定返回显示的文本
"text" : "TCP OK - {0:.3f}s response on port {1}",
"value" : 1.5#指定waring_timeout,如果大于30,则使用默认值
},
"critical" : {
"text" : "Connection failed: {0} to {1}:{2}",
"value" : 5.0
}
},
"type" : "PORT",
"uri" : "{{core-site/ha.zookeeper.quorum}}", #url必须为{{foo-bar/baz}}的形式,可为常量或是变量,如果变量值不存在,则agent会使用当前localhost代替
}
}
1.1.3.Web
Web 和port功能相似,区别是Web不仅检测TCP连接性,还检查HTTP响应状态码。
"source" : {
"reporting" : {
"ok" : {
"text" : "HTTP {0} response in {2:.3f} seconds"
},
"warning" : {
"text" : "HTTP {0} response in {2:.3f} seconds"
},
"critical" : {
"text" : "Connection failed to {1}: {3}"
}
},
"type" : "WEB",
"uri" : {
"http" : "{{hdfs-site/dfs.namenode.http-address}}",
"https" : "{{hdfs-site/dfs.namenode.https-address}}",
"https_property" : "{{hdfs-site/dfs.http.policy}}",
"https_property_value" : "HTTPS_ONLY",
"kerberos_keytab" : "{{hdfs-site/dfs.web.authentication.kerberos.keytab}}",
"kerberos_principal" : "{{hdfs-site/dfs.web.authentication.kerberos.principal}}",
"default_port" : 0.0,
"high_availability" : {
"nameservice" : "{{hdfs-site/dfs.nameservices}}",
"alias_key" : "{{hdfs-site/dfs.ha.namenodes.{{ha-nameservice}}}}",
"http_pattern" : "{{hdfs-site/dfs.namenode.http-address.{{ha-nameservice}}.{{alias}}}}",
"https_pattern" : "{{hdfs-site/dfs.namenode.https-address.{{ha-nameservice}}.{{alias}}}}"
}
}
}
1.2.Alert 相关的Rest API
1.2.1.Create
POST api/v1/clusters/<cluster>/alert_definitions “ Alert defintion data in json format “
1.2.2.Update
更新时,不需要传入所有的属性,只需要传入需要修改的属性,其他属性使用之前的值。
PUT api/v1/clusters/<cluster>/alert_definitions/<definition-id>
{
"AlertDefinition" : {
"interval" : 10,
"uri" : "{{yarn-site/yarn.resourcemanager.address.foo}}"
}
}
}
只更新Alert(具体Alert由Alert id指定)的uri和interval值
1.2.3.Delete
DELETE api/v1/clusters/<cluster>/alert_definitions/<definition-id>
1.2.4.Query
查询时也可传入参数,限定某些alert
GET api/v1/clusters/<cluster>/alert_definitions
1.2.5.Alert立即执行
PUT http://<server>/api/v1/clusters/<cluster>/alert_definitions/<definition-id>?run_now=true
1.3.告警通知
Ambari中的Notification是用来将集群告警信息发布出去。通知模版的内容是和notification类型强耦合的。Email和SNMP 都可以通过模版配置notification内容。
下面主要讲述如何进行自定义notification模版。自定义notification只能通过修改 ambari.properties配置文件,不提供Rest 或是其他方式进行修改。具体步骤:
① 编辑/etc/ambari-server/conf/ambari.properties文件,增加自定义的notification条目,例如:alerts.template.file=/foo/var/alert-templates-custom.xml
实际ambari在启动时,如果没有找到对应的自定义配置文件,则还是使用默认的(在ambari的jar包中)。
② 保存文件,然后重启ambari server.
1.3.1. Alert notification 模版XML结构
<alert-templates>
<alert-template type="EMAIL">
<subject>
Subject Content
</subject>
<body>
Body Content
</body>
</alert-template>
<alert-template type="SNMP">
<subject>
Subject Content
</subject>
<body>
Body Content
</body>
</alert-template>
</alert-templates>
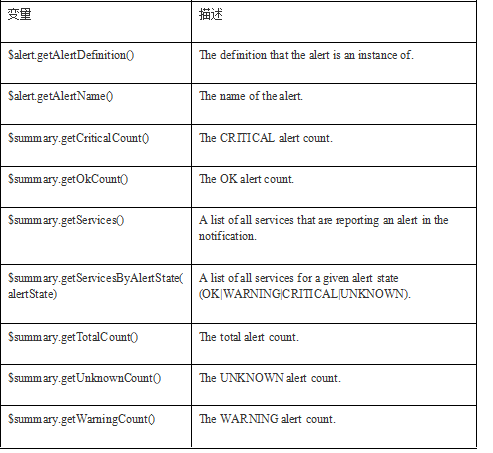
在XML模版中,可以使用模版变量。部分模版变量如下表所示。(详细完整的模版变量见:https://cwiki.apache.org//confluence/display/AMBARI/Customizing+the+Alert+Template)
1.3.2.告警通知示例
① 下载alert-templates.xml文件,作为模版(地址:https://github.com/apache/ambari/blob/trunk/ambari-server/src/main/resources/alert-templates.xml)
② 将模版保存到某个目录,例如: /var/lib/ambari-server/resources/alert-templates-custom.xml .
③ 编辑模版文件中的标签的subject域,改成:
<subject>
<![CDATA[Petstore Ambari has $summary.getTotalCount() alerts!]]>
</subject>
④ 保存文件
⑤ 编辑/etc/ambari-server/conf/ambari.properties文件,增加一个条目,指向刚才编辑的temple文件
alerts.template.file=/var/lib/ambari-server/resources/alert-templates-custom.xml
⑥ 保存文件,重启Ambari Server
2.Ambari Agent对Alert的处理
2.1.Ambari Agent获取Alert definition
Ambar agent获取Alert definition有两个方式:1)在向server注册时,注册成功时,会调用AlertSchedulerHandler进行Alert definitions更新;
Controller.py
def registerWithServer(self):
................
# always update alert definitions on registration
self.alert_scheduler_handler.update_definitions(ret)
.............
2)在收到Server的HeartBeat响应时,server可能会发送alertDefinitionCommands指令,则Agent需要处理该指令;
Controller.py
def heartbeatWithServer(self):
................
if 'alertDefinitionCommands' in response_keys:
logger.log(logging_level, "Updating alert definitions")
self.alert_scheduler_handler.update_definitions(response)
..................
.............
2.2.执行Alert
Alert任务的执行触发条件分为两种:
1)在Server的heartbeat响应中收到了alertExecutionCommands命令(如通过rest api发送了立刻执行的请求),在agent中则会立刻执行该alert;
Controller.py
def heartbeatWithServer(self):
................
if 'alertExecutionCommands' in response_keys:
logger.log(logging_level, "Executing alert commands")
self.alert_scheduler_handler.execute_alert(response['alertExecutionCommands'])
..................
.............
2)Alert定时到了。Alert在Agent中作为间隔定时作业进行调度。关于该部分下面几节会进行详细说明。
2.3.Ambari Agent上报alert信息
Agent会在heartbeat请求中加上alert信息
Heartbeat.py
def build(self, id='-1', add_state=False, componentsMapped=False):
................
if self.collector is not None:
heartbeat['alerts'] = self.collector.alerts()
..................
下面主要对Alert涉及的核心类进行详细分析,包括AlertSchedulerHandler,HeartBeat,APScheduler.Scheduler,Job,AlertCollector。
2.4.AlertSchedulerHandler.py
AlertSchedulerHandler属于Alert控制器,作用包括:
① 为controller提供接口,更新本机alert defintion
② 为controller提供接口,立刻执行Alert
③ 加载本机的Alert definition
④ 管理、启动Alert调度器,并负责在更新Alert definition时,对Alert 调度器中的任务进行管理(如删除任务、添加新任务)。
2.4.1.AlertSchedulerHandler启动流程
当Controller线程在初始化时,就会创建AlertSchedulerHandler对象,然后调用AlertSchedulerHandler的start方法。首先从start方法开始看看该类的处理过程。
Start方法处理过程:
① 如果没有创建调度器,则直接返回(该调度器会在AlertSchedulerHandler初始化函数中进行创建);
② 判定调度器的运行状态;如果调度器已经运行了,则停止注销该调度器,重新创建初始化调度器;
③ 调用__load_defintions函数,解析本机上的defintions.json文件(文件目录:/var/lib/ambari-agent/cache/alerts/defintions.json),找到其中定义的所有的Alert定义;
④ 调用schedule_defintion函数,将Alert加入到调度器中;
调用调度器的start方法,启动Alert调度器。
过程的流程图如下所示: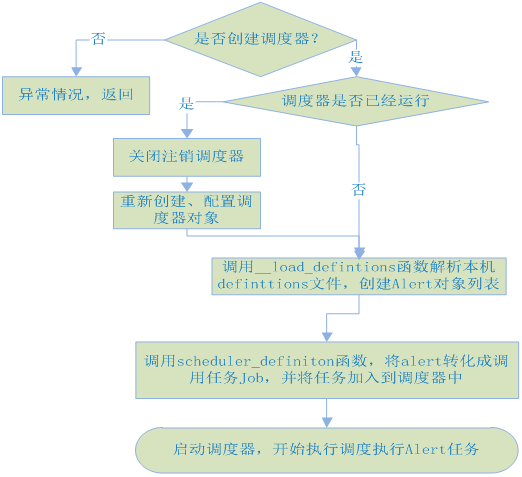
__load_defintions函数解析加载Alert过程如下所示: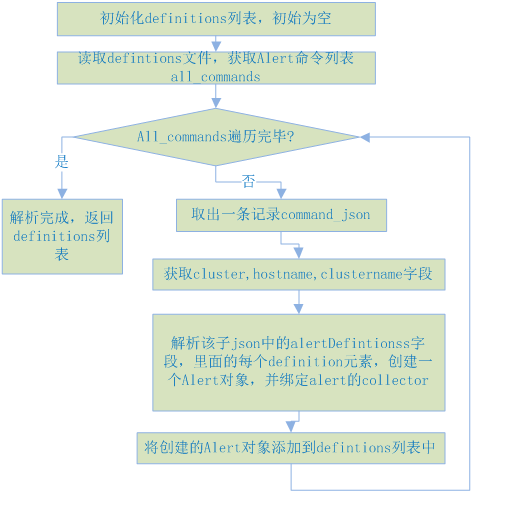
在根据json元素创建Alert对象时,会根据json中的type,source创建不同的Alert对象,包括MetricAlert,AmsAlert,PortAlert,ScriptAlert,WebAlert,RecoveryAlert。不同的Alert对象的类继承关系如下图所示: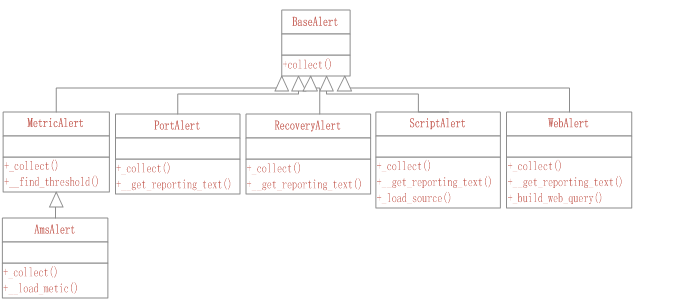
BaseAlert的collect函数为Alert的具体执行逻辑,在BaseAlert函数的collect函数中会调用具体子类的_collect函数。子类必须实现_collect函数,实现特定类型的Alert信息收集工作。
2.4.2.AlertSchedulerHandler更新Alert definition
AlertSchedulerHandler调用update_definitioons函数更新本机alert definiton,过程如下图所示: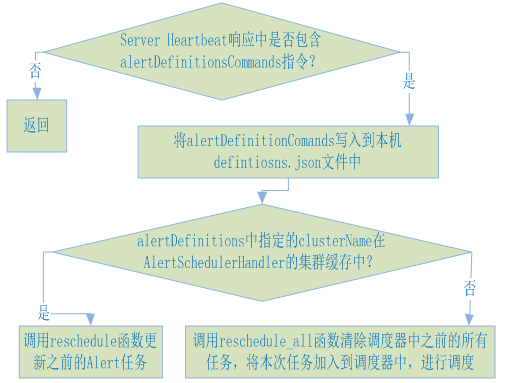
关于为什么需要判定:alertDefinitions中指定的clusterName在AlertSchedulerHandler的集群名列表中?如果alertDefinitions中指定的clusterName在AlertSchedulerHandler的集群列表中(该列表保存上次从definition.json中解析出的alert的clustername),则表示此处是更新某些Alert defintion,而不需要将之前存在与alert 调度器中的alert任务清理掉。如果不在的化,则说明之前从definiton.json中加载的alert defintion完全不同,则需要将alert 调度器中的alert任务清理掉,重新生成任务,加入到调度器中。
reschedule和reschedule_all函数的差别也就在于是否需要将之前存在与alert 调度器中的alert任务清理掉。
2.4.3.AlertSchedulerHandler立刻执行Alert definition
当Controller直接调用AlertSchedulerHandler的execute_alert函数时,AlertSchedulerHandler会立马执行该Alert Defintion任务,但是任务不会加入到调度器中,即任务之后执行一次。该接口主要用于测试目的(当任务的运行周期比较长,则需要等待很长时间才会运行)。
execute_alert函数逻辑比较简单,执行步骤如下:
① 解析heartbeat中的execution_commands数据;
② 对于execution_commands中的每条alert defintion,创建相应的Alert对象,绑定alert信息collector,然后直接执行Alert的collect方法,执行Alert。
注意,直接走execute_alert函数的化,execution_commands数据是不刷新到本机definitions.json文件中的
2.5.Alert调度器
2.5.1.Python APScheduler
APScheduler:强大的任务调度工具,可以完成定时任务,周期任务等,它是跨平台的,用于取代Linux下的cron daemon或者Windows下的task scheduler。
特点:
(1)内置三种调度调度系统:Cron风格、间隔性执行、仅在某个时间执行一次
(2)作业存储的backends支持:Memory、SQLAlchemy (any RDBMS supported by SQLAlchemy works)、MongoDB、Redis、RethinkDB、ZooKeeper
APScheduler中的基本组件:
① triggers: 描述一个任务何时被触发,有按日期、按时间间隔、按cronjob描述式三种触发方式
② job stores: 任务持久化仓库,默认保存任务在内存中,也可将任务保存都各种数据库中,任务中的数据序列化后保存到持久化数据库,从数据库加载后又反序列化。
③ executors: 执行任务模块,当任务完成时executors通知schedulers,schedulers收到后会发出一个适当的事件
④ schedulers: 任务调度器,控制器角色,通过它配置job stores和executors,添加、修改和删除任务。
运行逻辑:scheduler的主循环(main_loop),其实就是反复检查是不是有到时需要执行的任务,完成一次检查的函数是_process_jobs, 这个函数做这么几件事:
① 询问自己的每一个jobstore,有没有到期需要执行的任务(jobstore.get_due_jobs())
② 如果有,计算这些job中每个job需要运行的时间点(run_times = job._get_run_times(now))如果run_times有多个,这种情况我们上面讨论过,有coalesce检查。提交给executor排期运行(executor.submit_job(job, run_times))
③ 那么在这个_process_jobs的逻辑,什么时候调用合适呢?如果不间断地调用,而实际上没有要执行的job,是一种浪费。每次掉用_process_jobs后,其实可以预先判断一下,下一次要执行的job(离现在最近的)还要多长时间,作为返回值告诉main_loop, 这时主循环就可以去睡一觉,等大约这么长时间后再唤醒,执行下一次_process_jobs。这里唤醒的机制就会有IO模型的区别了。
根据Scheduler采用的IO模型,Scheduler具体实现有多种。内置scheduler有:
① BlockingScheduler: scheduler在当前进程的主线程中运行,所以调用start函数会阻塞当前线程,不能立即返回。
② BackgroundScheduler: 放到后台线程中运行,所以调用start后主线程不会阻塞
③ AsyncIOScheduler: 使用asyncio模块
④ GeventScheduler: 使用gevent作为IO模型,和GeventExecutor配合使用
⑤ TornadoScheduler: 配合TwistedExecutor,用reactor.callLater完成定时唤醒
⑥ TwistedScheduler: 使用tornado的IO模型,用ioloop.add_timeout完成定时唤醒
⑦ QtScheduler: 使用QTimer完成定时唤醒
2.5.2.Alert Scheduler
Alert调度器实现在apscheduler/scheduler中。Scheduler实现策略和Python的APscheduler类似。在Agent中的Scheduler采用的IO模型为Event模型,在调用_process_jobs处理任务时,会计算下次wakeup时间,执行完_process_jobs任务后,通过Event模型,睡眠一段时间,然后再次调用_process_jobs任务。
需要注意的是Scheduler在提交Alert任务时,直接将任务提交到线程池,但是任务绑定的运行函数为Scheduler._run_job函数。该函数负责调用Alert任务的collect函数,获取处理返回结果、结果做日志处理,并发出相关事件(Alert任务执行失败事件、任务执行成功事件等),通知Scheduler事件的监听者(默认情况下,Scheduler并没有注册任何事件监听者)。
2.6.AlertCollector
AlertCollector位于alerts/collector.py中,负责收集所有的Alert任务执行结果。
Cotroller线程会定时的向server发送Heartbeat信息。Heartbeat信息调用Heartbeat类的build方法进行构建,在构建heartbeat信息时,会调用collector的alerts()函数收集在此heartbeat期间执行的Alert任务的结果,然后将构建好的heartbeat信息发送给Server。
AlertCollector保存了一个map(key=集群,value={alert名字,执行结果})。当Alert执行完后,会将执行结果发送到绑定的AlertCollector中,放入到AlertCollector的map中。alerts函数的执行过程下图所示: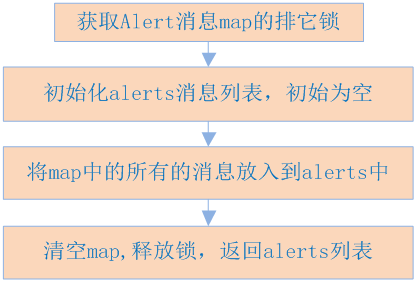
2.7.Ambari agent对Alert的处理总结
Ambari Agent中和Alert相关的各个组件之间的关系如下图所示: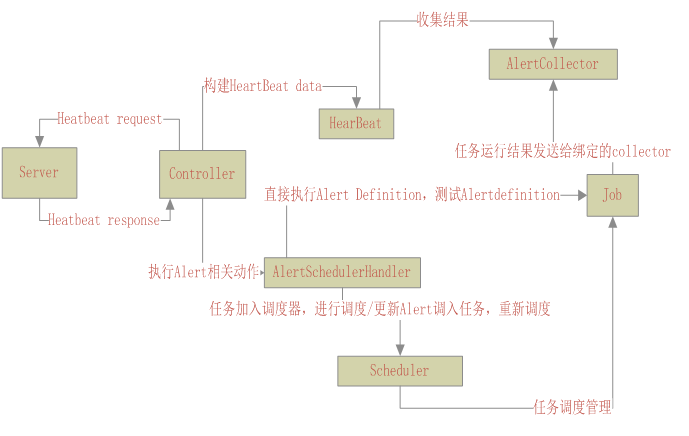
默认情况下,只有一个AlertCollector,所有的Alert任务都绑定同一个AlertCollector,当Job完成后,将结果发送给AlertCollector。当Controller发送Heartbeat消息时,调用Heartbeat类的build方法。Heartbeat类在构造hearbeat消息数据时,会调用AlertCollector的alert的方法,将所有的alert执行结果放入到heartbeat消息体中。
2.8.BaseAlert的collect函数执行过程
如前所述,Alert注册的执行体为类的collect函数,该函数在父类BaseAlert中实现。BaseAlert的collect函数的处理过程如下图所示: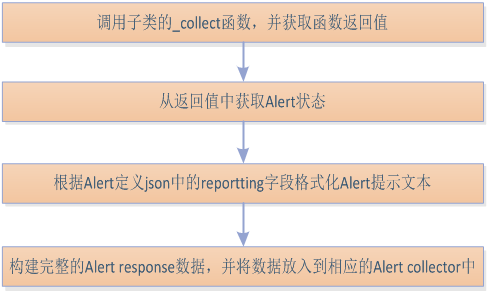
说明:在BaseAlert中实现的collect函数是一个基础执行框架,包括通用的异常处理和结果处理。在执行过程中,会调用子类的_collect函数,执行特定alert的业务逻辑。具体的Alert子类(如WebAlert,PortAlert)将自己的业务逻辑全部在_collect函数中定义。因此,下面讲述具体Alert执行过程时,就是描述该Alert的_collect的执行过程。
2.9.Agent执行WebAlert过程
WebAlert的_collect函数主要处理过程如下图所示:
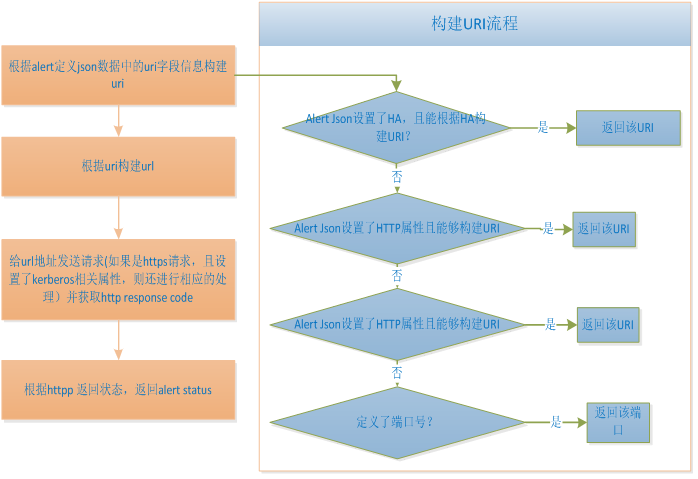
比如HDFS中定义的namenode_webui Alert,默认配置下,在hdfs-site中并没有配置dfs.internal.nameservices,也无法解析{{hdfs-site/dfs.ha.namenodes.{{ha-nameservice}}}},则无法根据HA配置中获取到URI。但是在hdfs-site中配置了dfs.namenode.http-address,其值为node1:50070,则最后构建的URI为:node1:50070,最后构造的URL为http://node1:50070
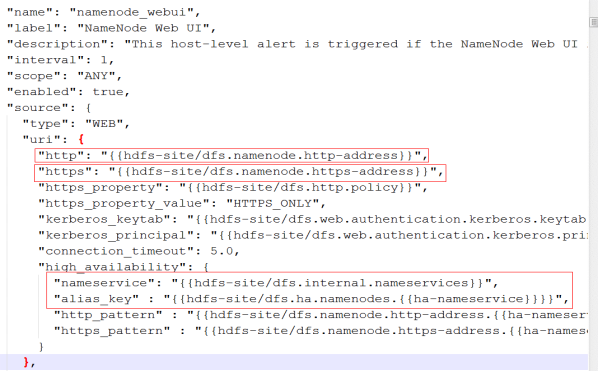
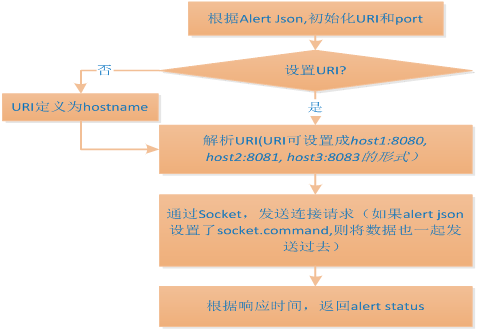
2.10.Agent执行Port Alert过程
PortAlert的_collect函数主要处理过程如下图所示:
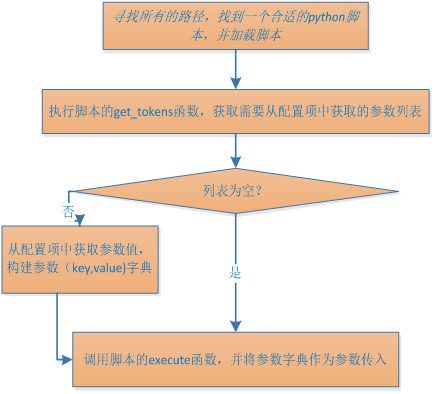
2.11.Agent执行Script Alert过程
3.Ambari Alert实践
(1)为Kibana增加一个port类型的alert,并通过rest api安装。Agent将本节点的alert定义从server端拉下来(通过heartbeat),保存到/var/lib/ambari-agent/cache/alerts/definition.json。
curl -u admin:admin -i -H 'X-Requested-By:ambari' -X POST http://node1:8080/api/v1/clusters/mycluster/alert_definitions -d '{"AlertDefinition" : {
"service_name" : "KIBANA",
"component_name" : "KibanaNode",
"enabled" : true,
"interval" : 1,
"label" : "Kibana Port",
"name" : "Kibana Port",
"scope" : "ANY",
"source": {
"type": "PORT",
"uri": "{{kibana-site/server.port}}",
"default_port": 5601,
"reporting": {
"ok": {
"text": "TCP OK - {0:.3f}s response on port {1}"
},
"warning": {
"text": "TCP OK - {0:.3f}s response on port {1}",
"value": 2.5
},
"critical": {
"text": "Connection failed: {0} to {1}:{2}",
"value": 10.0
}
} } }}'
(2)立即运行该alert,测试该alert是否能正确执行
curl -u admin:admin -i -H 'X-Requested-By:ambari' -X PUT http://node1:8080/api/v1/clusters/mycluster/alert_definitions/1002?run_now=true
(3)删除该alert(在该例子中, url后面的后缀数字为alert的id号)
curl -u admin:admin -i -H 'X-Requested-By:ambari' -X DELETE http://node1:8080/api/v1/clusters/mycluster/alert_definitions/1001
Alert的id号可通过ambari web端进行查看,如查看HDFS的名为Host Disk Usage的alert的id号的方式:在web中点击查看该alert,url中的后缀即为该alert的id号。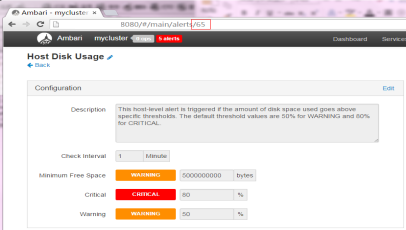
如何在 WEB 中管理修改 Alert
当用户登录到 Ambari WEB 中,便可以直接跳转到 Alert 的页面。然后可以操作过滤器筛选 Alert 信息。也可以直接点击最右侧的 Enable 关闭一个开启状态的 Alert(也可以点击 Disable 直接开启一个关闭的 Alert)。
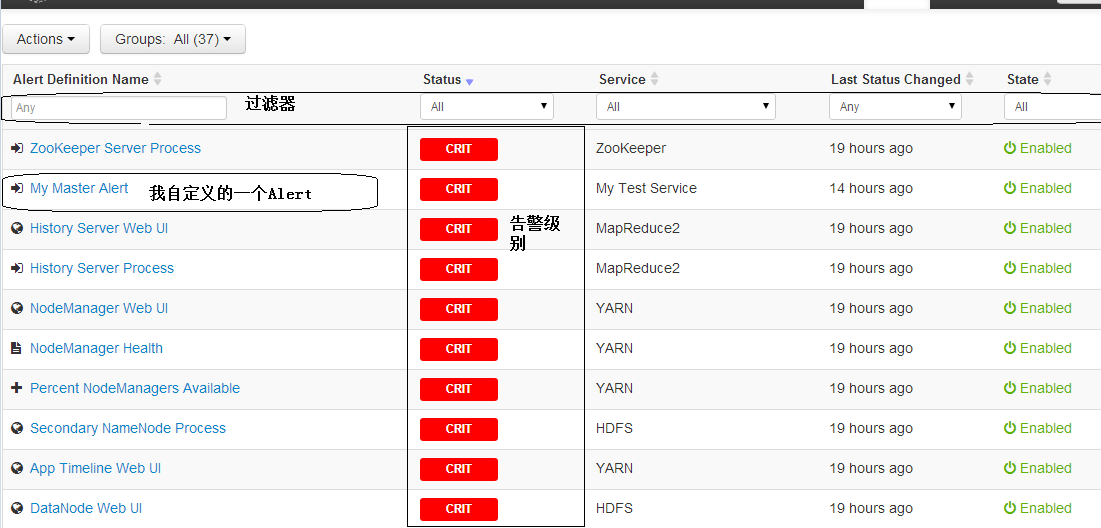
参照:https://www.cnblogs.com/tiandlsd001/p/11864255.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/13951.html

