
本文将介绍使用Pipeline对数据进行特征转换后运行决策树分类算法的小例子。
Pipeline简介
Pipeline一般翻译为流水线,简单讲就是将多种算法组合成一个流水线或工作流程。
结构
在结构上,一个Pipline会包含一个或多个Stage,每一个Stage都会完成一个任务,如数据处理、数据转化、模型训练、预测数据等。
使用时,需将每个Stage定义好,然后拼成一个Array,传给Pipeline的setStages方法就好,如:
val pipeline = new Pipeline().setStages(Array(tokenizer, hashingTF, lr))- 其中
tokenizer、hashingTF和lr就是三个Stage。
组件
Stage有两种,分别为Transformer和Estimator。
Transformer
Transformer可以翻译为转换器,主要是通过调用 transform() 方法,在原始数据上增加一列或多列来将一个DataFrame转成另一个DataFrame。
转换器主要有以下两种用法:
1. 特征变化:一个特征转换器输入一个DataFrame,读取其中一个或多个文本列,将其映射为新的特征向量列。输出一个新的带有特征向量列的DataFrame。
2. 学习模型:一个学习模型转换器输入一个DataFrame,读取其中包括特征向量的列,预测每一个特征向量的标签。输出一个新的带有预测标签列的DataFrame。
Estimator
Estimator可以翻译为估计器,主要是通过调用 fit() 方法,训练特征数据从而得到一个模型,这个模型就是一个Transformer。
一个小例子:(注:以下为伪代码)
val trainingData = Transformer.transform(data) //转换器的第一种用法
val model = Estimator.fit(trainingData) //训练数据 得到模型
val resultData = model.transform(testData) //转换器的第二种用法
特征转换方法简介
StringIndexer
StringIndexer(字符串-索引变换)是一个估计器,是将字符串列编码为标签索引列。索引位于[0,numLabels),按标签频率排序,频率最高的排0,依次类推,因此最常见的标签获取索引是0。
VectorIndexer
VectorIndexer(向量-索引变换)是一种估计器,能够提高决策树或随机森林等ML方法的分类效果,是对数据集特征向量中的类别(离散值)特征进行编号。它能够自动判断哪些特征是离散值型的特征,并对他们进行编号。
IndexToString
IndexToString(索引-字符串变换)是一种转换器,与StringIndexer对应,能将指标标签映射回原始字符串标签。一个常见的用例(下文的例子就是如此)是使用StringIndexer从标签生成索引,使用这些索引训练模型,并从IndexToString的预测索引列中检索原始标签。
一、StringIndexer
(1)StringIndexer本质上是对String类型–>index( number);如果是:数值(numeric)–>index(number),实际上是对把数值先进行了类型转换( cast numeric to string and then index the string values.),也就是说无论是String,还是数值,都可以重新编号(Index);
(2)利用获得的模型转化新数据集时,可能遇到异常情况
在使用Spark MLlib协同过滤ALS API的时候发现Rating的三个参数:用户id,商品名称,商品打分,前两个都需要是Int值。那么问题来了,当你的用户id,商品名称是String类型的情况下,我们必须寻找一个方法可以将海量String映射为数字类型。好在Spark MLlib可以answer这一切。
StringIndexer 将一列字符串标签编码成一列下标标签,下标范围在[0, 标签数量),顺序是标签的出现频率。所以最经常出现的标签获得的下标就是0。如果输入列是数字的,我们会将其转换成字符串,然后将字符串改为下标。当下游管道组成部分,比如说Estimator 或Transformer 使用将字符串转换成下标的标签时,你必须将组成部分的输入列设置为这个将字符串转换成下标后的列名。很多情况下,你可以使用setInputCol设置输入列。
import org.apache.spark.ml.feature.StringIndexer;
val spark = SparkSession.builder().appName("db").master("local[*]").getOrCreate()
val df = spark.createDataFrame(
Seq((0,"a"),(1,"b"),(2,"c"),(3,"a"),(4,"a"),(5,"c"))
).toDF("id","category")
val indexer =new StringIndexer()
.setInputCol("category")
.setOutputCol("categoryIndex")
val indexed = indexer.fit(df) // 训练一个StringIndexer => StringIndexerModel
.transform(df) // 用 StringIndexerModel transfer 数据集
indexed.show()
此外,当你针对一个数据集训练了一个StringIndexer,然后使用其去transform另一个数据集的时候,针对不可见的标签StringIndexer 有两个应对策略:
针对训练集中没有出现的字符串值,spark提供了几种处理的方法:
- error,直接抛出异常
- skip,跳过该样本数据( skip the row containing the unseen label entirely跳过包含不可见标签的这一行)
- keep,使用一个新的最大索引,来表示所有未出现的值
- throw an exception (which is the default)默认是抛出异常
val df2 = spark.createDataFrame(
Seq((0,"a"),(1,"b"),(2,"c"),(3,"d"),(4,"e"),(5,"f"))
).toDF("id","category")
val indexed2 = indexer.fit(df)
.setHandleInvalid("skip") // 不匹配就跳过
.transform(df2) // 用 不匹配的stringIndexModel 来 transfer 数据集
indexed2.show()
二、IndexToString
IndexToString 和StringIndexer是对称的,它将一列下标标签映射回一列包含原始字符串的标签。常用的场合是使用StringIndexer生产下标,通过这些下标训练模型,通过IndexToString从预测出的下标列重新获得原始标签。不过,你也可以使用你自己的标签。
import org.apache.spark.ml.feature.IndexToString
val converter =new IndexToString()
.setInputCol("categoryIndex")
.setOutputCol("originalCategory")
val converted = converter.transform(indexed) // class IndexToString extends Transformer
converted.select("id","originalCategory").show() 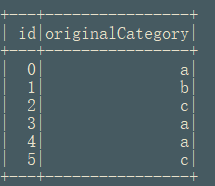
完整样例:
package xingoo.ml.features.tranformer
import org.apache.spark.ml.attribute.Attribute
import org.apache.spark.ml.feature.{IndexToString, StringIndexer}
import org.apache.spark.sql.SparkSession
object IndexToString2 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local[*]").appName("dct").getOrCreate()
spark.sparkContext.setLogLevel("WARN")
val df = spark.createDataFrame(Seq(
(0, "a"),
(1, "b"),
(2, "c"),
(3, "a"),
(4, "a"),
(5, "c")
)).toDF("id", "category")
val indexer = new StringIndexer()
.setInputCol("category")
.setOutputCol("categoryIndex")
.fit(df)
val indexed = indexer.transform(df)
println(s"Transformed string column '${indexer.getInputCol}' " +
s"to indexed column '${indexer.getOutputCol}'")
indexed.show()
val inputColSchema = indexed.schema(indexer.getOutputCol)
println(s"StringIndexer will store labels in output column metadata: " +
s"${Attribute.fromStructField(inputColSchema).toString}\n")
val converter = new IndexToString()
.setInputCol("categoryIndex")
.setOutputCol("originalCategory")
val converted = converter.transform(indexed)
println(s"Transformed indexed column '${converter.getInputCol}' back to original string " +
s"column '${converter.getOutputCol}' using labels in metadata")
converted.select("id", "categoryIndex", "originalCategory").show()
}
}得到的结果如下:
Transformed string column 'category' to indexed column 'categoryIndex'
+---+--------+-------------+
| id|category|categoryIndex|
+---+--------+-------------+
| 0| a| 0.0|
| 1| b| 2.0|
| 2| c| 1.0|
| 3| a| 0.0|
| 4| a| 0.0|
| 5| c| 1.0|
+---+--------+-------------+
StringIndexer will store labels in output column metadata: {"vals":["a","c","b"],"type":"nominal","name":"categoryIndex"}
Transformed indexed column 'categoryIndex' back to original string column 'originalCategory' using labels in metadata
+---+-------------+----------------+
| id|categoryIndex|originalCategory|
+---+-------------+----------------+
| 0| 0.0| a|
| 1| 2.0| b|
| 2| 1.0| c|
| 3| 0.0| a|
| 4| 0.0| a|
| 5| 1.0| c|
+---+-------------+----------------+VectorIndexer
主要作用:提高决策树或随机森林等ML方法的分类效果。
VectorIndexer是对数据集特征向量中的类别(离散值)特征(index categorical features categorical features )进行编号。
它能够自动判断那些特征是离散值型的特征,并对他们进行编号,具体做法是通过设置一个maxCategories,特征向量中某一个特征不重复取值个数小于maxCategories,则被重新编号为0~K(K<=maxCategories-1)。某一个特征不重复取值个数大于maxCategories,则该特征视为连续值,不会重新编号(不会发生任何改变)。
//定义输入输出列和最大类别数为5,某一个特征
//(即某一列)中多于5个取值视为连续值
VectorIndexerModel featureIndexerModel=new VectorIndexer()
.setInputCol("features")
.setMaxCategories(5)
.setOutputCol("indexedFeatures")
.fit(rawData);
//加入到Pipeline
Pipeline pipeline=new Pipeline()
.setStages(new PipelineStage[]
{labelIndexerModel,
featureIndexerModel,
dtClassifier,
converter});
pipeline.fit(rawData).transform(rawData).select("features","indexedFeatures").show(20,false); //显示如下的结果:
+-------------------------+-------------------------+
|features |indexedFeatures |
+-------------------------+-------------------------+
|(3,[0,1,2],[2.0,5.0,7.0])|(3,[0,1,2],[2.0,1.0,1.0])|
|(3,[0,1,2],[3.0,5.0,9.0])|(3,[0,1,2],[3.0,1.0,2.0])|
|(3,[0,1,2],[4.0,7.0,9.0])|(3,[0,1,2],[4.0,3.0,2.0])|
|(3,[0,1,2],[2.0,4.0,9.0])|(3,[0,1,2],[2.0,0.0,2.0])|
|(3,[0,1,2],[9.0,5.0,7.0])|(3,[0,1,2],[9.0,1.0,1.0])|
|(3,[0,1,2],[2.0,5.0,9.0])|(3,[0,1,2],[2.0,1.0,2.0])|
|(3,[0,1,2],[3.0,4.0,9.0])|(3,[0,1,2],[3.0,0.0,2.0])|
|(3,[0,1,2],[8.0,4.0,9.0])|(3,[0,1,2],[8.0,0.0,2.0])|
|(3,[0,1,2],[3.0,6.0,2.0])|(3,[0,1,2],[3.0,2.0,0.0])|
|(3,[0,1,2],[5.0,9.0,2.0])|(3,[0,1,2],[5.0,4.0,0.0])|
+-------------------------+-------------------------+
结果分析:特征向量包含3个特征,即特征0,特征1,特征2。如Row=1,对应的特征分别是2.0,5.0,7.0.被转换为2.0,1.0,1.0。
我们发现只有特征1,特征2被转换了,特征0没有被转换。这是因为特征0有6中取值(2,3,4,5,8,9),多于前面的设置setMaxCategories(5)
,因此被视为连续值了,不会被转换。
特征1中,(4,5,6,7,9)-->(0,1,2,3,4,5)
特征2中, (2,7,9)-->(0,1,2)
输出DataFrame格式说明(Row=1):
3个特征 特征0,1,2 转换前的值
|(3, [0,1,2], [2.0,5.0,7.0])
3个特征 特征1,1,2 转换后的值
|(3, [0,1,2], [2.0,1.0,1.0])|离散<->连续特征或Label相互转换
oneHotEncoder
独热编码将类别特征(离散的,已经转换为数字编号形式),映射成独热编码。这样在诸如Logistic回归这样需要连续数值值作为特征输入的分类器中也可以使用类别(离散)特征。
独热编码即 One-Hot 编码,又称一位有效编码,其方法是使用N位 状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器 位,并且在任意时候,其 中只有一位有效。
例如: 自然状态码为:000,001,010,011,100,101
独热编码为:000001,000010,000100,001000,010000,100000
可以这样理解,对于每一个特征,如果它有m个可能值,那么经过独 热编码后,就变成了m个二元特征。并且,这些特征互斥,每次只有 一个激活。因此,数据会变成稀疏的。
这样做的好处主要有:
解决了分类器不好处理属性数据的问题,在一定程度上也起到了扩充特征的作用
//onehotencoder前需要转换为string->numerical
Dataset indexedDf=new StringIndexer()
.setInputCol("category")
.setOutputCol("indexCategory")
.fit(df)
.transform(df);
//对随机分布的类别进行OneHotEncoder,转换后可以当成连续数值输入
Dataset coderDf=new OneHotEncoder()
.setInputCol("indexCategory")
.setOutputCol("ontHotCategory")//不需要fit
.transform(indexedDf);
Bucketizer
分箱(分段处理):将连续数值转换为离散类别
比如特征是年龄,是一个连续数值,需要将其转换为离散类别(未成年人、青年人、中年人、老年人),就要用到Bucketizer了。
分类的标准是自己定义的,在Spark中为split参数,定义如下:
double[] splits = {0, 18, 35,50, Double.PositiveInfinity}
将数值年龄分为四类0-18,18-35,35-50,55+四个段。
如果左右边界拿不准,就设置为,Double.NegativeInfinity, Double.PositiveInfinity,不会有错的。
double[] splits={0,18,35,55,Double.POSITIVE_INFINITY};
Dataset bucketDf=new Bucketizer()
.setInputCol("ages")
.setOutputCol("bucketCategory")
.setSplits(splits)//设置分段标准
.transform(df);//输出
+---+----+--------------+
|id |ages|bucketCategory|
+---+----+--------------+
|0.0|2.0 |0.0 |
|1.0|67.0|3.0 |
|2.0|36.0|2.0 |
|3.0|14.0|0.0 |
|4.0|5.0 |0.0 |
|5.0|98.0|3.0 |
|6.0|65.0|3.0 |
|7.0|23.0|1.0 |
|8.0|37.0|2.0 |
|9.0|76.0|3.0 |
+---+----+--------------+
QuantileDiscretizer
分位树为数离散化,和Bucketizer(分箱处理)一样也是:将连续数值特征转换为离散类别特征。实际上Class QuantileDiscretizer extends (继承自) Class(Bucketizer)。
参数1:不同的是这里不再自己定义splits(分类标准),而是定义分几箱(段)就可以了。QuantileDiscretizer自己调用函数计算分位数,并完成离散化。
-参数2: 另外一个参数是精度,如果设置为0,则计算最精确的分位数,这是一个高时间代价的操作。另外上下边界将设置为正负无穷,覆盖所有实数范围。
new QuantileDiscretizer()
.setInputCol("ages")
.setOutputCol("qdCategory")
.setNumBuckets(4)//设置分箱数
.setRelativeError(0.1)//设置precision-控制相对误差
.fit(df)
.transform(df)
.show(10,false);
//例子:
+---+----+----------+
|id |ages|qdCategory|
+---+----+----------+
|0.0|2.0 |0.0 |
|1.0|67.0|3.0 |
|2.0|36.0|2.0 |
|3.0|14.0|1.0 |
|4.0|5.0 |0.0 |
|5.0|98.0|3.0 |
|6.0|65.0|2.0 |
|7.0|23.0|1.0 |
|8.0|37.0|2.0 |
|9.0|76.0|3.0 |
决策树简介
决策树是一种树形结构,由节点和有向边组成。节点有两种类型:内部节点和叶节点,内部节点代表一个特征或属性,叶节点代表一个类。每个非叶节点代表一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出。使用决策树进行决策的过程就是从根节点开始,测试待分类项中的相应属性,按照其值选择输出分支,直到达到叶节点,将叶节点存放的类别作为决策结果。
决策树算法本质上是从训练数据集上归纳出一组分类规则,遵循局部最优原则。即每次选择分类特征时,都挑选当前条件下最优的那个特征作为划分规则。
具体原理介绍读者可自行参考机器学习类相关书籍资料。
主要参数有:
- impurity 信息增益的计算标准,默认为“gini”
- maxBins 树的最大高度,默认为5
- maxDepth 用于分裂特征的最大划分量,默认为32
运行实例
数据说明
数据为LIBSVM格式文本文件
数据格式为:标签 特征ID:特征值 特征ID:特征值……
内容如下:
[root@cu01 ML_Data]$ cat input/sample_libsvm_data.txt
0 128:51 129:159 130:253 131:159 132:50 155:48 156:238 157:252 158:252 159:252 160:237 182:54 183:227 184:253 185:252 186:239 187:233 188:252 189:57 190:6 208:10 209:60 210:224 211:252 212:253 213:252 214:202 215:84 216:252 217:253 218:122 236:163 237:252 238:252 239:252 240:253 241:252 242:252 243:96 244:189 245:253 246:167 263:51 264:238 265:253 266:253 267:190 268:114 269:253 270:228 271:47 272:79 273:255 274:168 290:48 291:238 292:252 293:252 294:179 295:12 296:75 297:121 298:21 301:253 302:243 303:50 317:38 318:165 319:253 320:233 321:208 322:84 329:253 330:252 331:165 344:7 345:178 346:252 347:240 348:71 349:19 350:28 357:253 358:252 359:195 372:57 373:252 374:252 375:63 385:253 386:252 387:195 400:198 401:253 402:190 413:255 414:253 415:196 427:76 428:246 429:252 430:112 441:253 442:252 443:148 455:85 456:252 457:230 458:25 467:7 468:135 469:253 470:186 471:12 483:85 484:252 485:223 494:7 495:131 496:252 497:225 498:71 511:85 512:252 513:145 521:48 522:165 523:252 524:173 539:86 540:253 541:225 548:114 549:238 550:253 551:162 567:85 568:252 569:249 570:146 571:48 572:29 573:85 574:178 575:225 576:253 577:223 578:167 579:56 595:85 596:252 597:252 598:252 599:229 600:215 601:252 602:252 603:252 604:196 605:130 623:28 624:199 625:252 626:252 627:253 628:252 629:252 630:233 631:145 652:25 653:128 654:252 655:253 656:252 657:141 658:37
1 159:124 160:253 161:255 162:63 186:96 187:244 188:251 189:253 190:62 214:127 215:251 216:251 217:253 218:62 241:68 242:236 243:251 244:211 245:31 246:8 268:60 269:228 270:251 271:251 272:94 296:155 297:253 298:253 299:189 323:20 324:253 325:251 326:235 327:66 350:32 351:205 352:253 353:251 354:126 378:104 379:251 380:253 381:184 382:15 405:80 406:240 407:251 408:193 409:23 432:32 433:253 434:253 435:253 436:159 460:151 461:251 462:251 463:251 464:39 487:48 488:221 489:251 490:251 491:172 515:234 516:251 517:251 518:196 519:12 543:253 544:251 545:251 546:89 570:159 571:255 572:253 573:253 574:31 597:48 598:228 599:253 600:247 601:140 602:8 625:64 626:251 627:253 628:220 653:64 654:251 655:253 656:220 681:24 682:193 683:253 684:220
……
……
……
1 130:218 131:170 132:108 157:32 158:227 159:252 160:232 185:129 186:252 187:252 188:252 212:1 213:253 214:252 215:252 216:168 240:144 241:253 242:252 243:236 244:62 268:144 269:253 270:252 271:215 296:144 297:253 298:252 299:112 323:21 324:206 325:253 326:252 327:71 351:99 352:253 353:255 354:119 378:63 379:242 380:252 381:253 382:35 406:94 407:252 408:252 409:154 410:10 433:145 434:237 435:252 436:252 461:255 462:253 463:253 464:108 487:11 488:155 489:253 490:252 491:179 492:15 514:11 515:150 516:252 517:253 518:200 519:20 542:73 543:252 544:252 545:253 546:97 569:47 570:233 571:253 572:253 596:1 597:149 598:252 599:252 600:252 624:1 625:252 626:252 627:246 628:132 652:1 653:169 654:252 655:132
1 130:116 131:255 132:123 157:29 158:213 159:253 160:122 185:189 186:253 187:253 188:122 213:189 214:253 215:253 216:122 241:189 242:253 243:253 244:122 267:2 268:114 269:243 270:253 271:186 272:19 295:100 296:253 297:253 298:253 299:48 323:172 324:253 325:253 326:253 327:48 351:172 352:253 353:253 354:182 355:19 378:133 379:251 380:253 381:175 382:4 405:107 406:251 407:253 408:253 409:65 432:26 433:194 434:253 435:253 436:214 437:40 459:105 460:205 461:253 462:253 463:125 464:40 487:139 488:253 489:253 490:253 491:81 514:41 515:231 516:253 517:253 518:159 519:16 541:65 542:155 543:253 544:253 545:172 546:4 569:124 570:253 571:253 572:253 573:98 597:124 598:253 599:253 600:214 601:41 624:22 625:207 626:253 627:253 628:139 653:124 654:253 655:162 656:9代码及相关说明
import org.apache.spark.ml.Pipeline
import org.apache.spark.ml.classification.DecisionTreeClassificationModel
import org.apache.spark.ml.classification.DecisionTreeClassifier
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
import org.apache.spark.ml.feature.{IndexToString, StringIndexer, VectorIndexer}
import org.apache.spark.sql.SparkSession
object DecisionTreeClassificationExample {
def main(args: Array[String]): Unit = {
// 构建Spark对象
val spark = SparkSession.
builder.
appName("DecisionTreeClassificationExample").
getOrCreate()
// 读取数据集
// 读取LIBSVM格式文本文件并保存为DataFrame.
val data = spark.read.format("libsvm").load("file:///home/xuqm/ML_Data/input/sample_libsvm_data.txt")
// 用StringIndexer转换标签列
val labelIndexer = new StringIndexer().
setInputCol("label").
setOutputCol("indexedLabel").
fit(data)
// 用VectorIndexer转换特征列
// 设置最大分类特征数为4
val featureIndexer = new VectorIndexer().
setInputCol("features").
setOutputCol("indexedFeatures").
setMaxCategories(4).
fit(data)
// 拆分成训练集和测试集(70%训练集,30%测试集).
val Array(trainingData, testData) = data.randomSplit(Array(0.7, 0.3))
// 指定执行决策树分类算法的转换器(使用默认参数)
val dt = new DecisionTreeClassifier().
setLabelCol("indexedLabel").
setFeaturesCol("indexedFeatures")
// 用IndexToString把预测的索引列转换成原始标签列
val labelConverter = new IndexToString().
setInputCol("prediction").
setOutputCol("predictedLabel").
setLabels(labelIndexer.labels)
// 组装成Pipeline.
val pipeline = new Pipeline().
setStages(Array(labelIndexer, featureIndexer, dt, labelConverter))
// 训练模型
val model = pipeline.fit(trainingData)
// 用训练好的模型预测测试集的结果
val predictions = model.transform(testData)
// 输出前10条数据
predictions.select("predictedLabel", "label", "features").show(10)
// 计算精度和误差
val evaluator = new MulticlassClassificationEvaluator().
setLabelCol("indexedLabel").
setPredictionCol("prediction").
setMetricName("accuracy")
val accuracy = evaluator.evaluate(predictions)
// 输出误差
println("Test Error = " + (1.0 - accuracy))
// 从PipelineModel中取出决策树模型treeModel
val treeModel = model.stages(2).asInstanceOf[DecisionTreeClassificationModel]
// 输出treeModel的决策过程
println("Learned classification tree model:\n" + treeModel.toDebugString)
}
}结果展示
// 输出前10条数据
predictions.select("predictedLabel", "label", "features").show(10)
+--------------+-----+--------------------+
|predictedLabel|label| features|
+--------------+-----+--------------------+
| 0.0| 0.0|(692,[98,99,100,1...|
| 0.0| 0.0|(692,[100,101,102...|
| 0.0| 0.0|(692,[124,125,126...|
| 0.0| 0.0|(692,[125,126,127...|
| 0.0| 0.0|(692,[126,127,128...|
| 0.0| 0.0|(692,[150,151,152...|
| 0.0| 0.0|(692,[152,153,154...|
| 0.0| 0.0|(692,[153,154,155...|
| 1.0| 0.0|(692,[154,155,156...|
| 1.0| 0.0|(692,[154,155,156...|
+--------------+-----+--------------------+
only showing top 10 rows
// 输出误差
Test Error = 0.07999999999999996
// 输出treeModel的决策过程
Learned classification tree model:
DecisionTreeClassificationModel (uid=dtc_bcf718ed2979) of depth 1 with 3 nodes
If (feature 406 <= 0.0)
Predict: 1.0
Else (feature 406 > 0.0)
Predict: 0.0
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/13961.html

