
前言
当索引一个文档的时候,文档会被存储到一个主分片中。那么,elasticsearch如何知道一个文档应该存放到哪个分片中呢?
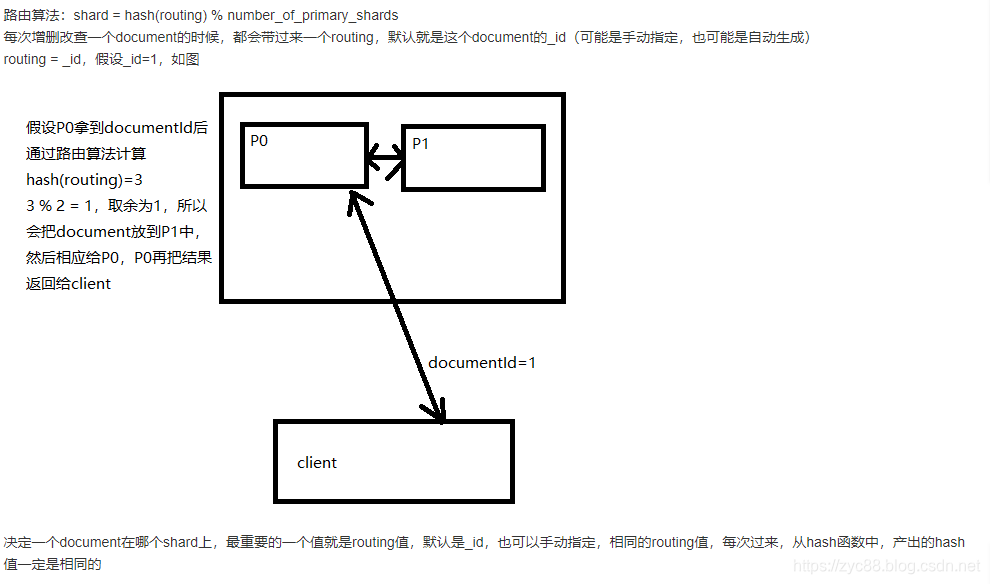
首先这肯定不是随机的,否则在检索文档时就不知道该从哪去寻找它了。实际上这个过程是根据下面公式决定的:
shard = hash(routing) % number_of_primary_shardsrouting是一个可变值,默认是文档的_id,也可以是自定义的值。hash函数将routing值哈希后生成一个数字,然后这个数字再除以number_of_primary_shards(主分片的数量)得到余数,这个分布在0到number_of_primary_shards减一(计数从0开始,比如5个主分片,那么范围就是0~4)之间的余数,就是文档存放的分片位置。
比如一篇文档的id为123,那么它就应该存在:
>>> hash(123) % 5
3这篇文档就存在P3主分片上。

这也就解释了为什么在创建索引时,主分片的数量一经定义就不能改变,因为如果数量变化了,那么之前所有的路由(routing)值都会无效,文档就再也找不到了。
一般的,elasticsearch的默认路由算法都会根据文档的id值作为依据将其哈希到相应的主分片上,该算法基本上会将所有的文档平均分布在所有的主分片上,而不会产生某个分片数据过大而导致集群不平衡的情况。
那么我们在向一个有100个主分片的索引发送查询某篇文档的请求时,该请求发送到集群,集群干了什么呢?
- 这个请求会被集群交给主节点。
- 主节点接收这个请求后,将这个查询请求广播到这个索引的每个分片上(包含主、复制分片)。
- 每个分片执行这个搜索请求,并将结果返回。
- 结果在主节点上合并、排序后返回给用户。
这里面就有些问题了。因为在存储文档时,通过hash算法将文档平均分布在各分片上,这就导致了elasticsearch也不确定文档的位置,所以它必须将这个请求广播到所有的分片上去执行。
为了避免不必要的查询,我们使用自定义的路由模式,这样可以使我们的查询更具目的性。比如之前的查询是这样的:
请求来了,你们(索引下的所有分片)都要检查一下自己是否有符合条件的文档当能自定义路由后的查询变成了:
请求来了,分片3、5你俩把文档给我返回
数据写入相关参数选择配置:
(1) replication
复制默认的值是sync。这将导致主分片得到复制分片的成功响应后才返回。
如果你设置replication为async,请求在主分片上被执行后就会返回给客户端。它依旧会转发请求给复制节点,但你将不知道复制节点成功与否。
上面的这个选项不建议使用。默认的sync复制允许Elasticsearch强制反馈传输。async复制可能会因为在不等待其它分片就绪的情况下发送过多的请求而使Elasticsearch过载。
(2) consistency
默认主分片在尝试写入时需要规定数量(quorum)或过半的分片(可以是主节点或复制节点)可用。这是防止数据被写入到错的网络分区。规定的数量计算公式如下:
int( (primary + number_of_replicas) / 2 ) + 1
consistency允许的值为one(只有一个主分片),all(所有主分片和复制分片)或者默认的quorum或过半分片。
注意number_of_replicas是在索引中的的设置,用来定义复制分片的数量,而不是现在活动的复制节点的数量。如果你定义了索引有3个复制节点,那规定数量是:
int( (primary + 3 replicas) / 2 ) + 1 = 3
- 但如果你只有2个节点,那你的活动分片不够规定数量,也就不能索引或删除任何文档。
(3) timeout
当分片副本不足时会怎样?Elasticsearch会等待更多的分片出现。默认等待一分钟。如果需要,你可以设置timeout参数让它终止的更早:100表示100毫秒,30s表示30秒。
自定义路由
所有的文档 API( get 、 index 、 delete 、 bulk 、 update 以及 mget )都接受一个叫做 routing 的路由参数 ,通过这个参数我们可以自定义文档到分片的映射。一个自定义的路由参数可以用来确保所有相关的文档——例如所有属于同一个用户的文档——都被存储到同一个分片中。
PUT r1/doc/1?routing=user1
{
"title":"论母猪的产前保养"
}
PUT r1/doc/2?routing=user1
{
"title":"论母猪的产后护理"
}
上例中,该文档使用user1作为路由值而不是使用_id。这样,具有相同user1的文档将会被分配同一个分片上。
reindex增加routing
想用原搜索某个字段作为目标索引的routing,可以通过script来完成。
例如,使用原索引里”city”字段的值做routing,可以这么写:
POST _reindex
{
"source": {
"index": "old_index"
},
"dest": {
"index": "new_index"
},
"script": {
"inline": "ctx._routing = ctx._source.city",
"lang": "painless"
}
}通过路由查询文档
自定义路由可以减少搜索,不需要将搜索请求分发到所有的分片,只需要将请求发送到匹配特定的路由值分片既可。
我们来查询:
GET r1/doc/1?routing=user1
# 结果如下
{
"_index" : "r1",
"_type" : "doc",
"_id" : "1",
"_version" : 3,
"_routing" : "user1",
"found" : true,
"_source" : {
"title" : "论母猪的产前保养"
}
}也可通过这个路由值查询文档:
GET r1/doc/_search
{
"query": {
"terms": {
"_routing":["user1"]
}
}
}
# 结果如下
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 2,
"max_score" : 1.0,
"hits" : [
{
"_index" : "r1",
"_type" : "doc",
"_id" : "2",
"_score" : 1.0,
"_routing" : "user1",
"_source" : {
"title" : "论母猪的产后护理"
}
},
{
"_index" : "r1",
"_type" : "doc",
"_id" : "1",
"_score" : 1.0,
"_routing" : "user1",
"_source" : {
"title" : "论母猪的产前保养"
}
}
]
}
}删除文档
我们来删除文档。
DELETE r1/doc/1
# 结果如下
{
"_index" : "r1",
"_type" : "doc",
"_id" : "1",
"_version" : 1,
"result" : "not_found",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1
}由上例可见,不提供路由,无法删除文档。
DELETE r1/doc/1?routing=user1
# 结果如下
{
"_index" : "r1",
"_type" : "doc",
"_id" : "1",
"_version" : 2,
"result" : "deleted",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 4,
"_primary_term" : 1
}给上路由就OK了。
由此可见,在查询、删除、更新文档时都要提供相同的路由值。
查询多个路由
除了指定查询单个路由值之外,还可以指定多个路由值查询:
PUT r2/doc/1?routing=user1
{
"title":"母猪产前保养重点在多喂饲料,辅以人工按摩"
}
PUT r2/doc/2?routing=user2
{
"title":"母猪产后护理重点在母子隔离喂养"
}此搜索请求将仅在与user1和user2路由值关联的分片上执行。
GET r2/doc/_search?routing=user1,user2
{
"query": {
"match": {
"title": "母猪"
}
}
}
# 结果如下
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 2,
"max_score" : 0.68324494,
"hits" : [
{
"_index" : "r2",
"_type" : "doc",
"_id" : "2",
"_score" : 0.68324494,
"_routing" : "user2",
"_source" : {
"title" : "母猪产后护理重点在母子隔离喂养"
}
},
{
"_index" : "r2",
"_type" : "doc",
"_id" : "1",
"_score" : 0.5753642,
"_routing" : "user1",
"_source" : {
"title" : "母猪产前保养重点在多喂饲料,辅以人工按摩"
}
}
]
}
}忘了路由值怎么办?
由之前的示例可以看到,再自定义的路由中,索引、查询、删除、更新文档时,都要提供路由值。但是我们有可能会忘记路由值,导致文档在多个分片建立索引:
PUT r3/doc/1?routing=u1
{
"title":"小猪仔非常可爱"
}
PUT r3/doc/2
{
"title":"再可爱也是一盘菜"
}正如上例所示,我们在创建文档2的时候,忘记路由了,导致这篇文档被默认分配到别的分片上了。那我们想通过u1路由查询就会发现:
GET r3/doc/_search
{
"query": {
"terms": {
"_routing":["u1"]
}
}
}
# 结果如下
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 1.0,
"hits" : [
{
"_index" : "r3",
"_type" : "doc",
"_id" : "1",
"_score" : 1.0,
"_routing" : "u1",
"_source" : {
"title" : "小猪仔非常可爱"
}
}
]
}
}可以发现,那个文档2通过这个路由值查询不到,但是可以通过普通的查询:
GET r3/doc/_search这样,两篇文档都会有被返回。
为了避免类似上述的情况出现,我们必须采取安全措施,加个套!在自定义映射关系时,使用_routing参数生成那个安全套!
# 以下是6.5.4版本的写法
PUT r4
{
"mappings": {
"doc":{
"_routing":{
"required": true
}
}
}
}
# 以下是7.0官方文档的的写法
PUT my_index2
{
“mappings”:{
“_ usting”:{
“required”:true
}
}
} 在_routing参数内,将required:true就表明在对文档做CURD时需要指定路由。不然就会抛出一个routing_missing_exception错误。就像下面的示例一样。
PUT r4/doc/1
{
"title":"母猪不怀孕怎么办?"
}
# 结果是报错
{
"error": {
"root_cause": [
{
"type": "routing_missing_exception",
"reason": "routing is required for [r4]/[doc]/[1]",
"index_uuid": "_na_",
"index": "r4"
}
],
"type": "routing_missing_exception",
"reason": "routing is required for [r4]/[doc]/[1]",
"index_uuid": "_na_",
"index": "r4"
},
"status": 400
}有了这种规范,我们在自定义路由时,就可以避免一些不必要的情况发生了。
自定义路由唯一ID
索引指定自定义_routing的文档时,不能保证索引中所有分片的_id唯一性。 事实上,如果使用不同的_routing值索引,具有相同_id的文档可能最终会出现在不同的分片上。
我们应确保ID在索引中是唯一的。
1.手动自定义id
PUT /index_test/type_test/1
{
"name":"one"
}

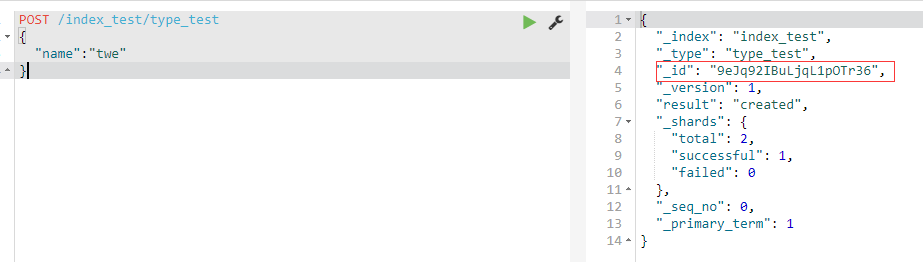
2.自动生成id
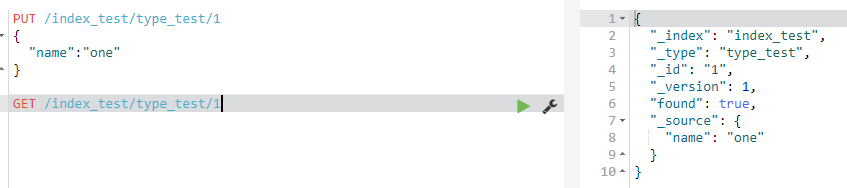
(1)自动生成的id,长度为20个字符,URL安全,base64编码,GUID,分布式系统并行生成时不可能会发生冲突
POST /index_test/type_test
{
"name":"twe"
}
路由到索引分区
问题来了,在实际开发中,可能由于业务场景问题碰到某个路由的文档量非常大,造成该分片非常大,而某些路由的文档却非常小,这就会造成数据偏移而导致集群不平衡。我们该如何办呢?
我们可以配置索引,使得自定义路由值将转到分片的子集而不是单个分片。这有助于降低上述问题导致集群不平衡的风险,同时仍然可以减少搜索的影响。
这是通过在索引创建时提供索引级别设置index.routing_partition_size来完成的。随着分区大小的增加,数据分布越均匀,代价是每个请求必须搜索更多分片。
PUT r6
{
"mappings": {
"doc":{
"_routing":{
"required": true
}
}
},
"settings": {
"index.routing_partition_size": 3
}
}通俗的说,这是限制文档分布到指定个数分片上,而不是默认的所有分片上,既提高了请求效率,也减小单一分片数据量过大的问题。
当此设置存在时,计算分片的公式变为:
shard_num = (hash(_routing) + hash(_id) % routing_partition_size) % num_primary_shards也就是说,_routing字段用于计算索引中的一组分片,然后_id用于选择该集合中的分片。
要启用此功能,index.routing_partition_size应具有大于1且小于index.number_of_shards的值。
启用后,分区索引将具有以下限制:
- 无法在其中创建具有join field关系的映射。
- 索引中的所有映射都必须将_routing字段标记为必需。
see also:
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/14032.html

