
1、Consumer Group 与 topic 订阅
每个Consumer 进程都会划归到一个逻辑的Consumer Group中,逻辑的订阅者是Consumer Group。所以一条message可以被多个订阅message 所在的topic的每一个Consumer Group,也就好像是这条message被广播到每个Consumer Group一样。而每个Consumer Group中,类似于一个Queue(JMS中的Queue)的概念差不多,即一条消息只会被Consumer Group中的一个Consumer消费。
1.1 Consumer 与 partition
其实上面所说的订阅关系还不够明确,其实topic中的partition被分配到某个consumer上,也就是某个consumer订阅了某个partition。 再重复一下:consumer订阅的是partition,而不是message。所以在同一时间点上,订阅到同一个partition的consumer必然属于不同的Consumer Group。
在官方网站上,给出了这样一张图:
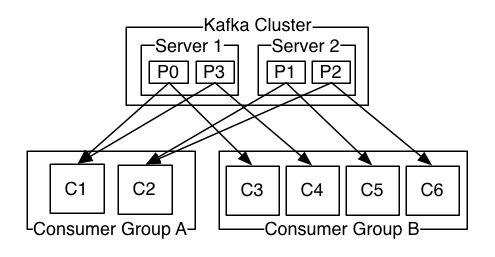
一个kafka cluster中的某个topic,有4个partition。有两个consumer group (A and B)订阅了该topic。 Consumer Group A有2个partition:p0、p1,Consumer Group B有4个partition:c3,c4,c5,c6。经过分区分配后,consumer与partition的订阅关系如下:


Topic 中的4个partition在Consumer Group A中的分配情况如下: C1 订阅p0,p3 C2 订阅p1,p2 Topic 中的4个partition在Consumer Group B中的分配情况如下: C3 订阅p0 C4 订阅p3 C5 订阅p1 C6 订阅p2
另外要知道的是,partition分配的工作其实是在consumer leader中完成的。
1.2 Consumer 与Consumer Group
Consumer Group与Consumer的关系是动态维护的:
当一个Consumer 进程挂掉 或者是卡住时,该consumer所订阅的partition会被重新分配到该group内的其它的consumer上。当一个consumer加入到一个consumer group中时,同样会从其它的consumer中分配出一个或者多个partition 到这个新加入的consumer。
当启动一个Consumer时,会指定它要加入的group,使用的是配置项:group.id。
为了维持Consumer 与 Consumer Group的关系,需要Consumer周期性的发送heartbeat到coordinator(协调者,在早期版本,以zookeeper作为协调者。后期版本则以某个broker作为协调者)。当Consumer由于某种原因不能发Heartbeat到coordinator时,并且时间超过session.timeout.ms时,就会认为该consumer已退出,它所订阅的partition会分配到同一group 内的其它的consumer上。而这个过程,被称为rebalance。
那么现在有这样一个问题:如果一个consumer 进程一直在周期性的发送heartbeat,但是它就是不消费消息,这种状态称为livelock状态。那么在这种状态下,它所订阅的partition不消息是否就一直不能被消费呢?
1.3 Coordinator
Coordinator 协调者,协调consumer、broker。早期版本中Coordinator,使用zookeeper实现,但是这样做,rebalance的负担太重。为了解决scalable的问题,不再使用zookeeper,而是让每个broker来负责一些group的管理,这样consumer就完全不再依赖zookeeper了。
1.3.1 Consumer连接到coordinator
从Consumer的实现来看,在执行poll或者是join group之前,都要保证已连接到Coordinator。连接到coordinator的过程是:
1)连接到最后一次连接的broker(如果是刚启动的consumer,则要根据配置中的borker)。它会响应一个包含coordinator信息(host, port等)的response。
2)连接到coordinator。
1.4 Consumer Group Management
Consumer Group 管理中,也是需要coordinator的参与。一个Consumer要join到一个group中,或者一个consumer退出时,都要进行rebalance。进行rebalance的流程是:
1)会给一个coordinator发起Join请求(请求中要包括自己的一些元数据,例如自己感兴趣的topics)
2)Coordinator 根据这些consumer的join请求,选择出一个leader,并通知给各个consumer。这里的leader是consumer group 内的leader,是由某个consumer担任,不要与partition的leader混淆。
3)Consumer leader 根据这些consumer的metadata,重新为每个consumer member重新分配partition。分配完毕通过coordinator把最新分配情况同步给每个consumer。
4)Consumer拿到最新的分配后,继续工作。
2、Consumer Fetch Message
在Kafka partition中,每个消息有一个唯一标识,即partition内的offset。每个consumer group中的订阅到某个partition的consumer在从partition中读取数据时,是依次读取的。
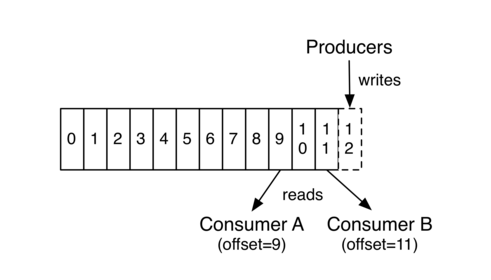
上图中,Consumer A、B分属于不用的Consumer Group。Consumer B读取到offset =11,Consumer A读取到offset=9 。这个值表示Consumer Group中的某个Consumer 在下次读取该partition时会从哪个offset的 message开始读取,即 Consumer Group A 中的Consumer下次会从offset = 9 的message 读取, Consumer Group B 中的Consumer下次会从offset = 11 的message 读取。
这里并没有说是Consumer A 下次会从offset = 9 的message读取,原因是Consumer A可能会退出Group ,然后Group A 进行rebalance,即重新分配分区。
2.1 poll 方法
Consumer读取partition中的数据是通过调用发起一个fetch请求来执行的。而从KafkaConsumer来看,它有一个poll方法。但是这个poll方法只是可能会发起fetch请求。原因是:Consumer每次发起fetch请求时,读取到的数据是有限制的,通过配置项max.partition.fetch.bytes来限制的。而在执行poll方法时,会根据配置项个max.poll.records来限制一次最多pool多少个record。
那么就可能出现这样的情况: 在满足max.partition.fetch.bytes限制的情况下,假如fetch到了100个record,放到本地缓存后,由于max.poll.records限制每次只能poll出15个record。那么KafkaConsumer就需要执行7次才能将这一次通过网络发起的fetch请求所fetch到的这100个record消费完毕。其中前6次是每次pool中15个record,最后一次是poll出10个record。
在consumer中,还有另外一个配置项:max.poll.interval.ms ,它表示最大的poll数据间隔,如果超过这个间隔没有发起pool请求,但heartbeat仍旧在发,就认为该consumer处于 livelock状态。就会将该consumer退出consumer group。所以为了不使Consumer 自己被退出,Consumer 应该不停的发起poll(timeout)操作。而这个动作 KafkaConsumer Client是不会帮我们做的,这就需要自己在程序中不停的调用poll方法了。
2.2 commit offset
当一个consumer因某种原因退出Group时,进行重新分配partition后,同一group中的另一个consumer在读取该partition时,怎么能够知道上一个consumer该从哪个offset的message读取呢?也是是如何保证同一个group内的consumer不重复消费消息呢?上面说了一次走网络的fetch请求会拉取到一定量的数据,但是这些数据还没有被消息完毕,Consumer就挂掉了,下一次进行数据fetch时,是否会从上次读到的数据开始读取,而导致Consumer消费的数据丢失吗?
为了做到这一点,当使用完poll从本地缓存拉取到数据之后,需要client调用commitSync方法(或者commitAsync方法)去commit 下一次该去读取 哪一个offset的message。
而这个commit方法会通过走网络的commit请求将offset在coordinator中保留,这样就能够保证下一次读取(不论进行了rebalance)时,既不会重复消费消息,也不会遗漏消息。
对于offset的commit,Kafka Consumer Java Client支持两种模式:由KafkaConsumer自动提交,或者是用户通过调用commitSync、commitAsync方法的方式完成offset的提交。
自动提交的例子:
Properties props = new Properties(); props.put("bootstrap.servers", "localhost:9092"); props.put("group.id", "test"); props.put("enable.auto.commit", "true"); props.put("auto.commit.interval.ms", "1000"); props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); consumer.subscribe(Arrays.asList("foo", "bar")); while (true) { ConsumerRecords<String, String> records = consumer.poll(100); for (ConsumerRecord<String, String> record : records) System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value()); }
手动提交的例子:
Properties props = new Properties(); props.put("bootstrap.servers", "localhost:9092"); props.put("group.id", "test"); props.put("enable.auto.commit", "false"); props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); consumer.subscribe(Arrays.asList("foo", "bar")); final int minBatchSize = 200; List<ConsumerRecord<String, String>> buffer = new ArrayList<>(); while (true) { ConsumerRecords<String, String> records = consumer.poll(100); for (ConsumerRecord<String, String> record : records) { buffer.add(record); } if (buffer.size() >= minBatchSize) { insertIntoDb(buffer); consumer.commitSync(); buffer.clear(); } }
在手动提交时,需要注意的一点是:要提交的是下一次要读取的offset,例如:
try {
while(running) { // 取得消息 ConsumerRecords<String, String> records = consumer.poll(Long.MAX_VALUE); // 根据分区来遍历数据: for (TopicPartition partition : records.partitions()) { List<ConsumerRecord<String, String>> partitionRecords = records.records(partition); // 数据处理 for (ConsumerRecord<String, String> record : partitionRecords) { System.out.println(record.offset() + ": " + record.value()); } // 取得当前读取到的最后一条记录的offset long lastOffset = partitionRecords.get(partitionRecords.size() - 1).offset(); // 提交offset,记得要 + 1 consumer.commitSync(Collections.singletonMap(partition, new OffsetAndMetadata(lastOffset + 1))); } } } finally { consumer.close(); }
3、Consumer的线程安全性
KafkaProducer是线程安全的,上一节已经了解到。但Consumer却没有设计成线程安全的。当用户想要在在多线程环境下使用kafkaConsumer时,需要自己来保证synchronized。如果没有这样的保证,就会抛出ConcurrentModificatinException的。
当你想要关闭Consumer或者为也其它的目的想要中断Consumer的处理时,可以调用consumer的wakeup方法。这个方法会抛出WakeupException。
例如:
public class KafkaConsumerRunner implements Runnable { private final AtomicBoolean closed = new AtomicBoolean(false); private final KafkaConsumer consumer; public void run() { try { consumer.subscribe(Arrays.asList("topic")); while (!closed.get()) { ConsumerRecords records = consumer.poll(10000); // Handle new records } } catch (WakeupException e) { // Ignore exception if closing if (!closed.get()) throw e; } finally { consumer.close(); } } // Shutdown hook which can be called from a separate thread public void shutdown() { closed.set(true); consumer.wakeup(); } }
4、Consumer Configuration
在kafka 0.9+使用Java Consumer替代了老版本的scala Consumer。新版的配置如下:
·bootstrap.servers
在启动consumer时配置的broker地址的。不需要将cluster中所有的broker都配置上,因为启动后会自动的发现cluster所有的broker。
它配置的格式是:host1:port1;host2:port2…
·key.descrializer、value.descrializer
Message record 的key, value的反序列化类。
·group.id
用于表示该consumer想要加入到哪个group中。默认值是 “”。
·heartbeat.interval.ms
心跳间隔。心跳是在consumer与coordinator之间进行的。心跳是确定consumer存活,加入或者退出group的有效手段。
这个值必须设置的小于session.timeout.ms,因为:
当Consumer由于某种原因不能发Heartbeat到coordinator时,并且时间超过session.timeout.ms时,就会认为该consumer已退出,它所订阅的partition会分配到同一group 内的其它的consumer上。
通常设置的值要低于session.timeout.ms的1/3。
默认值是:3000 (3s)
·session.timeout.ms
Consumer session 过期时间。这个值必须设置在broker configuration中的group.min.session.timeout.ms 与 group.max.session.timeout.ms之间。
其默认值是:10000 (10 s)
·enable.auto.commit
Consumer 在commit offset时有两种模式:自动提交,手动提交。手动提交在前面已经说过。自动提交:是Kafka Consumer会在后台周期性的去commit。
默认值是true。
·auto.commit.interval.ms
自动提交间隔。范围:[0,Integer.MAX],默认值是 5000 (5 s)
·auto.offset.reset
这个配置项,是告诉Kafka Broker在发现kafka在没有初始offset,或者当前的offset是一个不存在的值(如果一个record被删除,就肯定不存在了)时,该如何处理。它有4种处理方式:
1) earliest:自动重置到最早的offset。
2) latest:看上去重置到最晚的offset。
3) none:如果边更早的offset也没有的话,就抛出异常给consumer,告诉consumer在整个consumer group中都没有发现有这样的offset。
4) 如果不是上述3种,只抛出异常给consumer。
默认值是latest。
·connections.max.idle.ms
连接空闲超时时间。因为consumer只与broker有连接(coordinator也是一个broker),所以这个配置的是consumer到broker之间的。
默认值是:540000 (9 min)
·fetch.max.wait.ms
Fetch请求发给broker后,在broker中可能会被阻塞的(当topic中records的总size小于fetch.min.bytes时),此时这个fetch请求耗时就会比较长。这个配置就是来配置consumer最多等待response多久。
·fetch.min.bytes
当consumer向一个broker发起fetch请求时,broker返回的records的大小最小值。如果broker中数据量不够的话会wait,直到数据大小满足这个条件。
取值范围是:[0, Integer.Max],默认值是1。
默认值设置为1的目的是:使得consumer的请求能够尽快的返回。
·fetch.max.bytes
一次fetch请求,从一个broker中取得的records最大大小。如果在从topic中第一个非空的partition取消息时,如果取到的第一个record的大小就超过这个配置时,仍然会读取这个record,也就是说在这片情况下,只会返回这一条record。
broker、topic都会对producer发给它的message size做限制。所以在配置这值时,可以参考broker的message.max.bytes 和 topic的max.message.bytes的配置。
取值范围是:[0, Integer.Max],默认值是:52428800 (5 MB)
·max.partition.fetch.bytes
一次fetch请求,从一个partition中取得的records最大大小。如果在从topic中第一个非空的partition取消息时,如果取到的第一个record的大小就超过这个配置时,仍然会读取这个record,也就是说在这片情况下,只会返回这一条record。
broker、topic都会对producer发给它的message size做限制。所以在配置这值时,可以参考broker的message.max.bytes 和 topic的max.message.bytes的配置。
·max.poll.interval.ms
前面说过要求程序中不间断的调用poll()。如果长时间没有调用poll,且间隔超过这个值时,就会认为这个consumer失败了。
·max.poll.records
Consumer每次调用poll()时取到的records的最大数。
·receive.buffer.byte
Consumer receiver buffer (SO_RCVBUF)的大小。这个值在创建Socket连接时会用到。
取值范围是:[-1, Integer.MAX]。默认值是:65536 (64 KB)
如果值设置为-1,则会使用操作系统默认的值。
·request.timeout.ms
请求发起后,并不一定会很快接收到响应信息。这个配置就是来配置请求超时时间的。默认值是:305000 (305 s)
·client.id
Consumer进程的标识。如果设置一个人为可读的值,跟踪问题会比较方便。
·interceptor.classes
用户自定义interceptor。
·metadata.max.age.ms
Metadata数据的刷新间隔。即便没有任何的partition订阅关系变更也行执行。
范围是:[0, Integer.MAX],默认值是:300000 (5 min)
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/14287.html

