
书名《MySQL是怎样运行的:从根儿上理解MySQL》。
这本书讲得真的很好,建议大家想学习的去看看😊
本文是基于我的认识上将InnoDB的结构进行的回想,查缺补漏。
InnoDB记录结构
InnoDB是以页来存储数据的,一个页的大小为16KB。
InnoDB行格式有COMPACT行格式和Redundant行格式,以及MySQL默认的Dynamic行格式。
COMPACT行格式
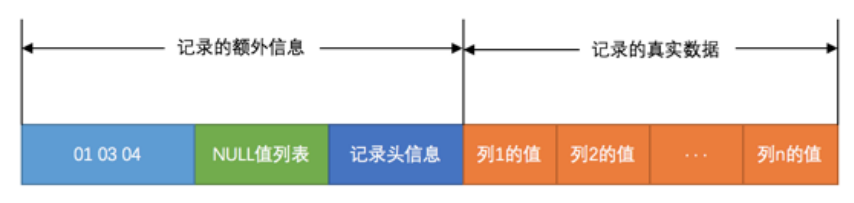
-
变长字段的长度,按列逆序存放,c3,c2,c1列存储。
-
null字段是否为null,表示一些可以为null的字段,具体占用大小具体字段多少,每个可以为null的字段占一位。同样是按列逆序存放,高位用0填充。
-
记录头信息
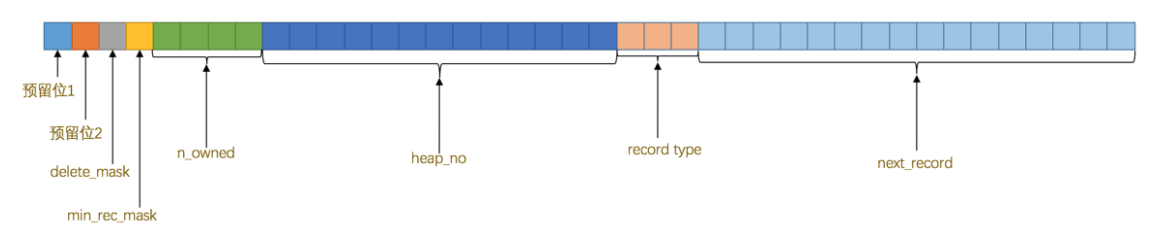

- delete_mask 表示删除位,如果删除置1。1位
- min_rec_mask 表示非叶子节点的最小值
- n_owned 表示每页中最小节点拥有user record数量
- heap_no 表示当前记录在堆中的数量
- record_type 表示当前记录的类型,可以为普通记录0,索引记录1
- next_record 表示下一个数据的指针
-
隐藏列的信息
- row_id 表示当这个表中没有主键时会自动添加一个row_id充当其区别。但是当表中存在主键就会被其替代,不会出现。
- transation_id 事务ID
- roll_pointer 回滚指针
-
列的值,定长的就会直接用一定长度占用,没有占用的用0填充。不定长的就会被指定长度,然后占用其长度的位置。
补充:但是当我们指定的表是不定长的字符集时,会导致一些定长的列也会被列入不定长的列中,但是它会占用最小的空间。比如utf8是1-3字节不定长,char(10)如果没有用超过10个字节的话,最终还是会占用最低10个字符,不够用0填充,原因会产生碎片。
ERROR 1118 (42000): Row size too large. The maximum row size for the used table type, not counting BLOBs, is 65535. This includes storage overhead, check the manual. You have to change some columns to TEXT or BLOBs。
上面也表明了一行表列表中最大的大小65535字节,我们声明整个列时,所有列的空间大小(包括列固定空间(定长+不定长),每个列的根据长度1字节或者2字节,每个列不能为空或者能为空(根据列的空间来判定它的长度))。所以我们在声明大小的时候需要对其大小进行判断,如果大于65535字节需要对其进行调整列的属性大小。
mysql> create table varchar_demo(
-> c varchar(65532)
-> ) CHarset=ascii row_format=compact;
Query OK, 0 rows affected (0.04 sec)
mysql> create table varchar_demo_01(
-> c varchar(65533)
-> ) CHarset=ascii row_format=compact;
ERROR 1118 (42000): Row size too large. The maximum row size for the used table type, not counting BLOBs, is 65535. This includes storage overhead, check the manual. You have to change some columns to TEXT or BLOBs
我们使用的是ASCII字符集只占一个字节,可以发现65532字节 + 判断空的1个字节 + 长度2个字节 刚好是65535字节,当我们试图多加一个字节时就会报错。
Dynamic行格式:
其实和compact行格式差不多,但是它会在数据溢出时全部以引用的方式来引用,而不像compact一样留有768字节在原页中,然后剩余的使用引用的方式。
我们插入的一条一条数据就是形成的这样一条条记录结构,我们想要快速查找到数据呢,就要学习数据页。
InnoDB数据页结构
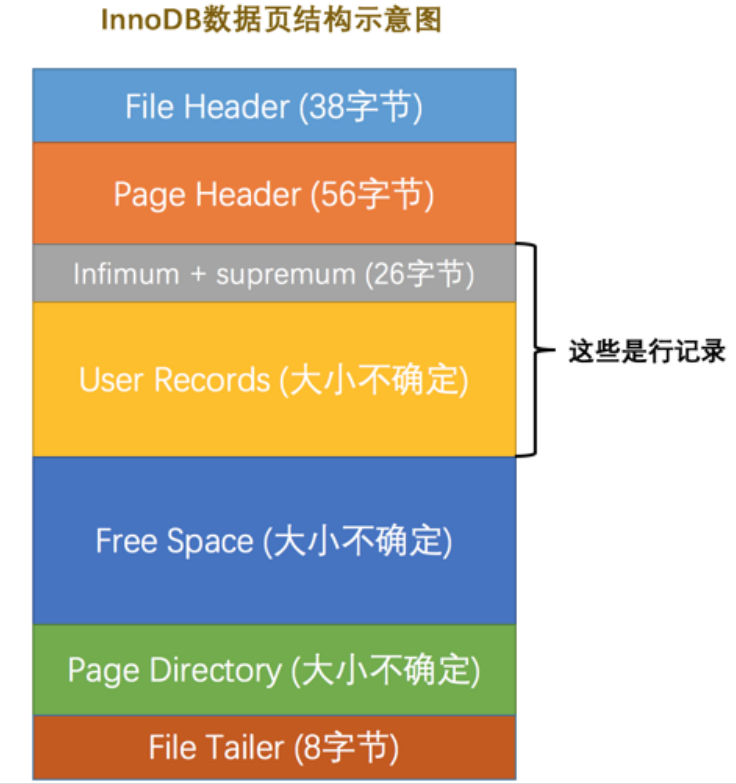
-
File-Header :
- 存储了校验和用来验证数据页进行更新的主要部分。首先呢更新操作会直接将其头部这个File-Header覆盖,然后进行覆盖操作后,如果中途断电,覆盖失败,没有进行覆盖到File-Tailer,此时进行验证,发现头和尾的值值不一样,就会判定为更新失败。
- 下一页和上一页的引用。用来形成页之间的双向链表
- 页的类型是索引页还是数据页。
-
Page Header

-
infimum+supremum。也是一种数据行的形式,是页中固有的两个行。
-
Page Directory 页目录,就是存储页中槽的地方。
首先介绍一下数据页加快查询数据的方法
- 数据插入后会和最小页和最大页形成一个单向链表,并且数据是按主键的大小插入位置的。(主键建议自增,不然会增加开销)
- 然后会进行分组,最小页单独一组,后续4-8行一组,当数据插入组数量变多会出现组分裂为两个组,每组的最后一个数据行作为槽的引用,槽中存储数据行的引用和主键的值。
- 槽中的每个键值就存储的是引用和主键值,然后我们就二分查找主键值即可。
这样我们的数据行就可以很快根据槽存储每组的最大值找到了。
添加一个知识点:就是B+树中删除数据行并不会将其从地址中去除,可能就是把引用释放一下,然后就只是将其删除标记标记一下,下次有数据加入的时候就会直接将其占用。
B+树索引
索引就是对于每页进行再一次的目录化可以这么理解。
将每页的最小的主键作为key和页的索引作为值。当请求key就可以用二分的方法获得这个主键可能所在的页。
对于一个数据页的索引可以作为一个数据行,对于多个数据页的索引,就是多个数据,同样可以分组和将他们集合成一个索引页,如果数据多的话可以多级索引页,数量将是指数级的增长。
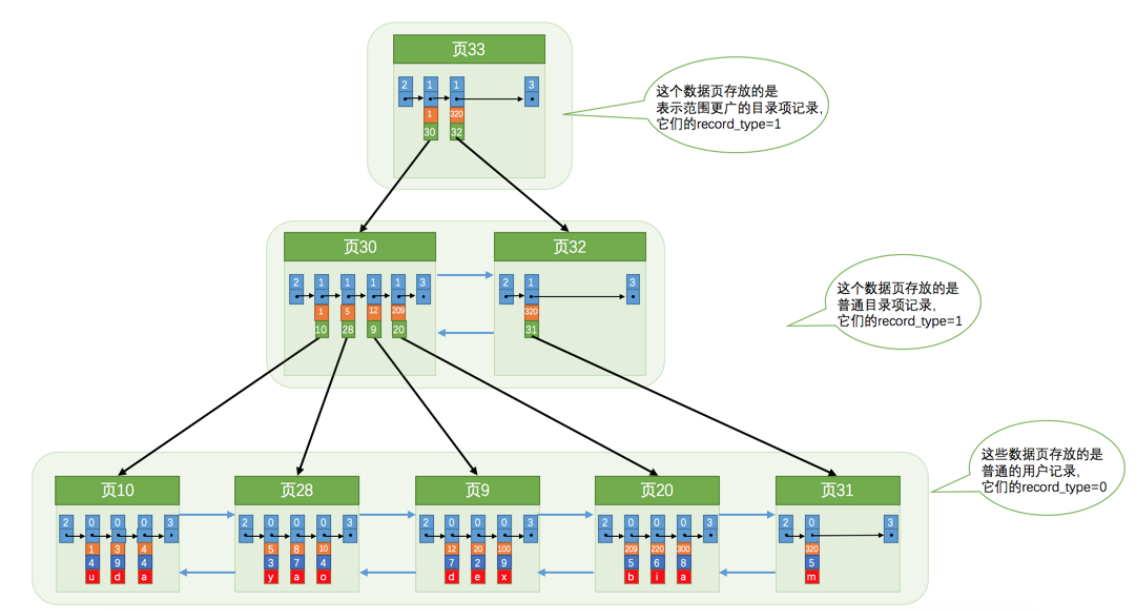
在表创建时,会为主键创建一个聚簇索引。也就是向上面的B+树一样,叶子节点存储的是数据页,非叶子节点存储的是索引页。
但是我们也可以 创建索引,对于列再创建一个B+树即创建二级索引。
MySQL就会再维护一个B+树,此时叶子节点的数据行就是索引指定的列和主键组成的(我们会在进行一次回文,即拿着主键去聚簇索引中找数据);
索引节点就是指定列和页索引,但是当指定列出现了多次重复值,此时就会变成指定列+主键+页索引,防止多个页索引值相同懵逼的状况。
MyISAM索引方案
即数据存放在文件中,然后全部都拿着数据的引用和主键拼在一起。即数据是数据,索引就是索引。不像B+树一样,叶子节点是存放数据行,这个存储引擎则是全部都是索引行,直接拿着地址文件中找数据。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/14529.html

