
为了元素均匀的分布在数组上,减少hash碰撞的机会。
一、hashmap数据结构
1、没有hash碰撞
hashmap初始化,或者put操作没有产生碰撞时,都是均匀分布在数组上。


2、hash碰撞
元素产生hash碰撞时,会调用equals方法比较两个元素是否相同,不相同则以链表的形式存储。
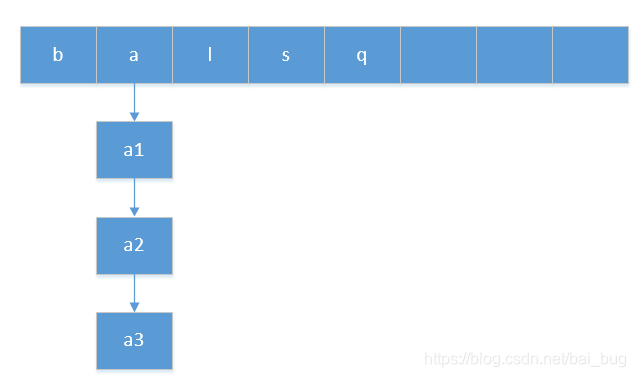
3、链表长度大于8
遍历链表寻找元素的时间复杂度是O(n),当链表长度大于8时,转换成功red black tree(红黑树),
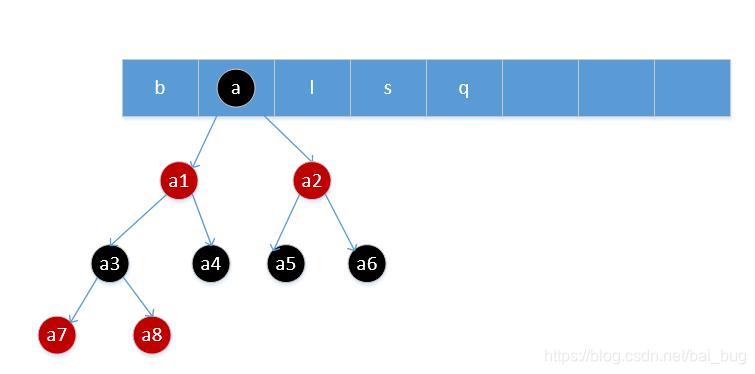
时间复杂度O(lgn)
二、长度是2^n次方如何定位元素位置:
hashMap的put操作是如何定位元素位置的,先求hash值。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}1、hashcode的低位和高位(高位右移16位)做异或运算(相同是0,相异是1,任何与0做异或运算的结果都是原来的数)
2、求hash值的过程
h=key.hashCode()
h: 0000 0000 0000 1111 0000 0000 0000 0000
h>>>16(无符号右移16位,高位补0): 0000 0000 0000 0000 0000 0000 0000 1111
h^h>>>16 : 0000 0000 0000 0000 0000 0000 0000 1111
hash值:15
3、求index,用长度-1和hash值做与运算(相异是0,相同则是其本事,0&0是0,1&1是1),初始长度16
(n-1)&hash
n-1的二进制表示: 0000 0000 0000 0000 0000 0000 0000 1111
hash: 0000 0000 0000 0000 0000 0000 0000 1111
(n-1)&hash 0000 0000 0000 0000 0000 0000 0000 1111
计算出来的index是:15
4、再看一种求index:
(n-1)&hash
n-1的二进制表示: 0000 0000 0000 0000 0000 0000 0000 1111
hash: 0000 0000 0000 0000 0000 0000 0000 1011
(n-1)&hash 0000 0000 0000 0000 0000 0000 0000 1011
计算出来的index是:11
5、最后计算出来的结果和hash值的低几位有关系,只要我们保证hash算法每次结果重复概率小,
上面是长度是16的时候,两种都均匀分布了,一个是7,一个是15。
三、如果长度不是2^n次方,比如10,
1、
n-1的二进制表示: 0000 0000 0000 0000 0000 0000 0000 1001
hash: 0000 0000 0000 0000 0000 0000 0000 1111
(n-1)&hash: 0000 0000 0000 0000 0000 0000 0000 1001
计算出来的index是:9
2、再看一种:
n-1的二进制表示: 0000 0000 0000 0000 0000 0000 0000 1001
hash: 0000 0000 0000 0000 0000 0000 0000 1011
(n-1)&hash: 0000 0000 0000 0000 0000 0000 0000 1001
计算出来的index是:9
3、两次计算出的结果是一样。并且有些情况永远不会出现,比如*11*。这就可能会出现如下数据结构:
所有元素都冗余到一个位置,增加遍历的时间复杂度,降低效率。
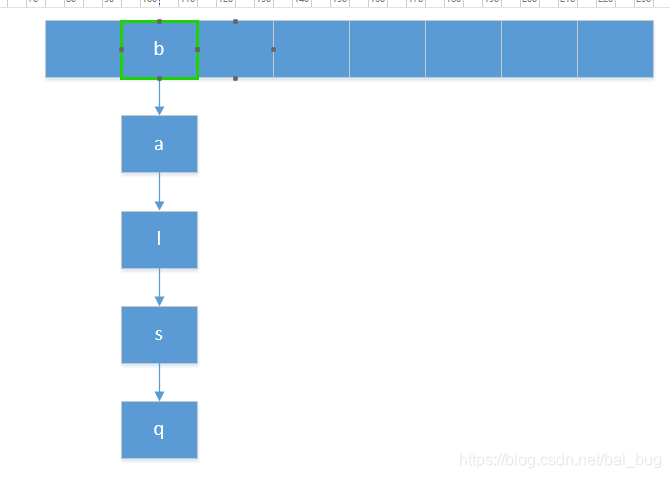
四、所以,长度是2^n,是为了元素在数组上分布均匀。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/14834.html

