
上周做了一个订单数据统计的任务,统计的是订单的新客户数量,本文做一个解题过程的记录和整理。
新客户的定义
新客户指的是选取时间段有订单,时间段之前没有订单。
比如下面的订单数据:
| 时间段 | 2月1日之前 | 2月1日 ~ 3月1日 |
|---|---|---|
| 客户 | A,B,C | A,D,E |
在2月1日之前,有 A,B,C 三家企业下过订单,而2月1号到3月1号有 A,D,E 企业下过订单,找到存在2月1号到3月1号而不存在 2月1号之前的客户,也就是 D,E企业就是新客户。
订单表 t_order 有如下字段:
标识id、 订单号order_sn、业务员 sales、客户 company、下单时间order_time
统计某个时间段的新客户数量(难度:简单)
比如统计2月1日到3月1日的新客户,时间段起始时间和结束时间分别用 begin 和 end 表示。
首先统计出 2月1日之前的客户数,使用 group by 做去重处理 :
select company from t_order where order_time < begin group by company
然后统计出2月1日到3月1日的客户数:
select company from t_order where order_time >= begin and order_time <= end group by company
新客户是存在2月1日到3月1日,不存在2月1日之前的客户,也就是在2月1日到3月1日上去除2月1日之前的客户,整合以上两个 sql 语句,可得如下 sql:
select count(*) from
(select company from t_order where order_time >= begin and order_time <= end group by company) where company not in
(select company from t_order where order_time < begin group by company)
统计业务员的新客户数量(难度:中等)
在上面的基础上多添加业务员的细分统计,使用客户 做分组,先统计出时间段之前的客户:
select company from t_order where order_time < begin group by company
然后查询时间段之内的下单客户,使用业务员、客户做分组:
select company,sales from t_order where order_time >= begin and order_time <= end group by company,sales
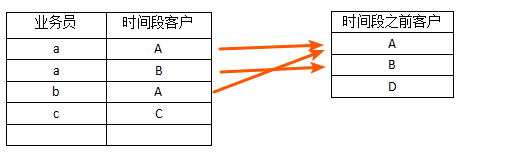

上图展示时间段和时间段之前的客户,相同的客户使用关联连接。其中没有关联的就是新客户,也就是C才是新客户。两个查询做连接查询再使用业务员做分组查询,可得到每个业务的新客户数:
select toi1.sales,
sum( if(toi1.company is not null and toi2.company is null,1,0)) as new_customer
from
(select company,sales from t_order where order_time >= begin and order_time <= end group by company,sales)
toi1 left join
(select company from t_order where order_time < begin group by company) toi2 on toi1.company = toi2.company
group by toi1.sales
统计时间段内每天或者每月的新客户(难度:困难)
上面两个查询都是在统计时间段的客户的基础上排除时间段之前的数据。统计每天或者每个月的,都需要每天和之前的做对比。这里有两个解决方案。
方案一:
步骤一:统计时间段每天或者每月的客户
把客户用 group_concat 拼接起来:
select substring(order_time,1,#{subTime}) as order_time,group_concat(distinct(company)) as companys
from t_order where order_time >= begin and order_time <= end
group by substring(order_time,1,#{subTime})
步骤二:统计每天之前的客户
每一天都需要和前面的数据做比较,首先查询到每天的客户集合,遍历每天的数据再查询之前的数据,如果在当天的客户而不在之前的客户,就是新客户。因为查询要查询很多次,所以查询的时间会很长。
比如查询 2月1日到2月3日的新客户:
| 日期 | 公司集合 |
|---|---|
| 2月1日 | A,B |
| 2月2日 | B,D |
| 2月3日 | C,E |
上面有三条数据,都要循环三次查询,如果时间段比较长,查询耗时更长。
后面想到使用 union all 组合查询,在上面查询的基础上,使用 foreach 遍历每一条数据,每条数据都往前查询数据的客户集合:
<foreach collection="list" item="list" separator=" UNION ALL ">
select #{list.order_time} as order_time,group_concat(distinct (company )) as companys from
t_order_info
where order_type=1 and amount>0 and finish_subtype not in (3,6)
and substring(order_time,1,#{subTime}) < #{list.order_time}
and company in
<foreach collection="list.companys" item="company" open="(" close=")" separator=",">
#{company}
</foreach>
</foreach>
以上的 sql 实际应该是如下格式:
select order_time,company from t_order
union all
select order_time,company from t_order
union all
select order_time,company from t_order
使用 union all 联合查询,快了很多。
步骤三:步骤一的集合去掉步骤二的集合
包含在时间段之内的数据,去掉之前的集合,也就是新客户的了。
group_concat拼接字符,会出现不完整的情况,这是因为超过了group_concat_max_len值,默认是1024,增加该值即可。
方案二:升级方案
下面是2月1日之前,以及2月1日到2月3日每天的客户集合:
| 日期 | 2月1日之前 | 2月1日 | 2月2日 | 2月3日 |
|---|---|---|---|---|
| 公司 | A,B | C | A,D | C,D |
分析
首先看2月1日的数据,客户C 是不存在2月1号之前的,所以2月1号的新客户就是C。
然后看2月2日,要找到2月2日之前的数据。
2月2日之前就是2月1日之前 + 2月1日
所以2月2日之前的数据不需要再去数据库查询,把之前的数据累加起来。
解决方案
使用 set 集合存放数据,首先把 2月1号之前的数据放入set
2月1号之前 A 和 B 放入集合,set 不存在的就是新客户。
首先2月1号的C不在set中,所以2月1号的新客户是C。然后把C添加到集合中。
2月2日中的A在集合中,D不在集合中,所以2月2号的新客户是D。D添加到集合中。
2月3日中的C和D都存在集合中,所以2月3日没有新客户。
如果觉得文章对你有帮助的话,请点个推荐吧!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/14954.html

