
在日常工作中,遇到查询数据比较慢的情况,一般是数据量很大,且没用到索引,索引就像书的目录,如果没有目录,需要一页一页的查询,效率很慢。有了目录,可以快速的查找数据。
索引常见的三种模型
- hash 表
- 排序数组
- 二叉查找树
hash 表是一种以键 – 值存储数据的结构,通过 key 直接直接找到对应的 vale。hash 表只适用等值查询场景,对范围查找就失效了。
排序数组支持等值查询和范围查询,在有序数组中,使用二分查找,查询的时间复杂度是 O(logn)。从查询效率来说,有序数组确实是一个很好的选择。但是需要添加或者删除数据时,为了保证数组的有序性,往中间插入的数据,需要移动数组后面的数组,而内存的分配是很耗时的过程。
二叉树查找树也叫二叉搜索树,它的特定是一个结点上左子树上所有的值都小于右子树上所有的值,可以将索引的值有序的保存在二叉树上,如下图所示。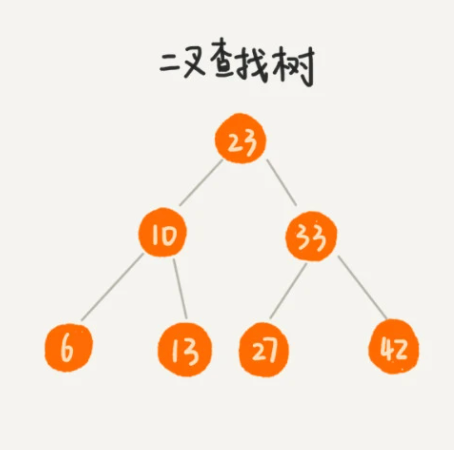
查询的速度就是树的高度,节点每次的访问都对应这磁盘的 IO 操作,同样的数据,为了加快查询速度,需要降低树的高度,而降低树的高度,需要将二叉树转成 N 叉树。这里的 N 和mysql 查询的页的大小有关。
B+树结构
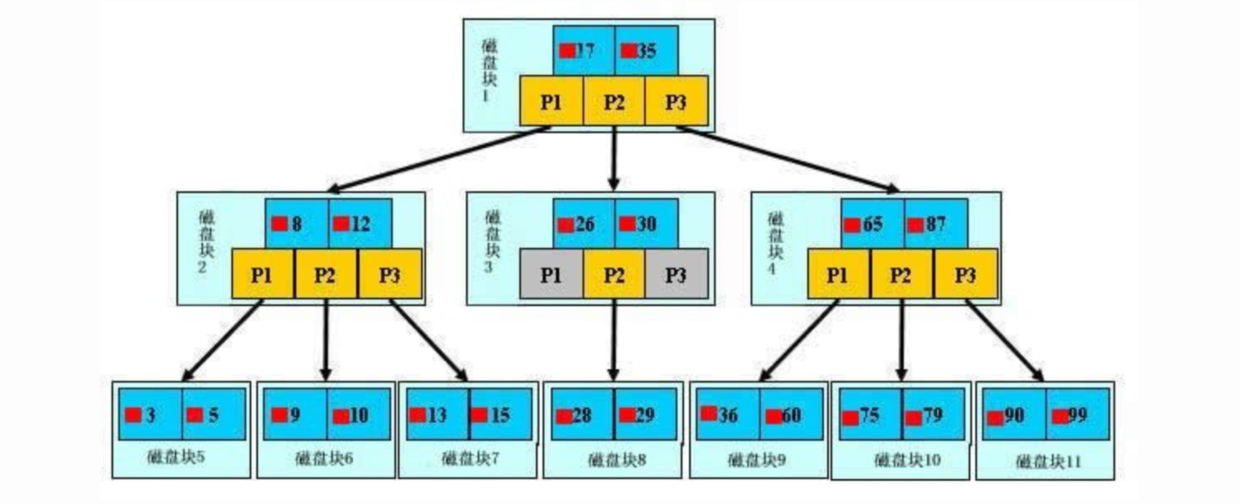
b+树的查找过程
如图所示,B+ 树是一个 N 叉树,每个节点有索引和指针。如果查找数据项28。
- 首先会把磁盘块1加载到内存,此时发生一次IO,在内存中使用二分查找确定28在17和35之间
- 找到磁盘1中的P2指针,通过磁盘1的P2指针指向的磁盘3加载到内存,发生第二次IO
- 28在26和30之间,找到磁盘3的P2指针指向磁盘8,把磁盘8加载到内存中,发生第三次IO
- 在内存中做二分查找找到28,总共三次IO
真实情况是,三层的 b+ 树可以表示上百万的数据,如果百万的数据只需要三次IO,性能将会很大的提升,没有索引,查询每条数据都需要发生一次IO,查询的效率很低。
通过分析,我们可以知道IO次数取决于b+树的高度,当数据一定时,每个磁盘的数量越大,树的高度就越小,磁盘的大小也就是一个数据页的大小,是固定的,如果数据项占的空间越小,数据项的数量越多,树的高度就越低,所以在选择索引字段的时候要尽量小,比如 int 4个字节要比 bigint 占8个字节少占一半。
B+树和B树的区别
- b 树节点存储数据,b+树的节点不存储数据,只是存索引,数据都存储在叶子节点。
- b+树叶子节点用链表串联起来,而b树没有。
创建索引的几个原则
- 最左匹配原则,mysql 会一直向右匹配知道遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 ,如果建立(a,b,c,d)顺序的索引,d是用不到索引的。如果建立(a,b,d,c)的索引都可以用到,a、b、d的顺序可以任意调整。
- = 和 in 可以乱序,比如 a = 1 and b = 2 and c = 3 建立 (a,b,c)索引可以任意顺序,mysql 查询优化器会优化查询索引
- 尽量选择区分度高的列作为索引,区分度指的字段的不重复性比例,比例越大,扫描的记录就越少,唯一键的区分度是1,而一些状态,性别区分度在数据量大的面前区分度就是0
- 索引不能参与计算,保持列的干净,不能在索引列上添加函数,或者运算之类。因为b+树存储的是数据表的数据,而经过运算的数据和b+树上的数据不能做比较,导致索引失效
- 尽量的扩展索引,不要新建索引。比如表中原来有a的索引,现在要添加b的索引,把原来的索引扩展成(a,b)的索引即可。因为没建一个索引,就需要创建一个b+树。
参考
如果觉得文章对你有帮助的话,请点个推荐吧!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/14974.html

![JAVA 如何使用Iterator、foreach遍历集合元素 [案例+代码+总结]](https://www.bmabk.com/wp-content/uploads/2022/05/post-loading-480x300.gif)