
1 常用的客户端命令
1.1、上传文件
cd /usr/local/hadoop-2.8.5/bin
#把jdk上传到hadoop根目录,hdfs默认按128M切割数据并且存3副本,可以进入datanode存数据的地方查看当前文件切割
./hadoop fs -put /usr/local/jdk-8u144-linux-x64.tar.gz /
#如果想要修改备份文件数量和切文件的大小
cd /usr/local/hadoop-2.8.5/etc/hadoop
vim hdfs-site.xml
<property>
<name>dfs.blocksize</name>
<value>64m</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
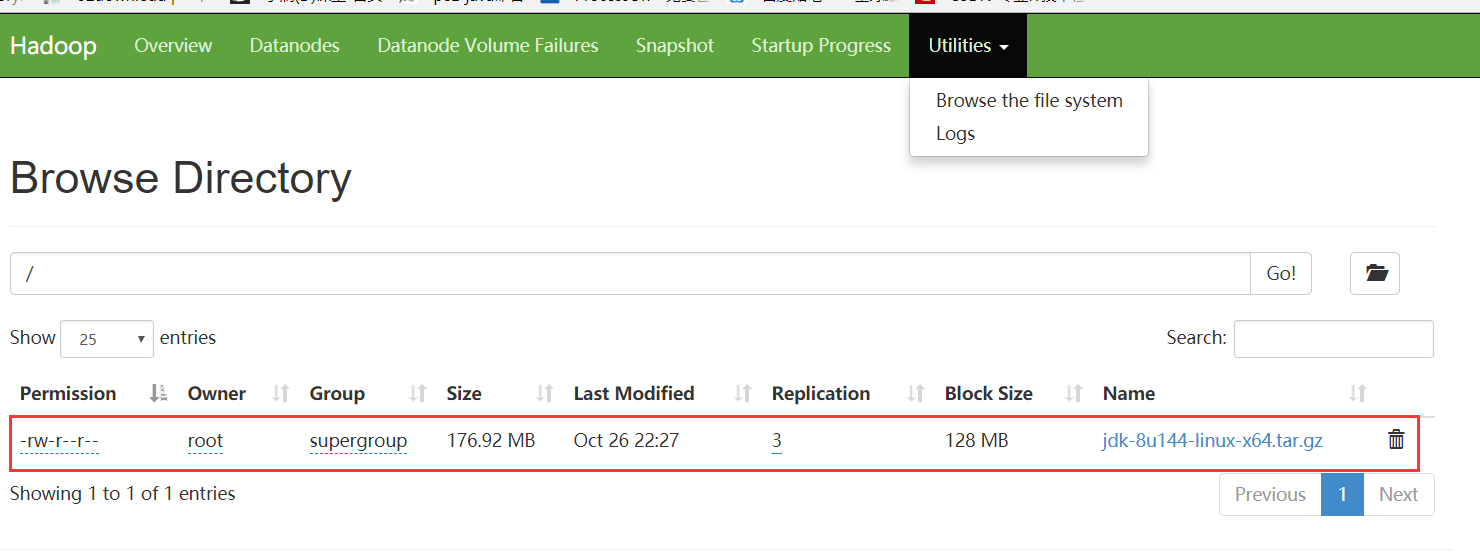


1.2、查看文件
#查找文件
./hadoop fs -ls /
#查看文件大小
./hadoop fs -du -s -h /jdk-8u144-linux-x64.tar.gz

1.3、取文件
./hadoop fs -get /jdk-8u144-linux-x64.tar.gz /usr/local/

2 windows环境配置
2.1 不配置报错
java.io.FileNotFoundException: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset. -see https://wiki.apache.org/hadoop/WindowsProblems
at org.apache.hadoop.util.Shell.fileNotFoundException(Shell.java:528) ~[hadoop-common-2.8.4.jar:na]
at org.apache.hadoop.util.Shell.getHadoopHomeDir(Shell.java:549) ~[hadoop-common-2.8.4.jar:na]
at org.apache.hadoop.util.Shell.getQualifiedBin(Shell.java:572) ~[hadoop-common-2.8.4.jar:na]
at org.apache.hadoop.util.Shell.<clinit>(Shell.java:669) ~[hadoop-common-2.8.4.jar:na]
at org.apache.hadoop.util.StringUtils.<clinit>(StringUtils.java:79) [hadoop-common-2.8.4.jar:na]
2.2 下载windows的hadoop
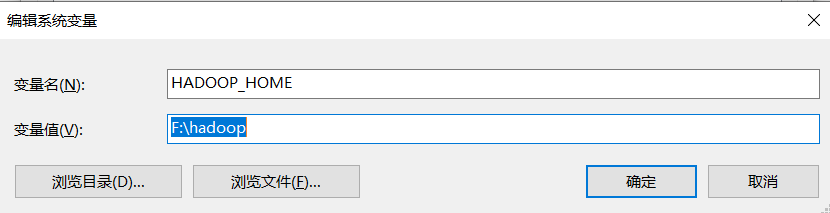
2.3 环境变量
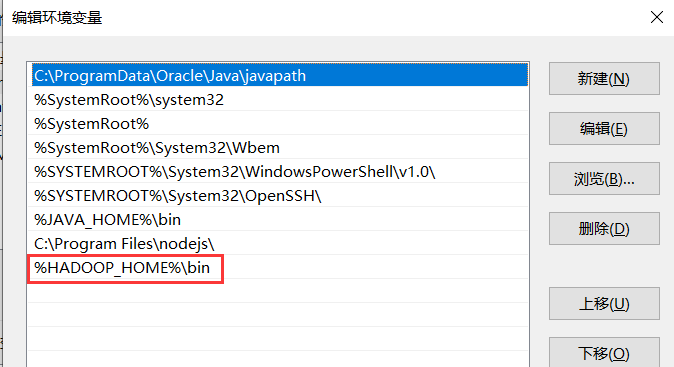
2.4 编辑PATH
2.5、重启Ecplice或IDEA
3 JAVA 整合HDFS
3.1 pom文件
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.8.5</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.8.5</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs-client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs-client</artifactId>
<version>2.8.5</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.6</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.8.1</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
3.2 常用API
#配置文件官网
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
public class HdfsClientDemo {
Configuration conf = null;
FileSystem fs = null;
@Before
public void hdfsInitial() throws Exception {
//1、创建hdfs的配置文件
conf = new Configuration();
// 指定本客户端上传文件到hdfs时需要保存的副本数为:2
conf.set("dfs.replication", "2");
// 指定本客户端上传文件到hdfs时切块的规格大小:64M
conf.set("dfs.blocksize", "64m");
//2、创建客户端,namenodeurl,配置文件,身份
fs = FileSystem.get(new URI("hdfs://192.168.0.38:9000"), conf, "root");
}
/**
* 测试上上传文件
*/
@Test
public void testUpload() {
try {
fs.copyFromLocalFile(new Path("F:\\linux_tar\\hbase\\hbase-1.2.1-bin.tar.gz"), new Path("/hbase/"));
} catch (IOException e) {
e.printStackTrace();
} finally {
if (fs != null) {
try {
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
/**
* 在hdfs中创建文件夹
*/
@Test
public void testMkdir() {
try {
fs.mkdirs(new Path("/test"));
} catch (IOException e) {
e.printStackTrace();
} finally {
if (fs != null) {
try {
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
/**
* 从HDFS中下载文件到客户端本地磁盘
*/
@Test
public void testGet() {
try {
fs.copyToLocalFile(new Path("/test"), new Path("f:/"));
} catch (IOException e) {
e.printStackTrace();
} finally {
if (fs != null) {
try {
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
/**
* 查询hdfs指定目录下的文件信息
*/
@Test
public void testLs() {
// 只查询文件的信息,不返回文件夹的信息
RemoteIterator<LocatedFileStatus> iter = null;
try {
iter = fs.listFiles(new Path("/"), true);
while (iter.hasNext()) {
LocatedFileStatus status = iter.next();
System.out.println("文件全路径:" + status.getPath());
System.out.println("块大小:" + status.getBlockSize());
System.out.println("文件长度:" + status.getLen());
System.out.println("副本数量:" + status.getReplication());
System.out.println("块信息:" + Arrays.toString(status.getBlockLocations()));
System.out.println("--------------------------------");
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if (fs != null) {
try {
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
/**
* 在hdfs中删除文件或文件夹
*/
@Test
public void testRm() {
try {
fs.delete(new Path("/jdk-8u144-linux-x64.tar.gz"), true);
} catch (IOException e) {
e.printStackTrace();
} finally {
if (fs != null) {
try {
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
/**
* 查询hdfs指定目录下的文件和文件夹信息
*/
@Test
public void testSelect() {
try {
FileStatus[] listStatus = fs.listStatus(new Path("/"));
for (FileStatus status : listStatus) {
System.out.println("文件全路径:" + status.getPath());
System.out.println(status.isDirectory() ? "这是文件夹" : "这是文件");
System.out.println("块大小:" + status.getBlockSize());
System.out.println("文件长度:" + status.getLen());
System.out.println("副本数量:" + status.getReplication());
System.out.println("--------------------------------");
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if (fs != null) {
try {
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
4 HDFS元数据管理机制
fsimage 镜像文件:是元数据的一个持久化的检查点,包含 Hadoop 文件系统中的所有目录和文件元数据信息,但不包含文件块位置的信息。文件块位置信息只存储在内存中,是在 datanode 加入集群的时候,namenode 询问 datanode 得到的,并且间断的更新。
Edits 编辑日志:存放的是 Hadoop 文件系统的所有更改操作(文件创建,删除或修改)的日志,文件系统客户端执行的更改操作首先会被记录到 edits 文件中。
fsimage 和 edits 文件都是经过序列化的,在 NameNode 启动的时候,它会将 fsimage文件中的内容加载到内存中,之后再执行 edits 文件中的各项操作,使得内存中的元数据和实际的同步,存在内存中的元数据支持客户端的读操作,也是最完整的元数据。
secondary namenode:SecondNamenode其实只是一个简单的元数据备份进程,它会定期(缺省是1小时)把edits文件的内容合并到fsimage文件,同时保存最新的元数据副本在SecondNamenode进程所在机器的文件系统里。
checkpoint : 会定期从namenode上下载fsimage镜像和新生成的edits日志,然后加载fsimage镜像到内存中,然后顺序解析edits文件,对内存中的元数据对象进行修改(整合)
整合完成后,将内存元数据序列化成一个新的fsimage,并将这个fsimage镜像文件上传给namenode。(checkpoint第一次需要下载fsimage,以后就不需要了)
vim hdfs-site.xml
<!--这两个条件任何一个被满足了,就触发一次检查点创建。-->
<!--1小时-->
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
</property>
<!--操作100w次-->
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
</property>
<!--默认1分钟检查一次是否触发checkpoint条件-->
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60</value>
</property>
5 读写数据流程
5.1 写数据流程
1)客户端请求namnenode,写文件目录+文件。
2)name判断当前目录是否存在,如果存在告知可写,如果不存在抛出异常。
3)客户端请求namenode写入BLOCK。
4)namenode返回3个datanode(几个备份就返回几个datanode,假如d1,d2,d3)。
5)挑选最近的datanode建立传输数据的链接(d1),d1会请求d2(建立数据链接),d2会请求d3(建立数据链接),最终返回给客户端数据链接建立成功。
6)客户端通过流把数据传输给d1,d1一边进行数据写出一边把数据传给d2,d2会一边把数据写入一边把数据传给d3。
7)传第二个BLOCK
5.2 读数据流程
1)客户端请求namenode
2)namenode返回元数据信息(例如d1,d2,d3)
3)客户端选择最近的datanode建立连接,读取文件。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/15165.html

