
如果你觉得内容对你有帮助的话,不如给个赞,鼓励一下更新😂。
加油啊!新的一天,新的开始😘
Redis为什么这么快呢?
- Redis 采用 ANSI C 语言编写。采用 C 语言进行编写的好处是底层代码执行效率高,依赖性低,因为使用 C 语言开发的库没有太多运行时(Runtime)依赖,而且系统的兼容性好,稳定性高。
- 此外,Redis 是基于内存的数据库,所有数据都在内存中,所有运算都是内存级别的运算,这样可以避免磁盘 I/O,因此 Redis 也被称为缓存工具。
- 其次,数据结构结构简单,Redis 采用 Key-Value 方式进行存储,也就是使用 Hash 结构进行操作,数据的操作复杂度为 O(1)。
- 它采用单进程单线程模型,这样做的好处就是避免了上下文切换和不必要的线程之间引起的资源竞争。
- 在技术上 Redis 还采用了多路 I/O 复用(事件轮询)技术。这里的多路指的是多个 socket 网络连接,复用指的是复用同一个线程。采用多路 I/O 复用技术的好处是可以在同一个线程中处理多个 I/O 请求,尽量减少网络 I/O 的消耗,提升使用效率。
Redis数据结构
Redis如何保存这些数据类型?
Redis使用一个哈希表来保存所有键值对,使用哈希表必然存在hash冲突,redis解决hash冲突的方式主要是用链式存储,但是这样会导致在链上查找时变成O(n)的时间复杂度,所以redis会对哈希表做rehash操作,主要是用的渐进式hash
Redis默认使用两个哈希表,哈希表1和哈希表2,默认使用1,然后2没分配,当redis进行rehash的时候,给2分配比1更大的空间,然后把1的数据重新映射到2中,并释放1的空间。:
五大基础数据类型
String
最简单的类型,就是普通的 set 和 get,做简单的 KV 缓存
List
通过 list 存储一些列表型的数据结构,类似粉丝列表、文章的评论列表之类的东西;
简单消息队列,分页
Hash
类似 map 的一种结构,这个一般就是可以将结构化的数据,比如一个对象(前提是这个对象没嵌套其他的对象)给缓存在 Redis 里,例如:存储用户信息,存储对象
Set
如果你需要对一些数据进行快速的全局去重,你当然也可以基于 jvm 内存里的 HashSet 进行去重,但是如果你的某个系统部署在多台机器上呢?得基于 Redis 进行全局的 set 去重;
比如存储中奖用户,交集并集可以算共同好友等
ZSet
排行榜,滑动窗口限流
Redis中一定要尽量避免大Key的产生,因为如果某个 key 太大,会数据导致迁移卡顿。另外在内存分配上,如果一个 key 太大,那么当它需要扩容时,会一次性申请更大的一块内存,这也会导致卡顿。如果这个大 key 被删除,内存会一次性回收,卡顿现象会再一次产生。
高级功能
bit 位图
统计活跃人数,用户签到等
HyperLogLog
可用来统计每个页面每天访问次数
不适合统计单个用户的相关数据,因为单个HyperLoglog一定会占用12kb的存储空间
布隆过滤器
用户记录去重,爬虫url去重,判断一个数据是否存在等
redis-cell 漏斗限流
cl.throttle laoqian:reply 15 30 60 1
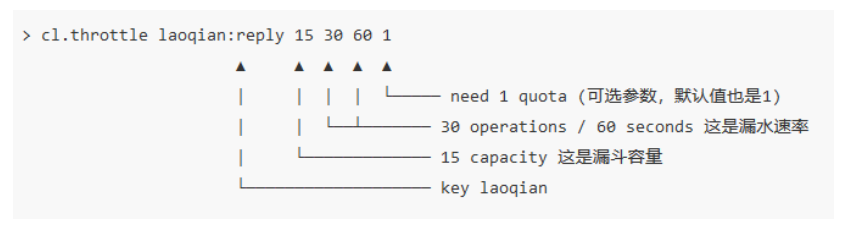
上面这个指令的意思是允许「用户老钱回复行为」的频率为每 60s 最多 30 次(漏水速
率),漏斗的初始容量为 15,也就是说一开始可以连续回复 15 个帖子,然后才开始受漏水速率的影响。我们看到这个指令中漏水速率变成了 2 个参数,替代了之前的单个浮点数。用两个参数相除的结果来表达漏水速率相对单个浮点数要更加直观一些。

线程IO模型
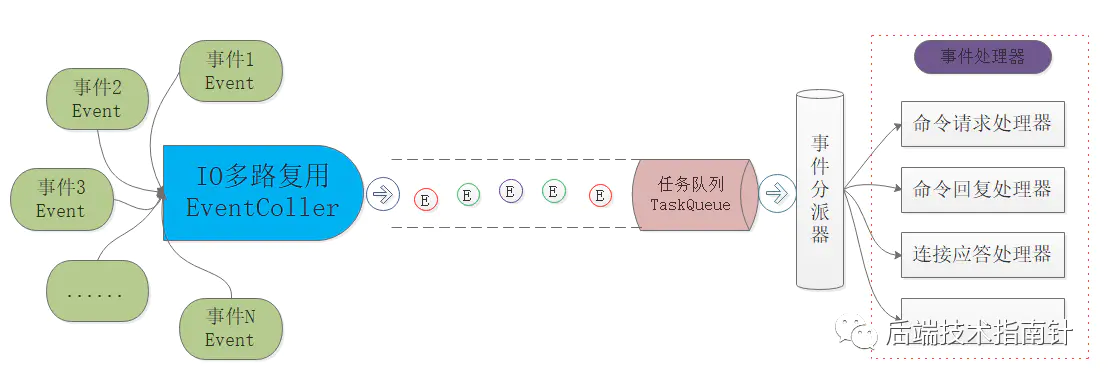
Redis使用的是单线程的Reactor事件处理模型,内部使用文件事件处理器 file event handler ,这个文件事件处理器是单线程的,所以 Redis 才叫做单线程的模型。
因为Redis是单线程的,所有对于那些O(n)的指令我们要小心使用,避免带来服务卡顿。
Redis是单线程的,不是指整个Redis是以单线程在运行而是指Redis 服务器中其它模块同样是单线程运行的,比如IO多路复用程序和文件事件分派器就是两个独立的单线程,它们中间通过队列来维护先进先出的执行
文件事件处理器的结构包含 4 个部分:
- 多个 socket
- IO 多路复用程序
- 文件事件分派器
- 事件处理器(连接应答处理器、命令请求处理器、命令回复处理器)
Redis的一次通信
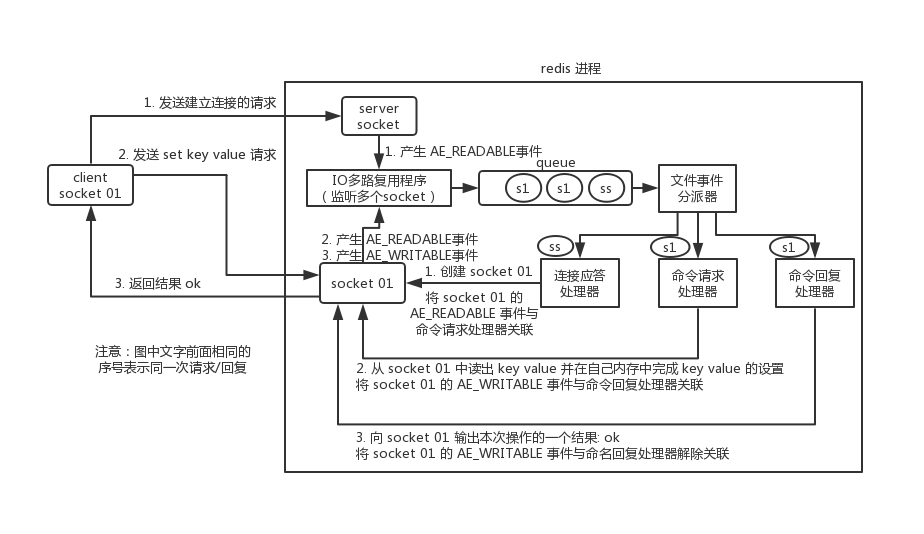
- 首先,Redis 服务端进程初始化的时候,会将
ServerSocket的AE_ACCEPT事件与连接应答处理器关联。 - 客户端 client 向 Redis 进程的
ServerSocket请求建立连接,此时ServerSocket会产生一个AE_ACCEPT事件,IO 多路复用程序监听到ServerSocket产生的事件后,将该 Socket 压入指令队列中。文件事件分派器从队列中获取 Socket,交给连接应答处理器。连接应答处理器会创建一个能与客户端通信的Socket01,并将该Socket01的AE_READABLE事件与命令请求处理器关联。 - 假设此时客户端发送了一个
set请求,此时 Redis 中的Socket01会产生AE_READABLE事件,IO 多路复用程序将Socket01压入队列,此时事件分派器从队列中获取到Socket01产生的AE_READABLE事件,由于前面Socket01的AE_READABLE事件已经与命令请求处理器关联,因此事件分派器将事件交给命令请求处理器来处理。命令请求处理器读取Socket01的set操作,并在自己内存中完成 。它会将Socket01的AE_WRITABLE事件与命令回复处理器关联。 - 如果此时客户端准备好接收返回结果了,那么 Redis 中的
Socket01会产生一个AE_WRITABLE事件,同样压入队列中,事件分派器找到相关联的命令回复处理器,由命令回复处理器对Socket01输入本次操作的一个结果,之后解除Socket01的AE_WRITABLE事件与命令回复处理器的关联。
多路复用(事件轮询)
Redis采用IO多路复用来解决并发客户端连接的问题
指令队列
Redis 会将每个客户端套接字都关联一个指令队列。客户端的指令通过队列来排队进行顺序处理,先到先服务。自然还有响应队列,Redis 服务器通过响应队列来将指令的返回结果回复给客户端。
Redis 6.0 开始引入多线程
Redis 6.0 之后的版本抛弃了单线程模型这一设计,原本使用单线程运行的 Redis 也开始选择性地使用多线程模型。
这其实说明 Redis 在有些方面,单线程已经不具有优势了。因为读写网络的 Read/Write 系统调用在 Redis 执行期间占用了大部分 CPU 时间,如果把网络读写做成多线程的方式对性能会有很大提升。
Redis 的多线程部分只是用来处理网络数据的读写和协议解析,执行命令仍然是单线程。
持久化
快照是内存数据的二进制序列化形式,在存储上非常紧凑,而 AOF 日志记录的是内存数据修改的指令记录文本。
RDB快照持久化
Redis使用操作系统的多进程COW(Copy On Write)机制来实现持久化,Redis会fork一个子进程,然后把快照持久化交给子进程来处理,父进程继续处理客户端子进程,比如 bgsave 指令就是fork 出一个新子进程,原来的 Redis 进程(父进程)继续处理客户端请求,而子进程则负责将数据保存到磁盘,然后退出。
AOF增量持久化
AOF 日志存储的是 Redis 服务器的顺序指令序列,AOF 日志只记录对内存进行修改的指令记录。假设 AOF 日志记录了自 Redis 实例创建以来所有的修改性指令序列,那么就可以通过对一个空的 Redis 实例顺序执行所有的指令,也就是 「重放」,来恢复 Redis 当前实例的内存数据结构的状态。
AOF 日志在长期的运行过程中会变的无比庞大,数据库重启时需要加载 AOF 日志进行指令重放,这个时间就会无比漫长。 所以需要定期进行 AOF 重写,给 AOF 日志进行瘦身。
Redis4.0混合持久化
重启Redis时,我们很少使用rdb的方式来恢复内存状态,因为会丢失大量数据,我们通常使用aof日志重放,但是重放aof日志性能相对rdb来说要慢很多,redis 4.0为了解决这个问题,带来了新的持久化选项-混合持久化,混合持久化下的AOF 重写产生的文件将同时包含 RDB 格式的内容和 AOF 格式的内容, 其中 RDB 格式的内容用于记录已有的数据, 而 AOF 格式的内存则用于记录最近发生了变化的数据, 这样 Redis 就可以同时兼有 RDB 持久化和 AOF 持久化的优点 —— 既能够快速地生成重写文件, 也能够在出现问题时, 快速地载入数据。
管道(Pipeline)
当我们使用客户端对 Redis 进行一次操作时,客户端将请求传送给服务器,服务器处理完毕后,再将响应回复给客户端。这要花费一个网络数据包来回的时间。 如果连续执行多个指令,那么就是多个网络数据包来回的时间。

这样我们只需要花费一次网络数据包来回的时间,这便是管道的本质,客户端通过对管道中的指令列表改变读写顺序就可以大幅节省 IO 时间。管道中指令越多,效果越好。
事务
Redis 提供的不是严格的事务,Redis 只保证隔离性,也即串行执行命令,并且能保证全部执行,但是执行命令失败时并不会回滚,而是会继续执行下去,所以不保证原子性。
过期策略
两种:定期删除和惰性删除
Redis 会将每个设置了过期时间的 key 放入到一个独立的字典中,以后会定时遍历这个字典来删除到期的 key。除了定时遍历之外,它还会使用惰性策略来删除过期的 key,所谓惰性策略就是在客户端访问这个 key 的时候,redis 对 key 的过期时间进行检查,如果过期了就立即删除。定时删除是集中处理,惰性删除是零散处理。
Redis 默认会每秒进行十次过期扫描,过期扫描不会遍历过期字典中所有的 key,而是采用了一种简单的贪心策略。
1、从过期字典中随机 20 个 key;
2、删除这 20 个 key 中已经过期的 key;
3、如果过期的 key 比率超过 1/4,那就重复步骤 1;
同时,为了保证过期扫描不会出现循环过度,导致线程卡死现象,算法还增加了扫描时间的上限,默认不会超过 25ms。
内存淘汰机制
设置方式:内存淘汰策略我们可以通过配置文件来修改,redis.conf 对应的配置项是“maxmemory-policy noeviction”,只需要把它修改成我们需要设置的类型即可,修改后需要重启Redis实例。
当 Redis 内存超出物理内存限制时,内存的数据会开始和磁盘产生频繁的交换 (swap),交换会让 Redis 的性能急剧下降。
默认的淘汰策略是”noeviction”,也即不会继续服务写请求 (DEL 请求可以继续服务),读请求可以继续进行。这样可以保证不会丢失数据,但是会让线上的业务不能持续进行。
volatile-xxx 策略只会针对带过期时间的 key 进行淘汰,allkeys-xxx 策略会对所有的key 进行淘汰。如果你只是拿 Redis 做缓存,那应该使用 allkeys-xxx,客户端写缓存时不必携带过期时间。如果你还想同时使用 Redis 的持久化功能,那就使用 volatile-xxx 策略,这样可以保留没有设置过期时间的 key,它们是永久的 key 不会被 LRU 算法淘汰。
LRU( Least Recently Used,最近最少使用)淘汰算法:是一种常用的页面置换算法,也就是说最久没有使用的缓存将会被淘汰。
LFU(Least Frequently Used,最不常用的)淘汰算法:最不常用的算法是根据总访问次数来淘汰数据的,它的核心思想是“如果数据过去被访问多次,那么将来被访问的频率也更高”。
LFU 相对来说比 LRU 更“智能”,因为它解决了使用频率很低的缓存,只是最近被访问了一次就不会被删除的问题。如果是使用 LRU 类似这种情况数据是不会被删除的,而使用 LFU 的话,这个数据就会被删除。
阅读推荐
关于Redis强烈推荐这本小册子:Redis 深度历险:核心原理与应用实践
真的写的很好,价格优惠且知识点齐全,还在等什么?此文大部分记录都来源于这本小册子,感谢作者。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/15199.html

