
本文主要演示Sharding JDBC 相关JAVA API 是如何使用的,通过实际案例让大家能掌握如何分库分表。
官网:https://shardingsphere.apache.org/index_zh.html
项目整体思路:根据uid取模分库,根据oderid取模分表。
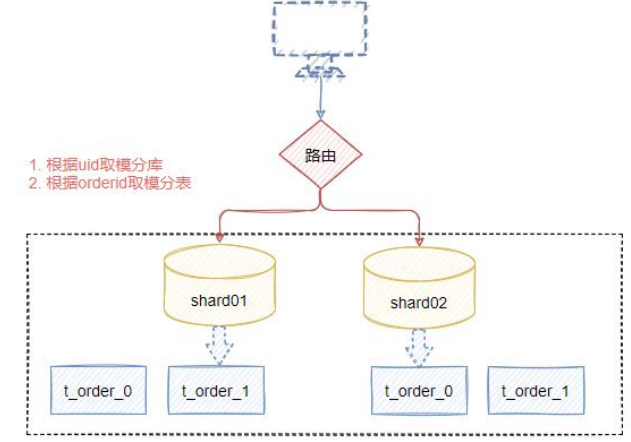

1. 项目搭建
通过IDEA直接创建一个Spring Boot 或者 Mavne 项目即可。
2. 相关依赖
引入相关依赖,如:连接池依赖、数据库依赖以及最重要的shardingsphere-jdbc依赖。
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core</artifactId>
<version>5.0.0-alpha</version>
</dependency>
<dependency>
<groupId>com.zaxxer</groupId>
<artifactId>HikariCP</artifactId>
<version>3.4.1</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
</dependencies>
3. 业务代码
业务代码直接使用JDBC来实现表的创建以及数据的插入,代码比较简单,就不过多讲解。
- 实体类
@Data
public class Order implements Serializable {
private static final long serialVersionUID = 661434701950670670L;
private long orderId;
private int userId;
private long addressId;
private String status;
}
- Dao层
public interface OrderRepository {
void createTableIfNotExists() throws SQLException;
Long insert(final Order order) throws SQLException;
}
public class OrderRepositoryImpl implements OrderRepository {
private final DataSource dataSource;
public OrderRepositoryImpl(final DataSource dataSource) {
this.dataSource = dataSource;
}
@Override
public void createTableIfNotExists() throws SQLException {
String sql = "CREATE TABLE IF NOT EXISTS t_order (order_id BIGINT NOT NULL AUTO_INCREMENT, user_id INT NOT NULL, address_id BIGINT NOT NULL, status VARCHAR(50), PRIMARY KEY (order_id))";
try (Connection connection = dataSource.getConnection();
Statement statement = connection.createStatement()) {
statement.executeUpdate(sql);
}
}
@Override
public Long insert(final Order order) throws SQLException {
String sql = "INSERT INTO t_order (user_id, address_id, status) VALUES (?, ?, ?)";
try (Connection connection = dataSource.getConnection();
PreparedStatement preparedStatement = connection.prepareStatement(sql, Statement.RETURN_GENERATED_KEYS)) {
preparedStatement.setInt(1, order.getUserId());
preparedStatement.setLong(2, order.getAddressId());
preparedStatement.setString(3, order.getStatus());
preparedStatement.executeUpdate();
try (ResultSet resultSet = preparedStatement.getGeneratedKeys()) {
if (resultSet.next()) {
order.setOrderId(resultSet.getLong(1));
}
}
}
return order.getOrderId();
}
}
- service 层
public interface ExampleService {
/**
* 初始化表结构
*
* @throws SQLException SQL exception
*/
void initEnvironment() throws SQLException;
/**
* 执行成功
*
* @throws SQLException SQL exception
*/
void processSuccess() throws SQLException;
}
public class OrderServiceImpl implements ExampleService {
private final OrderRepository orderRepository;
Random random = new Random();
public OrderServiceImpl(final DataSource dataSource) {
orderRepository = new OrderRepositoryImpl(dataSource);
}
@Override
public void initEnvironment() throws SQLException {
orderRepository.createTableIfNotExists();
}
@Override
public void processSuccess() throws SQLException {
System.out.println("-------------- Process Success Begin ---------------");
List<Long> orderIds = insertData();
System.out.println("-------------- Process Success Finish --------------");
}
private List<Long> insertData() throws SQLException {
System.out.println("---------------------------- Insert Data ----------------------------");
List<Long> result = new ArrayList<>(10);
for (int i = 1; i <= 10; i++) {
Order order = insertOrder(i);
result.add(order.getOrderId());
}
return result;
}
private Order insertOrder(final int i) throws SQLException {
Order order = new Order();
order.setUserId(random.nextInt(10000));
order.setAddressId(i);
order.setStatus("INSERT_TEST");
orderRepository.insert(order);
return order;
}
}
4. 多数据源工具类
由于我们想实现分库分表,所以我们需要操作多个数据源,这里编写一个工具类帮助我们获取多个数据源。
public class DataSourceUtil {
private static final String HOST = "localhost";
private static final int PORT = 3306;
private static final String USER_NAME = "root";
private static final String PASSWORD = "123456";
public static DataSource createDataSource(final String dataSourceName) {
HikariDataSource result = new HikariDataSource();
result.setDriverClassName("com.mysql.jdbc.Driver");
result.setJdbcUrl(String.format("jdbc:mysql://%s:%s/%s?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8", HOST, PORT, dataSourceName));
result.setUsername(USER_NAME);
result.setPassword(PASSWORD);
return result;
}
}
5. Sharding JDBC Configuration
该部分是实现分库分表的核心部分,我们逐步讲解。
5.1 数据源配置
首先我们不能通过原生的数据源操作数据库,所以我们需要通过 ShardingSphereDataSourceFactory 工厂创建的 ShardingSphereDataSource 实现自 JDBC 的标准接口 DataSource。
所以,我们首先将我们需要用到的本地数据源创建成功,后期作为参数使用。这里用到上文的工具类创建相关的数据源。
private static Map<String, DataSource> createDataSourceMap() {
//代表真实的数据源
Map<String, DataSource> dataSourceMap = new HashMap<>();
dataSourceMap.put("ds0", DataSourceUtil.createDataSource("shard01"));
dataSourceMap.put("ds1", DataSourceUtil.createDataSource("shard02"));
return dataSourceMap;
}
5.2 分片规则
在创建数据源时,我们从相关参数中可以看出,除了需要数据源,我们还需要配置相关规则。

我们在创建分片规则的时候有如下几个需要考虑:一种是针对数据库的分片,一种是针对表的分片;同时我们还需要注意配置分片键、分片算法以及处理全局ID的相关问题;
-
分库规则
下方代码中,我们根据user_id进行数据的分片,通过user_id和2取模,使用相应的数据源将其存入数据库中;
//设置数据库分库规则 configuration.setDefaultDatabaseShardingStrategy( new StandardShardingStrategyConfiguration ("user_id", "db-inline")); Properties properties = new Properties(); properties.setProperty("algorithm-expression", "ds${user_id%2}"); //设置分库策略 configuration.getShardingAlgorithms(). put("db-inline", new ShardingSphereAlgorithmConfiguration("INLINE", properties));关于这里面的分库策略,使用的是 sharding jdbc 提供的内置算法进行分片。
上文代码中
db-inline是我们任意取的名字,然后INLINE是固定的行类算法类型,使用分库策略的时候,我们需要设置相关的参数;比如上文的algorithm-expression就是分片算法的行表达式。当然,除了内置算法,我们也可以采用自定义算法,在本文就不过多讲述。
https://shardingsphere.apache.org/document/current/cn/user-manual/shardingsphere-jdbc/builtin-algorithm/sharding/
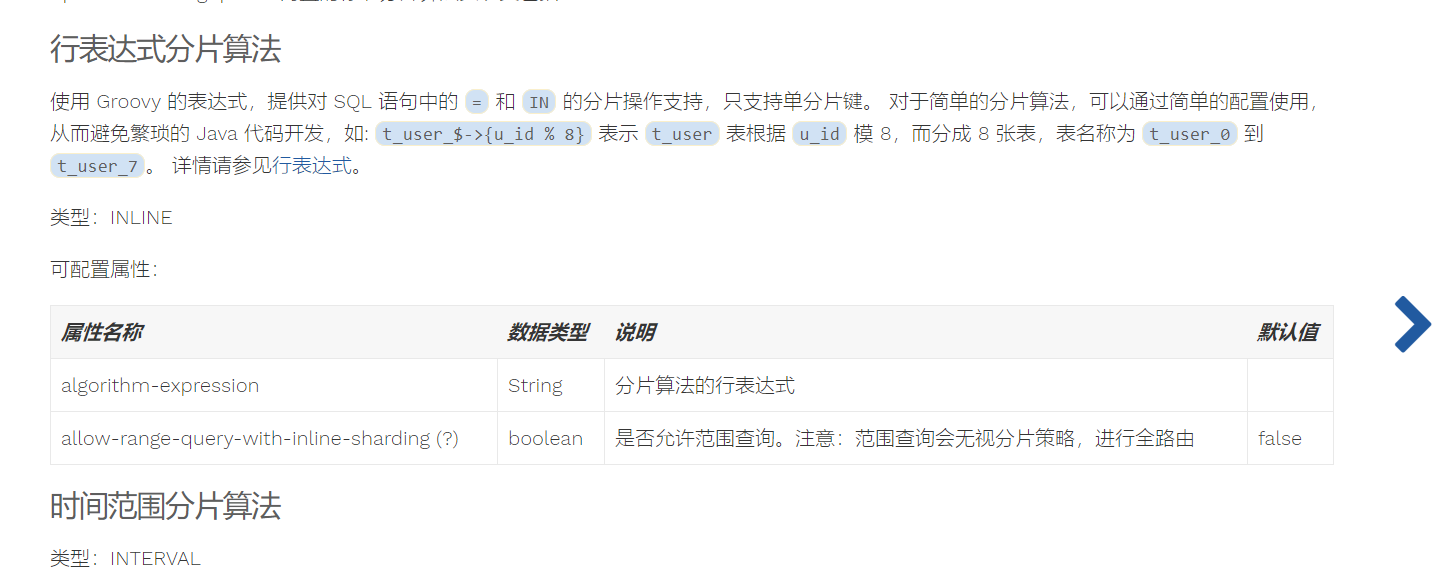
-
分表策略
设置完分库策略后,我们可以按照相同的逻辑编写分表策略。
//设置表的分片规则(数据的水平拆分) configuration.setDefaultTableShardingStrategy(new StandardShardingStrategyConfiguration ("order_id", "order-inline")); //设置分表策略 Properties props = new Properties(); props.setProperty("algorithm-expression", "t_order_${order_id%2}"); configuration.getShardingAlgorithms().put("order-inline", new ShardingSphereAlgorithmConfiguration("INLINE", props)); -
雪花算法
为了确保主键唯一,提供了内置的UUID以及雪花算法。
https://shardingsphere.apache.org/document/current/cn/features/sharding/concept/key-generator/
//设置主键生成策略 // * UUID // * 雪花算法 Properties idProperties = new Properties(); idProperties.setProperty("worker-id", "123"); configuration.getKeyGenerators().put("snowflake", new ShardingSphereAlgorithmConfiguration("SNOWFLAKE", idProperties)); -
配置逻辑表以及表的id策略
由于我们在Dao层,插入数据的时候表名还是t_order,并不是我们分片时候的t_order_0和t_order_1;所以我们需要配置相应的逻辑表。
//配置逻辑表以及表的id策略 //逻辑表不是物理存在的表 //ds0.t_order_1/ds1.t_order_0 private static ShardingTableRuleConfiguration getOrderTableRuleConfiguration() { ShardingTableRuleConfiguration tableRuleConfiguration = new ShardingTableRuleConfiguration("t_order", "ds${0..1}.t_order_${0..1}"); tableRuleConfiguration.setKeyGenerateStrategy(new KeyGenerateStrategyConfiguration("order_id", "snowflake")); return tableRuleConfiguration; }
5.3 全部代码
public class ShardingDatabaseAndTableConfiguration {
private static Map<String, DataSource> createDataSourceMap() {
//代表真实的数据源
Map<String, DataSource> dataSourceMap = new HashMap<>();
dataSourceMap.put("ds0", DataSourceUtil.createDataSource("shard01"));
dataSourceMap.put("ds1", DataSourceUtil.createDataSource("shard02"));
return dataSourceMap;
}
//创建分片规则
//* 针对数据库
//* 针对表
//* 一定要配置分片键
//* 一定要配置分片算法
//* 完全唯一id的问题
private static ShardingRuleConfiguration createShardingRuleConfiguration() {
ShardingRuleConfiguration configuration = new ShardingRuleConfiguration();
//把逻辑表和真实表的对应关系添加到分片规则配置中
configuration.getTables().add(getOrderTableRuleConfiguration());
//设置数据库分库规则
configuration.setDefaultDatabaseShardingStrategy(
new StandardShardingStrategyConfiguration
("user_id", "db-inline"));
Properties properties = new Properties();
properties.setProperty("algorithm-expression", "ds${user_id%2}");
//设置分库策略
configuration.getShardingAlgorithms().
put("db-inline", new ShardingSphereAlgorithmConfiguration("INLINE", properties));
//设置表的分片规则(数据的水平拆分)
configuration.setDefaultTableShardingStrategy(new StandardShardingStrategyConfiguration
("order_id", "order-inline"));
//设置分表策略
Properties props = new Properties();
props.setProperty("algorithm-expression", "t_order_${order_id%2}");
configuration.getShardingAlgorithms().put("order-inline",
new ShardingSphereAlgorithmConfiguration("INLINE", props));
//设置主键生成策略
// * UUID
// * 雪花算法
Properties idProperties = new Properties();
idProperties.setProperty("worker-id", "123");
configuration.getKeyGenerators().put("snowflake", new ShardingSphereAlgorithmConfiguration("SNOWFLAKE", idProperties));
return configuration;
}
//配置逻辑表以及表的id策略
//逻辑表不是物理存在的表
//ds0.t_order_1/ds1.t_order_0
private static ShardingTableRuleConfiguration getOrderTableRuleConfiguration() {
ShardingTableRuleConfiguration tableRuleConfiguration =
new ShardingTableRuleConfiguration("t_order", "ds${0..1}.t_order_${0..1}");
tableRuleConfiguration.setKeyGenerateStrategy(new KeyGenerateStrategyConfiguration("order_id", "snowflake"));
return tableRuleConfiguration;
}
public static DataSource getDatasource() throws SQLException {
return ShardingSphereDataSourceFactory
.createDataSource(createDataSourceMap(), Collections.singleton(createShardingRuleConfiguration()), new Properties());
}
}
6. 测试
测试之前,请先查看对应数据库有没有创建,如果不该代码的话,应该创建shard01和shard02两个数据库。
使用Sharding-JDBC代理的datasource实现数据的分库分表。
public class ExampleMain {
public static void main(String[] args) throws SQLException {
//被Sharding-JDBC代理的datasource
DataSource dataSource = ShardingDatabaseAndTableConfiguration.getDatasource();
ExampleService exampleService = new OrderServiceImpl(dataSource);
exampleService.initEnvironment();
exampleService.processSuccess();
}
}
运行之后,可以到数据库中看相应的效果。
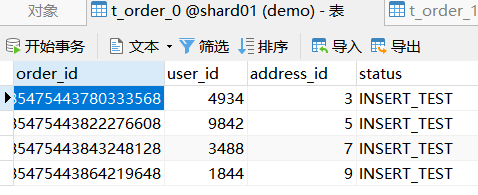
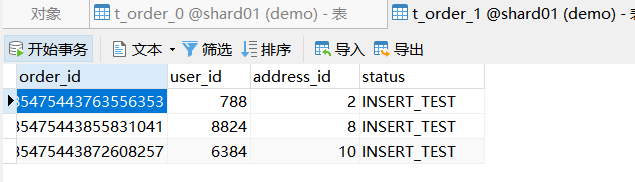
7. 项目地址
https://gitee.com/cl1429745331/sharding-jdbc-demo
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/16738.html

