
1. 生产者
前面我们说Message Queue是用来做横向扩展,生产者利用队列可以实现消息的负载和平均分布。那什么时候会发到那个队列呢?
1.1 消息发送规则
从Producer的send方法开始追踪,在DefaultMQProducer的select方法会选择要发送的Queue:
public MessageQueue selectOneMessageQueue(TopicPublishInfo tpInfo, String lastBrokerName) {
return this.mqFaultStrategy.selectOneMessageQueue(tpInfo, lastBrokerName);
}
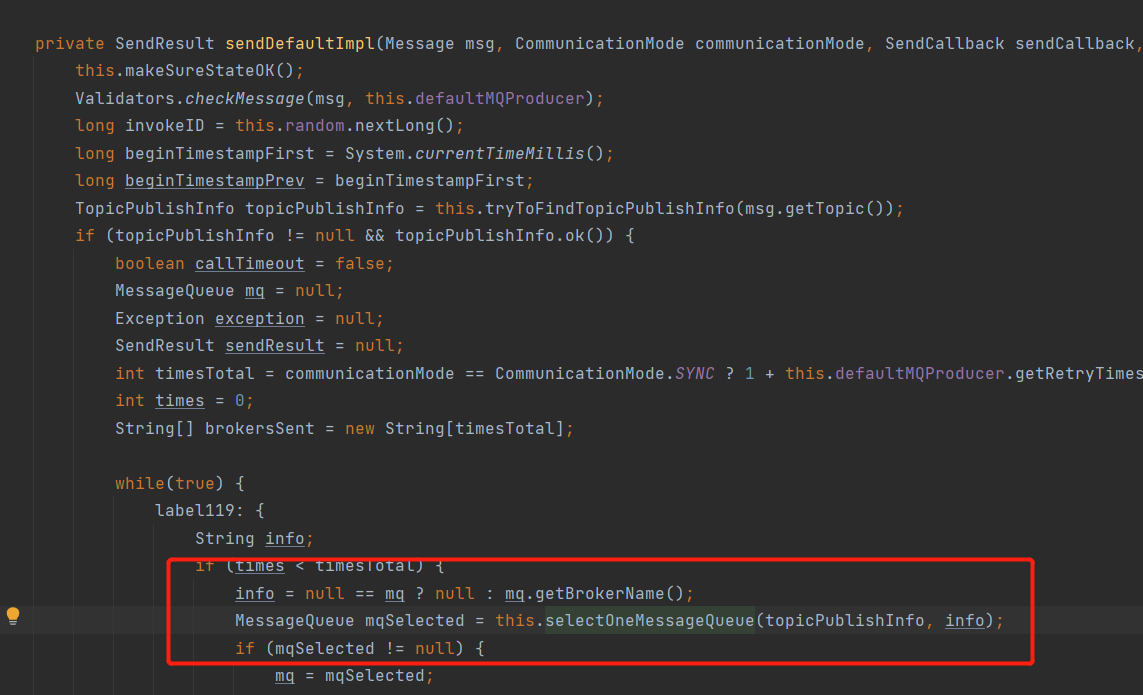

调用的是mqFaultStrategy的选择队列的方法,这个是MQ负载均衡的核心类。
MessageQueueSelector有三个实现类:
- SelectMessageQueueByHash(默认)︰它是一种不断自增、轮询的方式。
- SelectMessageQueueByRandom:随机选择一个队列。
- SelectMessageQueueByMachineRoom:返回空,没有实现。
除了上面自带的策略,也可以自定义MessageQueueSelector,作为参数传进去:
SendResult sendResult = producer.send(msg, new MessageQueueSelector() {
@Override
public MessageQueue select(List<MessageQueue> mqs, Message msg, Object arg) {
Integer id = (Integer) arg;
int index = id % mqs.size();
return mqs.get(index);
}
}, orderId);
1.2 顺序消息
顺序消息的场景:一个客户先提交了一笔订单,订单号1688,然后支付,后面又发起了退款,产生了三条消息:一条提交订单的消息,一条支付的消息,一条退款的消息。
这三笔消息到达消费者的顺序,肯定要跟生产者产生消息的顺序一致。不然,没有订单,不可能付款;没有付款,是不可能退款的。
在RPC调用的场景中我们不用考虑有序性的问题,本来代码中调用就是有序的。而消息中间件经过了Broker的转发,而且可能出现多个消费者并发消费,就会导致乱序的问题。
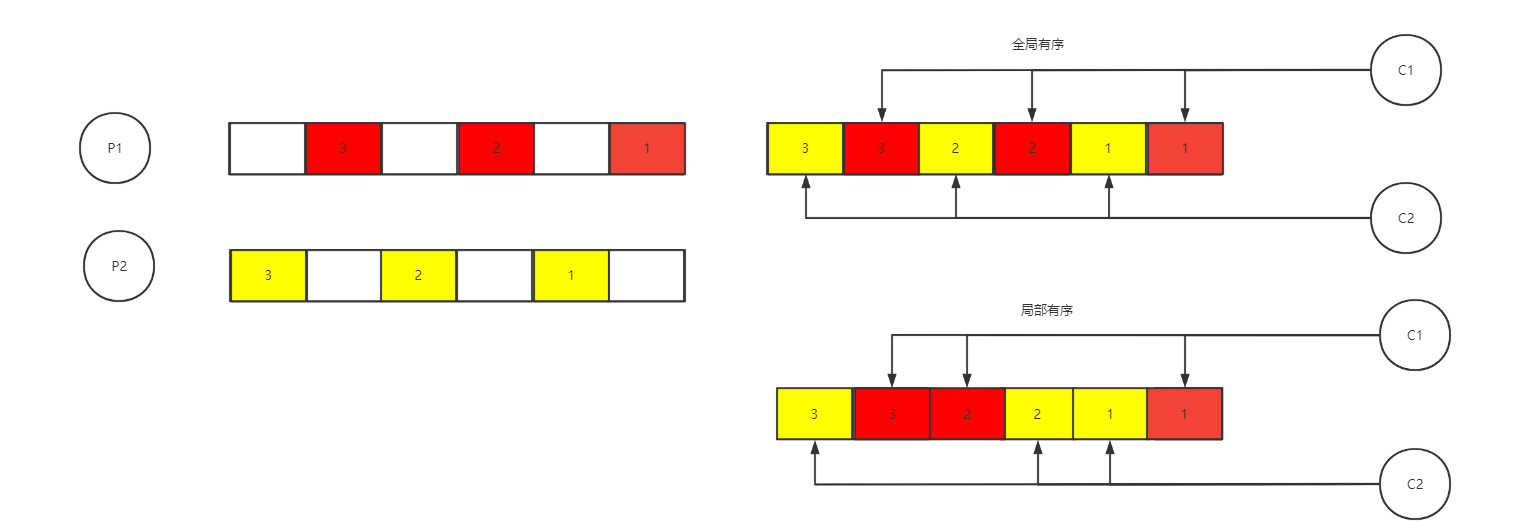
这里我们先区分一个概念,全局有序和局部有序。全局有序就是不管有几个生产者,在服务端怎么写入,有几个消费者,消费的顺序跟生产的顺序都是一致的。
全局有序(或者叫严格有序)的实现比较麻烦,而且即使实现了,也会对MQ的性能产生很大的影响。所以我们这里说的顺序消息其实是局部有序。
比如不同的颜色表示不同的订单相关的消息,只要同一个订单相关的信息在消费的时候是有序的可以了。
要保证消息有序,要分成几个环节分析:
1、生产者发送消息的时候,到达Broker应该是有序的。所以对于生产者,不能使用多线程异步发送,而是顺序发送。
2、写入 Broker的时候,应该是顺序写入的。也就是相同主题的消息应该集中写入,选择同一个queue,而不是分散写入。
3、消费者消费的时候只能有一个线程。否则由于消费的速率不同,有可能出现记录到数据库的时候无序。
RocketMQ的顺序是怎么实现的呢?
-
首先是生产者发送消息,是单线程的。
可以跟踪producer的send方法,在DefaultMQProducerimpl类send方法里面有一个默认的参数:
CommunicationMode.SYNC这表示消息是同步发送的,生产者需要等待Broker的响应。
最终其实是调用了MQClientAPIImpl的sendMessageSync方法,入口为sendKernelImpl方法。
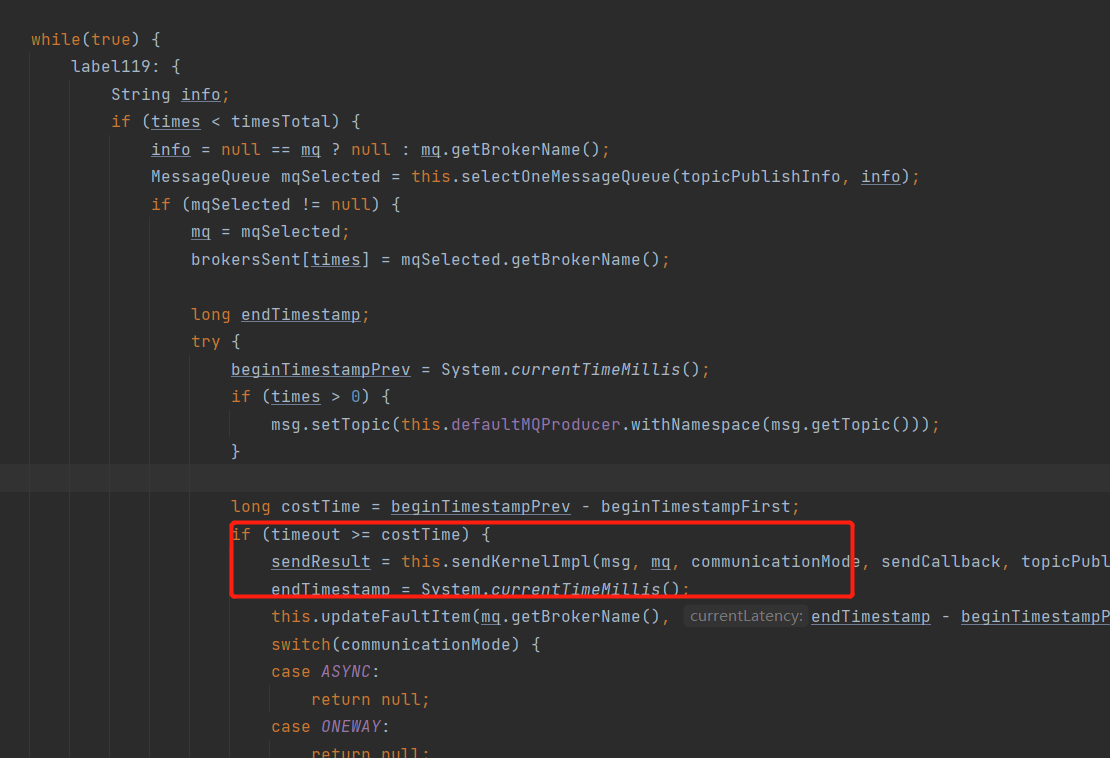
生产者收到Broker的成功的Reponse才算消息发送成功。
-
其次是消费者需要路由到相同的queue(同一队列才能实现先进先出):
生产者怎么控制队列的选择?通过MessageUQueueSelector,默认是用Hashkey选择。
Spring boot 的源码跟着跟着你就会发现orderly不见了,其实是传了一个hashkey进去,只要大家使用同一个hashkey,那么他们就会选择同一个队列。
this.producer.sendOneway(rocketMsg, this.messageQueueSelector, hashKey); -
最后在消费者,需要保证一个队列只有一个线程消费。
在Spring boot 中,consumeMode 设置为ORDERLY。Java api中,传入MessageListenerOrderly的实现类。
consumer.registerMessageListener(new MessageListenerOrderly() {}消费者在启动consumer.start()的时候会判断getMessageListenerInner的实现:
if (this.getMessageListenerInner() instanceof MessageListenerOrderly) { this.consumeOrderly = true; this.consumeMessageService = new ConsumeMessageOrderlyService(this, (MessageListenerOrderly)this.getMessageListenerInner()); } else if (this.getMessageListenerInner() instanceof MessageListenerConcurrently) { this.consumeOrderly = false; this.consumeMessageService = new ConsumeMessageConcurrentlyService(this, (MessageListenerConcurrently)this.getMessageListenerInner()); }根据Listener类型使用不同的Service,紧接着然后会启动这个Service:
this.consumeMessageService.start();在DefaultMQPushConsumerImpl pullMessage 中,将拉取到的消息放入ProcessQueue:
boolean dispatchToConsume = processQueue.putMessage(pullResult.getMsgFoundList()); DefaultMQPushConsumerImpl.this.consumeMessageService.submitConsumeRequest(pullResult.getMsgFoundList(), processQueue, pullRequest.getMessageQueue(), dispatchToConsume);然后进入ConsumeMessageOrderlyService的submitConsumeRequest方法:
public void submitConsumeRequest(List<MessageExt> msgs, ProcessQueue processQueue, MessageQueue messageQueue, boolean dispathToConsume) { if (dispathToConsume) { ConsumeMessageOrderlyService.ConsumeRequest consumeRequest = new ConsumeMessageOrderlyService.ConsumeRequest(processQueue, messageQueue); this.consumeExecutor.submit(consumeRequest); } }拉取到的消息构成了ConsumeRequest(实现了Runnable),然后放入线程池等待执行。
既然是多线程,那他的执行顺序还能保证有序吗?
我们可以回头看一下放消息的ProcessQueue,他是用TreeMap来存放消息的:
private final TreeMap<Long, MessageExt> msgTreeMap = new TreeMap();TreeMap是红黑树实现的,自平衡的二叉树。因为key是当前消息的offset,消息是按照offset排序的。
再看ConsumeRequest的run方法:
Object objLock = ConsumeMessageOrderlyService.this.messageQueueLock.fetchLockObject(this.messageQueue); synchronized(objLock) {因为只有一个队列,而消费的时候必须加上锁,RocketMQ顺序消息消费会将队列锁定,当队列获取锁之后才能进行消费,所以能够实现有序消费。
1.3 事务消息
https://rocketmq.apache.org/rocketmq/the-design-of-transactional-message/
随着应用的拆分,从单体架构变成分布式架构,每个服务或者模块也有了自己的数据库。一个业务流程的完成需要经过多次的接口调用或者多条MQ消息的发送。
举个例子,在一笔贷款流程中,提单系统登记了本地的数据库,资金系统和放款系统必须也要产生相应的记录。这个时候,作为消息生产者的提单系统,不仅要保证本地数据库记录是成功的,还要关心发出去的消息是否被成功Broker接收。也就是要么都成功要么都失败。
问题来了,如果是多个DML的操作,数据库的本地事务是可以保证原子性的(通过undo log)。但是一个本地数据库的操作,一个发送MQ的操作,怎么把他们两个放在—个逻辑单元里面执行呢?
我们来分析一下情况,如果先发送MQ消息,再操作本地数据库。第一步失败和两个都成功就不说了,这个是一致的。
关键就是第一步发送消息成功了,第二步操作本地数据库失败了,比如出现了各种数据库异常,主键重复或者字段超长。也就是下游的业务系统有最新的数据,而我自己本地数据库反而没有。
因为这条数据可能是业务异常,所以就是没办法登记到数据库。修改以后再登记也没用,这个时候跟其他系统已经登记的数据就不一样了。而发出去的消息又不可能撤回,有可能别人都已经消费了,这个叫做覆水难收。所以不能先发MQ消息。
改一下,如果先操作本地数据库,再发送MQ消息。
如果操作本地数据库成功,而发送MQ消息失败,比如网络出了问题。自己的业务系统有最新的数据,但是其他系统没有。
所以,现在我们的问题就是,怎么设计发送消息的流程,才能让这两个操作要么都成功,要么都失败呢?如果能有一个协调的方法,那先发MQ消息还是先操作数据库就不是那么重要了。
我们可不可以参照2PC两阶段提交的思想,把发送消息分成两步,然后把操作本地数据库包括在这个流程里面呢?
比如:
1、为了防止MQ关键时刻掉链子,先去试探一下。生产者先发送一条消息到Broker,把这个消息状态标记为“未确认”。
2、Broker通知生产者消息接收成功,现在你可以执行本地事务。
3、生产者执行本地事务。
第三步会有两种结果:
(a)如果本地事务执行成功,那么第四步:生产者给Broker’发送请求,把消息状态标记为“已确认”,这样的消息就可以让消费者去消费了。那就全部成功了。
(b)如果本地事务执行失败,那么第四步:生产者给Broker发送请求,把消息状态标记为“丢弃”。那就全部失败了。
看起来好像很美好,但是还有一种异常情况,第3步之后生产者迟迟没有告诉Broker本地事务是否执行成功,有可能是连接数据库超时,也可能是连接Broker超时。那Broker也不能一直等待下去吧,这个消息是确认还是丢弃,必须有个最终状态。
这个时候Broker就要主动出击了,去生产者检查本地事务是否执行成功。如果成功,确认;如果失败,丢弃。
我们设计的这个流程很完美吧? RocketMQ里面就是这么实现的。这个里面出现了两个新的概念:
1、半消息 (half message)︰暂不能投递消费者的消息,发送方已经将消息成功发送到了MQ 服务端,但是服务端未收到生产者对该消息的二次确认,此时该消息被标记成“暂不能投递”状态,处于该种状态下的消息即半消息。
2、消息回查(Message Status Check):由于网络闪断、生产者应用重启等原因,导致某条事务消息的二次确认丢失,MQ服务端通过扫描发现某条消息长期处于“半消息”时,需要主动向消息生产者询问该消息的最终状态(Commit 或是 Rollback),该过程即消息回查。
看一下整体流程:
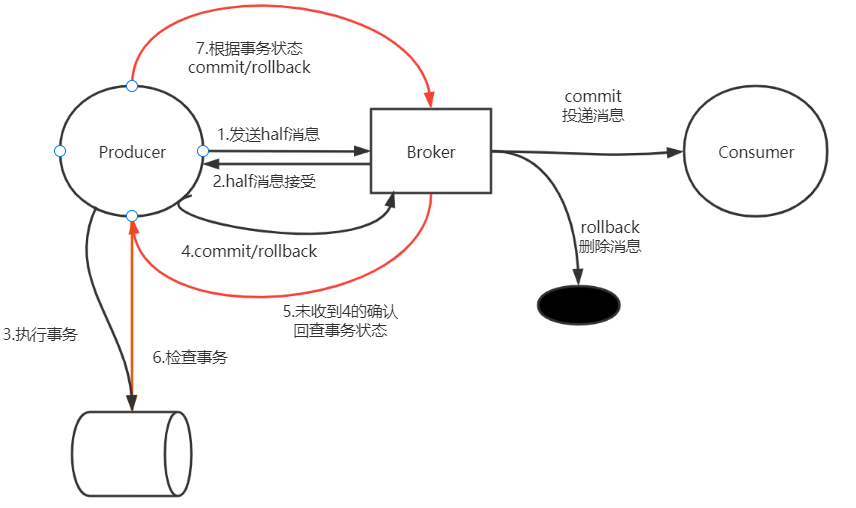
黑色线是正常的,红色的线是消息回查流程。
流程描述:
1、生产者向MQ服务端发送消息。
2、MQ服务端将消息持久化成功之后,向发送方ACK确认消息已经发送成功,此时消息为半消息。
3、发送方开始执行本地数据库事务逻辑。
4、发送方根据本地数据库事务执行结果向MQ Server提交二次确认(Commit或是Rollback),MQ Server 收到Commit 状态则将半消息标记为可投递,订阅方最终将收到该消息;MQ Server 收到Rollback 状态则删除半消息,订阅方将不会接受该消息。
5、在断网或者是应用重启的特殊情况下,上述步骤4提交的二次确认最终未到达MQ Server,经过固定时间后MQ Server 将对该消息发起消息回查。
6、发送方收到消息回查后,需要检查对应消息的本地事务执行的最终结果。
7、发送方根据检查得到的本地事务的最终状态再次提交二次确认MQ Server仍按照步骤4对半消息进行操作(commit/rollback) 。
在代码中怎么实现呢?
RocketMQ提供了一个TransactionListener接口,这个里面可以实现执行本地事务。
@Override
public LocalTransactionState executeLocalTransaction(Message msg, Object arg) {
System.out.println("收到ACK,返回结果:UNKNOW……");
return LocalTransactionState.UNKNOW;
}
executeLocalTransaction方法中执行本地事务逻辑。
这个方法会决定Broker是commit消息还是丢弃消息,所以必须return 一个状态。这个状态可以有三种:
1、COMMIT状态,表示事务消息被提交,会被正确分发给消费者
2、ROLLBACK状态,该状态表示该事务消息被回滚,因为本地事务逻辑执行失败导致。
如果既没有收到COMMIT,也没有收到ROLLBACK,可能是事务执行时间太长,或者报告Broker的时候网络出了问题呢?那就是第三种状态。
3、UNKNOW状态:表示事务消息未确定。返回UNKNOW之后,因为不确定到底事务有没有成功,Broker会主动发起对事务执行结果的查询。
checkLocalTransaction方法执行事务回查逻辑。
@Override
public LocalTransactionState checkLocalTransaction(MessageExt msg) {
System.out.println("有人没有报告事务执行状态,主动检查!");
return LocalTransactionState.COMMIT_MESSAGE;
}
默认回查次数是15次,第一次回查间隔时间是6S,后续每次间隔60S。
生产者消息发送的是TransactionMQProducer,指定listener,Spring boot 中使用rocketMQTemplate.sendMessageInTransaction。
TransactionMQProducer producer = new TransactionMQProducer("transaction_test_group_name");
1.4 延迟消息
延迟消息的场景在RabbitMQ的文章中已经说过,为什么不直接用定时任务也说了。
在RabbitMQ里面需要通过死信队列或者插件来实现。RocketMQ可以直接支持延迟消息。但是开源版本功能被阉割了,只能支持特定等级的消息。商业版本可以任意指定时间。
msg.setDelayTimeLevel(2); // 5秒钟
比如level=3代表10秒。一共支持18个等级,延时级别配置代码在MessageStoreConfig#messageDelayLevel 中:
this.messageDelayLevel = "Is 5s 10s 30s lm 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h";
Spring Boot中这样使用:
rocketMQTemplate.syncSend(topic, message,1000,3);/表示延时10秒
实现原理:
Broker端内置延迟消息处理能力,核心实现思路都是一样:将延迟消息通过一个临时存储进行暂存,到期后才投递到目标Topic中。
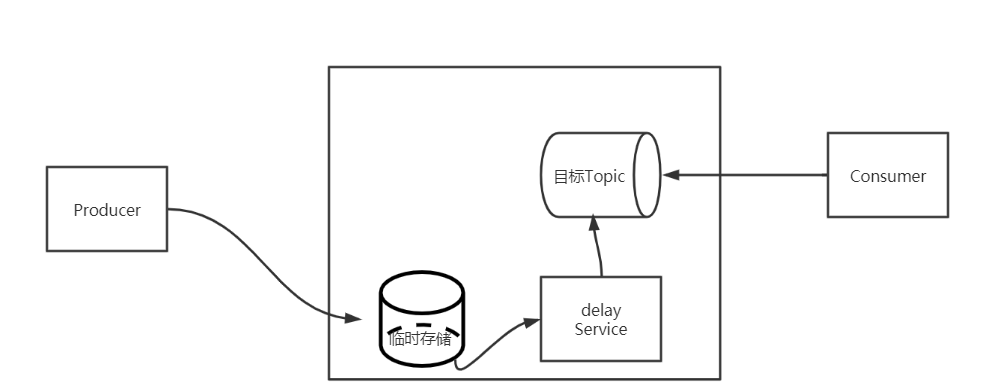
步骤说明如下:
-
producer要将一个延迟消息发送到某个Topic 中;
-
Broker判断这是一个延迟消息后,将其通过临时存储进行暂存;
-
Broker内部通过一个延迟服务(delay service)检查消息是否到期,将到期的消息投递到目标Topic 中;
-
消费者消费目标topic 中的延迟投递的消息。
临时存储和延迟服务都是在Broker 内部实现,对业务透明。当然在这个地方,消息实际是存储在commitlog,异步写入consumer queue。
事实上,RocketMQ的消息重试也是基于延迟消息来实现的。在消息消费失败的情况下,将其重新当作延迟消息传递回Broker中。
2. Broker
2.1 消息存储
2.1.1 消息存储设计理念
RocketMQ的消息存储与Kafka有所不同。既没有分区的概念,也没有按分区存储消息。
RocketMO官方对这种设计进行了解释:
http://rocketmq.apache.org/rocketmq/how-to-support-more-queues-in-rocketmq/
1、每个分区存储整个消息数据。尽管每个分区都是有序写入磁盘的,但随着并发写入分区的数量增加,从操作系统的角度来看,写入变成了随机的。
2、由于数据文件分散,很难使用Linux IO Group Commit机制(指的是一次把多个数据文件刷入磁盘。例如:批量发送3条数据,分散在3个文件里面,做不到一次刷盘。
所以RocketMQ干脆另辟蹊径,设计了一种新的文件存储方式,就是所有的Topic的所有的消息全部写在同一个文件中(这种存储方式叫集中型存储或者混合型存储),这样就能够保证绝对的顺序写。
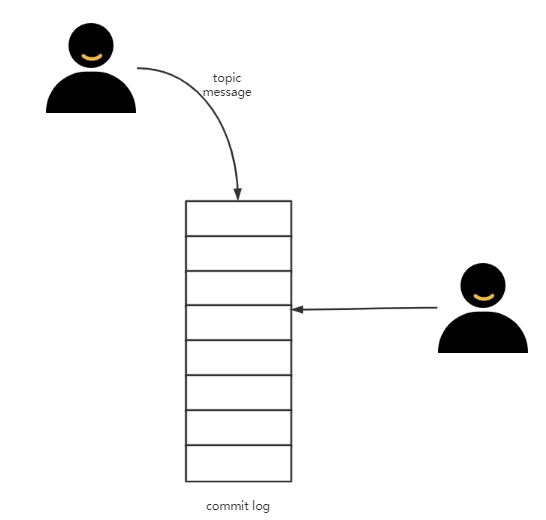
这样做的优势:
1)队列轻量化,单个队列数据量非常少。
2)对磁盘的访问串行化,完全顺序写,避免磁盘竞争,不会因为队列增加导致IOWAIT增高。
当然消费的时候就有点复杂了。
在kafka中是一个topic下面的partition有独立的文件,只要在一个topic里面找消息就OK了, kafka把这个consumer group跟topic的 offset的关系保存在一个特殊的队列中。
现在变成了:要到一个统一的巨大的commitLog种去找消息,需要遍历全部的消息,效率太低了。
怎么办呢?
如果想要每个consumer group只查找自己的topic的 offset信息,可以为每一个consumer group 把他们消费的topic的最后消费到的offset单独存储在一个地方。
这个存储消息的偏移量的对象就叫做consume queue。
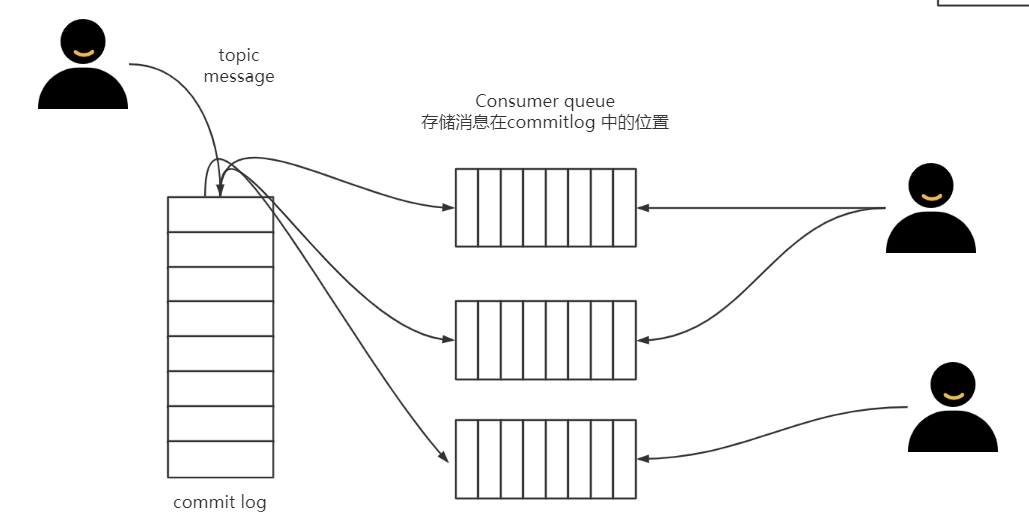
也就是说,消息在Broker存储的时候,不仅写入commitlog,同时也把在commitlog中的最新的offset(异步)写入对应的consume queue。
消费者在消费消息的时候,先从consume queue读取持久化消息的起始物理位置偏移量offset、大小size和消息Tag的HashCode值,随后再从commit log中进行读取待拉取消费消息的真正实体内容部分。
consume queue可以理解为消息的索引,它里面没有存消息。
总结:
-
写虽然完全是顺序写,但是读却变成了完全的随机读(对于commit log)。
-
读一条消息,会先读consume queue,再读commit log,增加了开销。
2.1.2 物理存储文件分析
源码方式安装,默认的存储路径在/root/store。存储路径也可以在配置文件中自定义。

| 文件名 | 描述 |
|---|---|
| checkpoint | 文件检查点,存储commitlog,consumer queue ,indexfile最后一次刷盘时间 |
| index | 消息索引文件存储目录 |
| consumerqueue | 消息消费队列存储目录 |
| config | 运行时的配置文件:消息过滤,集群,延迟消息,消费组等配置 |
2.1.2.1 commit log
commit log,一个文件集合,每个默认文件1G大小。当第一个文件写满了,第二个文件会以初始偏移量命名。比如起始偏移量1080802673,第二个文件名为00000000001080802673,以此类推。
跟kafka一样,commit log 的内容是在消费之后是不会删除的。有什么好处?
-
可以被多个consumer group重复消费。只要修改consumer group,就可以从头开始消费,每个consumer group 维护自己的 offset。
-
支持消息回溯,随时可以搜索。
2.1.2.2 consume queue
consume queue:一个Topic可以有多个,每一个文件代表一个逻辑队列,这里存放消息在commit log的偏移值以及大小和Tag属性。
从实际物理存储来说,consume queue对应每个Topic和Queueld下面的文件。单个文件由30W条数据组成,大小600万个字节(约5.72M)。当一个ConsumeQueue类型的文件写满了,则写入下一个文件。

2.1.2.3 index file
前面我们在使用API方法的时候,看到Message有一个keys参数,它是用来检索消息的。所以,如果出现了keys,服务端就会创建索引文件,以空格分割的每个关键字都会产生一个索引。
单个IndexFile可以保存2000W个索引,文件固定大小约为40OM。
索引的目的是根据关键字快速定位消息。根据关键字定位消息?那这样的索引用什么样的数据结构合适?
HashMap,没错,RocketMQ的索引是一种哈希索引。由于是哈希索引,key尽量设置为唯一不重复。
2.2 RocketMQ 存储关键技术(持久化/刷盘)
RocketMQ消息存储在磁盘上,但是还是能做到这么低的延迟和这么高的吞吐量,到底是怎么实现的呢?
首先要介绍Page Cache的概念。
CPU如果要读取或者操作磁盘上的数据,必须要把磁盘的数据加载到内存,这个是由硬件结构和访问速度的差异决定的。
这个加载的大小有一个固定的单位,叫做 Page。x86的 linux中一个标准页面大小是4KB。如果要提升磁盘访问速度,或者说尽量减少磁盘I/O,可以把访问过的Page在内存中缓存起来。这个内存的区域就叫做Page Cache。
下次处理I/O请求的时候,先到 Page Cache查找,找到了就直接操作。没找到就到磁盘查找。
Page Cache本身也会对数据文件进行预读取,对于每个文件的第一个读请求操作,系统在读入所请求页面的同时会读入紧随其后的少数几个页面。
但这里还是有一个问题。我们知道,虚拟内存分为内核空间和用户空间。Page Cache属于内核空间,用户空间访问不了,因此读取数据还需要从内核空间拷贝到用户空间缓冲区。
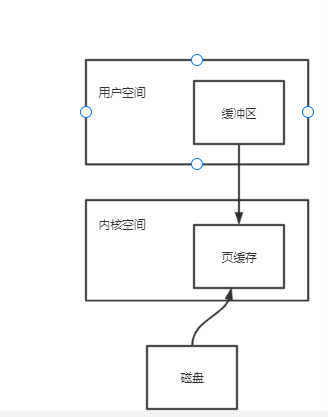
可以看到数据需要从Page Cache再经过一次拷贝程序才能访问得到。这个copy的过程会降低数据访问的速度。有什么办法可以避免从内核空间到用户空间的copy呢?
这里用到了一种零拷贝的技术。
干脆把 Page Cache的数据在用户空间中做一个地址映射,这样用户进程就可以通过指针操作直接读写Page Cache,不再需要系统调用(例如read())和内存拷贝。
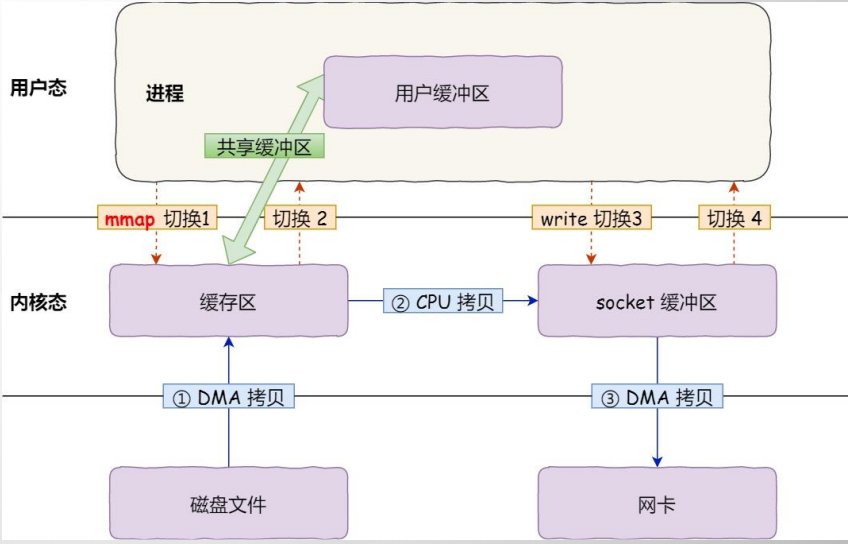
RocketMQ中具体的实现是使用mmap(内存映射),不论是CommitLog还是ConsumerQueue都采用了mmap。kafka用的是sendfile。
2.3 文件清理策略
跟kafka一样,RocketMQ中被消费过的消息是不会删除的,所以保证了文件的顺序写入。如果不清理文件的话,文件数量不断地增加,最终会导致磁盘可用空间越来越少。
首先,哪些文件需要清理?主要清除CommitLog、ConsumeQueue 的过期文件。
private void cleanFilesPeriodically() {
this.cleanCommitLogService.run();
this.cleanConsumeQueueService.run();
}
其次,什么情况下这些文件变成过期文件? 默认是超过72个小时的文件。
private int fileReservedTime = 72;
那什么时候开始删除呢?
有两种情况:
第一种情况:通过定时任务,每天凌晨4点,删除这些过期的文件。
private String deleteWhen = "04";
如果说磁盘已经快写满了,还要等到凌晨4点嘛?
第二种情况就是磁盘使用空间超过了75%,开始删除过期文件。
private int diskMaxUsedSpaceRatio = 75;
如果情况更严重:
如果磁盘空间使用率超过85%,会开始批量清理文件,不管有没有过期,直到空间充足。
如果磁盘空间使用率超过90%,会拒绝消息写入。
在DefaultMessageStore类中能找到这两个默认值的定义:
private final double diskSpaceWarningLevelRatio = Double.parseDouble(System.getProperty("rocketmq.broker.diskSpaceWarningLevelRatio", "0.90"));
private final double diskSpaceCleanForciblyRatio = Double.parseDouble(System.getProperty("rocketmq.broker.diskSpaceCleanForciblyRatio", "0.85"));
3. 消费者
在集群消费模式下(广播模式就不说啦),如果我们要提高消费者的负载能力,必然要增加消费者的数量。消费者的数量增加了,怎么做到尽量平均的消费消息呢?队列怎么分配给相应的消费者?
首先,队列的数量是固定的。比如有4个队列,假设有3个消费者,或者5个消费者,这个时候队列应该怎么分配?
消费者挂了?消费者增加了?队列又怎么分配?
3.1 消费端的负载均衡与rebalance
消费者增加的时候肯定会引起rebalance,所以从消费者启动的代码入手,我们可以在start方法中几行关键的的代码:
this.mQClientFactory = MQClientManager.getInstance().getAndCreateMQClientInstance(this.defaultMQPushConsumer, this.rpcHook);
this.mQClientFactory.start();
start方法里面就调用了rebalanceService:
这里实际上调用了rebalanceService的run方法:
public void run() {
this.log.info(this.getServiceName() + " service started");
while(!this.isStopped()) {
this.waitForRunning(waitInterval);
this.mqClientFactory.doRebalance();
}
this.log.info(this.getServiceName() + " service end");
}
也就是说,消费者启动的时候,或者有消费者挂掉的时候,默认最多20秒,就会做一次rebalance,让所有的消费者可以尽量均匀地消费队列的消息。
但是20秒钟是不是太长了?
在DefaultMQPushConsumerlmpl的start方法末尾还有一句:
this.mQClientFactory.rebalanceImmediately();
会唤醒沉睡的线程,也就是立即执行RebalanceService 的run方法。
public void rebalanceImmediately() {
this.rebalanceService.wakeup();
}
具体到底怎么rebalance的呢?从rebalanceService的run方法一直往后面跟:case CLUSTERING
AllocateMessageQueueStrategy strategy = this.allocateMessageQueueStrategy;
List allocateResult = null;
try {
allocateResult = strategy.allocate(this.consumerGroup, this.mQClientFactory.getClientId(), mqAll, cidAll);
} catch (Throwable var10) {
log.error("AllocateMessageQueueStrategy.allocate Exception. allocateMessageQueueStrategyName={}", strategy.getName(), var10);
return;
}
AllocateMessageQueueStrategy有6种实现的策略,可以指定,也可以自定义实现:
consumer.setAllocateMessageQueueStrategy();
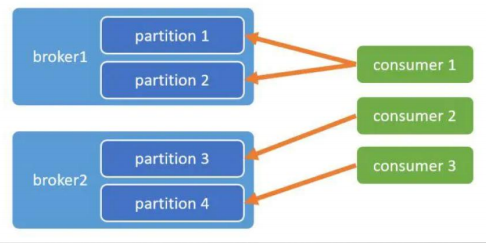
AllocateMessageQueueAveragely:连续分配(默认)
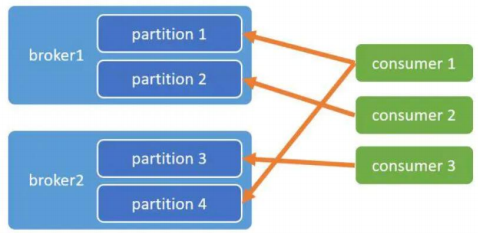
AllocateMessageQueueAveragelyByCircle:每人轮流一个
AllocateMessageQueueByConfig:通过配置
AllocateMessageQueueConsistentHash:一致性哈希
AllocateMessageQueueByMachineRoom:指定一个broker的 topic中的queue消费
AllocateMachineRoomNearby:按Broker的机房就近分配
队列的数量尽量要大于消费者的数量。
3.2 消费端重试与死信队列
先看一个业务流程中RocketMQ的使用场景。订单系统是消息的生产者,物流系统是消息的消费者。物流系统收到消费消息后需要登记数据库,生成物流记录。
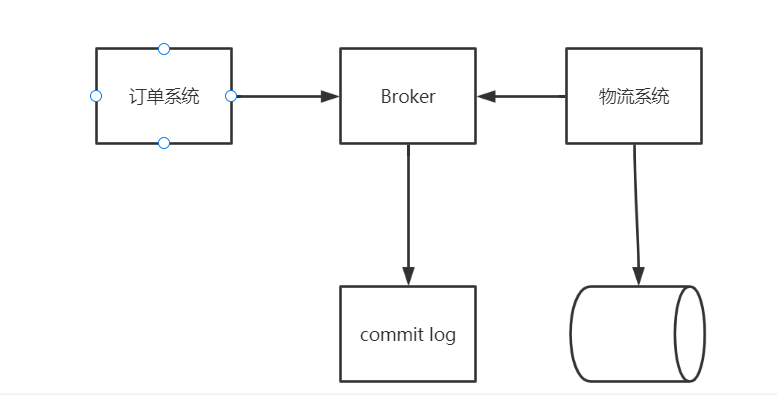
生成记录后,返回给Broker,通知消费成功,更新offset。消费者的代码可以这样写:
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs,
ConsumeConcurrentlyContext context) {
System.out.printf("%s Receive New Messages: %s %n", Thread.currentThread().getName(), msgs);
for (MessageExt msg : msgs) {
String topic = msg.getTopic();
String messageBody = "";
try {
messageBody = new String(msg.getBody(), "utf-8");
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
// 重新消费
return ConsumeConcurrentlyStatus.RECONSUME_LATER;
}
String tags = msg.getTags();
System.out.println("topic:" + topic + ",tags:" + tags + ",msg:" + messageBody);
}
// 消费成功
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
如果物流系统处理消息的过程发生异常,比如数据库不可用,或者网络出现问题,这时候返回给Broker的是RECONSUME_LATER,表示稍后重试。
这个时候消息会发回给Broker,进入到RocketMQ的里试队列中。服方端会为consumer group创建一个名字为%RETRY%开头的重试队列。
重试队列的消息过一段时间会再次发送给消费者,如果还是异常,会再次进入重试队列。重试的时间间隔会不断衰减,从10秒开始直到2个小时:10s 30s 1m 2m 3m 4m5m 6m 7m 8m 9m 10m 20m 30m 1h 2h,最多重试16次。
这个时间间隔似乎之前见过?没错,这个就是延迟消息的时间等级,从Level=3开始。也就是说重试队列是用延迟队列的功能实现的,发到对应的SCHEDULE_TOPIC_XXXX,到时间后再替换成真实的Topic,实现重试。
重试消费16次都没有成功怎么处理呢?这个时候消息就会被丢到死信队列了。
Broker 会创建一个死信队列,死信队列的名字是%DLQ%+ConsumerGroupName。
死信队列的消息最后需要人工处理,可以写一个线程,订阅%DLQ%+ConsumerGroupName,消费消息。
4. 高可用架构
在RocketMQ的高可用架构中,我们主要关注两块:主从同步和故障转移。
4.1 主从同步的意义
1、数据备份:保证了两/多台机器上的数据冗余,特别是在主从同步复制的情况下,一定程度上保证了master 出现不可恢复的故障以后,数据不丢失。
2、高可用性:即使master掉线, consumer 会自动重连到对应的slave机器,不会出现消费停滞的情况。
3、提高性能:主要表现为可分担master读的压力,当从master拉取消息,拉取消息的最大物理偏移与本地存储的最大物理偏移的差值超过一定值,会转向slave(默认brokerld=1)进行读取,减轻了master压力。
4、消费实时: master节点挂掉之后,依然可以从 slave节点读取消息,而且会选择一个副本作为新的master,保证正常消费。
4.2 数据同步
4.2.1 主从的关联
主从服务器怎么联系在一起?比如A机器上的broker-a-master和B机器上的broker-b-slave。
首先,集群的名字相同,brokerClusterName=rocket-cluster.其次,连接到相同的NameServer。
第三,在配置文件中: brokerld =0代表是 master,brokerld =1代表是slave。
4.2.2 主从同步和刷盘类型
在部署节点的时候,配置文件中设置了Broker角色和刷盘方式:
| 属性 | 值 | 含义 | |
|---|---|---|---|
| brokerRole | ASYNC_MASTER | 主从异步复制 | master写成功,返回客户端成功。拥有较低的延迟和较高的吞吐量,但是当master出现故障后,有可能造成数据丢失。 |
| SYNC_MASTER | 主从同步双写(推荐) | master和slave均写成功,才返回客户端成功。maste挂了以后可以保证数据不丢失,但是同步复制会增加数据写入延迟,降低吞吐量。 | |
| flushDiskType | ASYNC_FLUSH | 异步刷盘(默认) | 生产者发送的每一条消息并不是立即保存到磁盘,而是暂时缓存起来,然后就返回生产者成功。随后再异步的将缓存数据保存到磁盘,有两种情况:1是定期将缓存中更新的数据进行刷盘,2是当缓存中更新的数据条数达到某一设定值后进行刷盘。这种方式会存在消息丢失(在还未来得及同步到磁盘的时候宕机),但是性能很好。默认是这种模式。 |
| SYNC_FLUSH | 同步刷盘 | 生产者发送的每一条消息都在保存到磁盘成功后才返回告诉生产者成功。这种方式不会存在消息丢失的问题,但是有很大的磁盘IO开销,性能有一定影响。 |
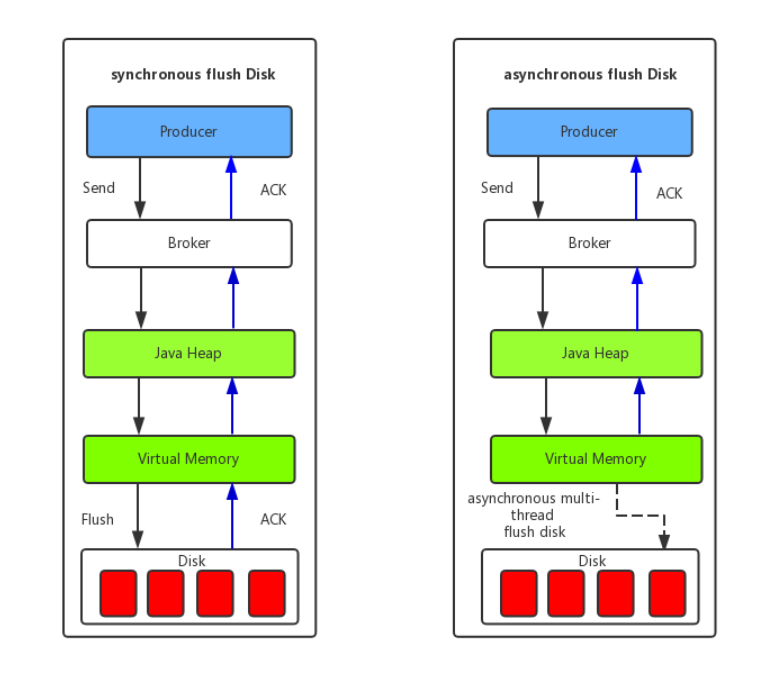
通常情况下,会把 Master和Slave 的 Broker均配置成ASYNC_FLUSH 异步刷盘方式,主从之间配置成SYNC_MASTER同步复制方式,即:异步刷盘+同步复制。
4.2.3 主从同步流程
主从同步流程:
1、从服务器主动建立TCP连接主服务器,然后每隔5s 向主服务器发送commitLog 文件最大偏移量拉取还未同步的消息;
2、主服务器开启监听端口,监听从服务器发送过来的信息,主服务器收到从服务器发过来的偏移量进行解析,并返回查找出未同步的消息给从服务器;
3、客户端收到主服务器的消息后,将这批消息写入commitLog 文件中,然后更新commitLog拉取偏移量,接着继续向主服务拉取未同步的消息。
4.3 HA与故障转移
在之前的版本中,RocketMQ只有master/slave一种部署方式,一组Broker 中有一个master,有零到多个slave, slave通过同步复制或异步复制方式去同步master的数据。master/slave部署模式,提供了一定的高可用性。
但这样的部署模式有一定缺陷。比如故障转移方面,如果主节点挂了还需要人为手动的进行重启或者切换,无法自动将一个从节点转换为主节点。
如果要实现自动故障转移,根本上要解决的问题是自动选主的问题。比如Kafka 用Zookeeper选 Controller,用类PacificA 算法选 leader、Redis哨兵用Raft协议选 Leader。
用ZK的这种方式需要依赖额外的组件,部署和运维的负担都会增加,而且ZK故障的时候会影响RocketMQ集群。
RocketMQ 2019年3月发布的4.5.0版本中,利用 Dledger技术解决了自动选主的问题。DLedger就是一个基于raft协议的commitlog存储库,也是RocketMQ实现新的高可用多副本架构的关键。它的优点是不需要引入外部组件,自动选主逻辑集成到各个节点的进程中,节点之间通过通信就可以完成选主。
Dledget架构图:
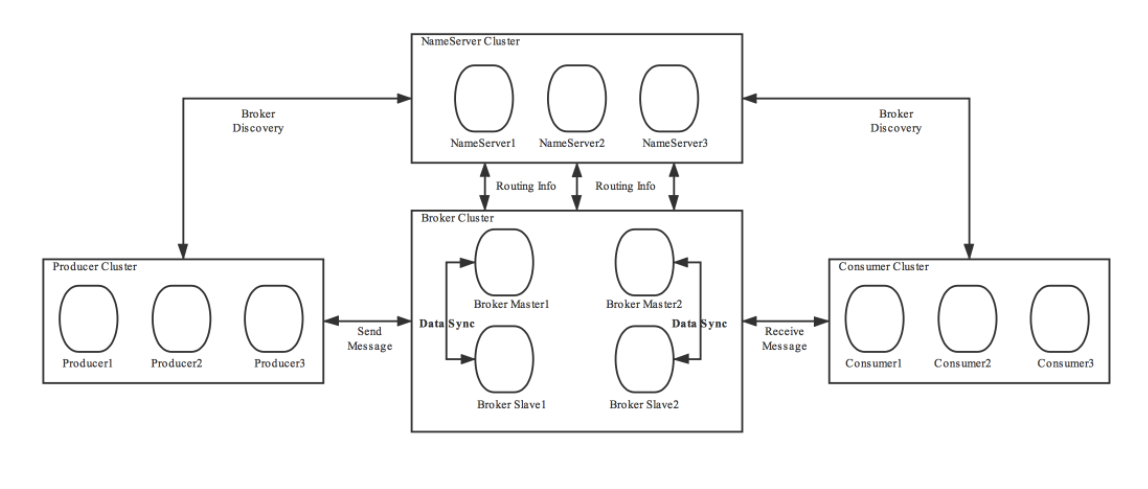
在这种情况下,commitlog是Dledger管理的,具有选主的功能。
怎么开启Dledger的功能?
enableDLegerCommitLog是否启用Dledger,即是否启用RocketMQ主从切换,默认值为false。如果需要开启主从切换,则该值需要设置为true.
需要添加以下配置:
enableDLegerCommitLog=true
dLegerGroup=RaftNode00
dLegerPeers=n0-127.0.0.1:40911;n1-127.0.0.1:40912;n2-127.0.0.1:40913
## must be unique
dLegerSelfId=n0
5. RocketMQ特性
现在市面上有这么多流行的消息中间件,RocketMQ又有什么不同之处?
一般我们会从使用、功能、性能、可用性和可靠性四个方面来衡量。其中有一些是基础特性,这里重点说一下RocketMQ比较突出的:
1、单机可以支撑上万个队列的管理—可以满足众多项目创建大量队列的需求;
2、上亿级消息堆积能力——在存储海量消息的情况下,不影响收发性能;
3、具有多副本容错机制——消息可靠性高,数据安全;
4、可以快速扩容缩容,有状态管理服务器——那就意味着具备了横向扩展的能力;
5、可严格保证消息的有序性——满足特定业务场景需求;
6、Consumer支持 Push和Pull两种消费模式平—更灵活(主要是Pull) ;
7、支持集群消费和广播消息——适合不同业务场景;
8、低延迟:客户端消息延迟控制在毫秒级别(从双十一的复盘情况来看,延迟在1ms以内的消息比例99.6%;延迟在10ms 以内的消息占据99.996%)——效率高。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/16758.html

![[MySQL] 给root用户设置权限](https://www.bmabk.com/wp-content/uploads/2022/05/post-loading-480x300.gif)