
一、关于集合的背景概况
1、为什么会产生集合?
集合可以类比到数组,都是储存多个数据的容器。
数组:长度不可变,在定义时就已经指定其长度(巴士)
集合:长度可变(火车,可以加车厢)
所以,在使用层面上来说,使用集合会比使用数组更加便利。
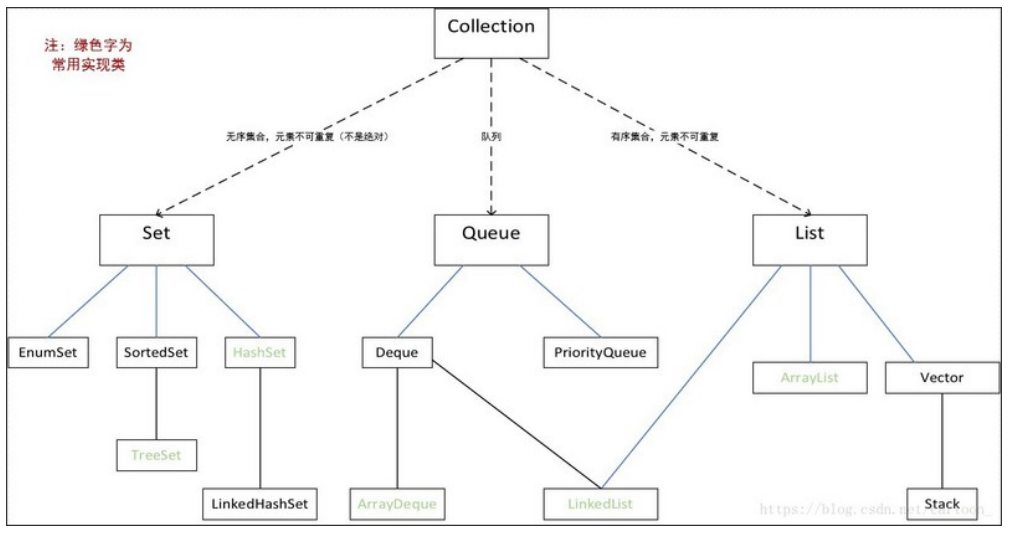
2、集合类概述
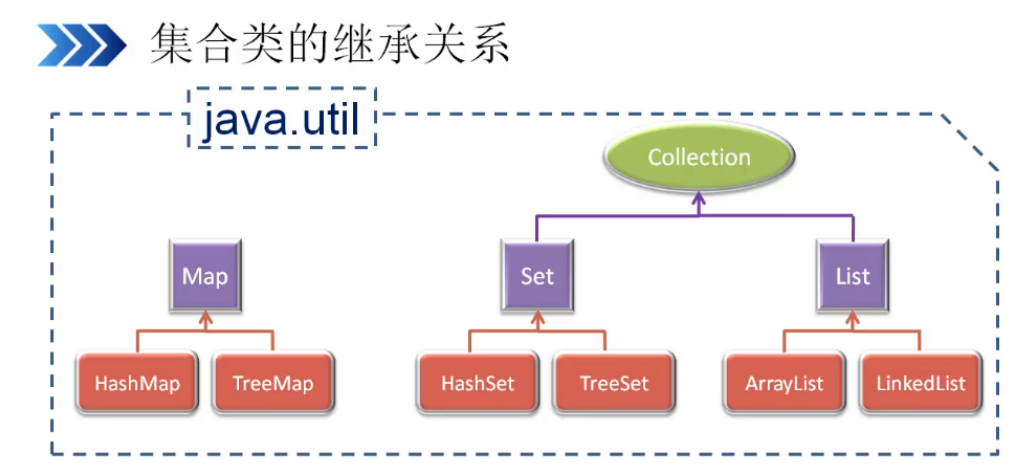

说明:
Collection是List和Set的父接口
List和Set同样也是接口
List常用的实现类:ArrayList和LinkedList
Set常用的实现类:HashSet和TreeSet
Map常用的实现类:HashMap和TreeMap
小知识:
Collection(集合名称) Collections(操作集合的工具类)
Array(数组名称) Arrays(操作数组的工具类)
说明:
首先,我们必须明确一点,以下所谈有序和无序不是指集合中的排序,而是指是否按照元素添加的顺序来存储对象。
二、List集合
List集合的特点:有序,可以有重复的元素。
常用实现类:ArrayList和LinkedList
1、ArrayList和LinkedList对比
(1)ArrayList集合
具有数组结构的list集合,有下标,可以通过下标查找、删除、修改、添加集合中的元素,下标和数组一样从0开始。
与数组对比: ArrayList集合的长度是可以改变的,添加元素和删除元素是不需要手动扩容和缩容的。
(2)LinkedList集合
双向链表结构,没有下标。
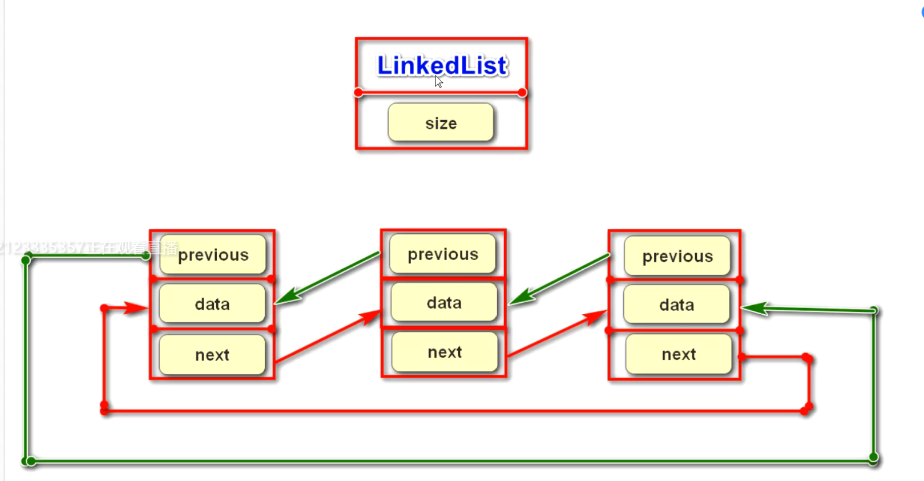
说明: 对于LinkedList集合中的一个元素,除了存放data信息,还存放着上一个元素以及下一个元素的地址信息。
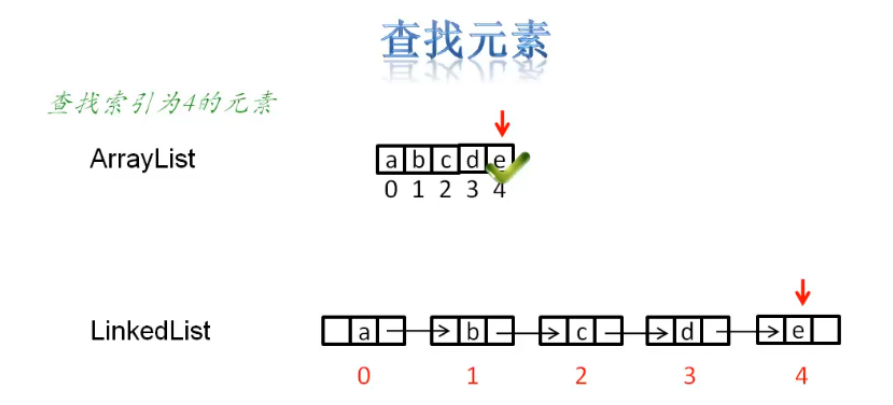
(3)从查询角度看
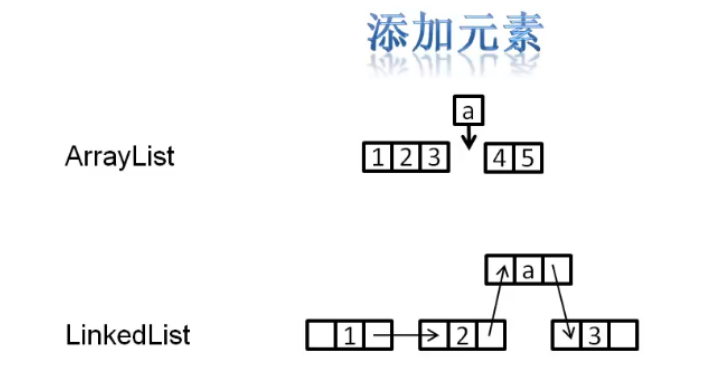
(4)从修改角度看
(5) ArrayList必须是连续的内存空间,LinkedList不需要连续的内存空间。
综上所述:
查询方面:
ArrayList有下标,可以根据下标直接获取元素。
LinkedList没有下标,获取元素需要前后遍历 。
修改方面:
ArrayList删除和添加元素的机制类似于数组,效率慢。
LinkedList删除和添加元素,只需要断开指定的连接,在断开的地方添加或者修改元素、修改地址信息即可,相对ArrayList要快。
2、List集合常用方法
1、添加元素
集合名.add(o);
2、获取集合长度
集合名.size();
3、获取元素(通过下标)
集合名.get(index);
4、删除元素
集合名.remove(index);
remove的重载方法:

5、修改元素
集合名.set(index, o);
6、添加元素
例如:在下标为1的位置上插入
集合名.add(index,o);
以上,不管是ArrayList还是LinkedList集合都适合用,
后面会列举一些LinkedList集合特有的方法。
3、ArrayList集合遍历
for以及foreach的遍历方式省略不写。
(1)迭代器遍历
原理:
当获取到对应集合的迭代器时,光标指在集合最开始的那个元素,借助迭代器名.hasNext() 来判断是否有下一个元素,如果有则会返回true,没有则会返回false,即已经取到迭代器的末尾了。同时通过迭代器名.next() 来获取元素。
public class Test {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
list.add("123");
list.add("abc");
list.add("456");
//1、根据集合获取对应的迭代器
Iterator<String> it = list.iterator();
//2、判断后面还有无元素,如果有则输出,无则跳出循环
while(it.hasNext()) {
System.out.println(it.next());
}
}
}
(2)lambda表达式
JDK1.8之后的新特性。
演变过程复杂,所以展示其应用即可。
public class Test {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
list.add("123");
list.add("abc");
list.add("456");
System.out.println("======第一种======");
list.forEach(n->System.out.println(n));
System.out.println("======第二种======");
list.forEach(System.out::println);
}
}
4、LinkedList详解
分析: LinkedList可以看做是List的实现类,也可以看做是Queue的实现类,所以下面会介绍一下Queue。
“节点”
(1)Queue
队列:FIFO(先进先出,类似于在生活中去银行办业务)
演示代码:
Queue<String> de = new LinkedList<String>();
打开Queue类,可以看到有6个方法:
| 方法名 | 方法名 | 作用 |
|---|---|---|
| add() | offer() | 添加元素 |
| remove() | poll() | 获取头元素并删除 |
| element() | peek() | 获取头元素但不删除 |
| 可能会产生异常 | 不会产生异常 | 小区别(与底层实现有关) |
具体可以参考链接内的内容:
链接: Queue接口分析
(2)Deque
<1>双端队列
两端的元素,既能入队,也能出队。
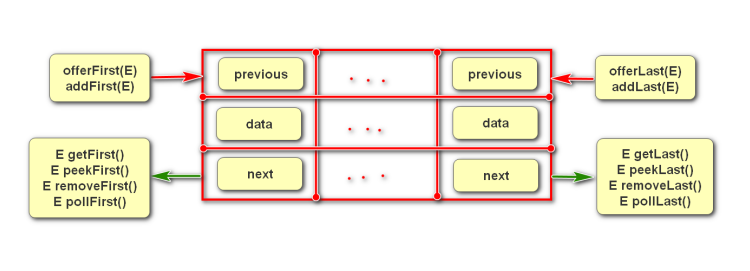
演示代码:
Deque<String> de = new LinkedList<String>();
打开Deque类,查看接口中的方法
| 方法名 | 方法名 | 作用 |
|---|---|---|
| addFirst() | offerFirst() | 添加头元素 |
| addLast() | offerLast() | 添加末尾元素 |
| removeFirst() | pollFirst() | 移除并返回此列表的第一个元素 |
| removeLast() | pollLast() | 移除并返回此列表的最后一个元素 |
| getFirst() | peekFirst() | 获取头元素但不删除 |
| getLast() | peekLast() | 获取末尾元素但不删除 |
| 可能会产生异常 | 不会产生异常(一般推荐使用此列方法) | 小区别(与底层实现有关) |
还有两个方法:
boolean remove(Object o);//删除第一次出现的元素
boolean removeFirstOccurrence(Object o);///删除最后一次出现的元素
<2>实现栈结构
解释: 如果将Deque限制为只能一端进行入队和出队,就是栈的数据结构的实现。
Stack:栈 :FILO(先进后出)。
对于栈而言,有入栈(push)和出栈(pop)。
应用: 涉及餐厅的蒸菜系统,数值转化,括号匹配校验,迷宫求解,汉诺塔递归,最多的是后面的文件处理的一些应用,比如对文件进行修改,要查看修改的日
志,先修改的先打印出来。(有待研究)
三、Set集合
Set集合的特点:无序,不可以有重复的元素。
常用实现类:HashSet和TreeSet(底层涉及到红黑树)
(1)HashSet(散列集合)
(2)TreeSet(存放有序)
底层是对集合进行了排序。
要想指定集合的存放顺序,被排序的对象需要实现Comparable接口,并且实现CompareTo()方法,自定义比较方法。
注意: TreeSet不能添加null值,因为调用到CompareTo()方法时,会出现空指针异常。
以下只对由HashSet创建的集合对象进行说明
1、说明无序:
public class Test {
public static void main(String[] args) {
Set<String> set = new HashSet<String>();
set.add("1小幸运");
set.add("2时间有泪");
set.add("3空");
set.add("4昨日青空");
System.out.println(set);
}
}
输出结果:
[3空, 4昨日青空, 2时间有泪, 1小幸运]
2、说明不可重复:
public class Test {
public static void main(String[] args) {
Set<String> set = new HashSet<String>();
set.add("1小幸运");
set.add("2时间有泪");
set.add("3空");
set.add("4昨日青空");
set.add("2时间有泪");
System.out.println(set);
}
}
输出结果:
[3空, 4昨日青空, 2时间有泪, 1小幸运]
HashSet保证元素唯一性的比较原理?
当比较两个对象是否一样时,首先比较两个对象的hashcode值:
如果hashcode值相同再调用equals()方法进行比较,如果equals()返回true则判定这两个对象相同。
如果hashcode值不相同,就直接判定两个对象不相同,不会再调用equals()方法。
3、对集合的一些操作
(1)判断set集合中是否包含某个元素
set.contains(o);
(2)删除集合中的元素
set.remove(o);
(3)清空set集合
set.clear();
(4)判断集合中是否有元素
set.isEmpty();
(5)遍历集合
(for,foreach,迭代器,lambda)
四、Map集合
Map集合:Map<K,V>
特点:无序 ,由Key(键)和Value(值)组成。
注意:一个键对应一个值(键值映射),不能有重复的键 。
PS: 键重复的情况,新的Value会覆盖旧的。
public class Test {
public static void main(String[] args) {
Map<Integer,String> map = new HashMap<Integer,String>();
//1、将元素放入Map集合中
map.put(1,"人海");
map.put(1,"远辰");
System.out.println(map);//{1=远辰}
}
}
常用的实现类:HashMap(散列的键值对)和TreeMap(树状键值对)
以下只对由HashMap创建的集合对象进行说明
(1)常用方法说明:
public class Test {
public static void main(String[] args) {
Map<Integer,String> map = new HashMap<Integer,String>();
//1、将元素放入Map集合中
map.put(1,"人海");
map.put(4,"远辰");
map.put(2,"误解");
map.put(3,"不算");
System.out.println(map);//{1=人海, 2=远辰, 3=误解, 4=不算}
//也说明了Map集合无序的特性
//2、get(Key):通过键,获取值。
System.out.println(map.get(2));//误解
//3、containsKey(key):查找map中是否存在某个键
System.out.println(map.containsKey(4));//true
//4、containsValue(o):查找map中是否存在某个值
System.out.println(map.containsValue("误解"));//true
}
}
(2)遍历map集合
<1> 获取主键(key)集合,用Set集合来接收。
why not List?
想想他们的特性,List里面的元素可以重复,但是Set里面的元素无序、不可以重复,更为符合!
public class Test {
public static void main(String[] args) {
Map<Integer,String> map = new HashMap<Integer,String>();
map.put(1,"人海");
map.put(4,"远辰");
map.put(2,"误解");
map.put(3,"不算");
//获取主键(key)集合,用Set集合来接收。
Set<Integer> set = map.keySet();
System.out.println("=====foreach====");
for(int i:set) {
//System.out.println(i);//1 2 3 4
System.out.println("<"+i+","+map.get(i)+">");
//<1,人海>
//<2,误解>
//<3,不算>
//<4,远辰>
}
System.out.println("===迭代器===");
Iterator it = set.iterator();
//判断迭代器内是否有下一个元素
while(it.hasNext()) {
Object o = it.next();
System.out.println("<"+o+","+map.get(o)+">");
//效果同上
}
}
}
<2> entrySet()遍历Map
此种方式是将map集合中的key和value整体放在set集合
相当于将map集合整体转换成了set集合
public class Test {
public static void main(String[] args) {
Map<Integer,String> map = new HashMap<Integer,String>();
map.put(1,"人海");
map.put(4,"远辰");
map.put(2,"误解");
map.put(3,"不算");
//将map集合转换成set集合
Set<Entry<Integer, String>> set = map.entrySet();
Iterator<Entry<Integer, String>> it = set.iterator();
while(it.hasNext()) {
Map.Entry<Integer, String> entry = it.next();
//System.out.println("<"+o+","+map.get(o)+">");
System.out.println("<"+entry.getKey()+","+entry.getValue()+">");
}
for(Entry entry:set) {
System.out.println(entry);
}
//1=人海
//2=误解
//3=不算
//4=远辰
}
}
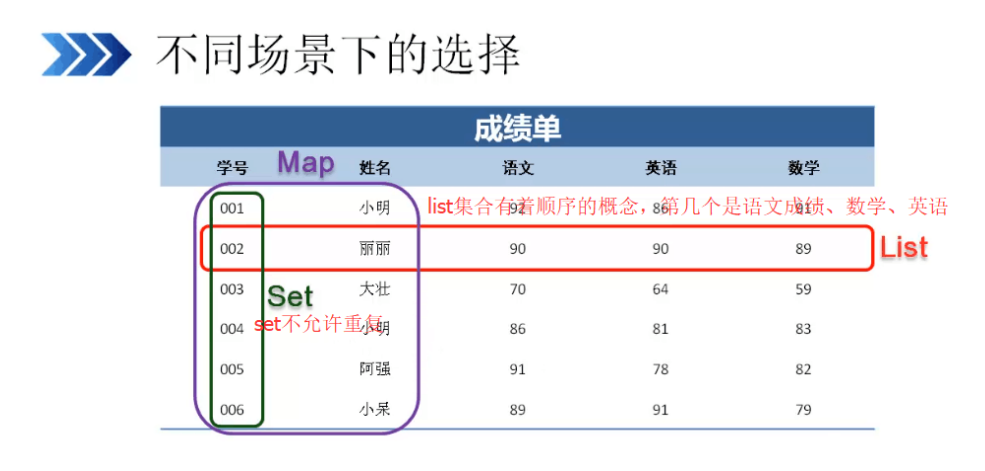
五、三种集合的侧重点
1、List关注的是索引
2、Set关注唯一性,它不允许重复
3、Map关注的是唯一的标识符(KEY)
六、Collections
1、给集合排序:
Collections.sort(集合名);
2、打乱集合的顺序
Collections.shuffle(集合名)
3、求集合的最大值
Collections.max(集合名);
4、求集合的最小值
Collections.min(集合名);
5、替换
Collections.replaceAll(集合名, oldVal, newVal);
七、提醒自己
注意去学一些算法,要弄懂底层的原理。
递归、排序等等。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/16900.html

