
前言
LRU算法其实就是叫做最近最久未使用算法,经常出现在面试的笔试题目中,更有可能是在面试的过程中让你手撕一下LRU算法。没明白其中的道理的那真的是干熬啊,没办法。所以今天就来总结一下很久之前学的LRU算法。
首先
首先我们要知道我们写这个LRU算法的时候需要用到什么样的数据类型。这里我采用的是双向链表的形式来存储。但是呢,我们知道链表的查找时O(n)的时间复杂度,而删除和插入是O(1)的时间复杂度,这对于我们查找时很不友好的。所以我们得想想能不能将查找元素的时间复杂度降低一些把他也变成O(1)的形式。当然可以,我们很容易就可以知道HashMap这一数据结构,我们可以用一个Map<Integer,Entry> 这一结构将双向链表结合起来,那么我们去查找的时候可以O(1)的时间复杂度查找。其实大家看到现在也是一团雾水,心里肯定在说“这*,到底在讲什么鬼东西~”。不着急我们看一下下面这个就明白了。
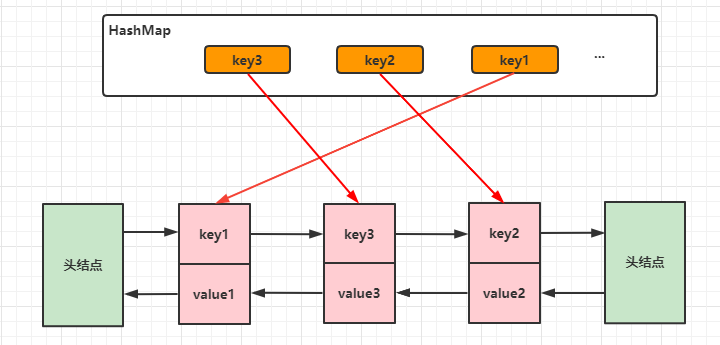
是不是现在就更加清楚了。
过程
我们知道了我们需要用到什么数据结构来存储的时候,那么我们就得知道他的一个工作原理先。LRU算法的原理就是你访问这个数据的时候你就要把这个结点放在最前面然后删除它在原来的位置。如果说你put进一个数据的时候,你要先判断你put的数据是不是已经存在于这个缓存中,如果存在那么一样的要先将这个数据放在最前面,那么自然一直没有被使用的数据就会在双向链表的最后面,那么当缓存的空间不够了那么就会删除最末尾的那个元素。这也就是这个算法的思想。
get(key) 过程
我们在获取这个数据的时候我们先要看看看是不是这个数据存不存在与这个双向链表中,如果说存在的话那么就直接返回,并将访问的数据放到双向链表的最前面,但如果说不存在的话我这边是直接返回一个-1。
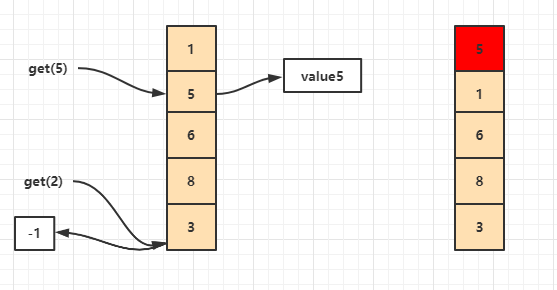
put(key,value) 过程
put过程的话就相对来说就比较繁琐一些,在put的时候你先看看是不是这个元素已经存在于缓存之中了,如果是的话那么就直接将其放到双向链表的最前面即可。接下来我们也要判断一下当前的缓存大小是不是已经到达了所规定的容量大小,若是的话那就必须将双向链表中的最后一个结点删除(这就是LRU的精髓啊~),删除完之后我们再将这个结点放入到双向链表的最前端即完成了put操作。
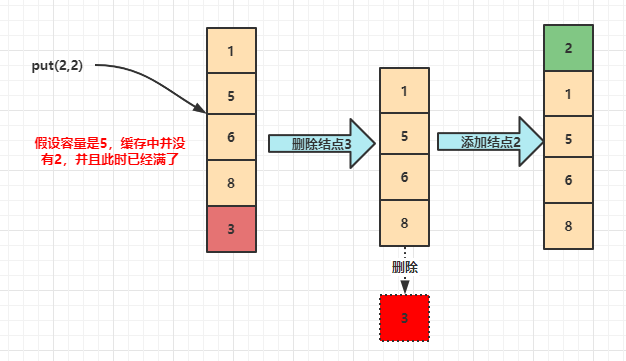
这就是LRU算法的两个get、put 操作的过程,通过画图应该是可以帮助我们更好的理解代码,接下来就是代码详解。
代码
package LinkedList;
import java.util.HashMap;
import java.util.Map;
/**
* @author: 聪明不喝牛奶
* @ProjectName: LeetCode
* 最近最久未使用算法LRU
* 采用:HashMap+Entry双向链表 来写
* @Date: 2022/4/20
*/
public class LRUCache {
Entry head,tail;
int capacity;
int size;
Map<Integer,Entry> cached;
/**
* 初始化构造函数
* @param capacity 指定缓存的初试容量大小
*/
public LRUCache(int capacity){
this.capacity = capacity;
//初始化链表
initLinkedList();
size = 0;
cached = new HashMap<>(capacity+2);
}
/**
* 如果结点不存在,返回 -1,如果存在,将结点移动到头结点,并返回结点的数据
* @param key
* @return
*/
public int get(int key){
Entry node = cached.get(key);
if (node == null){
return -1;
}
//如果结点存在那么就移动结点
moveToHead(node);
return node.value;
}
/**
* 存储新的结点,如果说要存储的key已经存在那么就直接将其放到最前面,
* 否则的话,要判断当前的容量是不是已经满了:
* 1)若满了,那么得先删除链表最后的那个结点
* 2)如果没有满的话,那么就直接将数据封装成entry并将其放在最前面
* @param key
* @param value
*/
public void put(int key,int value){
//先查一下cached中存在key,存在的话那么就直接将结点放在最前面
Entry node = cached.get(key);
if (node != null){
node.value = value;
moveToHead(node);
return;
}
//不存在,先加进去,在移除尾结点
//此时容量已满 删除尾结点
if (size == capacity){
Entry lastNode = tail.pre;
deleteNode(lastNode);
cached.remove(lastNode.key);
size --;
}
//将新值封装成结点,并加入头结点
Entry newNode = new Entry();
newNode.key = key;
newNode.value = value;
addNode(newNode);
cached.put(key,newNode);
size ++;
}
/**
* 将雪莱的结点删除掉,然后将原来的结点添加到链表的最前面
* @param node 要移动的结点
*/
private void moveToHead(Entry node) {
//首先删除原来结点的信息
deleteNode(node);
addNode(node);
}
/**
* 就是将这个结点加到头结点的后面第一个结点的前面即可
* @param node 当前结点
*/
private void addNode(Entry node) {
head.next.pre = node;
node.next = head.next;
node.pre = head;
head.next = node;
}
/**
* 就是将当前结点前一个结点next指针指向当前结点的后一个结点,当前结点的后一个结点的pre指针指向当前结点的前一个结点
* @param node 要删除的结点
*/
private void deleteNode(Entry node) {
//当前结点的前一个结点的指针指向当前结点的下一个结点
node.pre.next = node.next;
//当前结点的下一个结点的前指针指向当前结点的前一个结点
node.next.pre = node.pre;
}
/**
* 定义双向链表
*/
public static class Entry{
public Entry pre;
public Entry next;
public int key;
public int value;
public Entry(){};
public Entry(int key,int value){
this.key = key;
this.value = value;
}
}
/**
* 初始化头结点和尾结点
*/
private void initLinkedList(){
head = new Entry();
tail = new Entry();
head.next = tail;
tail.pre = head;
}
public static void main(String[] args) {
LRUCache cache = new LRUCache(2);
cache.put(1,1);
//21
cache.put(2,2);
//12
System.out.println(cache.get(1));
cache.put(3,3);
//31
System.out.println(cache.get(2));
}
}
结语
好啦,通过半天的复习总结LRU算法也算是有了更进一步的了解,希望此篇文章能够帮助到你~
搞定,收工!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/16912.html

