
why-为什么要有多线程?
单线程情况下:
在有IO操作的情况下,线程是在阻塞的,cpu什么事情也不干,直到IO操作完成
如果没有IO操作且是单核cpu,可以是单线程
多线程的情况下:
有IO操作的情况下,分配其中一条线程去等待IO操作,让cpu去执行另一个线程的计算任务,直至IO操作完成,cpu切换到原来的线程继续执行任务
在有用户交互的情况下,多线程是必须的
what-什么是线程?它和进程有什么区别?
进程
进程是资源管理的最小单位
进程拥有更多的系统权限:
- 地址空间(Address space)
- 公共变量(Global variables)
- 打开文件(Open files)
- 子进程(Child processes)
- 等待报警(Pending alarms)
- 信号处理(Signals and signal handlers)
- 账户信息(Accounting information)
线程
线程是程序执行的最小单位
线程主要是执行任务,有如下几个模块:
- 程序计数器(Program Counter)
- 寄存器(Registers)
- 栈(Stack)
- 状态(Running、Bocked、Wait等)
所以总的来说就是进程管理资源,线程执行程序,进程不能脱离线程独立工作
什么是上下文切换?
cpu在进行多线程切换的时候,每一个线程都有自己的寄存器状态需要保留,在执行切换的时候线程会保留当前的寄存器状态,当切换到另一个线程的时候,可以复用这些寄存器;直到上下文切换回来的时候,恢复保留的寄存器状态,继续执行未完成的任务
JVM Thread 和 OS Thread 的映射关系?
可以有不同的比例,比如1:1、n:1、n:m
其中JVM是自己实现了分时调度,所以是n:m多对多的关系
Java 线程状态State
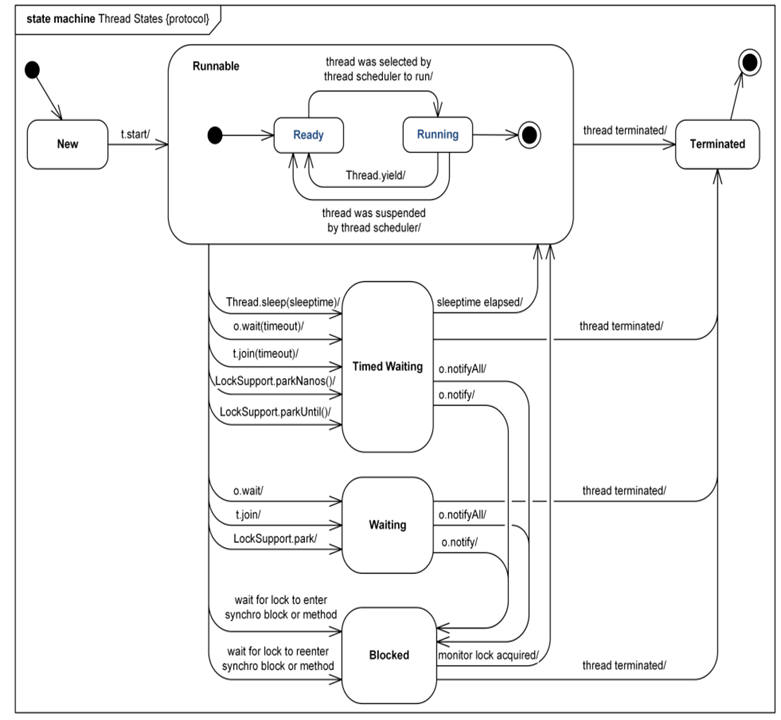
图中可以看出,State共有六种状态,分别为:
public enum State {
/**
* 尚未启动的线程的线程状态
*/
NEW,
/**
* 可运行的线程状态
* 处于runnable状态的线程正在Java虚拟机中执行,但它可能正在等待来自操作系统(如处理器)的其他资源。(Ready和Running)
*/
RUNNABLE,
/**
* 等待锁的线程阻塞状态.
* 处于阻塞状态的线程正在等待锁来进入一个同步的块/方法,或者在调用{@link Object#wait() Object.wait}之后重新进入一个同步的块/方法。
*/
BLOCKED,
/**
* 等待状态的线程
* 线程由于调用以下方法之一而处于等待状态:
* {@link Object#wait() Object.wait} with no timeout
* {@link #join() Thread.join} with no timeout
* {@link LockSupport#park() LockSupport.park}
*
* 处于等待状态的线程正在等待另一个线程执行特定的操作
* 例如,在一个对象上调用 object.wait() 的线程正在等待另一个线程在该对象上调用 object.notify()或 object.notifyall()。
* 调用thread.join()的线程正在等待指定的线程终止。
*/
WAITING,
/**
* 具有指定等待时间的等待线程的线程状态
*
* 一个线程处于定时等待状态,因为调用了下列具有指定正等待时间的方法之一:
* {@link #sleep Thread.sleep}
* {@link Object#wait(long) Object.wait} with timeout
* {@link #join(long) Thread.join} with timeout
* {@link LockSupport#parkNanos LockSupport.parkNanos}
* {@link LockSupport#parkUntil LockSupport.parkUntil}
*/
TIMED_WAITING,
/**
* 终止线程的状态
* 线程已经执行完成
*/
TERMINATED;
}
Java 并发编程面临的问题及解决方案
Race condition(竞争条件)
多个线程同时竞争同一个资源导致的同步问题
public class ExampleIncr {
private int i = 0;
private void incr() {
i++;
}
public static void main(String[] args) throws InterruptedException {
ExampleIncr self = new ExampleIncr();
int concurrent = 1200;
// 同时并发1200个线程执行方法incr()
CodeUtil.run(concurrent, self::incr);
System.out.println(self.i);
}
}
在多次执行后,发现有的时候结果是1199,这就是多个线程竞争同一个变量所导致的问题
问题原因:
在实际执行i++的过程,字节码中有如下几个步骤:
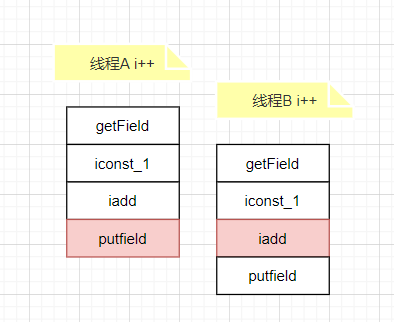
在线程A还没有将add后的i值putfield,上下文就切换到了线程B,线程B执行了add操作。
两个线程同时对一个老的i进行add,所有原来应该+2的变成只有+1,最终导致数据的偏差
解决方案:
在incr()方法中增加synchronized关键字
private synchronized void incr() {
i++;
}
Visibility(可见性)
可见性表示一个变量的值被更新后,是否能够在每个线程中可见
public class ExampleVisibility {
private boolean stop = false;
private void stop() {
this.stop = true;
}
private void run() {
while (!stop) {
// run
}
System.out.println("stop!!");
}
public static void main(String[] args) throws InterruptedException {
ExampleVisibility self = new ExampleVisibility();
new Thread(() -> {
self.run();
}).start();
Thread.sleep(1000 * 4);
new Thread(() -> {
// 停止while
self.stop();
}).start();
}
}
执行多次,你会发现有的时候无法停止while,也就是stop一直为false
问题原因:
在cpu中有多级cache,如果每次在内存中取效率不高,所有cpu中有自己的cache以提高效率
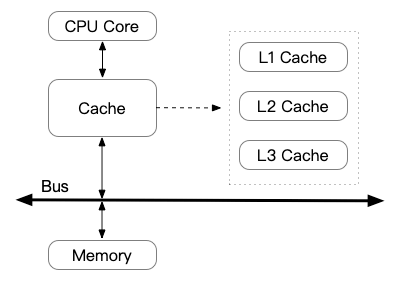
有如下两种可能原因:
- 线程将变量stop修改后没有更新到主存中
- stop在cpu一级缓存或二级缓存有缓存,当线程要读取stop变量的时候发现已存在缓存中,没有再去主存中重新读取stop变量
解决方案:
在stop变量中增加volatile关键字保证可见性
private volatile boolean stop = false;
Re-ordering(指令重排)
指令重排序是编译器和处理器为了高效对程序进行优化的手段,它只能保证程序执行的结果时正确的,但是无法保证程序的操作顺序与代码顺序一致。这在单线程中不会构成问题,但是在多线程中就会出现问题。
代码转换为机器执行的指令所经过的步骤:

流水线:
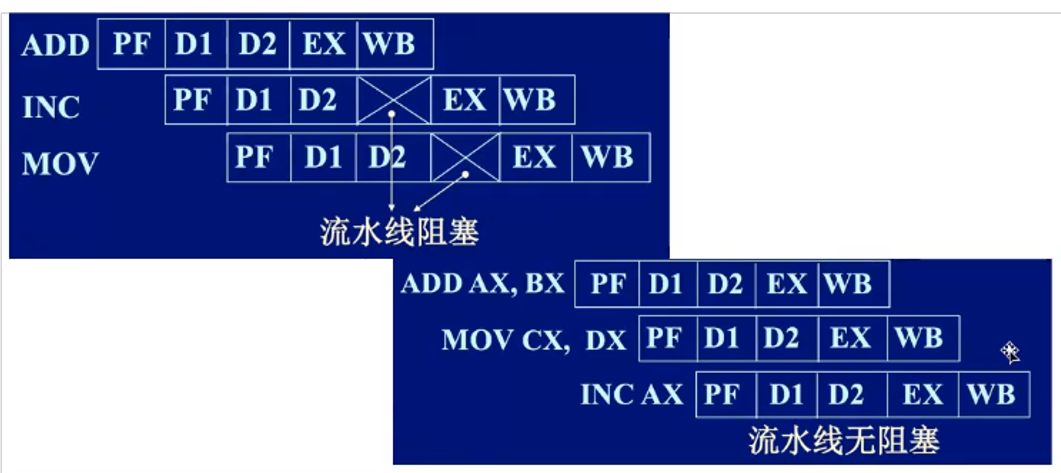
在cpu内部不同的操作是由不同的硬件来做,比如专门ADD操作的硬件、INC的硬件、MOV的硬件,它们之间同时执行多个指令,上一级处理完成流到下一级,所以叫做流水线
在未排序之前需要阻塞等待ADD指令完成写入后INC才能继续执行,INC执行后才能MOV
在重排序之后,先执行了MOV,然后INC,指令之间没有阻塞(一般的重排序不会对结果产生影响)
public class ExampleReordering {
private static int x = 0, y = 0;
private static int a = 0, b = 0;
public static void main(String[] args) throws InterruptedException {
int count = 0;
while (true) {
count++;
x = 0;
y = 0;
a = 0;
b = 0;//clear
Thread one = new Thread(new Runnable() {
public void run() {
shortWait(100000);
a = 1;
x = b;
}
});
Thread other = new Thread(new Runnable() {
public void run() {
b = 1;
y = a;
}
});
one.start();
other.start();
one.join();
other.join();
String result = "第" + count + "次 (" + x + "," + y + ")";
if (x == 0 && y == 0) {
System.err.println(result);
break;
} else {
System.out.println(result);
}
}
}
public static void shortWait(long interval) {
long start = System.nanoTime();
long end;
do {
end = System.nanoTime();
} while (start + interval >= end);
}
}
代码正确执行情况下,x和y不会同时等于0,在指令重排序的情况下,就可能发生x和y都等于0的异常情况
解决方案:
在每个变量中增加volatile关键字禁止指令重排序
private volatile static int x = 0, y = 0;
private volatile static int a = 0, b = 0;
解决并发问题的常见方法
- 无状态/不可变/copy on write
- 线程隔离(stack、thread local)
- 原子操作(Atomic*)
- 锁(ReentrantLock、)
- …
扩展
什么是happen-before
JMM可以通过happens-before关系向程序员提供跨线程的内存可见性保证(如果A线程的写操作a与B线程的读操作b之间存在happens-before关系,尽管a操作和b操作在不同的线程中执行,但JMM向程序员保证a操作将对b操作可见)。
具体的定义为:
-
如果一个操作happens-before另一个操作,那么第一个操作的执行结果将对第二个操作可见,而且第一个操作的执行顺序排在第二个操作之前。
-
两个操作之间存在happens-before关系,并不意味着Java平台的具体实现必须要按照happens-before关系指定的顺序来执行。如果重排序之后的执行结果,与按happens-before关系来执行的结果一致,那么这种重排序并不非法(也就是说,JMM允许这种重排序)。
具体的规则:
- 程序顺序规则:一个线程中的每个操作,happens-before于该线程中的任意后续操作。
- 监视器锁规则:对一个锁的解锁,happens-before于随后对这个锁的加锁。
- volatile变量规则:对一个volatile域的写,happens-before于任意后续对这个volatile域的读。
- 传递性:如果A happens-before B,且B happens-before C,那么A happens-before C。
- start()规则:如果线程A执行操作ThreadB.start()(启动线程B),那么A线程的ThreadB.start()操作happens-before于线程B中的任意操作。
- Join()规则:如果线程A执行操作ThreadB.join()并成功返回,那么线程B中的任意操作happens-before于线程A从ThreadB.join()操作成功返回。
- 程序中断规则:对线程interrupted()方法的调用先行于被中断线程的代码检测到中断时间的发生。
- 对象finalize规则:一个对象的初始化完成(构造函数执行结束)先行于发生它的finalize()方法的开始。
举例:
double pi = 3.14; // A
double r = 1.0; // B
double area = pi * r * r; // C
利用程序顺序规则(规则1)存在三个happens-before关系:
- A happens-before B
- B happens-before C
- A happens-before C
这里的第三个关系是利用传递性进行推论的。这里的第三个关系是利用传递性进行推论的。
A happens-before B,定义1要求A执行结果对B可见,并且A操作的执行顺序在B操作之前,但与此同时利用定义中的第二条,A,B操作彼此不存在数据依赖性,两个操作的执行顺序对最终结果都不会产生影响,在不改变最终结果的前提下,允许A,B两个操作重排序,即happens-before关系并不代表了最终的执行顺序。
总结
本文对多线程、进程概念做了阐述,对并发编程当前所面临的问题等进行了详细举例并提供了解决方案,我们在了解这些概念之后就能够比较好的找出并发问题。
除了文中讲到的一些问题外,还应该多注意并发编程所带来的性能问题
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/17841.html

