
为什么要有RDB和AOF?
Redis数据库基于内存储存数据,而内存的缺点就是当服务器挂掉了,数据就没了。
所以Redis需要持久化来恢复数据,而持久化的方式就有RDB和AOF
Redis 持久化
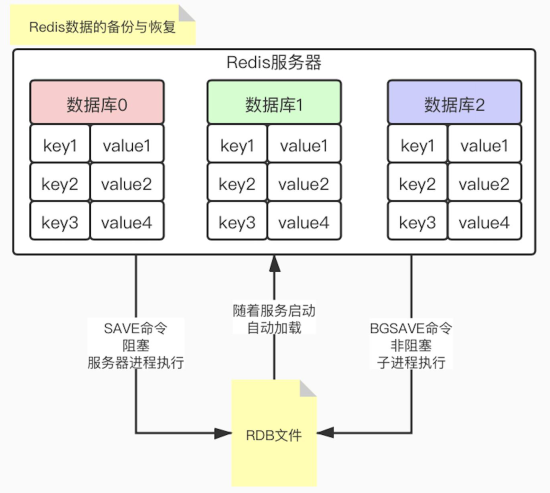
RDB 持久化(snapshotting)
把当前内存中的数据集快照写入磁盘,也就是 Snapshot 快照(数据库中所有键值对数据)。恢复时是将快照文件直接读到内存里。
自动触发:
在redis.conf配置文件中,有自动保存的默认配置:
save 900 1 // 在900s内修改或写入一次,则保存
save 300 10 // 在300s内修改10次则保存
save 60 10000 // 在60s内修改10000次则保存
手动触发:
-
SAVE
执行此命令后会阻塞当前Redis服务器,直至save操作完成,也就是将快照持久化到RDB文件中为止
显而易见,缺点就是会阻塞,接下来的第二种方式就能解决 -
BGSAVE
开启一个子进程在后台异步执行快照操作,快照同时可以继续响应客户端请求。
其中在fork()子进程的时候会阻塞,但时间很短,子进程完成RDB持久化后会自动结束
RDB 数据恢复:
将备份文件(dump.rdb)移动到redis安装目录并启动服务会自动恢复此文件的数据。
Redis服务器在载入RDB文件期间会处于阻塞状态,直到数据恢复完成为止
优势:
- 不阻塞主进程:生成RDB文件时,redis主进程会fork()一个子进程来处理所有保存工作
- 恢复数据快:RDB在恢复大数据集时速度比AOF快
劣势:
- RDB无法做到实时持久化:在一定时间做一次备份,会丢失间隔时间产生的数据
- 老版本RDB文件与新版本RDB文件存在不兼容的情况
RDB 自动保存原理

saveparam如下图所示,分别有三种配置,默认是 save 300 10

dirty代表距离上一次成功执行save命令后,redis服务器进行了多少次修改(写入、删除、更新)
lastsave属性是一个时间戳,表示上一次成功执行save或bgsave命令的时间
通过dirty、lastsave两个属性+saveparams配置,可以在时间和执行修改次数两个维度来判断是否需要进行快照
AOF 持久化(Append Only File):
在RDB持久化中,有一个缺点是一定时间内做一次备份,如果服务器挂了,那么在中间的间隔时间所产生的数据将丢失。而AOF就可以解决此问题
通过记录redis的命令去记录数据库的变更,然后持久化到文件中,具体过程如下:
客户端--->Redis服务器--->执行命令--->保存被执行的命令--->AOF文件中
eg:
set str1 "123"
sadd str1 "1" "2" "3"
del str1
AOF持久化就是将这三个命令保存到AOF文件中
开启AOF方式:在redis.conf
appendonly yes
aof_buf:打开AOF开关后每次执行一个写命令,都会把写命令以请求协议格式保存到aof_buf缓冲区
aof_buf写入&同步的时机:
appendfsync always:将aof_buf里的内容写入并同步到AOF文件中。真正实时的把指令存入了磁盘。
appendfsync everysec:上次同步时间距离现在超过1秒时将aof_buf里的内容写入到AOF文件中。
appendfsync no:将aof_buf里的内容写入到AOF文件中,但是不对AOF文件进行同步操作(page_cache,没有真正写入磁盘),写入到磁盘文件的时机由操作系统决定
以上三种aof_buf写入&同步的方式效率由低到高,但数据丢失的可能性确越来越大
优势:
- 在同步方式为
appendfsync always的时候,数据是实时同步
劣势:
- 执行命令的增多,AOF越来越大,会造成空间的大量浪费,数据的加载也会越来越慢
- 多条执行命令对相同数据的添加、删除、添加重复操作,很大几率是浪费的(AOF重写可以解决)
- AOF默认同步频率是每秒一次,性能消耗大于RDB
AOF 备份、还原、同步流程
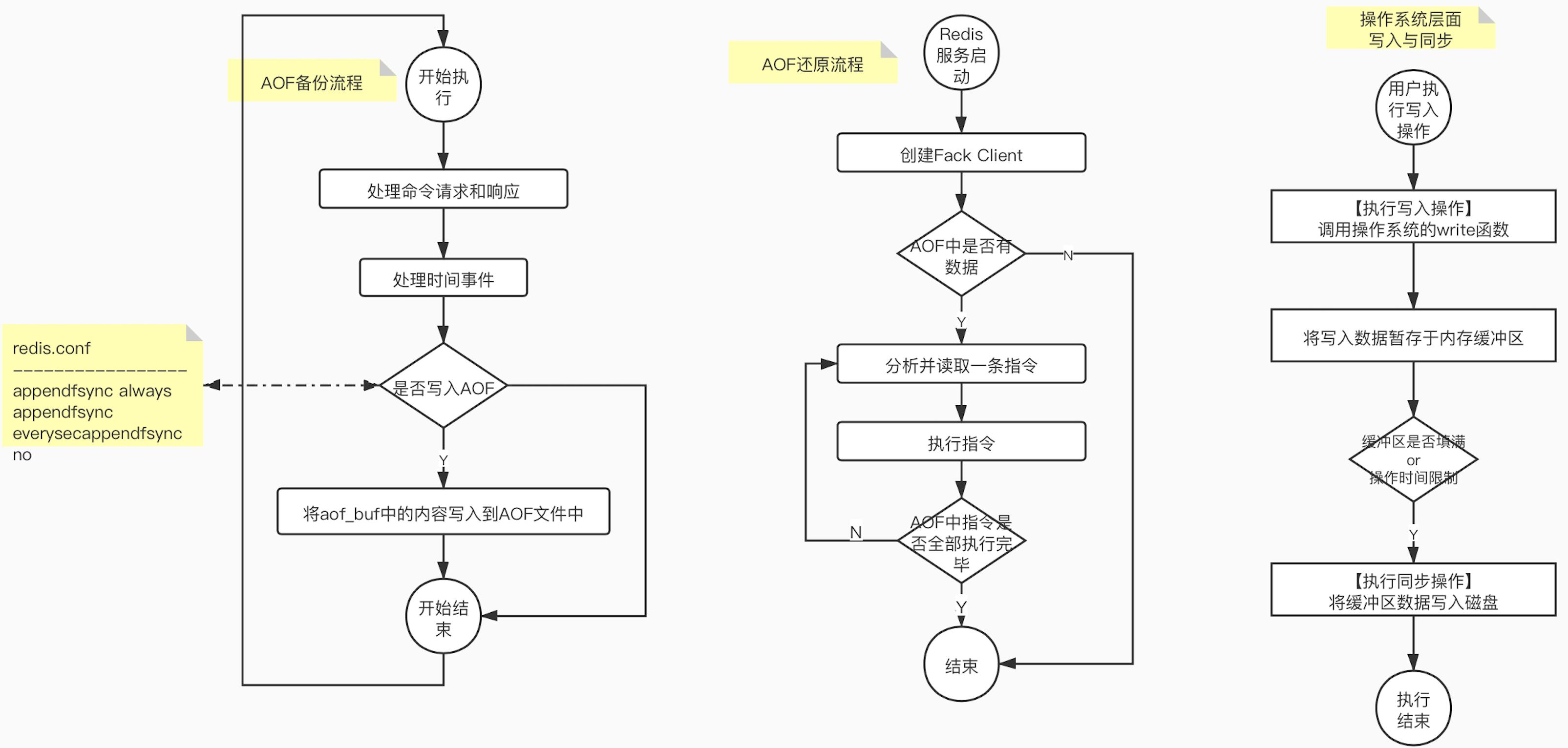
基本流程如图所示
Fack Client:伪客户端,不接受网络数据,在备份还原的时候使用
OAF重写
为了解决多条执行语句导致浪费的问题(比如执行6条语句,但可以优化为一条),这种优化叫做AOF重写
执行AOF重写的时机(redis.conf):
auto-aof-rewrite-percentage 100:表示上次重写后的体量增加了100%后执行AOF重写
auto-aof-rewrite-min-size 64mb:在AOF文件提交超过64MB后执行AOF重写
在Redis中是单进程,那么重写是谁来做?
在执行重写AOF操作的时候,实际上是fork了一个子进程进行重写,这样主进程才不会被阻塞,同样,在fork的时候会阻塞很短的时间
AOF重写基本流程:
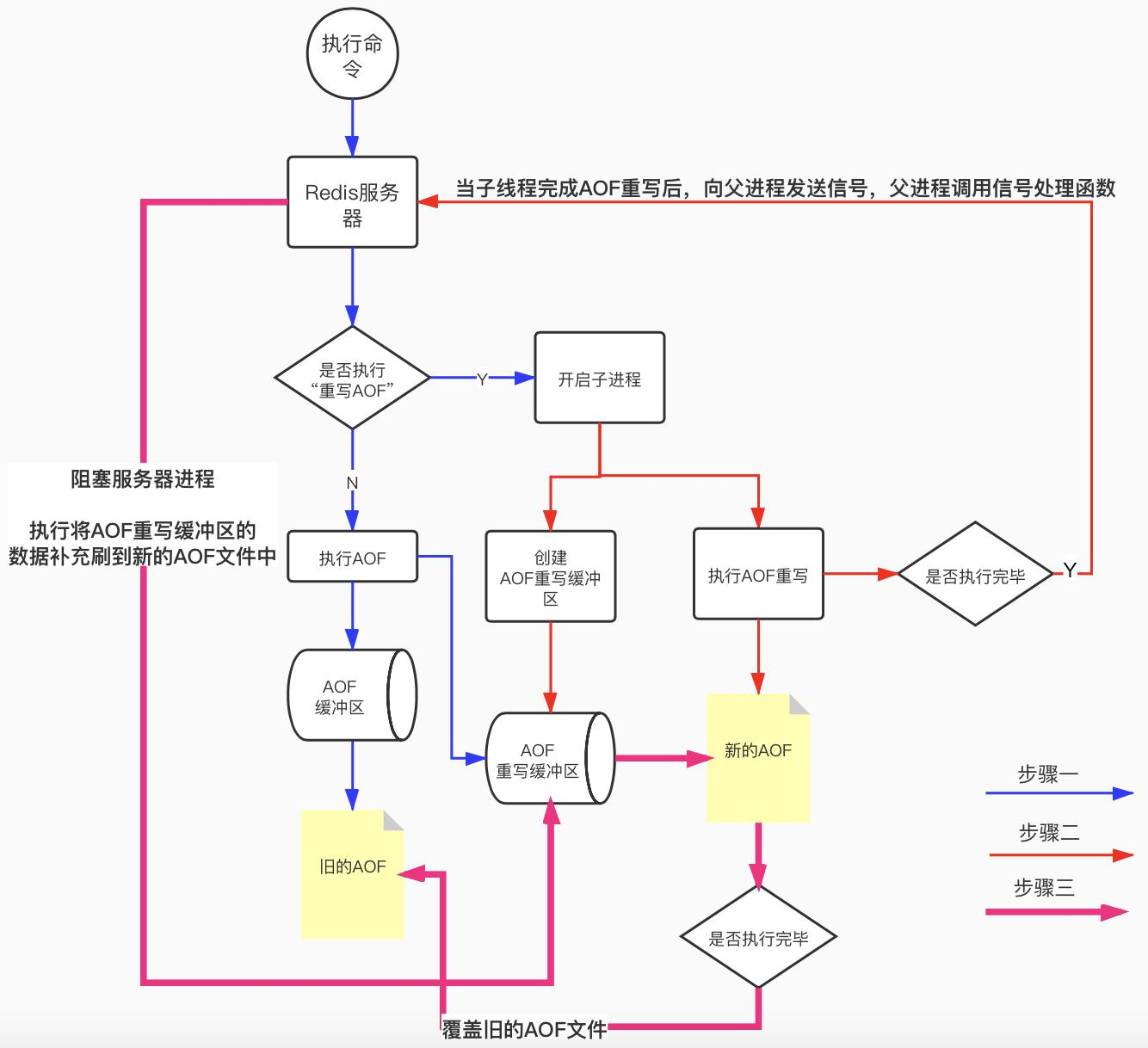
步骤一:
- 执行命令的时候会去判断是否需要AOF重写
- 如果不需要则执行AOF并将命令放入AOF缓冲区和AOF重写缓冲区
- 然后AOF会根据配置将缓冲区的文件写入到AOF文件中
步骤二:
- 如果需要重写AOF,则fork()子进程,然后创建一个AOF重写缓冲区(保存AOF重写时产生的执行命令)并同时执行AOF重写操作
- 然后将AOF重写后的数据保存到AOF文件中
- AOF文件重写完成后会发送一个信号到父进程
步骤三:
- 父进程收到信号后会调用AOF重写缓冲区的内容写入到新的AOF文件中
- AOF重写执行完成、AOF重写缓冲区数据也写到AOF文件后,会将重写后的AOF文件替换旧的AOF文件
总结
如果可以接受一小段时间的数据丢失,可以使用RDB,定时生成RDB快照,非常便于备份且恢复速度也比AOF快
否则就使用AOF重写,建议是两种结合使用。
在redis 4.0之后,新增了RDB-AOF混合持久化方式,这种方式既能够快速加载又能避免数据丢失
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/17847.html

