
索引
索引分为主键索引、唯一索引、普通索引、聚集索引、全文索引几种,而索引其实就是在无序的数据中建立索引,每次查询可以根据索引迅速查到我们想要的数据(就像字典的目录a-z一样)
-
优点
- 提高数据查找速度
- 提高group by、order by分组与排序的时间
-
缺点
- 每增加数据都需要更新索引,随者数据量增大,索引维护成本会增加
- 占用一定的存储空间,.myi后缀的文件存储的就是索引文件。
索引类型
主键索引
数据列不允许重复,不允许为NULL,可以被引用为外键,一个表只能有一个主键索引
唯一索引
数据列不允许重复,允许为NULL值,不可以被引用为外键,一个表允许多个列创建唯一索引
普通索引
基本的索引类型,没有唯一性限制,允许为NULL值,不可以被引用为外键,一个表可以有多个普通索引
主键索引、唯一索引、普通索引区别:
| 索引类型 | 数据是否允许重复 | 是否允许NULL | 是否可以当作外键 | 索引个数限制 |
|---|---|---|---|---|
| 主键索引 | 否 | 否 | 是 | 仅有一个 |
| 唯一索引 | 否 | 是 | 否 | 允许多个 |
| 普通索引 | 是 | 是 | 否 | 允许多个 |
表中可以看出约束是从高到低,对比表种内容然后依据不同场景进行使用
聚集索引(聚簇索引)
在聚集索引中,表中数据行的物理位置与逻辑值(索引和数据为同一个文件)的顺序相同,一个表中只能包含一个聚集索引,因为物理顺序只能有一个。聚集索引通常提供更快的数据访问速度。
其中 InnoDB采用的就是聚簇索引,数据和索引文件为一个idb文件,表数据文件本身就是主索引,相邻的索引临近存储。 叶节点data域保存了完整的数据记录(数据[除主键id外其他列data]+主索引[索引key:表主键id])。 叶子节点直接存储数据记录,以主键id为key,叶子节点中直接存储数据记录。(底层存储结构: frm -表定义、 ibd: innoDB数据&索引文件)
(1)如果表定义了主键,则PK就是聚集索引;
(2)如果表没有定义主键,则第一个非空唯一索引(not NULL unique)列是聚集索引;
(3)否则,InnoDB会创建一个隐藏的row-id作为聚集索引;
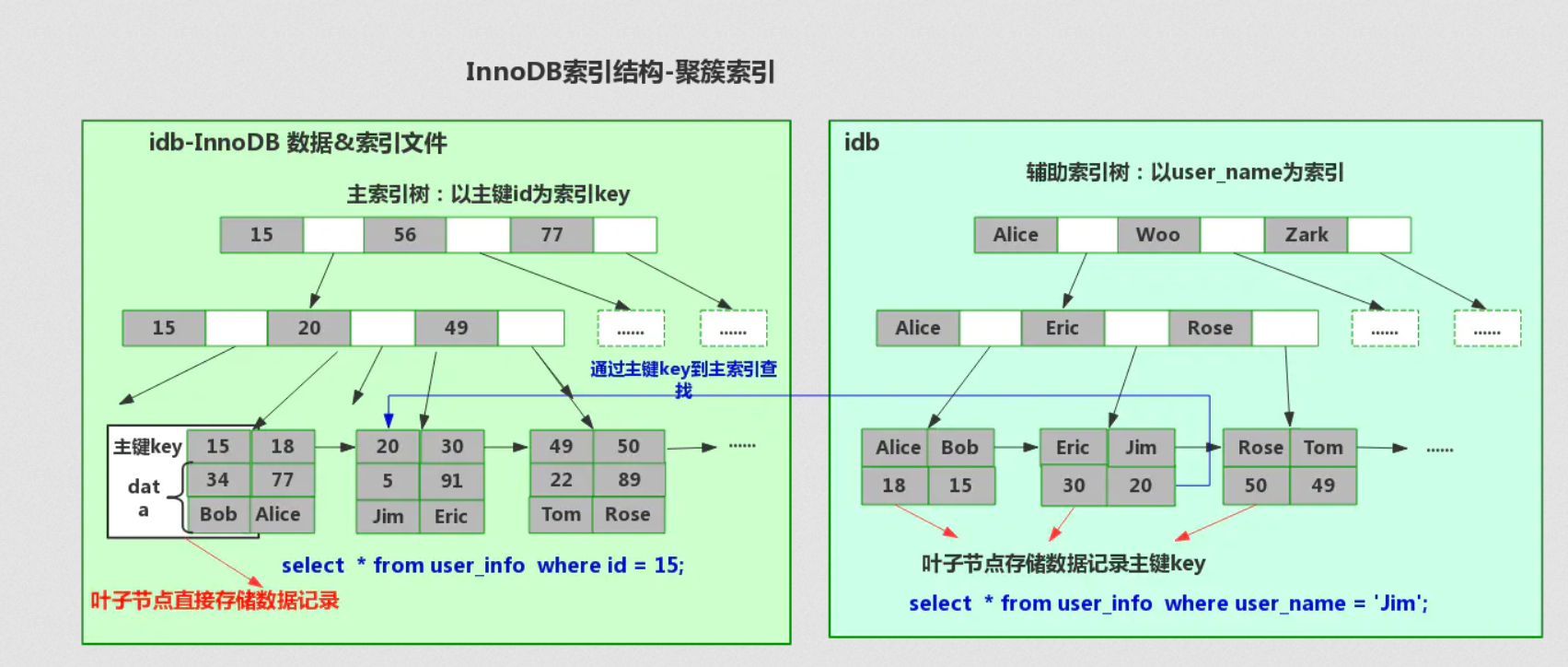
非聚簇索引
索引和数据分开的索引。
其中MyISAM底层采用的就是非聚簇索引,使用myi索引文件和myd数据文件分离,索引文件仅保存数据记录的指针地址。叶子节点data域存储指向数据记录的指针地址。(底层存储结构: frm -表定义、 myi -myisam索引、 myd-myisam数据)
覆盖索引
所谓覆盖索引就是指索引中包含了查询中的所有字段,这种情况下就不需要再进行回表查询了
MySQL 中只能使用 B-Tree 索引做覆盖索引,因为哈希索引等都不存储索引的列的值,覆盖索引对于 MyISAM 和 InnoDB 都非常有效,可以减少系统调用和数据拷贝等时间
组合索引
使用多个列来组成一个索引,比如B-Tree的方式
全文索引
主要用于海量数据的搜索,比如淘宝、京东对商品的搜索就可以建立全文索引(不可能用like模糊匹配吧),这个类型在mysql5.6开始支持InnoDB引擎的全文索引,功能没有专业搜索引擎比如solr、es丰富,如果需求简单,可以使用全文索引
适用场景:适用于海量数据的关键字模糊搜索,比如简易版的搜索引擎
索引的实现方式
B-Tree索引
InnoDB使用的是B-Tree算法,即每个叶子节点包含指向下一个叶子节点的指针,就像一个树一样
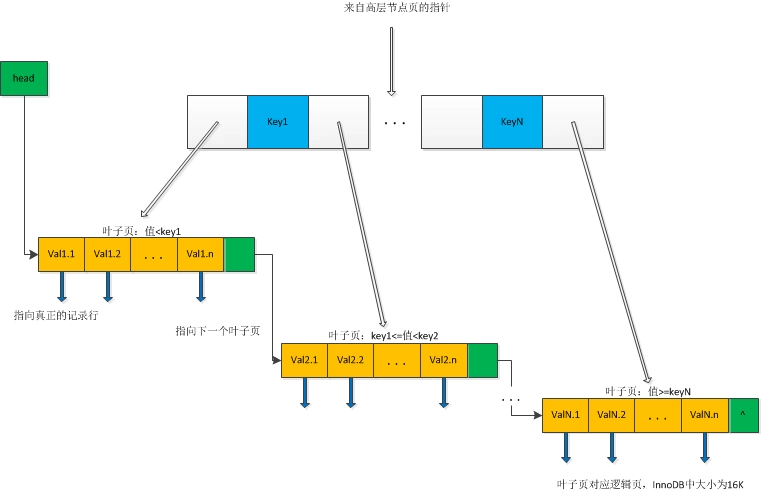
适用场景:最常用的一个索引类型,可以适用于多种场景
工作原理:B-Tree索引中,联合索引中的索引项会先根据第一个索引列进行排序,第一个索引列相同的情况下,会再按照第二个索引列进行排序,依次类推。
可以应用到B-Tree索引的情况:
- 全值匹配:查找条件和索引中的所有列相匹配
- 匹配最左前缀:查找条件只有索引中的第一列
- 匹配列前缀:比如有两个索引,一个是姓,一个是名,先找到zhang的列,然后再根据已找到的列找到名为s开头的人,也可以应用到索引
- 匹配范围值:比如查找姓在chen到zhang之间的人;或者查找姓为zhang,然后名为san到si范围的人
- 只访问索引的查询:即要查询的数据都在索引中包含,则只需要访问索引就行,无需访问数据行,比如只需要查询姓和名两列,而这两列刚好又是联合索引。这种索引被称作覆盖索引
- 索引排序:比如使用姓进行排序
无法使用到B-Tree索引的情况:
- 索引不是最左列开始查找,则无法使用索引。比如直接查找名为san的人,则无法应用到索引
- 索引不全:比如有三个字段的联合索引,条件中只有第一个、和第三个的字段条件,跳过了中间某个列,则只能使用到索引的第一列
- 如果查询中有某个列的范围查询,则该列右边的所有列都无法使用索引优化查询(范围的话没有具体的值)。
哈希索引
如果在列上建立索引,则针对每一行数据,存储引擎会根据所有的索引列计算出一个哈希码,每一个行计算出的哈希码会组成一个哈希表,同时在哈希表中存储了指向每个数据行的指针。
哈希表结构如下:

适用场景:仅作等值匹配且数据重复率低且对索引查找速度要求高的情况
可以应用到哈希索引的情况:
- 只有精确匹配全部索引行的查询条件才能利用索引
无法使用到哈希索引的情况:
- 索引中不包含任何列的值
- 索引无法应用于排序
- 不支持部分索引列匹配查找(必须使用全部索引列的查询条件才能使用哈希索引优化查询)
- 无法范围查找,只能等值比较
- 哈希冲突会影响性能:比如某个列的数据重复率非常高,则每次在找到匹配的哈希后还需要对这个哈希码的所有数据进行等值比较
其中,还有一个叫做“自适应哈希索引”,是当InnoDB注意到某些索引的使用频率很高时,会在B-Tree索引之上再建立一层哈希索引,以提高查询效率
空间数据索引(R-Tree)
空间索引可用于地理数据存储,它需要GIS相关函数的支持,由于MySQL的GIS支持并不完
善,所以该索引方式在MySQL中很少有人使用。
扩展
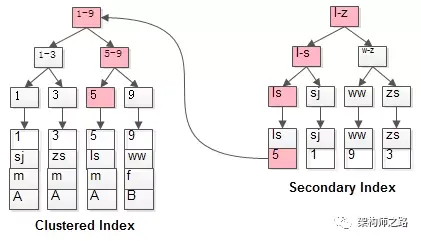
什么是回表
如果 select 所需获得列中有大量的非索引列,索引就需要到表中找到相应的列的信息,这就叫回表
比如如下例子,先使用普通索引查询除出ID,然后再去聚簇索引查询具体数据的过程就叫左做回表
如何避免回表?
使用聚集索引(主键或第一个唯一索引)就不会回表,普通索引就会回表
比如select id, name, sex from user;,将单列索引(name)升级为联合索引(name, sex),即可避免回表,因为要查询的name和sex都在索引中了
索引下推
MySQL 5.6引入了索引下推优化,可以在索引遍历过程中,对索引中包含的字段先做判断,过滤掉不符合条件的记录,减少回表字数
select * from tuser where name like '张 %' and age=10 and ismale=1;
没有索引下推:首先根据索引来查找记录,然后再根据where条件来过滤记录(回表)
有索引下推:MySQL会在取出索引的同时,判断是否可以进行where条件过滤再进行索引查询(回表)
唯一索引导致死锁
如图所示,有三个事务同时插入同一个记录,导致唯一索引冲突的过程:

死锁发生过程:
- T1时刻sessionA插入会加排他锁
- T2时刻SessionB插入同id会主键冲突,会加上共享锁
- T3时刻SessionC插入同id会主键冲突,会加上共享锁
- 这时,SessionA回滚释放排他锁,sessionB向获得排他锁,但发现sessionC有共享锁存在,B和C相互等待造成死锁
根本原因:
唯一索引导致,本质是并发请求导致一个数据重复插入或是网络抖动造成
解决方案:
- 可以使用缓存将重复请求去重,确保同时只执行一个相同sql
- 异常捕捉,mysql有死锁检测和恢复,只有一个事务会成功,只需要catch异常即可
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/17862.html

