
为什么要做分库分表?
单机存储容量、连接数、处理能力有限。当单表的数据量达到1000W+或100G+以后(MySQL8不止这个数),由于查询的维度较多,即使添加从库、优化索引也无法根本改变,这时候我们就需要考虑进行切分了,目的在于减少数据库的负担,缩短查询时间。
什么时候考虑切分?
能不切分尽量不要切分
在单机或单库、单表能够满足需求,最好不要做过度设计和过早优化。只有当数据量达到单表的瓶颈的时候,再去考虑分库分表
数据量过大,正常的运维影响到了业务访问运维是指:
- 数据库备份,如果单表数据量过大,备份需要大量的磁盘IO和网络IO。
- 对一个表进行DLL修改的时候,MySQL会所住全表,这个时间会很长,直接影响业务
- 大表频繁访问与更新,就更可能出现锁等待。将数据切分,空间换时间可以降低访问压力
- 随着业务发展,需要
对某些字段做垂直拆分:比如原本有一个user表,它有20个字段,其中有几个text字段数据多,且访问频率低,这时候可以考虑将几个访问频率低、数据量大的字段独立出来user_ext表 安全性和可用性考虑:业务之间相互影响,导致正常业务无法正常使用。可以利用垂直切分,将多个业务放到不同的数据库中,避免业务功能相互影响;利用水平切分,当一个库出现问题,不会影响到100%的用户,每一个库仅程度一部分数据,这样整体的可用性就提高了
垂直(纵向)切分
垂直切分分为垂直分库和垂直分表两种
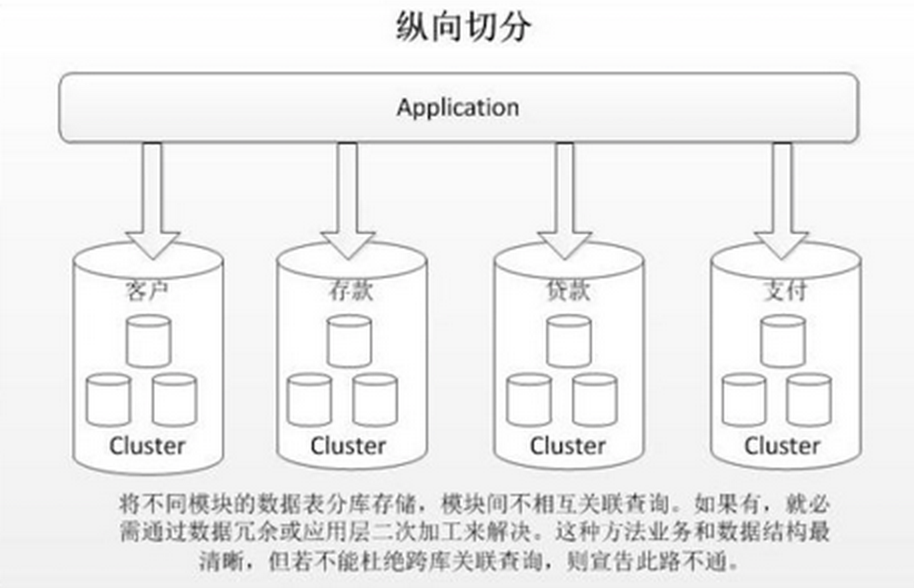
垂直分库
依据业务的耦合性进行拆分,将关联度低的不同表存储在不同的数据库。就像我们的微服务,每个微服务就是一个独立业务功能

垂直分表
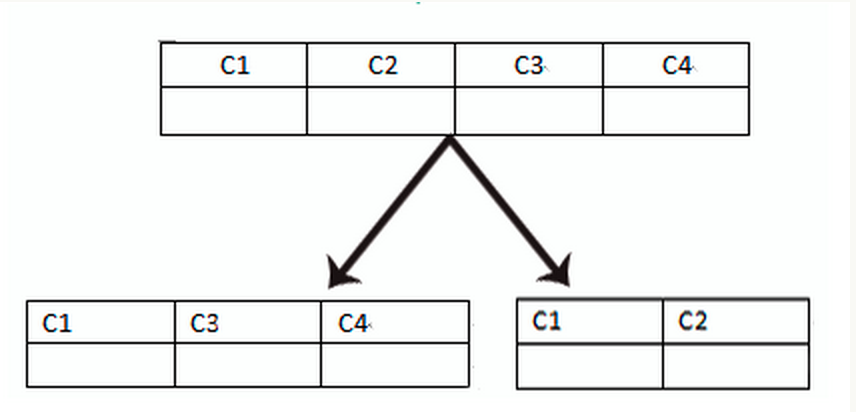
垂直分表就是将一个表中的多个数据列进行拆分到另一个表中,一般都是将比较不常用的进行拆分。比如有一个表中有100多个字段,但是常用的就10个字段,这个时候可以把剩余的90个字段独立出来为另一张表。大表拆小表更容易维护,也能够避免跨页的问题(MySQL底层是通过数据页进行存储,如果一条记录占用空间过大,就会造成跨页,造成额外的性能开销)。另一个数据库是以行为单位将数据加载到内存中,这样表中的字段少且访问频率高,同样的内存能够加载更多的数据,命中率更高、减少了磁盘IO,从而整体提升了数据库性能。
优点:
- 解决业务系统层面的耦合,每块业务更独立与清晰
- 与微服务类似,同能能够对不同业务的数据进行分级管理、维护、监控、扩展等
- 高并发的场景下,能够一定程度的提升IO、数据库连接数,解决单机硬件资源瓶颈
缺点:
- 部分表无法join,只能通过聚合的方式来解决,增加了开发复杂度
- 分布式的事务处理比单机更加复杂
无法解决单表数据量过大的问题(需要水平切分来进行解决)
水平(横向)切分
水平切分分为库内分表、分库分表两种,就是依据表内数据的逻辑关系,按照一定的条件将数据分散到多个数据库或多个表中,每个表仅包含一部分数据,从而使得单表或单库的数据量变小,提高读写、存储性能
当一个应用难以再更加细粒度的做垂直切分,或者就算切分后的数据量行数也很大,存在单库、单表读写、存储性能瓶颈,这时候就需要做水平切分
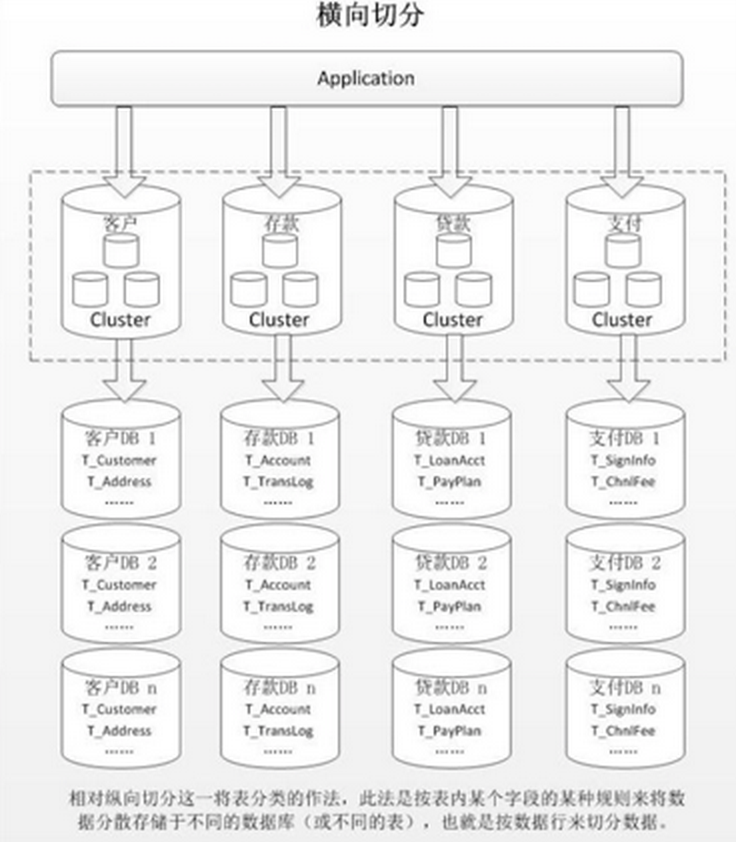
其中,如果仅仅是做库内分表,无法很好的解决问题,因为主要的瓶颈在于单机的CPU、内存、网络IO,所以最好是通过分库分表的方式来解决
优点:
不存在单库单表数据量过大的性能瓶颈,提升系统稳定性能负载能力- 应用端改造较小,不需要拆分业务模块
缺点:
- 跨分片的事务一致性难以保证
- 跨库的join关联查询性能较差
- 数据库
多次扩容和维护量极大(每次都需要重新将数据进行分散)
水平切分规则
垂直根据业务,那么水平是要根据什么?
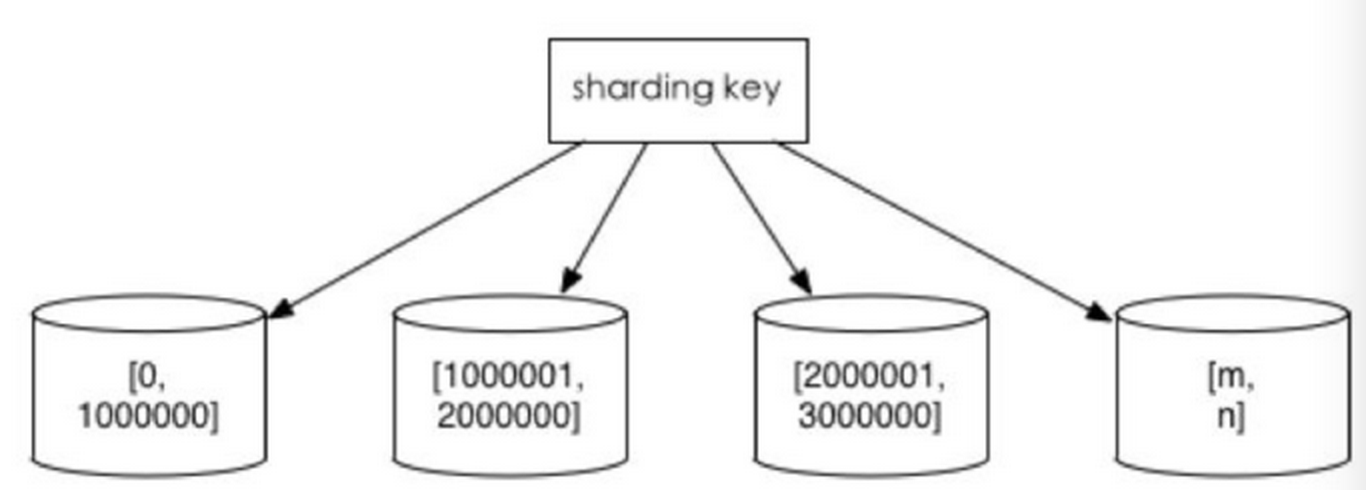
根据数值范围
比如我们的userId,1到9999记录的放在第一个库,100000~200000放到第二个库,以此类推
优点:
- 扩展性、维护性高,每次只需要将新的数据存入到新的库中,无需对其它分片进行数据迁移
- 单表大小可控
- 使用分片的条件字段进行范围查询时,连续分片可快速定位到分片进行查询,有效避免跨分片查询的问题(数据都是连续的,大概率是在同一个分片中)
缺点:
热点数据数据不均匀成为性能瓶颈。比如最新注册的用户是最活跃的,那么那一个分片必然就是被频繁的读写,而最早注册的用户则最少被读写
根据数值取模
一般采用hash或mod的切分方式。比如用户表中使用userId为条件切分到四个库中,这是userId%4等于0的在第一个库,userId%4等于1的放到第二个库,以此类推
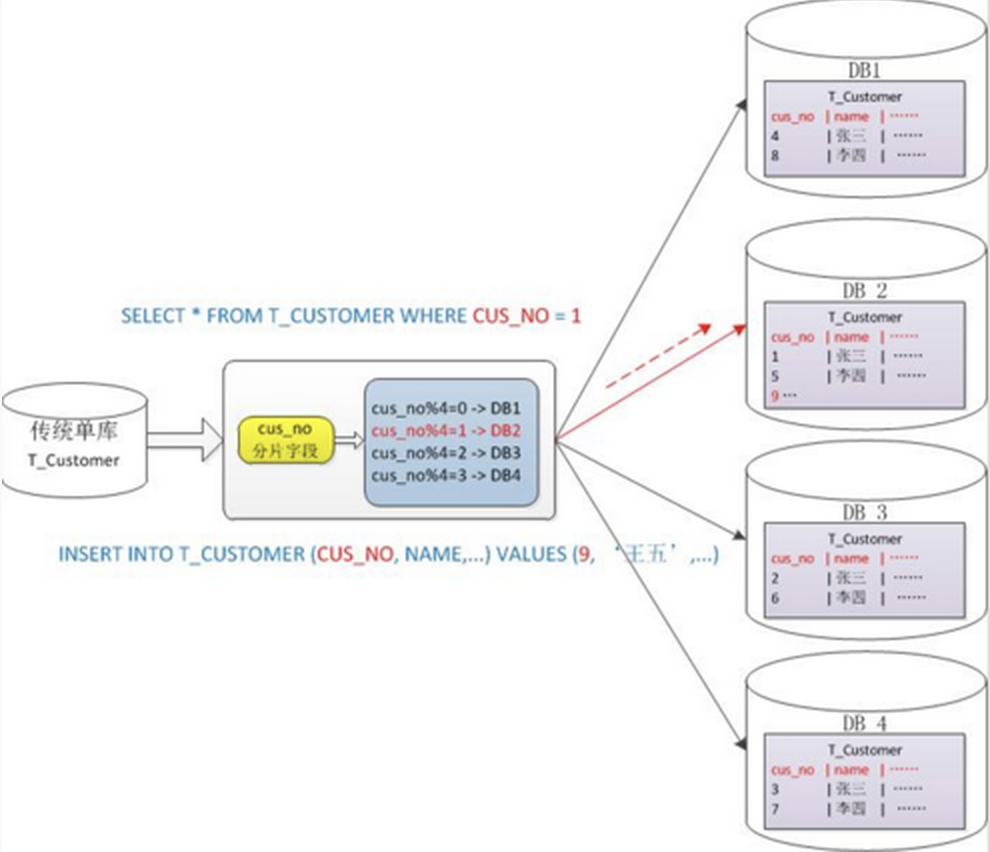
优点:
数据分片相对比较均匀,不容易出现热点数据库的问题
缺点:
2. 后期分片集群扩容的时候需要进行数据迁移(可以使用一致性hash算法解决)
3. 容易有分片查询的复杂问题。假设一个需要查询的数据没有userId,这时需要同时查询四个分片,然后聚合,然后返回给应用,分库后反而成为拖累
分库分表引发的问题
事务一致性问题
分布式事务
当更新内容分布在不同的数据库中,不可避免会带来跨事务的问题。
解决方案:
使用“XA”协议或“两阶段提交处理(2PC、3PC)”,但随着节点的增多,导致事务的时间更长,访问共享资源的时候容易造成死锁。这也是水平扩展的枷锁
最终一致性
对于实时性要求不高的系统,可以采用事务补偿的方式,即需要在一定时间内才能达到一致性。
补偿方式:对数据检查、基于日志对比、定期同步标准数据源等
跨界点关联查询join问题
解决方案:
- 全局表:将一些被多个模块依赖的表做冗余,即将这些表在每个数据库中都保存一份。
- 字段冗余:也是冗余的方式,不过冗余的是字段,比如很多表都有user_id,这个时候可以直接将user_name也一起冗余到表中。这种仅仅使用于字段较少的情况,但随之也带来了数据一致性的问题,比如我更新了user表,这个时候还要更新所有的冗余字段
- 数据组装:通过应用层来聚合所需要join的数据,比如先查出id集合,然后去另一个节点查询此id的数据,然后在应用层中进行组装成我们需要的字段。
- ER分片:顾名思义,就是对ER图进行分片,将一些存在关联性的表都放在一个分片上,可以很大程度避免join带来的问题。比如订单表和订单详情表可以放在一个分片上
跨节点分页、排序、函数问题
在进行多个库查询时,会出现limit、order by等问题。
如果分片规则是按照排序字段进行分片时,可以通过分片规则定位到指定的分片
如果分片规则不是按照排序字段分片时,就变得复杂,需要在不同分片上将数据进行排序后返回,然后再根据不同分片返回的结果进行汇总和再次排序,得到最终结果。
如果limit的数据很大,查询是非常耗时、CPU资源、内存资源的,所以limit的页数越大,系统性能也会越差
函数Max、Min、Sum、Count之类的函数计算,也是同理,需要先再每个分片执行相应的函数,然后够再汇总计算。
全局主键问题
自增主键在分布式上基本无用武之地,所以需要单独设计全局主键以避免跨库时主键重复问题。有如下几种解决方式:
UUID
UUID标准形式是包含32位16进制数,分为5段,格式为:8-4-4-4-12 的36个字符:550e8400e29b41d4a716446655440000
这是一种简单有效的主键生成策略,既是本地生成有没有网络耗时。但缺点也明显,比如UUID非常长,占用大量空间;id作为主键索引的时候,基于索引查询会存在性能问题;在InnoDB中,UUID的无序性会引起数据位置频繁变动,导致分页
使用数据库来维护主键ID表,在数据库中建立sequence表
CREATE TABLE `sequence` (
`id` bigint(20) unsigned NOT NULL auto_increment,
`stub` char(1) NOT NULL default '',PRIMARY KEY (`id`),
UNIQUE KEY `stub` (`stub`)
) ENGINE=MyISAM;
stub字段设置为唯一索引,统一stub值在统一sequence中只有一条记录,可以同时为多个表生成全局ID。内容如下:
+-------------------+------+
| id | stub |
+-------------------+------+
| 72157623227190423 | a |
+-------------------+------+
其中这里使用MyISAM存储引擎,而不是InnoDB来获取更高的性能。其中MyISAM是行级锁,而InnoDB是表级锁,所以不用担心并发时两次获取到同样的值
然后我们看下如何根据表来获取全局ID
REPLACE INTO sequence (stub) VALUES ('a');
SELECT LAST_INSERT_ID();
其中这两条语句是Connection级别的,这两条语句必须在同一个数据连接下执行。而使用REPLACE INTO代替 INSERT INTO是为了避免表行数过大而导致的定期清理。
Snowflake分布式自增算法
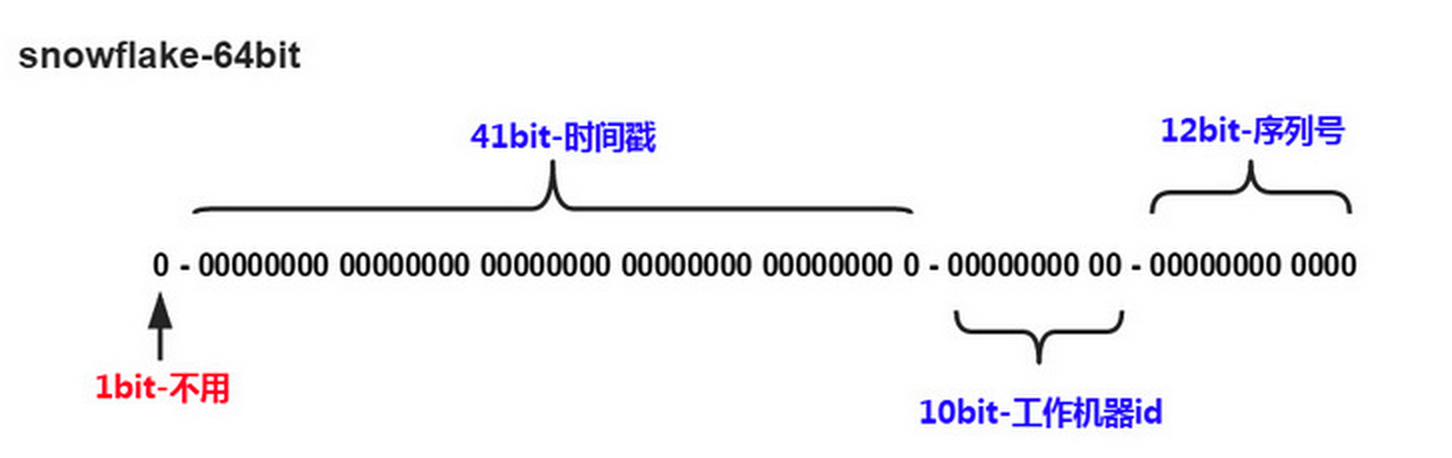
这个算法来源于Twitter,它解决了分布式系统生成全局ID的需求。ID格式为64为的Long型数字,组成部分如下:
- 第一位未使用
- 接下来41位是ms级时间,41位的长度可表示69年的时间
- 5位datacenterId,5位workerId。共10位的长度共支持1024个节点
- 最后12位是毫秒内的计数,12位的计数序列号支持每个节点每毫秒产生4096个ID序列
优点:
毫秒在高位,基本都是按照时间趋势递增;
不依赖第三方系统,稳定性和效率较高,理论上QPS约为409.6w/s(1000*2^12),且整个分布式系统内ID不会碰撞
可以根据自身业务灵活分配bit位
缺点:
强依赖时钟,如果时钟回拨则可能导致ID重复
数据迁移、扩容问题
只有当业务高速发展,面临性能和存储瓶颈时才会考虑分片设计,这个时候不可避免的就需要考虑历史数据迁移的问题。
如果采用的是数值范围分片,则不需要数据迁移
如果采用的是数值取模分片,则考虑后期扩容就会比较麻烦
总结
切分方案总结如下表:
| 切分方式 | join复杂度 | 事务复杂性 | 扩展性 | 单表数据量过大问题 |
|---|---|---|---|---|
| 垂直分库(业务维度切分) | 不复杂,业务之间有关联的大概率在一个分片上 | 不复杂,业务之间有关联的大概率在一个分片上 | 扩展性高,每增加一个功能增加一个分片 | 无法解决 |
| 垂直分表(高频字段切分) | 部分表无法join,只能通过聚合 | 分布式事务处理复杂 | 扩展性一般,新字段需要考虑新分片还是添加到旧分片 | 无法解决 |
| 垂直分库+分表 | 部分表无法join,只能通过聚合 | 分布式事务处理复杂 | 一般 | 可以解决 |
| 水平切分(库内分表) | 不会有join问题 | 能够保证事务一致性 | 扩展方式简单 | 可以解决 |
| 水平切分(分库分表) | 跨库join性能较差 | 跨分片事务一致性无法保证 | 扩展性难度大,每次都需要重新水平切分 | 可以解决 |
扩展
-
目前美团已有比较成熟的解决方案:Leaf——美团点评分布式ID生成系统 – 美团技术团队
-
2PC:多个节点只要有一个节点失败,所有节点事务回滚
-
3PC:先把事务头提交,但不commit,当所有数据库都执行完在统一commit
-
TCC(Trying Confirming Canceling)分布式事务实现的一种方式,主要有如下阶段:
TRYING阶段主要是对业务系统做检测及资源预留CONFIRMING阶段主要是对业务系统做确认提交,TRYING阶段执行成功并开始执行CONFIRMING阶段时,默认CONFIRMING阶段是不会出错的。即:只要TRYING成功,CONFIRMING一定成功。CANCELING阶段主要是在业务执行错误,需要回滚的状态下执行的业务取消,预留资源释放。 而幂等性则是指业务方法调用一次与调用多次的执行返回结果是一样的。
-
MVCC(Multi version concurrency control:多版本并发控制):用来避免写操作时阻塞读操作的并发问题。其中多版本指的就是在另一个事务在执行写操作时,不覆盖旧的数据,而是新建一条数据且保留旧的数据,因此当前事务可以看到被更新之前得值且不会被阻塞,这样以来就不需要等待另一个事务释放锁也不会读取到未提交的数据,提高了并发性。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/17863.html

