
linux常用命令1:
1.机器信息
1)Linux查看版本当前操作系统发行版信息:
cat /etc/redhat-release
2)Linux查看cpu相关信息:
cat /proc/cpuinfo
总核数 = 物理CPU个数 X 每颗物理CPU的核数 总逻辑CPU数 = 物理CPU个数 X 每颗物理CPU的核数 X 超线程数 查看物理CPU个数 cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l 查看每个物理CPU中core的个数(即核数) cat /proc/cpuinfo| grep "cpu cores"| uniq 查看逻辑CPU的个数 cat /proc/cpuinfo| grep "processor"| wc -l3)显示当前的各种用户进程限制
ulimit -a
2.查询
查询进程号:
jps -m 或者ps -ef |grep mysql或者lsof -i tcp:9876或者netstat -nap |grep 9876
查找文件:
locate mqadmin 或者whereis mqadmin 或者which mqadmin或者find . -name mqadmin
或者find ./ |grep mqadmin
模糊查找文件:
find ./ -name "*store*.log"
根据内容模糊查找文件:
`在当前目录搜索文件内容含有某字符串(大小写敏感)的文件:
find . -type f | xargs grep ‘namesrv’
在当前目录搜索文件内容含有某字符串(大小写敏感)的特定文件:
find . -type f -name ‘*.sh’ | xargs grep ‘namesrv’
在当前目录搜索文件内容含有某字符串(忽略大小写)的特定文件:
find . -type f -name ‘*.sh’ | xargs grep -i ‘namesrv’`
在文件中模糊查找内容:
cat store.log |grep broker
3.性能监控
1)查看机器网口带宽
ethtool eth0
2)查看内存使用情况:
free -h
3)查看磁盘
df -h
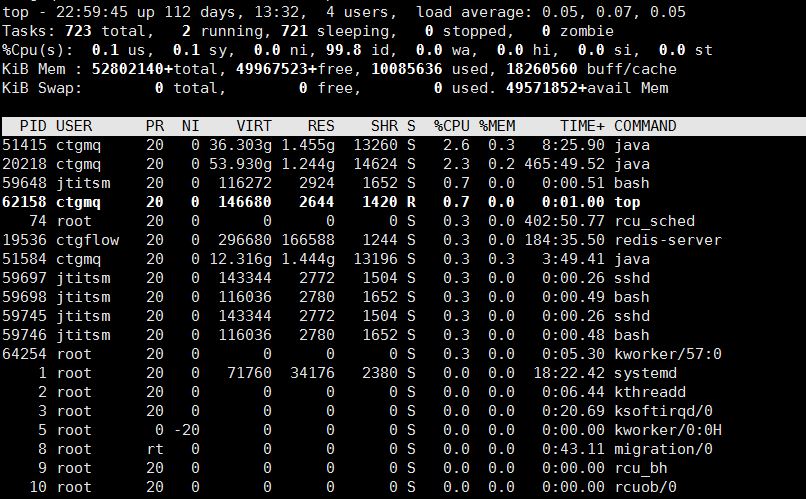
4)通过top命令查看系统的CPU、内存、运行时间、交换分区、执行的线程等信息。通过top命令可以有效的发现系统的缺陷出在哪里
top -d 2
PID — 进程id
USER — 进程所有者
PR — 进程优先级
NI — nice值。负值表示高优先级,正值表示低优先级
VIRT — 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
RES — 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
SHR — 共享内存大小,单位kb
S — 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程
%CPU — 上次更新到现在的CPU时间占用百分比
%MEM — 进程使用的物理内存百分比
TIME+ — 进程使用的CPU时间总计,单位1/100秒COMMAND — 进程名称(命令名/命令行)

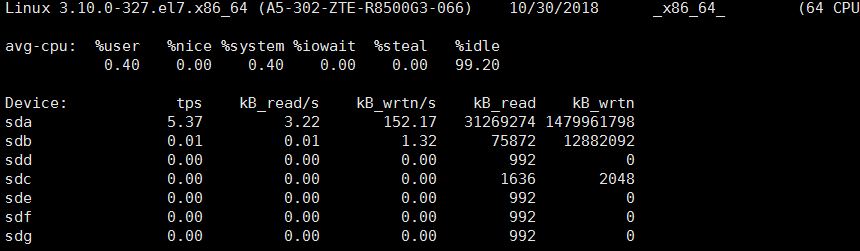
5)监控磁盘io
iostat -d -k 2
tps:该设备每秒的传输次数(Indicate the number of transfers per second that were issued to the device.)。“一次传输”意思是”一次I/O请求”。多个逻辑请求可能会被合并为”一次I/O请求”。”一次传输”请求的大小是未知的。kB_read/s:每秒从设备(drive expressed)读取的数据量;
kB_wrtn/s:每秒向设备(drive expressed)写入的数据量;
kB_read:读取的总数据量;
kB_wrtn:写入的总数量数据量;这些单位都为Kilobytes。
iostat -d -x -k 1
rrqm/s:每秒这个设备相关的读取请求有多少被Merge了(当系统调用需要读取数据的时候,VFS将请求发到各个FS,如果FS发现不同的读取请求读取的是相同Block的数据,FS会将这个请求合并Merge);wrqm/s:每秒这个设备相关的写入请求有多少被Merge了。rsec/s:每秒读取的扇区数;
wsec/:每秒写入的扇区数。
rKB/s:The number of read requests that were issued to the device per second;
wKB/s:The number of write requests that were issued to the device per second;
avgrq-sz 平均请求扇区的大小
avgqu-sz 是平均请求队列的长度。毫无疑问,队列长度越短越好。
await: 每一个IO请求的处理的平均时间(单位是微秒毫秒)。这里可以理解为IO的响应时间,一般地系统IO响应时间应该低于5ms,如果大于10ms就比较大了。
这个时间包括了队列时间和服务时间,也就是说,一般情况下,await大于svctm,它们的差值越小,则说明队列时间越短,反之差值越大,队列时间越长,说明系统出了问题。
svctm 表示平均每次设备I/O操作的服务时间(以毫秒为单位)。如果svctm的值与await很接近,表示几乎没有I/O等待,磁盘性能很好,如果await的值远高于svctm的值,则表示I/O队列等待太长, 系统上运行的应用程序将变慢。
%util: 在统计时间内所有处理IO时间,除以总共统计时间。例如,如果统计间隔1秒,该设备有0.8秒在处理IO,而0.2秒闲置,那么该设备的%util = 0.8/1 = 80%,所以该参数暗示了设备的繁忙程度
。一般地,如果该参数是100%表示设备已经接近满负荷运行了(当然如果是多磁盘,即使%util是100%,因为磁盘的并发能力,所以磁盘使用未必就到了瓶颈)。

6)vmstat查看服务器的CPU使用率,内存使用,虚拟内存交换情况,IO读写情况
[ctgmq@A5-302-ZTE-R8500G3-066 ~]$ vmstat 2 procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 0 0 0 499676992 293832 17967128 0 0 0 2 0 0 0 0 99 0 0 0 0 0 499677344 293832 17967128 0 0 0 0 1650 3292 0 0 100 0 0 0 0 0 499677728 293832 17967132 0 0 0 24 1762 3548 0 0 100 0 0 0 0 0 499678080 293832 17967132 0 0 0 0 1673 3312 0 0 100 0 0 0 0 0 499678304 293832 17967132 0 0 0 0 1675 3343 0 0 100 0 0 0 0 0 499678368 293832 17967140 0 0 0 36 1783 3591 0 0 100 0 0
r 表示运行队列(就是说多少个进程真的分配到CPU),我测试的服务器目前CPU比较空闲,没什么程序在跑,当这个值超过了CPU数目,就会出现CPU瓶颈了。这个也和top的负载有关系,一般负载超过了3就比较高,超过了5就高,超过了10就不正常了,服务器的状态很危险。top的负载类似每秒的运行队列。如果运行队列过大,表示你的CPU很繁忙,一般会造成CPU使用率很高。
b 表示阻塞的进程,这个不多说,进程阻塞,大家懂的。
swpd 虚拟内存已使用的大小,如果大于0,表示你的机器物理内存不足了,如果不是程序内存泄露的原因,那么你该升级内存了或者把耗内存的任务迁移到其他机器。
free 空闲的物理内存的大小,我的机器内存总共8G,剩余3415M。
buff Linux/Unix系统是用来存储,目录里面有什么内容,权限等的缓存,我本机大概占用300多M
cache cache直接用来记忆我们打开的文件,给文件做缓冲,我本机大概占用300多M(这里是Linux/Unix的聪明之处,把空闲的物理内存的一部分拿来做文件和目录的缓存,是为了提高 程序执行的性能,当程序使用内存时,buffer/cached会很快地被使用。)
si 每秒从磁盘读入虚拟内存的大小,如果这个值大于0,表示物理内存不够用或者内存泄露了,要查找耗内存进程解决掉。我的机器内存充裕,一切正常。
so 每秒虚拟内存写入磁盘的大小,如果这个值大于0,同上。
bi 块设备每秒接收的块数量,这里的块设备是指系统上所有的磁盘和其他块设备,默认块大小是1024byte,我本机上没什么IO操作,所以一直是0,但是我曾在处理拷贝大量数据(2-3T)的机器上看过可以达到140000/s,磁盘写入速度差不多140M每秒
bo 块设备每秒发送的块数量,例如我们读取文件,bo就要大于0。bi和bo一般都要接近0,不然就是IO过于频繁,需要调整。
in 每秒CPU的中断次数,包括时间中断
cs 每秒上下文切换次数,例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目,例如在apache和nginx这种web服务器中,我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了。系统调用也是,每次调用系统函数,我们的代码就会进入内核空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的时间少了,CPU没有充分利用,是不可取的。
us 用户CPU时间,我曾经在一个做加密解密很频繁的服务器上,可以看到us接近100,r运行队列达到80(机器在做压力测试,性能表现不佳)。
sy 系统CPU时间,如果太高,表示系统调用时间长,例如是IO操作频繁。
id 空闲 CPU时间,一般来说,id + us + sy = 100,一般我认为id是空闲CPU使用率,us是用户CPU使用率,sy是系统CPU使用率。
wt 等待IO CPU时间。
7)sar命令
1.观察CPU 的使用情况
sar -u
2.磁盘i/O
sar -b
3.设备使用情况监控
sar -d -p
怀疑CPU存在瓶颈,可用 sar -u 和 sar -q 等来查看
怀疑内存存在瓶颈,可用 sar -B、sar -r 和 sar -W 等来查看
怀疑I/O存在瓶颈,可用 sar -b、sar -u 和 sar -d 等来查看
8)系统性能分析
用vmstat、sar、iostat检测是否是CPU瓶颈
用free、vmstat检测是否是内存瓶颈
用iostat检测是否是磁盘I/O瓶颈
用netstat检测是否是网络带宽瓶颈
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/18399.html

