
对于 ElasticSearch8 集群,比较容易的方式就是无密码集群搭建。对于 ElasticSearch 来说,一般都是运行在内网中,可以通过防火墙限制来源 ip 或者通过 ElasticSearch 自身的配置来限制来源 ip。这种保障安全的方式比较类似于 Redis 。
对于 Kibana 来说,可以配置连接多个 ElasticSearch,可以使用 Cerebro 工具监控 ElasticSearch 集群节点,可以下载到本地直接运行,使用非常方便。本篇博客将直接跟 ElasticSearch 集群一起,使用 docker-compose 部署在 CentOS7 中。
官网上介绍的 ElasticSearch8 集群搭建,比较难以看懂和实践。我研究后参考之前的单节点 ElasticSearch 的搭建方式,改进一下进行集群搭建。本篇博客使用 docker-compose 搭建 3 节点 ElasticSearch8 集群,以及 Kibana 和 Cerebro 。我的虚拟机采用 CentOS7(IP 地址为 192.168.136.219),已经安装了 docker 和 docker-compose,建议虚拟机的内存不少于 8G。
一、搭建前的准备
首先创建出目录结构,我创建了 /app/es_cluster 目录,在该目录下创建出如下目录结构:
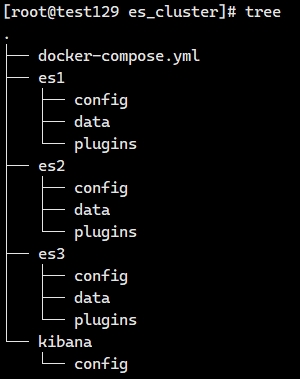

然后就是这些目录的权限,最好是 777(特别是 data 目录),否则 ES 很有可能无法启动。
# 为了省事,直接将 es_cluster 所有子目录的访问权限都设置为 777
cd /app
chmod -R 777 es_cluster/
官网上说最好把 Linux 宿主机本身最好修改以下 /etc/sysctl.conf 文件,那就修改一下呗:
vim /etc/sysctl.conf
# 添加以下内容
vm.max_map_count=262144
# 保存后运行以下命令使配置生效
sysctl -p
先使用 docker 运行以下单个 ElasticSearch 和 Kibana,主要目的使为了把容器中的 config 目录及其内部文件拷贝出来:
# 运行单节点 ElasticSearch
docker run -d --name es \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
docker.elastic.co/elasticsearch/elasticsearch:8.8.2
# 运行 Kibana
docker run -d --name kibana docker.elastic.co/kibana/kibana:8.8.2
# 将 docker 容器中的 ES 中的 config 目录及其内部文件都拷贝出来
docker cp es:/usr/share/elasticsearch/config /app/es_cluster/es1
docker cp es:/usr/share/elasticsearch/config /app/es_cluster/es2
docker cp es:/usr/share/elasticsearch/config /app/es_cluster/es3
# 将 docker 容器中的 Kibana 中的 config 目录及其内部文件都拷贝出来
docker cp kibana:/usr/share/kibana/config /app/es_cluster/kibana
# 销毁 docker 运行的 es 容器和 kibana 容器
docker rm -f es kibana
可以把之前博客中提到的 ik 分词器和 pinyin 分词器插件,上传到 3 个 es 中的 plugins 目录中,这里就不再赘述。
二、ES8 集群搭建
在 /app/es_cluster 下创建一个 docker-compose.yml 文件,内容如下:
version: "3.2"
services:
es1:
container_name: es1
image: docker.elastic.co/elasticsearch/elasticsearch:8.8.2
restart: always
privileged: true
ulimits:
memlock:
soft: -1
hard: -1
environment:
- "ES_JAVA_OPTS=-Xms1024m -Xmx1024m"
ports:
- 9201:9200
volumes:
- /app/es_cluster/es1/config:/usr/share/elasticsearch/config
- /app/es_cluster/es1/data:/usr/share/elasticsearch/data
- /app/es_cluster/es1/plugins:/usr/share/elasticsearch/plugins
networks:
- elastic_net
es2:
container_name: es2
image: docker.elastic.co/elasticsearch/elasticsearch:8.8.2
restart: always
privileged: true
ulimits:
memlock:
soft: -1
hard: -1
environment:
- "ES_JAVA_OPTS=-Xms1024m -Xmx1024m"
ports:
- 9202:9200
volumes:
- /app/es_cluster/es2/config:/usr/share/elasticsearch/config
- /app/es_cluster/es2/data:/usr/share/elasticsearch/data
- /app/es_cluster/es2/plugins:/usr/share/elasticsearch/plugins
networks:
- elastic_net
es3:
container_name: es3
image: docker.elastic.co/elasticsearch/elasticsearch:8.8.2
restart: always
privileged: true
ulimits:
memlock:
soft: -1
hard: -1
environment:
- "ES_JAVA_OPTS=-Xms1024m -Xmx1024m"
ports:
- 9203:9200
volumes:
- /app/es_cluster/es3/config:/usr/share/elasticsearch/config
- /app/es_cluster/es3/data:/usr/share/elasticsearch/data
- /app/es_cluster/es3/plugins:/usr/share/elasticsearch/plugins
networks:
- elastic_net
kibana:
container_name: kibana
image: docker.elastic.co/kibana/kibana:8.8.2
restart: always
ports:
- 5601:5601
volumes:
- /app/es_cluster/kibana/config:/usr/share/kibana/config
networks:
- elastic_net
cerebro:
container_name: cerebro
image: lmenezes/cerebro:0.9.4
restart: always
ports:
- 9000:9000
command:
- -Dhosts.0.host=http://es1:9200
- -Dhosts.1.host=http://es2:9200
- -Dhosts.2.host=http://es3:9200
networks:
- elastic_net
# 网络配置
networks:
elastic_net:
driver: bridge
分别进入 es1,es2,es3 文件夹中,使用如下内容,替换 config 目录下的 elasticsearch.yml 文件内容:
#################################
# es1 节点的 elasticsearch.yml 内容
#################################
# 集群节点名称
node.name: "es1"
# 设置集群名称为elasticsearch
cluster.name: "cluster_es"
# 网络访问限制
network.host: 0.0.0.0
# 是否支持跨域
http.cors.enabled: true
# 表示支持所有域名
http.cors.allow-origin: "*"
# 内存交换的选项,官网建议为true
bootstrap.memory_lock: true
# 集群中的其它节点
discovery.seed_hosts: es2,es3
# 集群中初始化的节点
cluster.initial_master_nodes: es1,es2,es3
# 取消安全验证
xpack.security.enabled: false
xpack.security.http.ssl.enabled: false
xpack.security.transport.ssl.enabled: false
#################################
# es2 节点的 elasticsearch.yml 内容
#################################
# 集群节点名称
node.name: "es2"
# 设置集群名称为elasticsearch
cluster.name: "cluster_es"
# 网络访问限制
network.host: 0.0.0.0
# 是否支持跨域
http.cors.enabled: true
# 表示支持所有域名
http.cors.allow-origin: "*"
# 内存交换的选项,官网建议为true
bootstrap.memory_lock: true
# 集群中的其它节点
discovery.seed_hosts: es1,es3
# 集群中初始化的节点
cluster.initial_master_nodes: es1,es2,es3
# 取消安全验证
xpack.security.enabled: false
xpack.security.http.ssl.enabled: false
xpack.security.transport.ssl.enabled: false
#################################
# es3 节点的 elasticsearch.yml 内容
#################################
# 集群节点名称
node.name: "es3"
# 设置集群名称为elasticsearch
cluster.name: "cluster_es"
# 网络访问限制
network.host: 0.0.0.0
# 是否支持跨域
http.cors.enabled: true
# 表示支持所有域名
http.cors.allow-origin: "*"
# 内存交换的选项,官网建议为true
bootstrap.memory_lock: true
# 集群中的其它节点
discovery.seed_hosts: es1,es2
# 集群中初始化的节点
cluster.initial_master_nodes: es1,es2,es3
# 取消安全验证
xpack.security.enabled: false
xpack.security.http.ssl.enabled: false
xpack.security.transport.ssl.enabled: false
进入 kibana 下的 config 目录中,使用如下内容替换 kibana.yml 文件的内容
18n.locale: zh-CN
server.host: "0.0.0.0"
server.shutdownTimeout: "5s"
elasticsearch.hosts: ["http://es1:9200","http://es2:9200","http://es3:9200"]
monitoring.ui.container.elasticsearch.enabled: true
以上操作都完成后,在 /app/es_cluster 目录下运行 docker-compose up -d 即可。
# 可以使用如下命令查看相关 es 节点的启动日志,比如查看 es1 的启动情况
docker logs -f es1
# 可以使用如下命令查看 kibana 节点的启动日志
docker logs -f kibana
# 可以使用如下命令查看 cerebro 节点的启动日志
docker logs -f cerebro
三、验证搭建成果
可以在浏览器上访问如下链接,查看 es 的 3 个节点是否启动成功:
# 查看 es1 节点
http://192.168.136.129:9201
# 查看 es2 节点
http://192.168.136.129:9202
# 查看 es3 节点
http://192.168.136.129:9203
可以在浏览器上访问 http://192.168.136.129:5601 查看 Kibana 是否启动成功
可以在浏览器上访问 http://192.168.136.129:9000 查看 Cerebro 监控工具,界面如下:
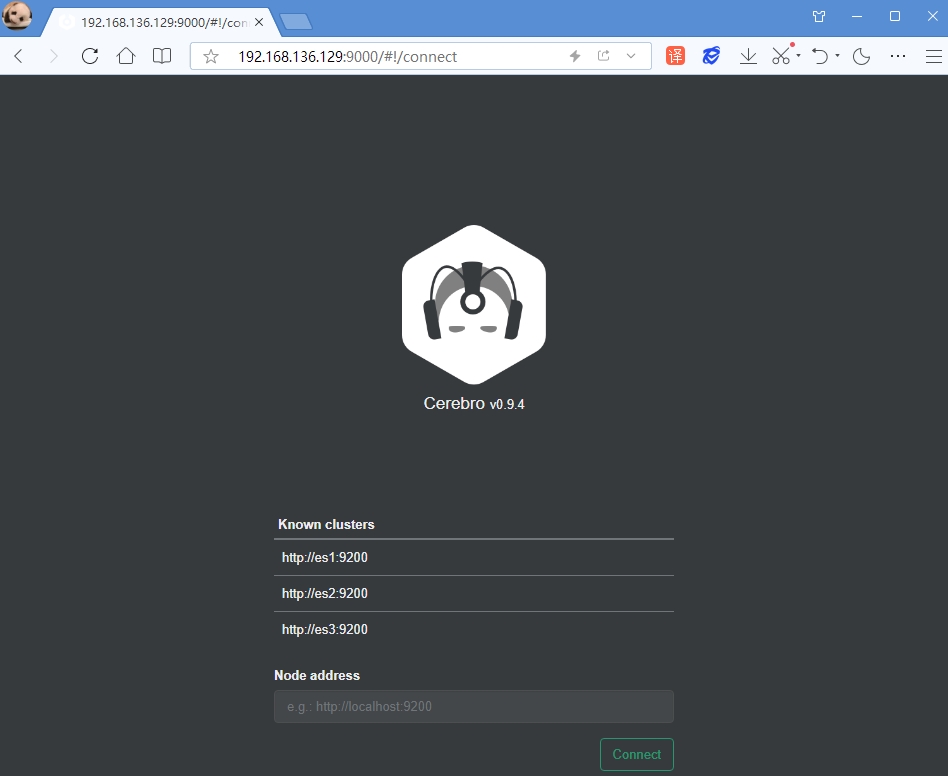
可以在 Node address 下面的文本框中输入 ES 节点的地址,也可以直接点击我们配置的 3 个节点中的任意一个节点,比如点击 http://es1:9200 即可进入到集群监控界面中,如下所示:
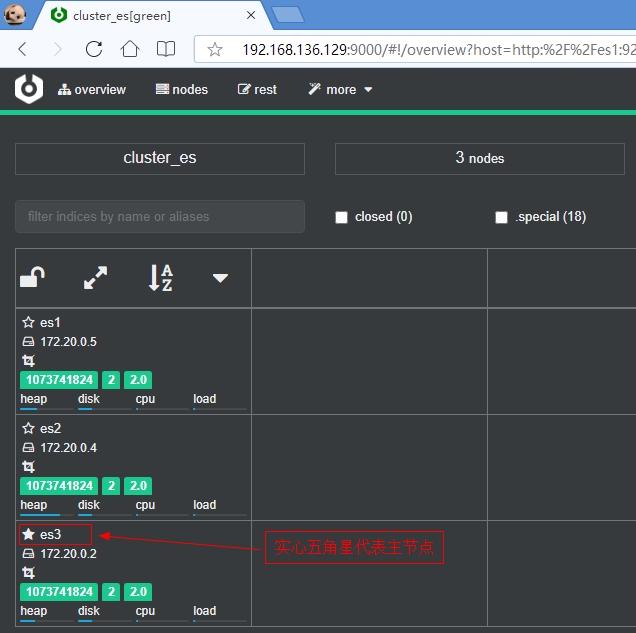
可以看出 es3 前面的五角星是实心的,表示 es3 是主节点,es1 和 es2 是从节点。既然是集群,肯定具有高可用的健壮性,当 es3 节点宕机后,es1 和 es2 中会有一个变成主节点,当 es3 恢复后就变成了从节点。这里就不再演示这个变化过程了。
Cerebro 工具除了监控 ES 集群之外,也具有向 ES 发送 DSL 操作语句的功能,还有可视化的操作界面,功能还是很强大的。当然 Cerebro 和 Kibana 工具各有一些实用功能和优缺点,大家可以根据自己的偏爱,选择使用合适的工具去操作 ElasticSearch。
既然搭建好了 ES 的集群,因此在创建索引库时,需要指定分片数量和副本数量,比如我们是 3 节点集群,可以指定分片数量为 3,副本数量为 1。
分片是指 ES 的数据分成多少份进行存放,每个分片存放在不同的节点上,主要用于 ES 数据量比较大,单节点无法承载的情况下使用。副本是指分片的备份,每个分片存放在不同的 ES 节点中,为了防止 ES 节点宕机导致部分数据无法访问,所以每个分片必须至少有 1 个副本,存放在其它的 ES 节点上。
目前 Cerebro 工具的最新版本为 0.9.4 ,下载地址为:https://github.com/lmenezes/cerebro/releases
对于下来的压缩包 cerebro-0.9.4.zip ,在 windows 上解压缩后,直接运行 bin 目录中的 cerebro.bat
启动成功后可以在浏览器上访问 http://localhost:9000 即可。
四、Java 代码操作 ES 集群
由于我们搭建的是无密码 ES 集群,以之前博客的 Demo 为例,要想连接无密码的 ES 集群,需要修改如下 3 个地方:
第一个就是修改 application.yml 文件,注释掉用户名和密码配置信息,连接地址设置为 3 个节点的 url 地址
# 自定义的 elasticsearch 配置内容
elasticsearch:
#username: elastic
#password: tdGiSi*fhwW0F60*i*Jc
# 连接的服务器 url,多个 url 之间用英文逗号分隔
urls: http://192.168.136.129:9201,http://192.168.136.129:9202,http://192.168.136.129:9203
第二个就是修改 ElasticSearchConfig 类,取消有关账号和密码相关的代码:
package com.jobs.config;
import org.apache.http.Header;
import org.apache.http.HttpHeaders;
import org.apache.http.HttpHost;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.UsernamePasswordCredentials;
import org.apache.http.client.CredentialsProvider;
import org.apache.http.impl.client.BasicCredentialsProvider;
import org.apache.http.message.BasicHeader;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.ArrayList;
@Configuration
public class ElasticSearchConfig {
//用户名
//@Value("${elasticsearch.username}")
//private String username;
//密码
//@Value("${elasticsearch.password}")
//private String password;
//对于 yml 中的配置项,如果配置值是以英文逗号分隔,可直接转换为数组
@Value("${elasticsearch.urls}")
private String[] urls;
@Bean
public RestHighLevelClient restHighLevelClient() {
//设置用户名和密码
//CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
//credentialsProvider.setCredentials(AuthScope.ANY,
// new UsernamePasswordCredentials(username, password));
//从 urls 数组中创建出多个 HttpHost 数组
ArrayList<HttpHost> hostlist = new ArrayList<>();
for (String url : urls) {
hostlist.add(HttpHost.create(url));
}
HttpHost[] hosts = hostlist.toArray(new HttpHost[hostlist.size()]);
RestClientBuilder builder = RestClient.builder(hosts);
//builder.setHttpClientConfigCallback(s -> s.setDefaultCredentialsProvider(credentialsProvider));
//使用 RestHighLevelClient 操作 ElasticSearch 8 版本时,需要加上以下 header 后,操作索引文档才能不报错
builder.setDefaultHeaders(new Header[]{
new BasicHeader(HttpHeaders.ACCEPT,
"application/vnd.elasticsearch+json;compatible-with=7"),
new BasicHeader(HttpHeaders.CONTENT_TYPE,
"application/vnd.elasticsearch+json;compatible-with=7")});
RestHighLevelClient client = new RestHighLevelClient(builder);
return client;
}
}
第三个就是创建索引库的 DSL 语句,需要增加上有关分片数量和副本数量的设置(settings 的内容):
# 创建索引库
PUT /myhotel
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
},
"mappings": {
"properties": {
"id":{
"type": "keyword"
},
"name":{
"type": "text",
"analyzer": "ik_max_word",
"copy_to": "all"
},
"address":{
"type": "keyword",
"index": false
},
"price":{
"type": "integer"
},
"brand":{
"type": "keyword",
"copy_to": "all"
},
"city":{
"type": "keyword"
},
"location":{
"type": "geo_point"
},
"all":{
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
当然你可以手动使用 kibana 运行以上 DSL 语句,创建好 myhotel 索引库,然后运行之前的代码批量添加文档数据。
批量添加文档数据之后,我们可以再看一下 Cerebro 工具的主界面,就能够发现分片和副本在 ES 的 3 个节点的分布情况:
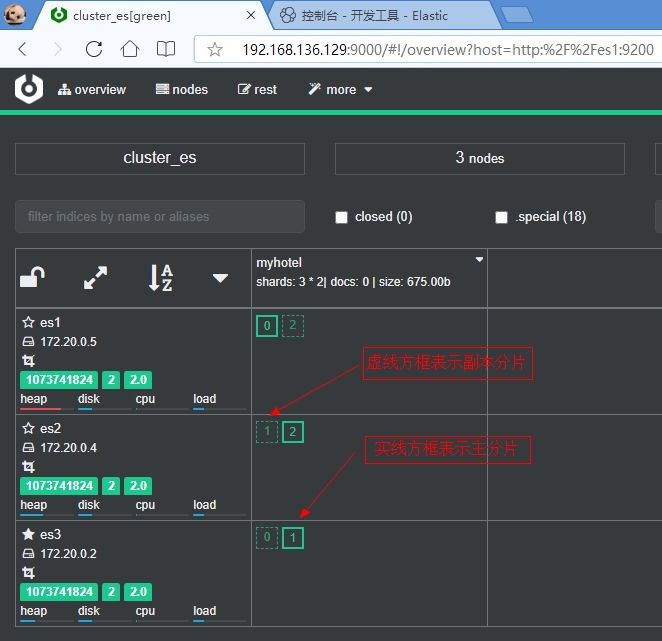
如上图所示:实现方框表示主分片,虚线方框表示副本分片。可以看到每个节点,各个主分片和副本分片的分布情况。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/191073.html

