

《Python工匠》是一本案例、技巧与工程实践的指导书,该书不是python基础语法的教程,而是python中最佳实践的教程,属于python进阶类的书籍。可以将本书当做PEP8编程规范的补充,书同时中描述了很多python编程优雅的实践方法,既有广度也有深度,是值得python开发者反复阅读的书。我感叹于作者丰富的实践和广博的积累,从中获益良多,所以将书中精华内容整理出来,希望阅读者也能从中获益。
一、变量与注释
变量解包
变量解包是Python中的一种特殊赋值操作,允许我们把一个列表的所有成员,一次性赋值给多个变量:
>>> arr = ["one", "two"]
>>>
>>> first, second = arr
>>>
>>> first
'one'
>>> second
'two'
出了普通解包之外,还支持更灵活的动态解包语法。用星号(*datas)作为变量,贪婪的捕获尽可能多的对象,并将捕获到的内容作为列表赋值给变量data
>>> arr = ["one", "two", "three", "four", "five"]
>>>
>>> first, *datas, last = arr
>>> first
'one'
>>> datas
['two', 'three', 'four']
>>> last
'five'
>>>
动态解包的方式比切片获取更加直观
first, *datas, last = arr
first, datas, last = arr[0], arr[1:-1], arr[-1]
变量命名规则
- 遵循PEP8规则
- 描述性要强:在可接受的长度范围内,变量名所指向的内容描述越精确越好。如 value 不如 total_number
- 要匹配类型:
匹配布尔类型的变量名,以is,has, allow等开头命名布尔类型;
匹配数值类型的变量名,释义为数字,例:port;以id结尾例:user_id,以length/count开头或结尾的单词,例:users_count - 尽量要短,为变量名命名要结合代码情景和上下文,如类,函数的内部的变量就不要重复出现相同的含义。变量名最好在4个单词以内
- 可以将高频长变量命名成较短变量名,但要严格控制数量
注释
注释分为代码注释和接口注释。注释常见的三种错误:
- 用注释屏蔽代码
- 用注释复述代码
- 接口注释描述函数实现细节
编程建议
- 保持变量一致,同一个事物在项目中始终保持同一个名字
- 变量定义尽量靠近使用
- 面对复杂的逻辑,定义临时变量提升可读性。如if判断条件过多
- 同一作用域不要有太多变量
- 能避免定义的变量尽量避免,减少阅读者记忆负担
- 不要使用locals返回所有变量
- 适当位置插入空行,隔离逻辑
- 先写注释再写代码
二、数值与字符串
字符串格式化
字符串格式化至少有三种方式:
- C语言风格的基于百分号%的格式化语句 ‘hello, %s’ % ‘word’
- 新式字符串格式化 str.format ‘hello, {}’.format(“word”)
- f-string 字符串字面量格式化表达式 name = “word” f”hello {name}”
首选f-string,配合format
字符串和字节串
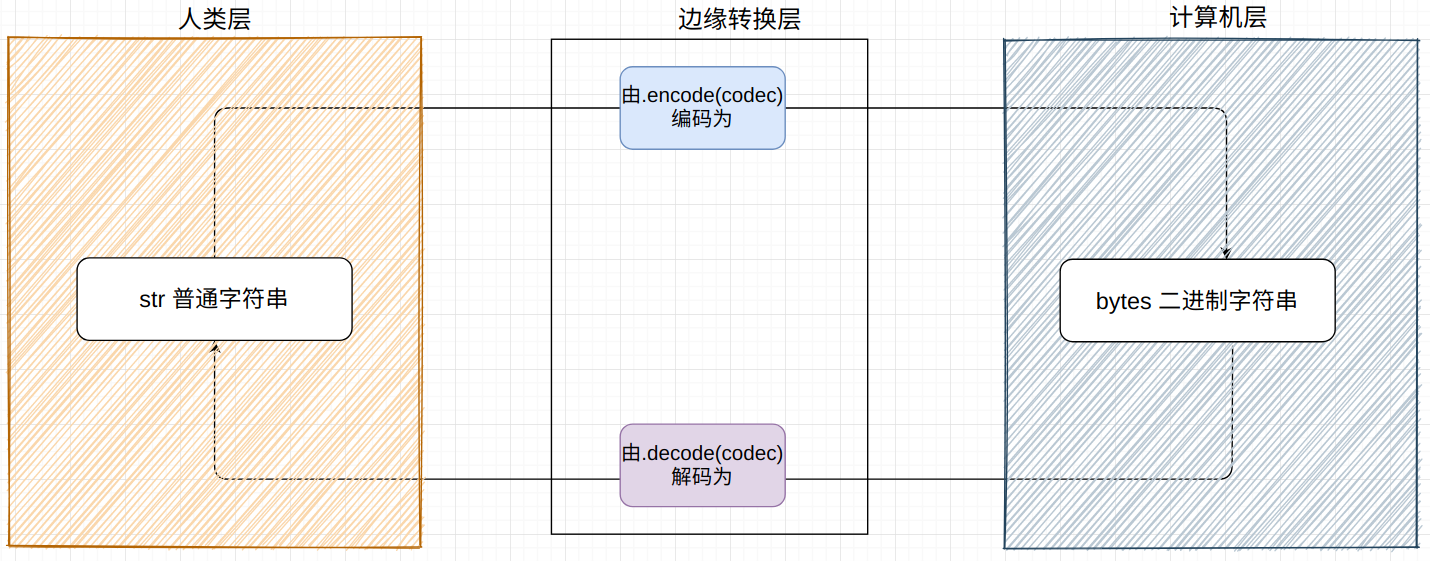
字符串:普通字符串,也称文本,是给人看的,对应python中的字符串 str,使用unicode标准
字节串:二进制字符串,给计算机看,对应python的字节串bytes。
通常来说不需要操作字节串,以下有两种情况可能涉及:
- 程序从文件或其他外部存储读取字节串内容,将其解码为字符串
- 程序完成处理,要把字符串写入文件或其他外部存储,将其编码为字节串
三、容器类型
用按需返回替换容器
用生成器替换列表。生成器具有节省内存的优点,可以将一次性生成全部数据的列表换成生成器返回,节省内存。
def get_item_list():
pass
for i in get_item_list():
print(i)
在这种情况下,可以有两种处理方法
第一种,返回列表:
def get_item_list():
arr = [i for i in range(100)]
return arr
第二种,返回生成器:
def get_item_list():
for i in range(100):
yield i
由于生成器一边生成一遍返回,所以最终只使用一个元素的内存,而列表使用100个元素的内存。
编程建议
- 避开列表的性能陷阱。列表的头插比尾插要慢很多,如果需要头插可以使用collections.deque来替换列表类型
- 使用集合判断成员是否存在。集合底层使用了哈希表数据结构,使用in操作判断,时间复杂度为常数
- 快速合并字典而不破坏原字典的方法:
d1={"name": "apple"} d2={"price": 18} d3={**d1, **d2} - 使用有序字典去重。要去重又要保留原有顺序,可以使用OrderedDict完成
- 禁止在遍历列表时同步修改。遍历过程索引不断增加,而列表成员如果在减少就会导致一些成员不会被访问到
- 继承
MutableMapping方便的创建自定义字典,封装处理逻辑。
from collections.abc import MutableMapping
class PerfLevelDict(MutableMapping):
def __init__(self):
pass
def __getitem__(self, key):
pass
def __setitem__(self, key, value):
pass
def __delitem__(self, key):
pass
def __iter__(self):
pass
def __len__(self):
pass
为什么要自定义字典?
基础数据结构的字典只能通过key获取value,不支持更加复杂的运算。而自定义字典可以在取值的方法__getitem__中实现更加复杂的操作
为什么不直接继承dict而是MutableMapping?
两个原因:
- 直接继承dict会出现更新操作行为不一致的现象。如
PerfLevelDict[key] = value和PerfLevelDict.update({key:value})同样是更新操作,行为却不一致 - MutableMapping是抽象基类,必须要实现6个方法,保证了行为的统一
四、条件分支控制流
使用bisect优化范围分支判断
def func(score):
if score >= 90:
return "S"
elif score >= 80:
return "A"
elif score >= 70:
return "B"
elif score >= 60:
return "c"
else:
return "D"
print(func(85))
import bisect
def func_bisect(score):
breakpoints = [60, 70, 80, 90]
grades= ["D", "C", "B", "A", "S"]
index = bisect.bisect(breakpoints, score)
return grades[index]
print(func_bisect(85))
>>>
A
A
编程建议
- 尽量避免多层分支嵌套。可以通过提前返回减少else分支
- 避免太复杂的条件分支
- 降低不同分支中代码的相似性。将相同逻辑移除分支。不同分支代码相似会增加读者的理解负担。
- 使用摩根定律。not A or not B ==> not (A and B)
- 使用all/any函数构建条件表达式。all和any可以容纳多个条件,让条件判断减少ifelse
- 留意 and 和 or 的优先级。(True or False) and False ==> False 和 True or False and False ==> True 。and优先级高于or
- 避免or运算的陷阱。or 操作有短路特性。
True or (1/0),这个表达式永远不会错误。因为有or的判断,当第一个条件为True之后,就不会执行第二个条件。
如果第一个条件为False,就会返回第二个条件的结果。利用这个特性,也可以减少ifelse判断。
如当配置项为空时获取默认值
default_num = None
num = default_num or 30
但这种写法有一个陷阱,就是如果default_num = 0时,或得的默认值是30而不是0,因为真值判断扩大了范围。本来只有None才能触发的条件,现在可以通过False,0,{},[]等触发。
五、异常处理
优先使用异常,获取原谅比许可更简单
例如以函数接口数据校验为例,使用if判断的方式称之为LBYL(look before you leap),而使用异常捕获的方式被称之为EAFP(easier to forgiveness than permissoin)。前者称之为获取许可,后者称之为获取原谅。Python 社区明显更加偏爱基于异常捕获的EAFP风格。
抛出异常而不是返回错误
返回错误:
def create_item(name):
if len(name) > 10:
return None, "name of item is too long"
if len(name) < 5:
return None, "name of item is too small"
return name
def create_from_input():
name = input()
item, err_msg = create_item(name)
if err_msg:
print(f"create item failed:{err_msg}")
else:
print(f"item<{name}> created")
create_from_input()
抛出异常
class CreateItemError(Exception):
pass
def create_item(name):
if len(name) > 10:
raise CreateItemError("name of item is too long")
if len(name) < 5:
raise CreateItemError("name of item is too small")
return name
def create_from_input():
name = input()
try:
item = create_item(name)
except CreateItemError as e:
print(f"create item failed :{e}")
else:
print(f"item<{name}> created")
create_from_input()
抛出异常比返回错误更好的地方:
- 抛出异常拥有更稳定的返回值类型,永远只返回Item类型或异常类型
- 抛出异常可以层层上报,因此create_from_input可以不处理异常,交给上层处理,但此处有风险。如果一直没有人处理就会让整个程序终止
异常或不异常都是由编程设计者尽心更多方取舍之后的结果,更多时候不存在绝对的优劣之分。单就python而言,使用异常来表达错误更符合python的哲学,更应该受到推崇。
使用上下文管理器
- 用于替代finally语句清理资源
- 用于忽略异常。对于需要忽略的异常使用try except会显得凌乱,在
__exit__中更加方便 - 使用contextmanager装饰器可以更加简单的完成上下文管理器
为什么需要异常捕获:
捕获异常表面上是避免程序因为异常发生而直接崩溃,但它的核心,其实是编码者对处于程序主流程之外的、已知或未知情况的一种妥当处置。
异常捕获建议
- 不要随意忽略异常
- 不要手动做数据校验
- 手动校验数据就是手动做数据类型的判断,如判断数据是否为字符串,长度小于12等。推荐使用专业的校验模块,如pydantic。
- 抛出可区分的异常
- 要继承Exception 而不是BaseException
- 异常类型要以Error或Exception结尾
- 不要使用assert来检查参数合法性。assert是一个专供开发者调试程序的关键字,它提供的断言检查可以使用-o选项直接跳过
- 在可抛可不抛错误的情况下,尽量不要抛出错误,减少调用方处理错误的次数,减轻各方的心智负担。可以通过返回空对象而不是异常,这样调用者方程序不会中断。
- 不要让函数返回错误信息,直接抛出自定义异常
- 过于模糊和宽泛的异常捕获可能会让程序免于崩溃,但是也可能带来更大的麻烦
- 异常捕获贵在精确,只不厚可能抛出异常的语句,支部或可能的异常类型
什么时候需要抛出异常:
- 核心代码,底层代码
- 不可容忍的情况发生,继续执行毫无意义

六 循环和可迭代对象
使用 itertools 模块优化循环
- product() 扁平化多层嵌套循环。prouct可以返回多个列表的笛卡尔积
target = 28
list1 = list2 = list3 = list(range(10))
for x in list1:
for y in list2:
for z in list3:
if x + y + z == target:
print(x,y,z)
from itertools import product
target = 20
list1 = list2 = list3 = list(range(10))
for x,y,z in product(list1, list2, list3):
if x + y + z == target:
print(x, y, z)
- islice 可以对迭代器进行切片
- takeswhile 条件筛选可迭代对象中的元素,只要元素为真就返回,第一次遇到不符合的条件就退出。可以在循环中替换break语句
输出符合条件的数据,遇到不符合的数据就退出
arr = [10,34,5,6,78,44,9]
for i in arr:
if i>= 10:
print(i)
else:
break
takewhile的写法
from itertools import takewhile
arr = [10,34,5,6,78,44,9]
res = takewhile(lambda x: x>=10, arr)
for i in res:
print(i)
正确读取文件的方法
- 读取小文件使用
with open(file_path) as file:
for line in file:
pass
该方法的缺点是:文件是一行一行返回的,不会占用太多内存。但是如果读取的文件没有换行符,那就会一次生成一个巨大的字符串对象。
补充:
python中文件的读取方法有四种:
with open("d.txt") as file:
res = file.read()
print(res)
print("-" * 20)
with open("d.txt") as file:
res = file.readline()
while res:
res = file.readline()
print(res)
print("+" * 20)
with open("d.txt") as file:
res = file.readlines()
print(res)
print("*" * 20)
with open("d.txt") as file:
for i in file:
print(i)
>>>
aaa
bbb
ccc
ddd
--------------------
bbb
ccc
ddd
++++++++++++++++++++
['aaa\n', 'bbb\n', 'ccc\n', 'ddd\n']
********************
aaa
bbb
ccc
ddd
读取文件总的来说两大类方法,一种是使用文件描述符的三种方法,read,readline,readlines;另一种是直接迭代文件描述符,默认使用换行符作为一个迭代元素。
每次读取一行看起来是一个好主意,但是如果一个文件就是一行就会让每次读取一行退化成读取全文,所以要控制每次读取的数据量。
- 读取大文件
with open (file_path) as file:
block_size = 1024 * 8
while True:
chunk = file.read(block_size)
if not chunk:
break
该方法的优点:使用了while循环来读取文件内容,每次最多读取8kb,程序不需要在内存中保存大量的字符串,避免内存占用过大
除此之外,还可以用iter改写这个方法
iter还有一个使用方法:
iter(callable, sentinel)
生成一个特殊的迭代器对象,如果循环遍历这个迭代器,iter就会不断调用callable,返回结果,如果结果等于sentinel就终止迭代
while open(file_path) as file:
_read = partial(fp.read, block_size)
for chunk in iter(_read, ''):
pass
编程建议
- 中断嵌套循环的正确方式:在多重循环中,使用return终止多层循环
- 生成器函数可以用来解耦循环代码,提升可复用性。
装饰可迭代对象 是指用生成器在循环外部包装原本的循环主体,完成一些原本必须在循环内部执行的工作,如过滤特定成员,提供额外结果等,以此简化循环代码。
arr = [10,34,5,6,78,44,9]
def max_than_10():
for i in arr:
if i>= 10:
yield i
for i in max_than_10():
print(i)
- 当心被耗尽的迭代器
>>> number = (i for i in range(4))
>>> 1 in number
True
>>> 1 in number
False
两次同样的操作结果却不相同,原因是:
第一次in操作触发了生成器遍历,找到4返回True;
第二次in操作,生成器已经遍历完了,无法再次遍历找到4,所以返回结果False
除了生成器函数、生成器表达式之外,还有返回生成的函数,如map,filter,reduce等都要小心。
七、函数
函数技巧
- 禁止将可变类型作为函数参数
- 定义仅限关键字参数
函数定义了参数,但是可以通过关键字和位置参数传递,为了限制只能通过关键字传递,可以在参数定义时使用*
def query_users(limit, offset, *, min_followers_count, inculde_profile)
在*之后的参数必须都要通过关键字传递。
也可以定义只能通过位置参数传递,用/标识。在/之前的都必须用位置参数传递。
- 尽量只返回一种类型
- 谨慎返回None
需要返回None的情况有如下三种:
- 操作类函数的默认返回值
- 意料之中的缺失值
- 在执行失败时代表错误
返回None的函数需要满足一下两点:
- 函数的名称和函数必须表达 “结果可能缺失” 的意思
- 如果函数执行无法产生结果,调用方也不关心具体的原因
除此之外对大部分函数来说,返回None不是一个好的做法。可以通过抛出异常来替代返回None更为合理。
- 早返回,多返回
单一出口的编程风格
def func(num):
if num == 0:
pass
elif num == 1:
pass
else:
pass
return
推荐多返回的编程风格
def func(num):
if num == 0:
return
if num == 1:
return
return
编程建议:
- 别写太复杂的函数,可以衡量的标准:
- 长度。不能超过200
- 圈复杂度.不能超过10
- 一个函数只能有符合的抽象
- 编写一个函数是需要考虑函数内代码和抽象界别的关系,假如一个函数内同时包含了多个抽象级别的内容,会引发一些列的问题。如:
- 函数的说明性不够。很难搞清楚的主流程,复杂度大,难理解
- 函数的可复用性差,多层抽象杂糅在一起,无法复用某一个抽象。
面对这个问题需要基于抽象重构代码。抽象和分层思想可以帮我们更好的构建和管理复杂的系统
- 优先使用列表推导式。列表推导式的描述性更强
例如获取所有活跃状态的用户积分
函数式编程:
points = list(map(query_points, filter(lambda user: user.is_active(), users)))
列表推导式:
points = [query_points(user) for user in users if user.is_active()]
- 函数与状态
如果一个函数根据执行的次数而表现不一致就是有状态的函数,存在这种情况需要注意:
- 避免使用全局变量给函数增加状态
- 当函数状态简单时,可以使用闭包技巧
- 当函数需要较为复杂的状态管理时,建议定义类来管理状态
思想:
虽然函数可以消除重复代码,但决不能只把它看成一种复用代码的工具,函数最重要的价值是创建合适的抽象,而提供复用价值可以说是抽象带来的一个副作用。所以想要写出好的函数,秘诀就在于设计好的抽象。
八、装饰器
装饰器是一种通过包装目标函数来修改其行为的特殊高阶函数,绝大多数装饰器是利用函数的闭包原理实现的
不带参数装饰器
import time
import random
def timer(func):
def decorated(*args, **kwargs):
st = time.time()
ret = func(*args, **kwargs)
print("time cost: {} seconds".format(time.time() - st))
return ret
return decorated
@timer
def random_sleep():
time.sleep(random.randint(0,5))
random_sleep()
>>> time cost: 2.0021181106567383 seconds
def random_sleep():
time.sleep(random.randint(0,5))
decorated = timer(random_sleep)
decorated()
>>> time cost: 2.1457672119140625e-05 seconds
带参数装饰器
def timer(print_args):
def decorator(func):
def wrapper(*args, **kwargs):
st = time.time()
ret = func(*args, **kwargs)
if print_args:
print(f"{func.__name__}, args: {args}, kwargs: {kwargs}")
print("time cost: {} seconds".format(time.time() - st))
return ret
return wrapper
return decorator
@timer(print_args=True)
def random_sleep():
time.sleep(random.randint(0,5))
random_sleep()
>>> random_sleep, args: (), kwargs: {}
time cost: 9.34600830078125e-05 seconds
def random_sleep():
time.sleep(random.randint(0,5))
# 传入参数, 获得内一层函数
decorator = timer(print_args=True)
# 真正的装饰器,返回新的函数
wrapper = decorator(random_sleep)
wrapper()
>>> random_sleep, args: (), kwargs: {}
time cost: 2.0015923976898193 seconds
装饰器缺点是会丢失被装饰函数的元数据,所以通过functools.wraps可以避免这个问题
用类实现装饰器(函数替换)
class timer:
def __init__(self, print_args):
self.print_args = print_args
def __call__(self, func):
def decorator(*args, **kwargs):
st = time.time()
ret = func(*args, **kwargs)
if self.print_args:
print(f"{func.__name__}, args: {args}, kwargs: {kwargs}")
print("time cost: {} seconds".format(time.time() - st))
return ret
return decorator
@timer(print_args=True)
def random_sleep():
time.sleep(random.randint(0,5))
random_sleep()
>>> random_sleep, args: (), kwargs: {}
time cost: 5.004449367523193 seconds
def random_sleep():
time.sleep(random.randint(0,5))
timer_instance = timer(print_args=True)
decorator = timer_instance(random_sleep)
decorator()
>>>
random_sleep, args: (), kwargs: {}
time cost: 1.000887393951416 seconds
用类实例实现装饰器(实例替换)
class DelayedStart:
def __init__(self, func):
self.func = func
def __call__(self, *args, **kwargs):
time.sleep(1)
print("wait for 1 second")
return self.func(*args, **kwargs)
def eager_call(self, *args, **kwargs):
print("call without delay")
return self.func(*args, **kwargs)
# demo已经变成DelayedStart的一个实例,等同于 demo = DelayedStart()
@DelayedStart
def demo():
print("hello world")
# 相当于调用__call__方法
# demo()
# 调用额外方法
# demo.eager_call()
编程建议
- 装饰器的意义
装饰器带来的改变,主要在于把修改函数的调用提前到函数定义处,而这一点位置上的小变化,重塑了读者理解代码的整个过程
装饰器适合的场景:
-
运行时校验:在执行阶段进行特定校验,当检验不通过时终止执行
适合原因:装饰器可以方便地在函数执行前介入,并且可以读取所有参数辅助校验
代表样例:Django 框架中用户登录态校验装饰器@login_required -
注入额外参数:在函数调用时自动注入额外的调用参数
适合原因:装饰器的位置在函数头部,非常靠近参数被定义的位置,关联性强
代表样例:unittest.mock模块的装饰器@patch -
缓存执行结果:通过调用参数等输入信息,直接缓存函数执行结果
适合原因:添加缓存不需要侵入函数内部逻辑,并且功能非常独立和通用
代表样例:funcools模块的缓存装饰器@lru_cache -
注册函数
适合原因:定义函数可以直接完成注册,关联性强
代表样例:Flask框架的路由注册装饰器@app.route -
替换为复杂对象:将原函数替换为更加复杂的对象,比如类实例或特殊的描述符对象
适合原因:在执行替换操作时,装饰器语法天然比foo=staticmethod(foo)的写法要直观很多
代表样例:静态类方法装饰器@staticmethod
装饰器和装饰器模式
装饰器模式和装饰器是截然不同的东西。
装饰器模式是通过组合的方式使用各种类,通过类与类之间的层层包装来实现复杂的功能(将一个类传递到另一个类)
九、面向对象
私有属性是君子协定
python中所有类的属性和方法默认都是公开的,可以通过添加双下划线前缀将其标注为私有,仅为标注没有语法上的保护。__{var}定义的私有属性,python只是给它重命名了为_{class}__{var},任然可以通过这个别名来访问。
私有属性最大的用途,就是在父类中定义一个不容易被子类重写的受保护属性。实际编程中极少使用
实例内容都在字典里
类实例所有的成员都保存在__dict__属性中,类也有__dict__,保存类的文档、方法等数据
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def say(self):
print("hi, My name is {self.name}, I'm {self.age}")
p = Person("ljk", 20)
print(p.__dict__)
>>>
{'name': 'ljk', 'age': 20}
print(Person.__dict__)
>>>
{'__module__': '__main__', '__init__': <function Person.__init__ at 0x7f78e6451670>, 'say': <function Person.say at 0x7f78e6331dc0>, '__dict__': <attribute '__dict__' of 'Person' objects>, '__weakref__': <attribute '__weakref__' of 'Person' objects>, '__doc__': None}
类方法
用@classmethod装饰器定义一种特殊方法:类方法,它属于类但是无需实例化也可以调用
静态方法
用@stamethod装饰器定义静态方法。静态方法依附于类,但是和类的其他属性和方法没有关系,多用于独立函数的创建
属性方法
类属性通常要使用inst.method()方法调用,使用@property装饰器将一个方法变成属性,通过inst.method来调用
class DemolayedStart:
@propety
def func(self):
pass
@func.setter
def func(self):
pass
@func.deleter
def func(self):
pass
@property装饰,func已经从一个普通方法变成一个属性
定义setter方法,该方法会在对属性复制时被调用
定义deleter方法,该方法会在删除属性时被调用
使用场景:
属性方法用于迅速拿到接口的场景,可以是对变量的转化或处理,不适用于耗时较长的方法
鸭子类型
鸭子类型是一种编程风格,而不是语言的类型。通俗的解释:
当看到一只鸟走起来像鸭子、游泳起来像鸭子、叫起来也像鸭子,那么这只鸟就是鸭子
在鸭子类型风格下,如果要操作某些对象,不需要判断它的类型,直接判断它有没有需要的方法,甚至可以直接调用需要的方法。
鸭子类型的局限性:
- 缺乏标准:使用鸭子类型需要频繁判断对象是否支持某个行为,并且没有统一的判断标准
- 过于隐式:对象的真实类型不再重要,取而代之的是对象提供的接口变得非常重要。但是所有接口都是隐式,全都藏在代码和函数注释中
鸭子类型的约束:抽象类。python中没有接口这个概念,但是可以通过抽象类实现类似接口的功能。继承自抽象类的子类需要实现抽象类中所有的方法,让鸭子类型更加清晰。
多重继承
python中一个类可以同时继承多个父类,在解决多重继承的方法优先级问题时,Python使用了一种名为MRO的算法,该算法会遍历类的所有父类,并将它们按照优先级从高到底排序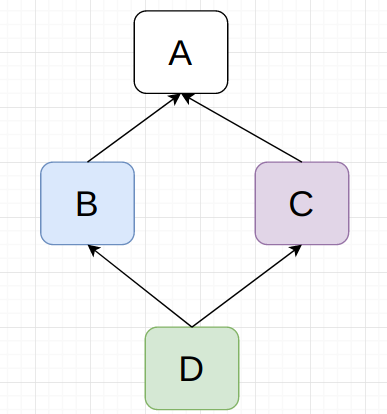
如上D继承B和C,那么在寻找一个方法时,遍历顺序是D->B->c->A,这条优先级链中只要找到就结束。
super 是一个用来调用父类方法的工具函数,super其实使用的不是当前类的父类,而是MRO链条里的上一个类
其他知识
面向对象的建模方式:针对事务的行为建模,而不是对事物本身建模。多数情况下基于事务的行为建模,可以孵化出更好、更灵活的模型设计。
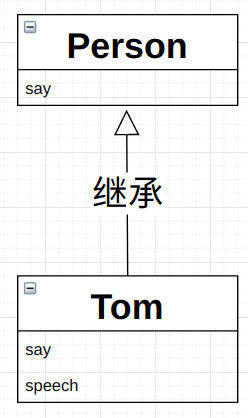
例如:一个类person,拥有方法say,子类Tom继承person。Tom有一个speech的能力,依赖于父类say。如果Person的say被修改,那么Tom的speech也会被影响。这个问题的原因就在于继承虽然能最低成本的复用功能,但是也会带来连锁反应。
继承是一种类与类之间精密的耦合关系,让子类继承父类,虽然看上去毫无成本的获取了父类的全部能力,但是也同时意味着,从此以后父类的所有改动都会影响子类。可以通过组合来解决复用的问题。
所谓组合就是将一个类当做参数传入另一个类中。

将事务的行为抽象一个类,通过传参的方式使用该类,这样也能复用,将不同点在自身逻辑中实现,这样能更加灵活的使用抽象。
多态
利用多态有效解决过多的逻辑判断
逻辑判断写法
class Save:
def __init__(self, file_type):
self.file_type = file_type
def save_log(self):
if self.file_type == "txt":
print("txt")
elif self.file_type == "tar":
print("tar")
elif self.file_type == "ini":
print("ini")
file_save = Save("tar")
file_save.save_log()
>>> tar
file_save = Save("ini")
file_save.save_log()
>> ini
file_save = Save("txt")
file_save.save_log()
>> txt
多态写法
class SaveFactory:
def __init__(self, save_obj):
self.save_obj = save_obj
def save_log(self):
self.save_obj().save_log()
class Txt:
def save_log(self):
print("txt")
class Tar:
def save_log(self):
print("tar")
txt = SaveFactory(Txt)
txt.save_log()
使用多态的时机
当你发现自己的代码出现以下特征时:
- 有许多if/else的判断,并且这些判断语句的条件都非常类似
- 有许多针对类型的
isinstance()判断逻辑
有序组织类
__init__实例化方法应该总是放在类的最前面,__new__方法类似- 公有方法应该放在类的前面,因为他们是其他模块调用类的入口
- 以
_开头的私有方法,大部分是类自身的实现细节,应该放在靠后的位置 - 类方法,静态方法和属性对象参考公有私有方法的思路即可
- 以
__开头的魔法方法,通常要按照方法的重要程度决定他们的位置。如__iter__应该放在非常靠前的位置
面向对象设计的两个技巧
- 将类的实例化变成函数调用,降低API使用成本
request 库的实现是一个类,但是为方便调用,提供函数方法request.get,request.post等。函数作为一种简化API的工具,封装了复杂的面向对象功能,大大降低使用成本
- 用全局实例替换多次实例化
项目启动时要从配置文件中读取所有配置项,然后将其加载到内存中供其他模块使用。由于程序只需要一个全局的配置对象,因此非常适合使用经典设计模式:单例模式。
python中实现单例模式的方法有很多种,如重写类的方法__new__。但是python中最简单的单例模式就是import机制。在python中执行import语句,无论import导入模块多少次,只会在内存中存在一份。因此要实现单例模式,只需要在模块里创建一个全局对象并导入即可。如下:
class AppConfig:
def __init__(self):
pass
_config == AppConfig()
十/十一、面向对象的设计原则
面向对象设计原则中最有名的是SOLID。SOLID中五个字母分别代表5条设计原则:
- S:singel responsibility principle 单一职责原则 SRP
- O: open-closed principle 开放-关闭原则 OCP
- L:Liskov substitution priciple 里式替换原则 LSP
- I: iterface segregation principle 接口隔离原则 ISP
- D: dependency inversion principle 依赖倒置原则 DIP
单一职责原则
定义:一个类只做一件事情,仅有一个被修改的理由。
所谓修改的理由是指功能发生变化需要修改,那么单一职责原则是如果有新功能要完成,只会有一个地方被修改,只有一处会变化。
优点:
- 功能互相独立,耦合性降低
- 复用性增强
- 功能之间修改不会互相影响
实现方法:
- 将大类拆解成小类
- 使用组合方式组装各个小类
开放-关闭原则
定义:类应该对扩展开放,对修改关闭。
修改关闭是指不修改代码,扩展开放是指新增功能。OCP原则的意思就是在不修改代码的前提下新增功能
优点:
- 代码改动量少
- 新增功能效率高
实现方法:
将会频繁变动的代码抽象出来,通过功能覆盖而实现支持变化
- 通过继承改造代码。在子类中继承基本方法,复写变动的方法,实现功能覆盖
- 使用组合与依赖注入。将变动部分的功能通过参数的方式传递到对象中
- 使用数据驱动。将经常变动的部分以数据的方式抽离出来,当需求变化时只改动数据,代码逻辑保持不变
继承实现OCP
class News:
def fetch(self, url):
res = request.get(url)
def get_data(self):
res = self.fetch("www.baidu.com")
# 数据处理
class Blog(News):
def get_data(self):
res = self.fetch("www.sina.com")
组合与依赖实现OCP
class Fetch:
def __init__(self, handler):
self.handler = handler
def fetch(self):
res = self.handler.get_data()
return res
class Sina:
def get_data(self):
res = requests.get("www.sina.com")
return res
class Baidu:
def get_data(self):
res = requests.get("www.baidu.com")
return res
sina_obj = Sina()
sina_data = Fetch(sina_obj)
baidu_obj = Baidu()
baidu_data = Fetch(baidu_obj)
数据驱动实现OCP
class Fetch:
def __init__(self, url):
self.url = url
def fetch(self):
res = request.get(url)
return res
sina = Fetch("www.sina.com")
baidu = Fetch("www.baidu.com")
里式替换原则
定义:在某一个功能变动时子类对象可不做修改的替换父类对象
子类如果想不做修改的替换父类,就需要子类的参数、返回值类型、抛出的异常要和父类一致
优点:可以将多态的潜能发挥出来
实现方法:
- 子类抛出的异常父类也认识
- 子类方法的返回值类型和父类一致
- 子类的方法参数和父类一致,或者比父类宽松
依赖倒置原则
定义:高层模块不应该直接依赖底层模块,两者都应该依赖抽象
高层模块不再直接依赖底层模块,因为底层模块变动就会让高层报错,高层模块要依赖处于中间的抽象层,底层模块也依赖抽象层,这样能解耦高层模块和底层模块
优点:解耦模块依赖关系、让代码变的灵活
实现方法:定义抽象类
接口隔离原则
定义:一个接口提供的方法应该刚好满足使用方的需求,一个不多,一个不少。
例如,当判断用户是不是新用户时传入request对象,其实只使用了里面的cookie属性,这就是不符合接口隔离原则。那么下次再使用这个接口时需要传入的就是整个对象,而不是一个cookie属性。
优点:减少依赖,参数容易构造。
实现方法:拆分接口,实现小类,小接口。
十二、数据模型和描述符
数据模型就是python自有的数据类型,及其包含的特殊方法。所有与数据模型有关的方法,基本都是以双下划线开头和结尾,通常也被称为魔法方法
__str__方法定义了对象的表现形式
class Person:
def __init__(self, name):
self.name = name
p = Person("zhangsan")
print(p)
>>>
<__main__.Person object at 0x7f6030f24470>
class Person:
def __init__(self, name):
self.name = name
def __str__(self):
return self.name
p = Person("zhangsan")
print(p)
>>>
zhangsan
比较运算符重载
比较运算符是指专门用来对比两个对象的运算符,如 == != > 等。在python中可以通过魔法方法来重载它们的行为用于两个对象之间的需要比较的场景。
如两个正方形对象的比较
class Square:
def __init__(self, length):
self.length = length
def area(self):
return self.length ** 2
sq1 = Square(4)
sq2 = Square(4)
print(sq1 == sq2)
>>> False
加入魔法方法__eq__
class Square:
def __init__(self, length):
self.length = length
def area(self):
return self.length ** 2
def __eq__(self, other):
if isinstance(other, self.__class__):
return self.length == other.length
sq1 = Square(4)
sq2 = Square(4)
print(sq1 == sq2)
>>> True
魔法方法
在python中,以双下划线开头和结尾的方法叫魔法方法,魔法方法可以理解为:对类中的内置方法的重载。
常见的魔法方法:
__init__: 对象的初始化__new__: 对象的创建__del__: 对象删除触发__str__: 改变对象显示__eq__: 比较对象__setattr__: 设置实例属性不存在时调用__getattr__: 获取实例属性时调用__getattribute__: 访问实例属性调用__getitem__:对象取值__setitem__:设置对象的键值对
class Demo:
def __init__(self, arr):
self.arr = arr
def __len__(self):
return len(self.arr) * 10
# 使用[]取值时,返回所给键对应的值。
# 当对象是序列时,键是整数。
# 当对象是字典,键是任意值
# __getitem__方法和__iter__都可以将对象变成可迭代对象。且__iter__优先级更高
def __getitem__(self, index):
return self.arr[index]
# 设置给定键的值
def __setitem__(self, key, value):
if len(self.arr) < key:
print("index 不存在")
else:
print(f"设置index:{key}")
self.arr[key] = value
# 对象取值时,取值的顺序为:
# 1. 先从object里__getattribute__中找
# 2. 第二步从对象的属性中找
# 3. 第三步从对应类属性中找
# 4. 第四步从父类中找
# 5. 第五步从__getattr__中找,如果没有,直接抛出异常。
def __getattr__(self, attr):
return f"{attr} not found"
# 设置属性时调用
def __setattr__(self, key, value):
if isinstance(value, int):
value = abs(value)
object.__setattr__(self, key, value)
# 访问实例的属性时就是调用这个方法
def __getattribute__(self, attr):
print("__getattribute__ 被调用")
return object.__getattribute__(self, attr)
demo = Demo([1,2,3,4,5])
print(len(demo))
>>>
__getattribute__ 被调用
50
print(demo[3])
>>>
__getattribute__ 被调用
4
print(demo.arr)
>>>
__getattribute__ 被调用
[1, 2, 3, 4, 5]
print(demo.abc)
>>>
__getattribute__ 被调用
abc not found
demo.abc = -100
print(demo.abc)
>>>
__getattribute__ 被调用
100
demo[6] = 100
>>>
__getattribute__ 被调用
index 不存在
demo[2] = 100
>>>
__getattribute__ 被调用
设置index:2
描述符
在 Python 中,允许把一个属性托管给一个类,这个类就是一个描述符,也叫描述符类。描述符类拥有__get__,__set__,__delete__等方法。
把描述符理解为:对象的属性不再是一个具体的值,而是交给了一个类去定义。
class Ten:
def __get__(self, obj, objtype=None):
return 10
class A:
x = Ten() # 属性换成了一个类
print(A.x) # 10
描述符的优点:
我们就可以在方法内实现自己的逻辑,最简单的,我们可以根据不同的条件,在方法内给属性赋予不同的值
class Age:
def __get__(self, obj, objtype=None):
if obj.name == 'zhangsan':
return 20
elif obj.name == 'lisi':
return 25
else:
return ValueError("unknow")
class Person:
age = Age()
def __init__(self, name):
self.name = name
p1 = Person('zhangsan')
print(p1.age) # 20
p2 = Person('lisi')
print(p2.age) # 25
p3 = Person('wangwu')
print(p3.age) # unknow
>>>
20
25
unknow
__get__(self, obj, type=None) -> value
__set__(self, obj, value) -> None
__delete__(self, obj) -> None
只要是实现了以上几个方法的其中一个,那么这个类属性就可以称作描述符。
另外,描述符又可以分为数据描述符和非数据描述符:
- 只定义了
__get___,叫做非数据描述符 - 除了定义
__get__之外,还定义了__set__或__delete__,叫做数据描述符
数据描述器和非数据描述器的区别在于:它们相对于实例的字典的优先级不同。
实例字典中有与描述符同名的属性:
- 描述符是数据描述符,优先使用数据描述符;
- 非数据描述符,优先使用字典中的属性。
描述符原理
描述符的参数说明
class Desc(object):
def __get__(self, instance, owner):
print("__get__...")
print("self : \t\t", self)
print("instance : \t", instance)
print("owner : \t", owner)
print('='*40, "\n")
def __set__(self, instance, value):
print('__set__...')
print("self : \t\t", self)
print("instance : \t", instance)
print("value : \t", value)
print('='*40, "\n")
class TestDesc(object):
x = Desc()
#以下为测试代码
t = TestDesc()
t.x
#以下为输出信息:
>>>
__get__...
self : <__main__.Desc object at 0x0000000002B0B828>
instance : <__main__.TestDesc object at 0x0000000002B0BA20>
owner : <class '__main__.TestDesc'>
可以看到,实例化类TestDesc后,调用对象t访问其属性x,会自动调用类Desc的 __get__方法,由输出信息可以看出:
① self: Desc的实例,其实就是TestDesc的属性x
② instance: TestDesc的实例,其实就是t
③ owner: 即谁拥有这些东西,当然是 TestDesc这个类,它是最高统治者,其他的一些都是包含在它的内部或者由它生出来的
说明:
Desc类就是是一个描述符(描述符是一个类),因为类Desc定义了方法 __get__,__set__。
描述符类的访问规则:
t为实例,访问t.x时,根据常规顺序,
- 首先:访问TestDesc的
__getattribute__()方法访问实例属性,发现没有,然后去访问TestDesc类属性,找到了! - 其次:判断属性 x 为一个描述符,此时,它就会做一些变动了,将 TestDesc.x 转化为
TestDesc.__dict__['x'].__get__()来访问 - 然后:进入类Desc的
__get__()方法,进行相应的操作
描述符做实例属性
#代码 2
class Desc(object):
def __init__(self, name):
self.name = name
def __get__(self, instance, owner):
print("__get__...")
print('name = ',self.name)
print('='*40, "\n")
class TestDesc(object):
x = Desc('x')
def __init__(self):
self.y = Desc('y')
#以下为测试代码
t = TestDesc()
t.x
t.y
#以下为输出结果:
__get__...
name = x
========================================
调用 t.y 时刻,首先会去调用TestDesc(即Owner)的 __getattribute__() 方法,由于在t这个实例中找到了y,就不会再去Desc中找了
类属性和实例属性同时存在
#代码 3
class Desc(object):
def __init__(self, name):
self.name = name
print("__init__(): name = ",self.name)
def __get__(self, instance, owner):
print("__get__() ...")
return self.name
def __set__(self, instance, value):
self.value = value
class TestDesc(object):
_x = Desc('x')
def __init__(self, x):
self._x = x
#以下为测试代码
t = TestDesc(10)
t._x
#输入结果
__init__(): name = x
__get__() ...
这就牵扯到了一个查找顺序问题:当Python解释器发现实例对象的字典中,有与描述符同名的属性时,描述符优先,会覆盖掉实例属性。
非数据描述符
#代码 4
class Desc(object):
def __init__(self, name):
self.name = name
print("__init__(): name = ",self.name)
def __get__(self, instance, owner):
print("__get__() ...")
return self.name
class TestDesc(object):
_x = Desc('x')
def __init__(self, x):
self._x = x
#以下为测试代码
t = TestDesc(10)
t._x
#以下为输出:
__init__(): name = x
属性查找优先级惹的祸,只是定义一个 __get__() 方法,为非数据描述符。非数据描述符,描述符优先级低于实例属性。所有查找到的是实例的属性
数据描述符和非数据描述符:
一个类,如果只定义了 __get__() 方法,而没有定义 __set__(), __delete__() 方法,则认为是非数据描述符; 反之,则成为数据描述符
属性描述符的使用场景
描述符的主要作用是用于复杂属性的行为控制,适合的场景如下:
- 用于参数校验,属性校验
- 利用描述符实现缓存和只读属性
对象的set去重
通常使用集合来去除重复的元素,凡是可以hash的数据类型都可以,如数字,字符串等。如果要对一个对象使用集合去重就需要特殊的操作。
使用集合去重对象,会存在一个问题,就是即使两个参数都相同的对象,比较结果是不同。
class Demo:
def __init__(self, name, age):
self.name = name
self.age = age
demo1 = Demo("tom", 20)
demo2 = Demo("tom", 20)
print(demo1 == demo2)
>>> False
因为对象之间比较的是内存空间,所以两个对象的内存空间肯定不一样。那么就需要重写__eq__方法,重载对象的比较。
class Demo:
def __init__(self, name, age):
self.name = name
self.age = age
def __eq__(self, other):
if isinstance(other, self.__class__):
return (self.name, self.age) == (other.name, other.age)
demo1 = Demo("tom", 20)
demo2 = Demo("tom", 20)
print(demo1 == demo2)
>>> True
通过重载__eq__方法可以让两个对象之间支持比较,但是会遇到一个新的问题,那就是对象不可以hash。
class Demo:
def __init__(self, name, age):
self.name = name
self.age = age
def __eq__(self, other):
if isinstance(other, self.__class__):
return (self.name, self.age) == (other.name, other.age)
demo1 = Demo("tom", 20)
demo2 = Demo("tom", 20)
print(demo1 == demo2)
demo_set = set()
demo_set.add(demo1)
>>>
True
Traceback (most recent call last):
File "rule_demo.py", line 95, in <module>
demo_set.add(demo1)
TypeError: unhashable type: 'Demo'
原因是对象在hash时使用的是对象的ID,现在重写了__eq__方法,就会出现一个现象:两个对象在逻辑上相同,但是他们的hash值不同。这是一个严重的悖论,所以python强制要求,如果重写了__eq__方法直接将对象变成不可hash,强制要求重新设计hash值算法。
class Demo:
def __init__(self, name, age):
self.name = name
self.age = age
def __eq__(self, other):
if isinstance(other, self.__class__):
return (self.name, self.age) == (other.name, other.age)
def __hash__(self):
return hash((self.name, self.age))
demo1 = Demo("tom", 20)
demo2 = Demo("tom", 20)
print(demo1 == demo2)
demo_set = set()
demo_set.add(demo1)
>>> True
增加__hash__之后,就可以将对象保存到集合中。
使用dataclass实现对象去重
dataclass 是3.7之后的一个内置模块,主要用于是利用类型注解的语法快速定义类似上面Demo的数据类。所谓数据类就是只用于保存数据不做方法处理的类。
通过dataclass定义的一个数据类,可以自动实现__eq__ 和 __hash__方法,不需要手动实现。
说要说明的是要增加参数(frozen=True),默认创建的数据类可以修改参数不支持hash操作,使用fronzen=True显示的将当前类变成不可变类型,能正常计算hash值。
from dataclasses import dataclass
@dataclass(frozen=True)
class Demo:
name: str
age: int
demo1 = Demo("tom", 20)
demo2 = Demo("tom", 20)
print(demo1 == demo2)
demo_set = set()
demo_set.add(demo1)
dataclass 补充
dataclass 是一个用来保存数据的类,不需要__init__方法就可以使用的类
from dataclasses import dataclass
@dataclass
class Demo:
name: str = ""
age: int = 0
demo = Demo(name="张三", age=200)
>>> demo
Demo(name='张三', age=200)
>>> print(demo)
Demo(name='张三', age=200)
dataclass的特点:
- 相比普通class,dataclass通常不包含私有属性,数据可以直接访问
- dataclass的repr方法通常有固定格式,会打印出类型名以及属性名和它的值
- dataclass拥有
__eq__和__hash__魔法方法 - dataclass有着模式单一固定的构造方式,或是需要重载运算符,而普通class通常无需这些工作
关于dataclass拥有__eq__和__hash__魔法方法这一点做出说明,__eq__魔法方法作用是让两个对象可以比较,__hash__魔法方法作用是让对象可以hash。通常来说重写__eq__方法就需要重写__hash__方法。
tom = Demo(name="tom", age=19)
jack = Demo(name="jack", age=20)
>>> tom == jack
False
dataclass 会自动实现__eq__和__hash__方法,__eq__方法的比较规则是将所有属性组合成元组,比较元祖。
tom == jack 等价与 (“tom”, 19) == (“jack”, 20), __hash__方法也类似,用属性组成的元组作为hash的数据,然后比较。
dataclass 的原型
dataclass(init=True, repr=True, eq=True, order=False, unsafe_hash=False, frozen=False)
- init:默认将生成__init__方法。如果传入False,那么该类将不会有__init__方法。
- repr:__repr__方法默认生成。如果传入False,那么该类将不会有__repr__方法。
- eq:默认将生成__eq__方法。如果传入False,那么__eq__方法将不会被dataclass添加,但默认为object.eq。
- order:默认将生成
__gt_、__ge__、__lt_、__le__方法。如果传入False,则省略它们。 - frozen:设置为True,那么实例在初始化后无法修改其属性
post_init:
使用dataclass装饰的类一个主要优势就是不用手动去实现__init__方法,但我们经常需要在对象初始化的时候对一些数据进行校验或者额外操作,此时一个选择是手动实现__init__方法,其中会有大段的初始化代码,例如self.a=a;self.b=b。另一个选择是定义__post_init__方法来进行初始化操作,优点是可以不需要完成属性赋值而直接使用。
from dataclasses import dataclass
@dataclass
class Demo:
name: str = ""
age: int = 0
def __post_init__(self):
if self.age < 18:
raise Exception("age lower than 18")
tom = Demo(name="tom", age=10)
>>>
Traceback (most recent call last):
File "dataclass_deo.py", line 14, in <module>
tom = Demo(name="tom", age=10)
File "<string>", line 4, in __init__
File "dataclass_deo.py", line 10, in __post_init__
raise Exception("age lower than 18")
Exception: age lower than 18
__post__init__在所有属性初始化之后,被__init__调用。通常,dataclass对象的创建以__init__开始,以__post__init__结束。
也就是说__post_init__是在__init__中被调用,如果没有__init__则会自动调用。如果__init__中没有调用__post_init__,那么即使定义了__post_init__也不会被调用。
数据模型的使用
class Events:
def __init__(self, events):
self.events = events
def is_empty(self):
return not bool(self.events)
def list_events_by_range(self, start, end):
return self.events[start: end]
events = Events(["compute_start", "os lanuched", "docker startd"])
if not events.is_empty():
print(events.list_events_by_range(1,3))
['os lanuched', 'docker startd']
上面代码时散发着浓浓的传统面对对象的气味,如果用数据模型的知识,可以将其改造的更加符合python的风格。
class Events:
def __init__(self, events):
self.events = events
def __len__(self):
return len(self.events)
def __getitem__(self, index):
return self.events[index]
events = Events(["compute_start", "os lanuched", "docker startd"])
if events:
print(events[1:3])
>>>
['os lanuched', 'docker startd']
不要依赖__del__方法
class Foo:
def __del__(self):
print(f"cleaning up {self}....")
foo = Foo()
del foo
>>> cleaning up <__main__.Foo object at 0x7fdc738b2e80>....
一个对象的__del__方法,并非在使用del语句时被触发,而是在他被作为垃圾回收时触发。del语句无法直接回收任务东西,他只能简单的删除指向当前对象的一个引用而已。
依赖__del__方法做一些清理资源、释放锁、关闭连接池之类的关键工作是非常危险的。因为创建的对象完全有可能因为某些原因一直都不被当做垃圾回收,这样网络连接会不断增长,锁也一直无法释放。
十三、开发大型项目
常用工具介绍
flake8: 检查代码是否遵循了PEP8规范
功能:
- 代码风格
- 语法错误
- 函数复杂度
isort:导入模块规范化
导入模块规则:
- 第一部分:标准库包
- 第二部分:第三方包
- 第三部分:本地包
black:更加严格的代码检查,只支持少量的参数
pre-commit:
pre-commit预提交,是git hooks中的一个钩子,由git commit命令调用,通常用于在提交代码前,进行代码规范检查.
mypy:
mypy 是 Python 中的静态类型检查器。可以在Python程序中添加类型提示(PEP 484),并使用mypy进行静态类型检查。查找程序中的错误。
单元测试:
unittest、pytest
单元测试建议:
- 写单元测试不是浪费时间
- 不要总想着补交单元测试
- 难测试的代码就是烂代码
- 想对待应用一样对待测试代码
- 避免教条主义
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/196522.html

