

树
树是一种很有规律的数据结构,如果使用合适的访问方法,可以很便捷高效的解决问题。比如递归
题目:
- 树的最大深度
- 验证二叉搜索树
- 对称二叉树
- 路径总和
- 二叉树的序列化与反序列化
- 树的公共父节点
树的最大深度
二叉树的最大深度
给定一个二叉树,找出其最大深度。
二叉树的深度为根节点到最远叶子节点的最长路径上的节点数。
说明: 叶子节点是指没有子节点的节点。
示例:
给定二叉树 [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
返回它的最大深度 3 。
从底向上
class Solution:
def maxDepth(self, root: TreeNode) -> int:
if not root:
return 0
else:
left = self.maxDepth(root.left)
right = self.maxDepth(root.right)
print("%d--%d" % (left,right))
return max(left,right) + 1
从顶向下
该调用方式是所谓的尾递归调用,所以比普通的调用方式更加高效和节省内存
class Solution:
def maxDepth(self, root: TreeNode) -> int:
def top_down(node,h):
if node is None:
return h
left = top_down(node.left, h+1)
right = top_down(node.right, h+1)
return max(left, right)
ret = top_down(root,0)
return ret
验证二叉搜索树
验证二叉搜索树
给定一个二叉树,判断其是否是一个有效的二叉搜索树。
假设一个二叉搜索树具有如下特征:
节点的左子树只包含小于当前节点的数。
节点的右子树只包含大于当前节点的数。
所有左子树和右子树自身必须也是二叉搜索树。
示例 1:
输入:
2
/ \
1 3
输出: true
示例 2:
输入:
5
/ \
1 4
/ \
3 6
输出: false
解释: 输入为: [5,1,4,null,null,3,6]。
根节点的值为 5 ,但是其右子节点值为 4 。
方法:这道题的规律也很明显,左边的值小于父节点,右边的值大于父节点。其子节点也是类似。有两种方式:1.中序遍历可以得到一个升序的数组,只要判断数组是否为完全升序即可;2.判断当前节点值在不在某个正常范围中
首先,我们来看二叉搜索树的两个特征:
节点的左子树只包含小于当前节点的数。
节点的右子树只包含大于当前节点的数。
仔细思考这两句话,你可以理解为:
当前节点的值是其左子树的值的上界(最大值)
当前节点的值是其右子树的值的下界(最小值)
OK,有了这个想法,你可以将验证二叉搜索树的过程抽象成下图(-00代表无穷小,+00代表无穷大)

class Solution:
def isValidBST(self, root: TreeNode) -> bool:
def dfs(node, min_val, max_val):
if not node: # 边界条件,如果node为空肯定是二叉搜索树
return True
if not min_val < node.val < max_val: # 如果当前节点超出上下界范围,肯定不是
return False
# 走到下面这步说明已经满足了如题所述的二叉搜索树的前两个条件
# 那么只需要递归判断当前节点的左右子树是否同时是二叉搜索树即可
return dfs(node.left, min_val, node.val) and dfs(node.right, node.val, max_val)
return dfs(root, float('-inf'), float('inf')) # 对于根节点,它的上下限为无穷大和无穷小
对称二叉树
对称二叉树
给定一个二叉树,检查它是否是镜像对称的。
例如,二叉树 [1,2,2,3,4,4,3] 是对称的。
1
/ \
2 2
/ \ / \
3 4 4 3
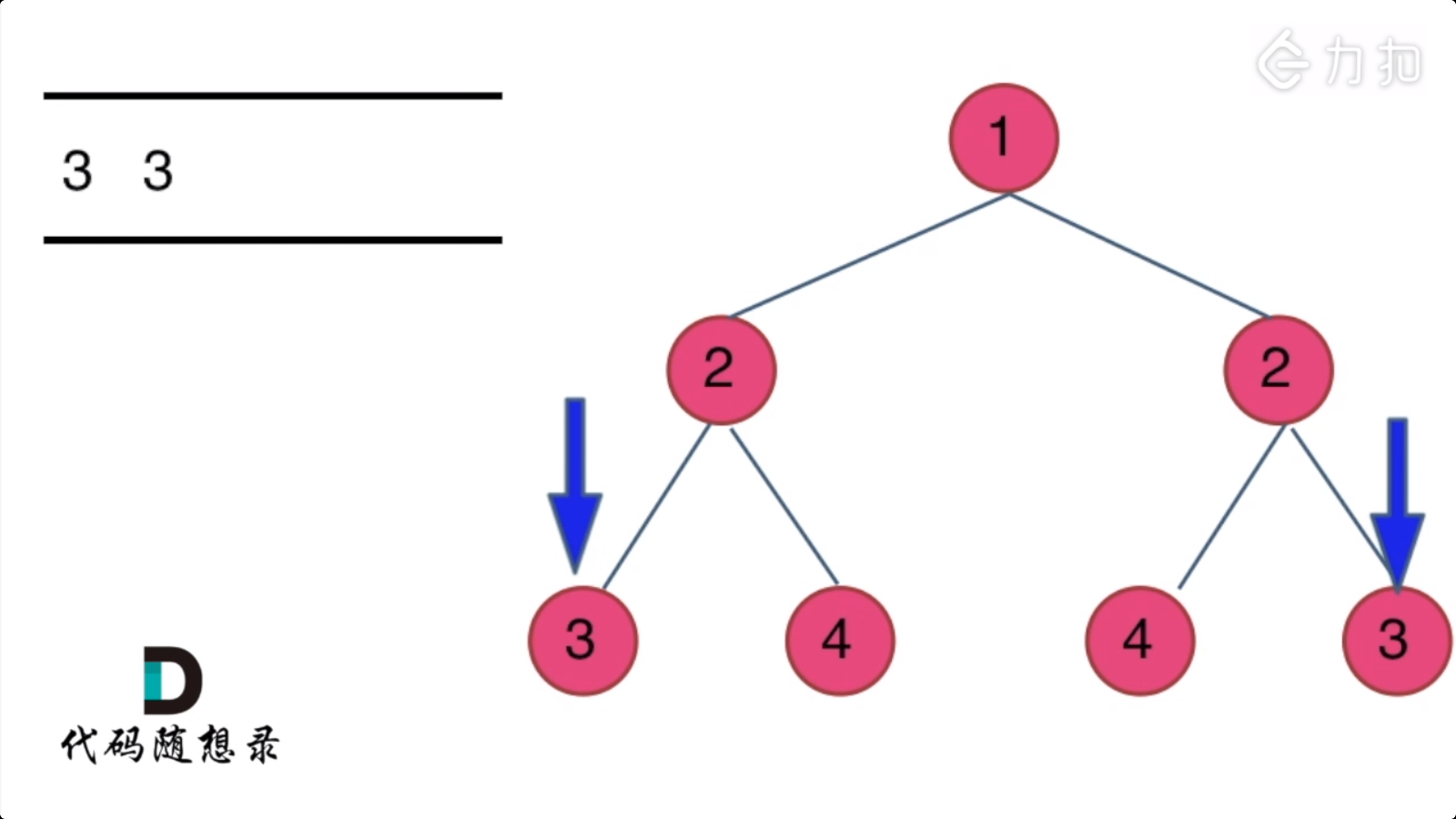
但是下面这个 [1,2,2,null,3,null,3] 则不是镜像对称的:
1
/ \
2 2
\ \
3 3
方法:原理就是分别比较对应位置上的值,如果相同则继续,如果不相同则退出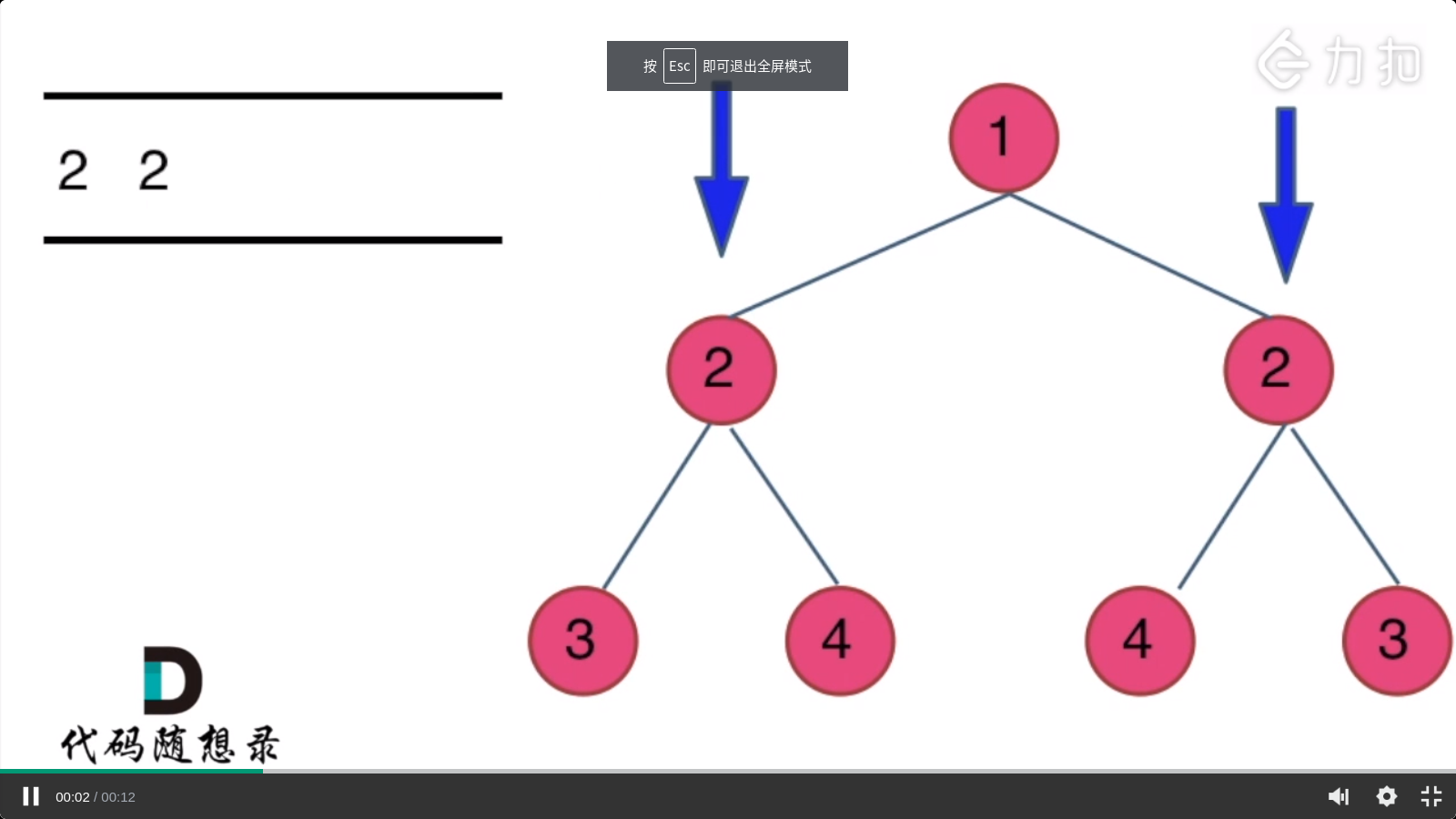
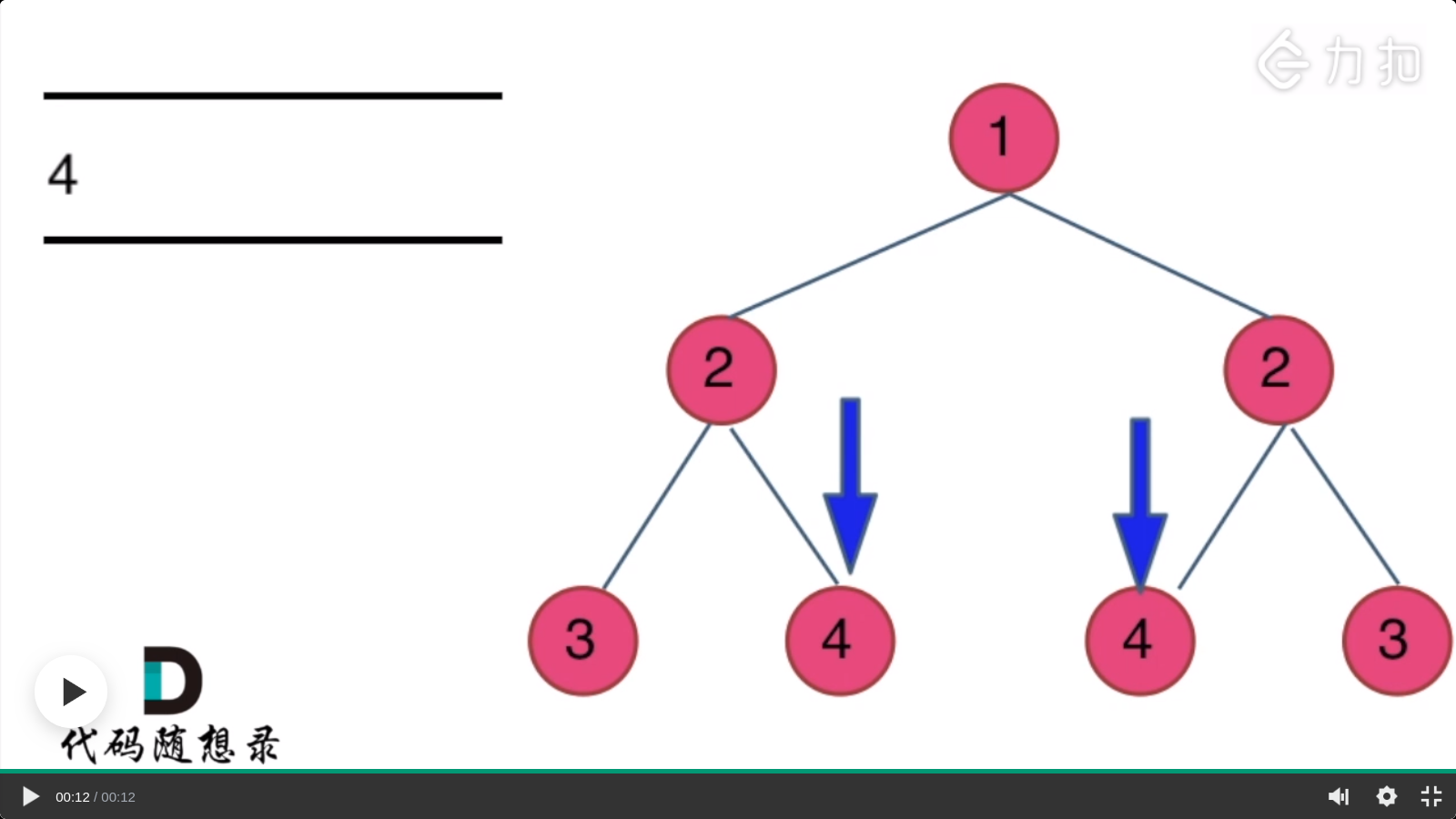
迭代方式:每次将对应的两组数据加入的队列中,然后取出比较,如果相等,再将其子树加入到队列中。知识点:层次遍历
class Solution:
def isSymmetric(self, root: TreeNode) -> bool:
if not root:
return True
queue = [root.left,root.right]
result = []
while queue:
left = queue.pop(0)
right = queue.pop(0)
if not left and not right:
continue
if not left or not right:
return False
if left.val != right.val:
return False
queue.append(left.left)
queue.append(right.right)
queue.append(left.right)
queue.append(right.left)
return True
递归方式:递归比较,从root节点的左右开始,左边和右边是否相等。左边的子节点和右边的子节点是否相等。迭代比较下
class Solution:
def isSymmetric(self, root: TreeNode) -> bool:
if not root:
return True
def new_trees(left, right):
if not left and not right:
return True
if not left or not right:
return False
if left.val != right.val:
return False
return all((new_trees(left.left,right.right), new_trees(left.right,right.left)))
return new_trees(root.left,root.right)
路径总和
给定一个二叉树和一个目标和,判断该树中是否存在根节点到叶子节点的路径,这条路径上所有节点值相加等于目标和。
说明: 叶子节点是指没有子节点的节点。
示例:
给定如下二叉树,以及目标和 sum = 22,
5
/ \
4 8
/ / \
11 13 4
/ \ \
7 2 1
返回 true, 因为存在目标和为 22 的根节点到叶子节点的路径 5->4->11->2。
解法一:一边遍历一边做减法
def hasPathSum(self, root: TreeNode, Sum: int) -> bool:
if not root:
return False
if Sum == root.val and not root.left and not root.right:
return True
left = self.hasPathSum(root.left, Sum-root.val)
right = self.hasPathSum(root.right, Sum-root.val)
return left or right
解法二: 遍历出所有路径,最后做加法
class Solution(object):
def hasPathSum(self, root, sum):
if not root: return False
res = []
return self.dfs(root, sum, res, [root.val])
def dfs(self, root, target, res, path):
if not root: return False
print(path)
if sum(path) == target and not root.left and not root.right:
return True
left_flag, right_flag = False, False
if root.left:
left_flag = self.dfs(root.left, target, res, path + [root.left.val])
if root.right:
right_flag = self.dfs(root.right, target, res, path + [root.right.val])
return left_flag or right_flag
>>>
[5]
[5, 4]
[5, 4, 11]
[5, 4, 11, 7]
[5, 4, 11, 2]
[5, 8]
[5, 8, 13]
[5, 8, 4]
[5, 8, 4, 1]
path 保留每一层的遍历结果,同时,多层的遍历中函数保存的path值是不一样的。每一层函数的遍历path列表的值都是保存当前的状态,互不影响。
原因在于:
if root.left:
left_flag = self.dfs(root.left, target, res, path + [root.left.val])
if root.right:
right_flag = self.dfs(root.right, target, res, path + [root.right.val])
简约版
def lijin(head,arr,target):
if not head :
print(arr)
if sum(arr) == target:
return True
return False
left = lijin(head.left,arr+[head.value],target)
right = lijin(head.right,arr+[head.value],target)
return left or right
分别在left和right中都使用了path,这个path在递归的层次中互相不干扰,如果想单纯的遍历出一棵树的路径,可以使用如下的代码:
def output(self,root,arr):
# result = []
if not root:
print(arr)
return None
else:
# self.result.append(root.value)
# arr.append(root.value)
self.output(root.left,arr+[root.value])
self.output(root.right,arr+[root.value])
二叉树的层序遍历
给你一个二叉树,请你返回其按 层序遍历 得到的节点值。 (即逐层地,从左到右访问所有节点)。
示例:
二叉树:[3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
返回其层次遍历结果:
[
[3],
[9,20],
[15,7]
]
方法:树的遍历很简单,分为DFS和BFS。其中这一道题比较适合BFS即广度优先遍历。
class Solution:
def levelOrder(self, root: TreeNode) -> List[List[int]]:
if not root: return [] # 特殊情况,root为空直接返回
from collections import deque
# 下面就是BFS模板内容,BFS关键在于队列的使用
layer = deque()
layer.append(root) # 压入初始节点
res = [] # 结果集
while layer:
cur_layer = [] # 临时变量,记录当前层的节点
for _ in range(len(layer)): # 遍历某一层的节点
node = layer.popleft() # 将要处理的节点弹出
cur_layer.append(node.val)
if node.left: # 如果当前节点有左右节点,则压入队列,根据题意注意压入顺序,先左后右,
layer.append(node.left)
if node.right:
layer.append(node.right)
res.append(cur_layer) # 某一层的节点都处理完之后,将当前层的结果压入结果集
return res
二叉树的序列化与反序列化
序列化是将一个数据结构或者对象转换为连续的比特位的操作,进而可以将转换后的数据存储在一个文件或者内存中,同时也可以通过网络传输到另一个计算机环境,采取相反方式重构得到原数据。
请设计一个算法来实现二叉树的序列化与反序列化。这里不限定你的序列 / 反序列化算法执行逻辑,你只需要保证一个二叉树可以被序列化为一个字符串并且将这个字符串反序列化为原始的树结构。
def serialize(self, root):
"""Encodes a tree to a single string.
:type root: TreeNode
:rtype: str
"""
if not root: return "[]"
queue = collections.deque()
queue.append(root)
res = []
while queue:
node = queue.popleft()
if node:
res.append(str(node.val))
queue.append(node.left)
queue.append(node.right)
else: res.append("null")
return '[' + ','.join(res) + ']'
def deserialize(self, data):
"""Decodes your encoded data to tree.
:type data: str
:rtype: TreeNode
"""
if data=='[]':
return None
vals, i = data[1:-1].split(','), 1
root = TreeNode(int(vals[0]))
queue = collections.deque()
queue.append(root)
while queue:
node = queue.popleft()
if vals[i] != "null":
node.left = TreeNode(int(vals[i]))
queue.append(node.left)
i += 1
if vals[i] != "null":
node.right = TreeNode(int(vals[i]))
queue.append(node.right)
i += 1
return root
二叉树的最近公共祖先
方法:使用前序遍历的方式,一直遍历找到一个节点,然后返回该节点,如果没有则直到叶子节点返回None。
当两个底层的节点不断被上浮,一定会相遇。像相遇点就是公共祖先节点。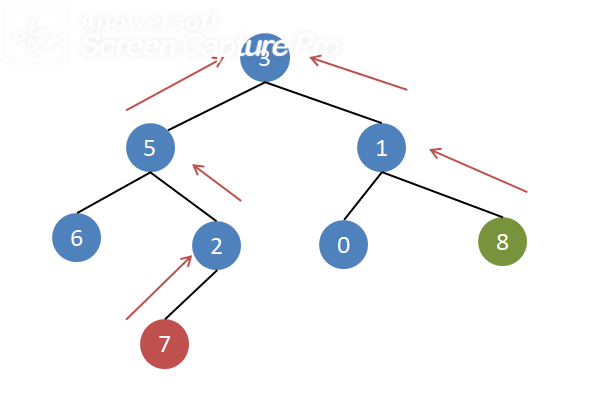
def lowestCommonAncestor(self, root: 'TreeNode', p: 'TreeNode', q: 'TreeNode') -> 'TreeNode':
if not root or root == p or root == q:
return root
left = self.lowestCommonAncestor(root.left, p, q)
right = self.lowestCommonAncestor(root.right, p, q)
if not left:
return right
if not right:
return left
return root
树的小结
树这种数据结构在算法中我还没有遇到,估计是面试官也不好驾驭这种数据结构。对于树来说,很多算法题我都非常懵,不看答案想破脑袋都想不出的,最好仰天长啸:原来还可以这样。
对于树来来说需要明白的技巧前序遍历,中序遍历,后序遍历,BFS,DFS等。多看套路,少走弯路。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/196571.html

