
问题描述
kafka中的数据格式如下:
{
"customerId": 1652,
"deviceId": "13011304383",
"timestamp": 1705637828000,
"parameters": {
"acc": 0,
"locationStatus": 1,
"altitude": 38.0,
"loc": {
"lng": 117.306441,
"lat": 31.93148
},
"latitude": 31.93148,
"brushState": 0,
"speed": 0.0,
"direction": 136.0,
"height": 38.0,
"longitude": 117.306441,
"mileage": 267119.0
},
"componentId": 7,
"entityId": 81495
}
需要通过telegraf把kafka中的数据,同步到influxdb,parameters中的所有key,作为时序数据库的指标存储。
由于influxdb的field value只支持string、int、float等简单类型,不支持对象。而parameters.loc是一个对象,因此呢,需要在telegraf中把对象转换成字符串进行存储。
方案一
使用telegraf中的xpath插件:
data_format = "xpath_json"
[[inputs.kafka_consumer.xpath]]
metric_name = "string('device_metric')"
timestamp = '/timestamp'
timestamp_format = 'unix_ms'
timezone = 'Asia/Shanghai'
field_selection = "/parameters/child::*"
### https://github.com/influxdata/telegraf/tree/master/plugins/parsers/json_v2
[inputs.kafka_consumer.xpath.tags]
customerId = "/customerId"
deviceId = "/deviceId"
## 优点:可以吧loc作为filed value字符串存储。 可以设置默认把parameters所有key作为指标
[inputs.kafka_consumer.xpath.fields]
speed = "number(/parameters/speed)"
battery = "number(/parameters/battery)"
brushState = "number(/parameters/brushState)"
height = "number(/parameters/height)"
mileage = "number(/parameters/mileage)"
oil = "number(/parameters/oil)"
original_oil = "number(/parameters/original_oil)"
original_waterLevel = "number(/parameters/original_waterLevel)"
loc = "/parameters/loc"
lng = "number(/parameters/loc/lng)"
lat = "number(/parameters/loc/lat)"
[inputs.kafka_consumer.xpath.fields_int]
acc = "/parameters/acc"
解析后得到的数据格式如下:
device_metric,customerId=2104,deviceId=18123255038,host=qths-hwpt-03 altitude="83",brushState=0,height=83,locationStatus="1",battery=0,acc=1i,direction="266",mileage=137323,latitude="22.640786",loc="{\"lat\":22.640786,\"lng\":114.200608}",oil=0,lng=114.200608,longitude="114.200608",speed=0,original_oil=0,original_waterLevel=0,lat=22.640786 1705638436000000000
重点关于field key: loc的值:
loc="{\"lat\":22.640786,\"lng\":114.200608}"
以及loc字段的解析配置:
loc = "/parameters/loc"
“/parameters/loc” 定义的是一个json path, 它的值是一个对象,默认情况下这个插件会把value转换成字符串,因此呢,loc的值就是字符串类型。
这一点能满足我们的需求。
但是xpath这个插件,我认为存在的问题是:它不能根据json value的类型,自定推断出指标的类型。
举例,kafka中,字段altitude的值是整型,而解析后altitude的值类型变成字符串了(我没有显式指定字段altitude的类型,默认就会当作字符串处理)。
我们的业务中有几百个指标,指标随时会新增,每次新增指标都需要在这里显示指定类型,非常不方便。
纠正:经过在github上询问,实际上这个插件也支持类型自动推断。参考https://github.com/influxdata/telegraf/issues/14597
方案二
使用telegraf中的json_v2插件:
data_format = "json_v2"
[[inputs.kafka_consumer.json_v2]]
measurement_name = "device_metric"
timestamp_path = 'timestamp'
timestamp_format = 'unix_ms'
timestamp_timezone = 'Asia/Shanghai'
[[inputs.kafka_consumer.json_v2.object]]
path = "parameters"
tags = ["customerId", "deviceId"]
解析得到的数据格式如下:
device_metric,host=xushengbindeMacBook-Pro.local acc=0,locationStatus=1,altitude=22,loc_lng=118.597916,loc_lat=24.838415,latitude=24.838415,brushState=0,speed=84,direction=150,height=22,longitude=118.597916,mileage=1288 1705651699000000000
相比前面的xpath插件,这个插件的优点是能自动推断数据类型(json中数据类型是啥,解析之后的数据类型还是啥)。
For each field you have the option to define the types. The following rules are in place for this configuration:
- If a type is explicitly defined, the parser will enforce this type and convert the data to the defined type if possible. If the type can’t be converted then the parser will fail.
- If a type isn’t defined, the parser will use the default type defined in the JSON (int, float, string)
但是呢,对于json中的object,官方是这么说的:
- Array: Every element in an array is treated as a separate line protocol
- Object: Every key/value in a object is treated as a single line protocol
从结果看,意思就是把loc对象又进行了解析,每一个key算作一个指标。loc_lng=118.597916,loc_lat=24.838415
这一点不符合预期。怎么办呢。 花了好大功能,找到了解决办法。
首先,https://github.com/influxdata/telegraf/tree/master/plugins/parsers/json_v2 中的配置,底层使用的是gjson库,它的语法参考:https://github.com/tidwall/gjson/blob/v1.7.5/SYNTAX.md
查阅这个文档,看到如下介绍: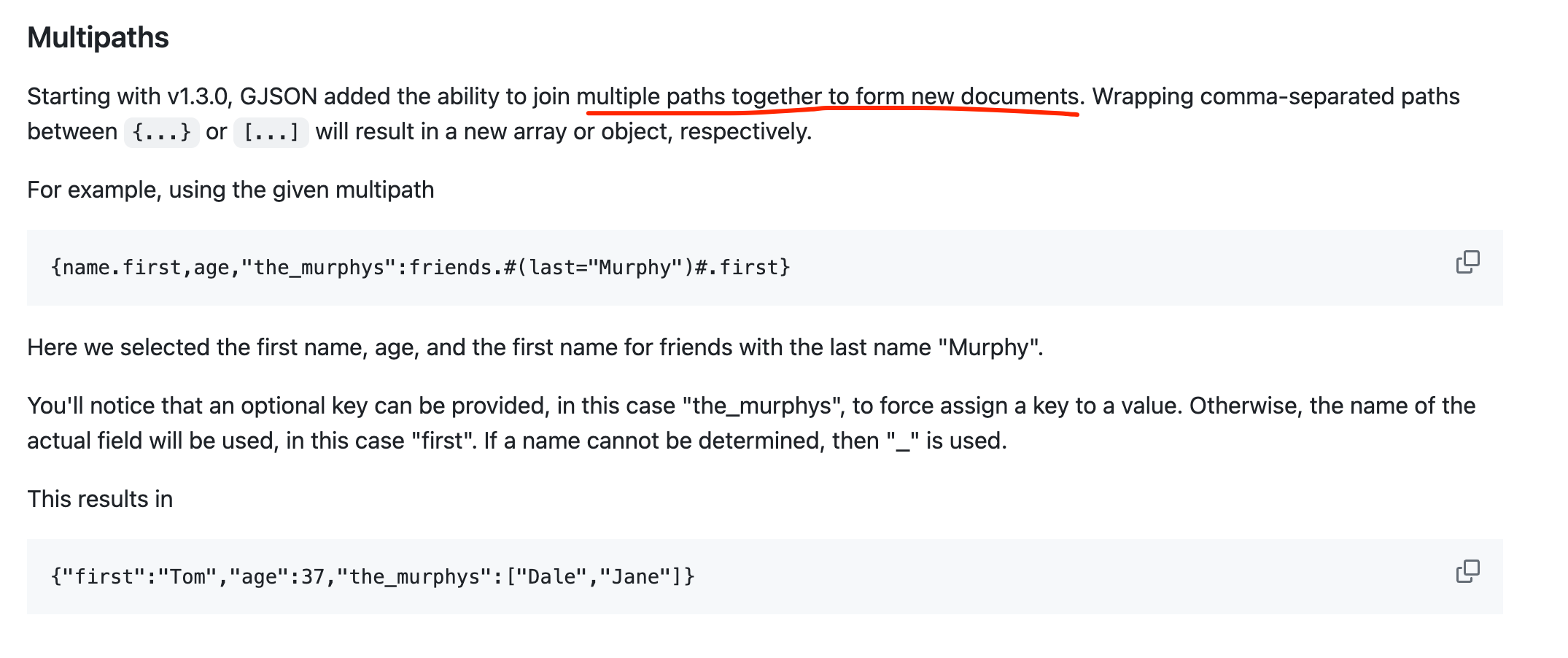
它实际上支持构造新的对象。
并且也支持类型转换(把构造的对象转换成string类型)。https://github.com/tidwall/gjson/blob/v1.7.5/SYNTAX.md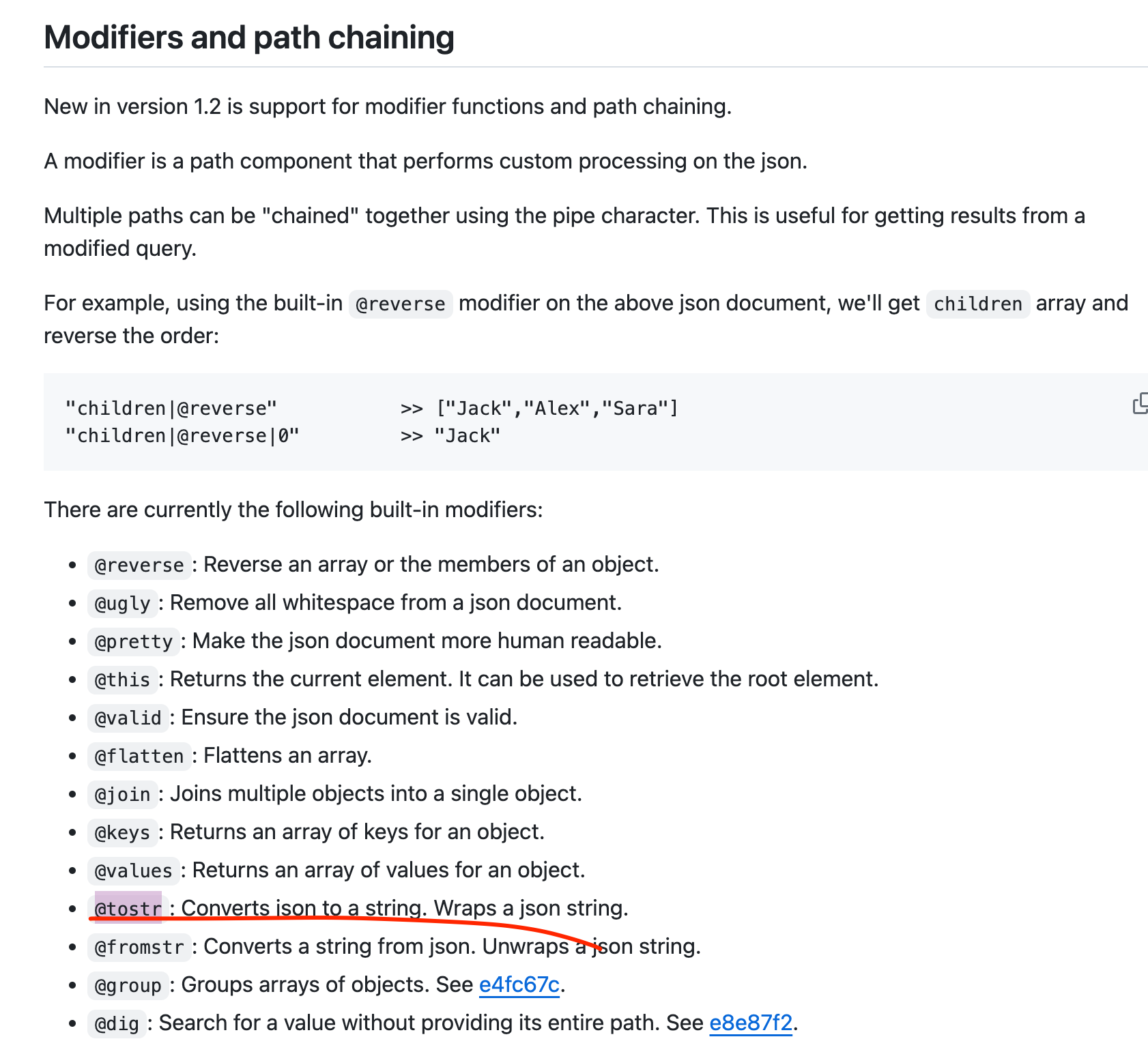
顺着这个思路,我修改了配置:
data_format = "json_v2"
[[inputs.kafka_consumer.json_v2]]
measurement_name = "device_metric"
timestamp_path = 'timestamp'
timestamp_format = 'unix_ms'
timestamp_timezone = 'Asia/Shanghai'
[[inputs.kafka_consumer.json_v2.object]]
excluded_keys = ["loc"]
path = "parameters"
tags = ["customerId", "deviceId"]
[[inputs.kafka_consumer.json_v2.field]]
path = "{parameters.latitude,parameters.longitude}|@tostr"
type = "string"
rename = "loc"
[[inputs.kafka_consumer.json_v2.tag]]
path = "customerId"
optional = true
[[inputs.kafka_consumer.json_v2.tag]]
path = "deviceId"
type = "string"
optional = false
两点调整:
1、默认插件会把parameters中的所有key都解析成指标,因此这里我利用excluded_keys,排除掉loc,默认不解析loc
2、利用"{parameters.latitude,parameters.longitude}|@tostr" 构造了新的loc字符串。
解析后的数据,结果如下:
device_metric,host=xushengbindeMacBook-Pro.local acc=1,locationStatus=1,altitude=77,latitude=31.95914,brushState=0,speed=0,direction=0,height=77,longitude=117.26341,mileage=45322,loc="{\"latitude\":31.95914,\"longitude\":117.26341}" 1705651750000000000
很完美。
1、解析后的类型和json中的值类型保持一致
2、loc的值变成一个字符串,适配influxdb中的field value type。
写到这里,我意识到,实际上可以有更简单的写法:
data_format = "json_v2"
[[inputs.kafka_consumer.json_v2]]
measurement_name = "device_metric"
timestamp_path = 'timestamp'
timestamp_format = 'unix_ms'
timestamp_timezone = 'Asia/Shanghai'
[[inputs.kafka_consumer.json_v2.object]]
excluded_keys = ["loc"]
path = "parameters"
tags = ["customerId", "deviceId"]
[[inputs.kafka_consumer.json_v2.field]]
path = "parameters.loc|@tostr"
type = "string"
rename = "loc"
[[inputs.kafka_consumer.json_v2.tag]]
path = "customerId"
optional = true
[[inputs.kafka_consumer.json_v2.tag]]
path = "deviceId"
type = "string"
optional = false
解析后的结果和上面一致,符合预期。
telegraf 使用技巧
1、在配置文件最顶层,加入[[processors.printer]] 就可以输出解析后的结果
influxdb中的数据类型
Field values can be floats, integers, strings, or Booleans: Floats – by default, InfluxDB assumes all numerical field values are floats.
influxdb 同一张表中同一个field,存在多个类型
https://github.com/influxdata/influxdb/issues/8535
当在一个分片内,如果一个field有多个类型,可能导致很多异常的问题,参考:
https://github.com/influxdata/influxdb/issues/8085
我今天就遇到了这个问题。SHOW FIELD KEYS from device_metric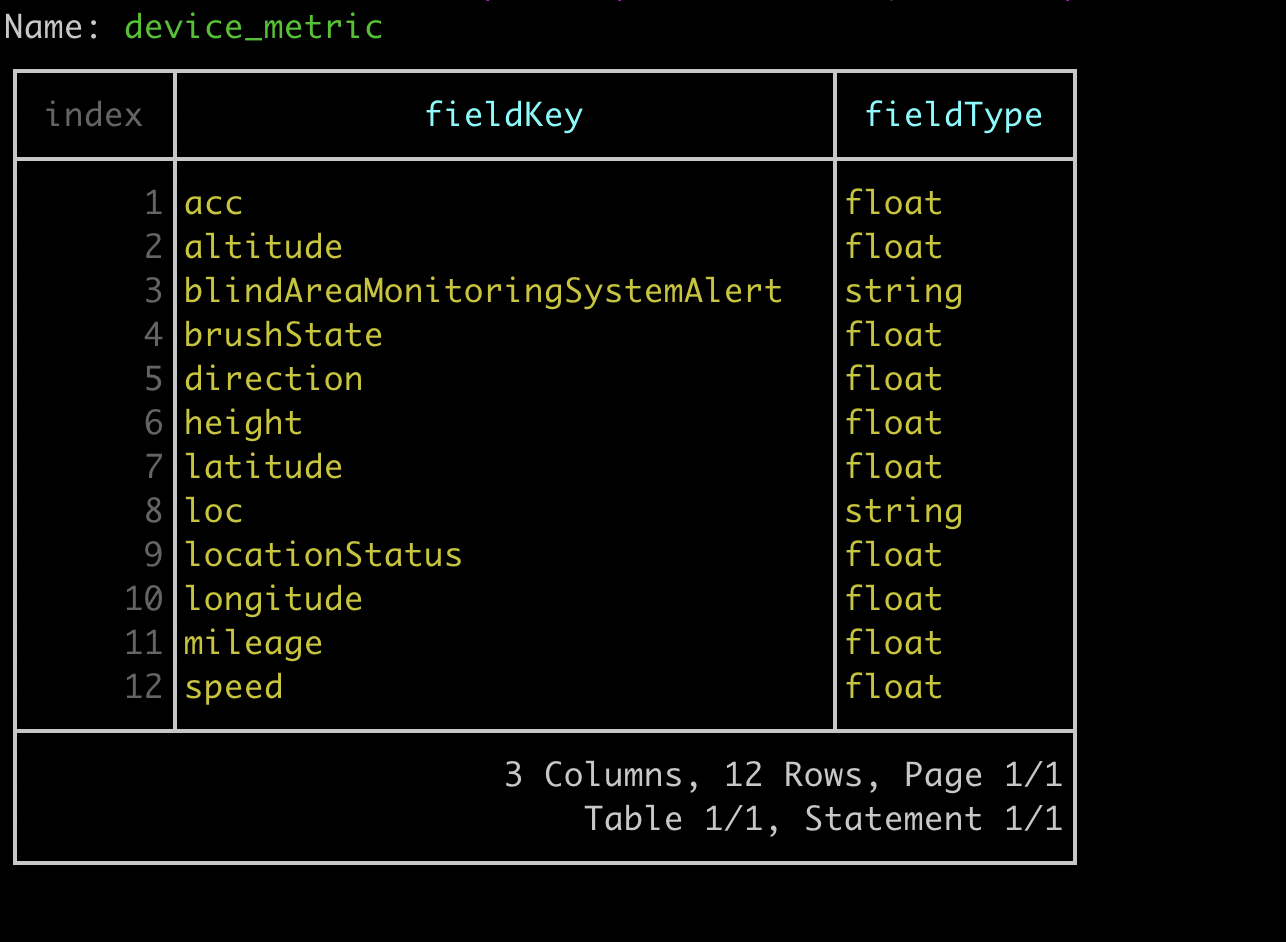
截图是优化后的结果。
优化前,同一个field key(如acc),即有float类型,又有int类型。就会导致意料之外的问题。
解决办法:
我们前面介绍了通过telegraf往Influxdb写数据时,可以选择自动类型推断。即原始json(我是存在kakfa中)中字段的类型是啥,存入influxdb中也是什么类型。
当然,也可以显示指定字段的类型。
如果选择让influxdb自动推断类型,就要保证原始数据中的类型是一致的(不能一会儿是int,一会儿是float)。
reload telegraf配置文件
kill -SIGHUP
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/203693.html

