

什么是MySQL?
- MySQL是一种开源关系数据库管理系统(RDBMS),它使用最常用的数据库管理语言-结构化查询语言(SQL)进行数据库管理。MySQL是开源的,因此任何人都可以根据通用公共许可证下载并根据个人需要对其进行修改。它的速度,可靠性和适应性引起了人们的广泛关注。大多数人认为,当不需要事务处理时,MySQL是管理内容的最佳选择。MySQL是一个关系数据库管理系统。关系数据库将数据存储在不同的表中,而不是将所有数据都放在一个大型仓库中,这提高了速度和灵活性。
- MySQL使用的SQL语言是用于访问数据库的最常用的标准化语言。MySQL软件采用双重授权策略,分为社区版本和商业版本。由于其体积小,速度快,总拥有成本低,尤其是开放源代码的特性,通常中小型网站开发都选择MySQL作为网站数据库。
- MySQL是一个开源数据库:MySQL是一个开源数据库,任何人都可以获取该数据库的源代码。这样,任何人都可以修复MySQL的缺陷,并且任何人都可以将数据库用于任何目的。MySQL是可免费使用的数据库。
- MySQL的跨平台:MySQL不仅可以在Windows操作系统上运行,而且可以在UNIX,Linux和Mac OS等操作系统上运行。由于许多网站选择UNIX和Linux作为其网站服务器,因此MySQL的跨平台性质保证了它在Web应用程序中的优势。尽管Microsoft的SQL Server数据库是出色的商业数据库,但它只能在Windows操作系统上运行。因此,MySQL数据库的跨平台性质是一个很大的优势。
- 价格优势:MySQL数据库是一个免费软件。任何人都可以从MySQL的官方网站下载该软件。这些MySQL的社区版本可免费试用。即使需要支付额外的功能,价格也非常便宜。与昂贵的商业软件(例如Oracle,DB2和SQL Server)相比,MySQL具有绝对的价格优势。
- 功能强大且易于使用:MySQL是真正的多用户,多线程SQL数据库服务器。它可以快速,有效和安全地处理大量数据。与Oracle之类的数据库相比,MySQL的使用非常简单。MySQL的主要目标是快速,健壮和易于使用。
与常用的主流数据库Oracle和SQL Server相比,MySQL的主要特点是它是免费的,可以在任何平台上使用,占用相对较小的空间。但是,MySQL也有一些缺点。例如,对于大型项目,MySQL的容量和安全性略逊于Oracle数据库。
数据库事务的特性(ACID):
- A, atomacity 原子性 事务必须是原子工作单元;对于其数据修改,要么全都执行,要么全都不执行。通常,与某个事务关联的操作具有共同的目标,并且是相互依赖的。如果系统只执行这些操作的一个子集,则可能会破坏事务的总体目标。原子性消除了系统处理操作子集的可能性。
- C, consistency 一致性 事务将数据库从一种一致状态转变为下一种一致状态。也就是说,事务在完成时,必须使所有的数据都保持一致状态(各种 constraint 不被破坏)。
- I, isolation 隔离性 由并发事务所作的修改必须与任何其它并发事务所作的修改隔离。事务查看数据时数据所处的状态,要么是另一并发事务修改它之前的状态,要么是另一事务修改它之后的状态,事务不会查看中间状态的数据。换句话说,一个事务的影响在该事务提交前对其他事务都不可见。
- D, durability 持久性 事务完成之后,它对于系统的影响是永久性的。该修改即使出现致命的系统故障也将一直保持。
事物隔离级别:
- 读未提交(Read uncommitted):就是一个事务可以读取另一个未提交事务的数据。
- 读提交(Read committed):就是一个事务要等另一个事务提交后才能读取数据。
- 重复读(Repeatable read):重复读是 Mysql 的默认隔离级,就是在开始读取数据(事务开启)时,不再允许修改操作。
- Serializable 序列化:最高的事务隔离级别,在该级别下,事务串行化顺序执行,可以避免脏读、不可重复读与幻读。但是这种事务隔离级别效率低下,比较耗数据库性能。
事物隔离的实现:
- (1) 行级锁 INNODB引擎
- 行级锁是Mysql中锁定粒度最细的一种锁,表示只针对当前操作的行进行加锁。
- 行级锁能大大减少数据库操作的冲突。其加锁粒度最小,但加锁的开销也最大。行级锁分为共享锁 和 排他锁。
- 特点:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
- (2) 表级锁 MYISAM引擎
- 表级锁是MySQL中锁定粒度最大的一种锁,表示对当前操作的整张表加锁,它实现简单,资源消耗较少,
- 被大部分MySQL引擎支持。最常使用的MYISAM与INNODB都支持表级锁定。表级锁定分为表共享读锁(共享锁)与表独占写锁(排他锁)。
- 特点:开销小,加锁快;不会出现死锁;锁定粒度大,发出锁冲突的概率最高,并发度最低。
- (3) 页级锁 BDB引擎
- 页级锁是MySQL中锁定粒度介于行级锁和表级锁中间的一种锁。表级锁速度快,但冲突多,行级冲突少,但速度慢。所以取了折衷的页级,一次锁定相邻的一组记录。
- 特点:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般
RDBMS 术语:
- 数据库: 数据库是一些关联表的集合。
- 数据表: 表是数据的矩阵。在一个数据库中的表看起来像一个简单的电子表格。
- 列: 一列(数据元素) 包含了相同类型的数据, 例如邮政编码的数据。
- 行:一行(=元组,或记录)是一组相关的数据,例如一条用户订阅的数据。
- 冗余:存储两倍数据,冗余降低了性能,但提高了数据的安全性。
- 主键:主键是唯一的。一个数据表中只能包含一个主键。你可以使用主键来查询数据。
- 外键:外键用于关联两个表。
- 复合键:复合键(组合键)将多个列作为一个索引键,一般用于复合索引。
- 索引:使用索引可快速访问数据库表中的特定信息。索引是对数据库表中一列或多列的值进行排序的一种结构。类似于书籍的目录。
- 参照完整性: 参照的完整性要求关系中不允许引用不存在的实体。与实体完整性是关系模型必须满足的完整性约束条件,目的是保证数据的一致性。
MySQL 为关系型数据库(Relational Database Management System), 这种所谓的”关系型”可以理解为”表格”的概念, 一个关系型数据库由一个或数个表格组成, 如图所示的一个表格:

- 表头(header): 每一列的名称;
- 列(col): 具有相同数据类型的数据的集合;
- 行(row): 每一行用来描述某条记录的具体信息;
- 值(value): 行的具体信息, 每个值必须与该列的数据类型相同;
- 键(key): 键的值在当前列中具有唯一性。
SQL语句:对数据库进行查询和修改操作的语言叫SQL。在MySQL中输入相关命令,MySQL软件可以接受命令,并做出相应的操作。SQL是一种专门用来与数据库通信的语言。SQL语句包含以下4个部分:
- (1) 数据定义(DDL):CREATE(创建)、ALTER(修改)、DROP(删除)。(?后跟命令可获取帮助);主要用于数据库组件,例如数据库、表、索引、视图、触发器、事件调度器、存储过程、存储函数;
- (2) 数据操作(DML):INSERT(增)、DELETE(删)、UPDATE(改)、SELECT(查);CRUD(增删改查)操作,主要用于操作表中的数据;每一种操作之前都要先查询;
- (3) 数据控制(DCL):GRANT(授权)、REVOKE(撤销);授权用户,登录主机地址权限及撤销权限;
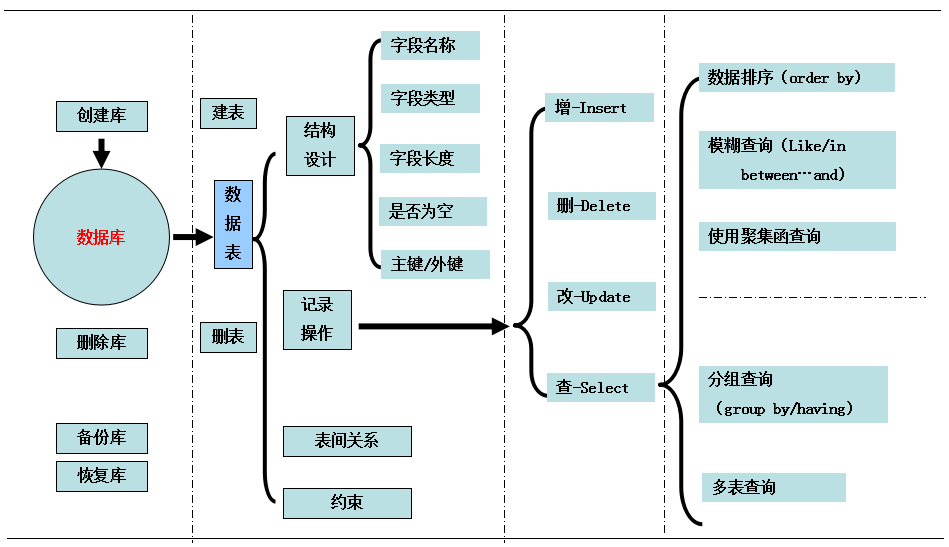
数据库操作-思路图:
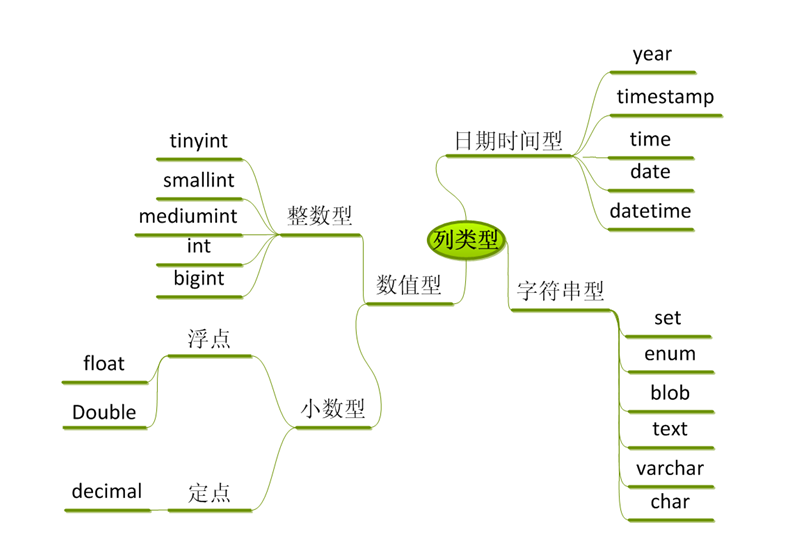
MySQL数据类型:
索引的概述和优缺点和种类:
(1) 什么是索引?
- 索引是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的引用指针。
- 类比理解:数据库中的索引相当于书籍目录一样,能加快数据库的查询速度。
- 没有索引的情况,数据库会遍历全部数据后选择符合条件的选项。
- 创建相应的索引,数据库会直接在索引中查找符合条件的选项。
(2) 索引的性质分类:
- 索引分为聚集索引和非聚集索引两种,聚集索引是索引中键值的逻辑顺序决定了表中相应行的物理顺序,而非聚集索引是不一样。
- 聚集索引能提高多行检索的速度,而非聚集索引对于单行的检索很快。
(3) 索引的优点:
- 加快数据检索速度 (创建索引主要原因)
- 创建唯一性索引,保证数据库表中每一行数据的唯一性
- 加速表和表之间的连接
- 使用分组和排序子句对数据检索时,减少检索时间
- 使用索引在查询的过程中,使用优化隐藏器,提高系统的性能
(4) 索引的缺点:
- 创建索引和维护索引要耗费时间,时间随着数据量的增加而增加
- 索引需要占用物理空间和数据空间
- 表中的数据操作插入、删除、修改, 维护数据速度下降
(5) 索引种类
- 普通索引: 仅加速查询
- 唯一索引: 加速查询 + 列值唯一(可以有null)
- 主键索引: 加速查询 + 列值唯一(不可以有null)+ 表中只有一个
- 组合索引: 多列值组成一个索引,专门用于组合搜索,其效率大于索引合并
- 全文索引: 对文本的内容进行分词,进行搜索 (注意:目前仅有MyISAM引擎支持)
外键约束(foreign key):
- 外键约束: foreign key 被约束的表叫做副表,外键设置在副表上面,外键引用主键字段所在的表叫做主表. (作用:约束两张表的数据)
- 外键定义语法: constraint 外键约束名称 foreign key(外键字段) references 主表名称(引用字段)
外键数据操作:
- 当有外键约束之后,添加数据的时候,先添加主表数据,再添加副表数据
- 当有了外键约束,修改数据的时候,先改副表的数据,在修改主表的数据
- 当有了外键约束,删除数据的时候,也是先删除副表的数据,再删除主表的数据
外键注意事项:
- 外键约束只有InnoDB存储引擎才支持.
- 实际项目中往往会用到外键的设计思想,但往往不会真正的从语法上进行外键约束. 因为外键约束的级联操作可能会带来一些现实的逻辑问题. 另外使用外键会较低mysql的效率.
语法及示例:
1 /* 启动MySQL */ 2 net start mysql 3 4 /* 连接与断开服务器 */ 5 mysql -h 地址 -P 端口 -u 用户名 -p 密码 6 7 /* 跳过权限验证登录MySQL */ 8 mysqld --skip-grant-tables 9 -- 修改root密码 10 密码加密函数password() 11 update mysql.user set password=password('root'); 12 13 SHOW PROCESSLIST -- 显示哪些线程正在运行 14 SHOW VARIABLES -- 15 16 /* 数据库操作 */ ------------------ 17 -- 查看当前数据库 18 select database(); 19 -- 显示当前时间、用户名、数据库版本 20 select now(), user(), version(); 21 -- 创建库 22 create database[ if not exists] 数据库名 数据库选项 23 数据库选项: 24 CHARACTER SET charset_name 25 COLLATE collation_name 26 -- 查看已有库 27 show databases[ like 'pattern'] 28 -- 查看当前库信息 29 show create database 数据库名 30 -- 修改库的选项信息 31 alter database 库名 选项信息 32 -- 删除库 33 drop database[ if exists] 数据库名 34 同时删除该数据库相关的目录及其目录内容 35 36 /* 表的操作 */ ------------------ 37 -- 创建表 38 create [temporary] table[ if not exists] [库名.]表名 ( 表的结构定义 )[ 表选项] 39 每个字段必须有数据类型 40 最后一个字段后不能有逗号 41 temporary 临时表,会话结束时表自动消失 42 对于字段的定义: 43 字段名 数据类型 [NOT NULL | NULL] [DEFAULT default_value] [AUTO_INCREMENT] [UNIQUE [KEY] | [PRIMARY] KEY] [COMMENT 'string'] 44 -- 表选项 45 -- 字符集 46 CHARSET = charset_name 47 如果表没有设定,则使用数据库字符集 48 -- 存储引擎 49 ENGINE = engine_name 50 表在管理数据时采用的不同的数据结构,结构不同会导致处理方式、提供的特性操作等不同 51 常见的引擎:InnoDB MyISAM Memory/Heap BDB Merge Example CSV MaxDB Archive 52 不同的引擎在保存表的结构和数据时采用不同的方式 53 MyISAM表文件含义:.frm表定义,.MYD表数据,.MYI表索引 54 InnoDB表文件含义:.frm表定义,表空间数据和日志文件 55 SHOW ENGINES -- 显示存储引擎的状态信息 56 SHOW ENGINE 引擎名 {LOGS|STATUS} -- 显示存储引擎的日志或状态信息 57 -- 数据文件目录 58 DATA DIRECTORY = '目录' 59 -- 索引文件目录 60 INDEX DIRECTORY = '目录' 61 -- 表注释 62 COMMENT = 'string' 63 -- 分区选项 64 PARTITION BY ... (详细见手册) 65 -- 查看所有表 66 SHOW TABLES[ LIKE 'pattern'] 67 SHOW TABLES FROM 表名 68 -- 查看表机构 69 SHOW CREATE TABLE 表名 (信息更详细) 70 DESC 表名 / DESCRIBE 表名 / EXPLAIN 表名 / SHOW COLUMNS FROM 表名 [LIKE 'PATTERN'] 71 SHOW TABLE STATUS [FROM db_name] [LIKE 'pattern'] 72 -- 修改表 73 -- 修改表本身的选项 74 ALTER TABLE 表名 表的选项 75 EG: ALTER TABLE 表名 ENGINE=MYISAM; 76 -- 对表进行重命名 77 RENAME TABLE 原表名 TO 新表名 78 RENAME TABLE 原表名 TO 库名.表名 (可将表移动到另一个数据库) 79 -- RENAME可以交换两个表名 80 -- 修改表的字段机构 81 ALTER TABLE 表名 操作名 82 -- 操作名 83 ADD[ COLUMN] 字段名 -- 增加字段 84 AFTER 字段名 -- 表示增加在该字段名后面 85 FIRST -- 表示增加在第一个 86 ADD PRIMARY KEY(字段名) -- 创建主键 87 ADD UNIQUE [索引名] (字段名)-- 创建唯一索引 88 ADD INDEX [索引名] (字段名) -- 创建普通索引 89 ADD 90 DROP[ COLUMN] 字段名 -- 删除字段 91 MODIFY[ COLUMN] 字段名 字段属性 -- 支持对字段属性进行修改,不能修改字段名(所有原有属性也需写上) 92 CHANGE[ COLUMN] 原字段名 新字段名 字段属性 -- 支持对字段名修改 93 DROP PRIMARY KEY -- 删除主键(删除主键前需删除其AUTO_INCREMENT属性) 94 DROP INDEX 索引名 -- 删除索引 95 DROP FOREIGN KEY 外键 -- 删除外键 96 97 -- 删除表 98 DROP TABLE[ IF EXISTS] 表名 ... 99 -- 清空表数据 100 TRUNCATE [TABLE] 表名 101 -- 复制表结构 102 CREATE TABLE 表名 LIKE 要复制的表名 103 -- 复制表结构和数据 104 CREATE TABLE 表名 [AS] SELECT * FROM 要复制的表名 105 -- 检查表是否有错误 106 CHECK TABLE tbl_name [, tbl_name] ... [option] ... 107 -- 优化表 108 OPTIMIZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ... 109 -- 修复表 110 REPAIR [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ... [QUICK] [EXTENDED] [USE_FRM] 111 -- 分析表 112 ANALYZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ... 113 114 115 116 /* 数据操作 */ ------------------ 117 -- 增 118 INSERT [INTO] 表名 [(字段列表)] VALUES (值列表)[, (值列表), ...] 119 -- 如果要插入的值列表包含所有字段并且顺序一致,则可以省略字段列表。 120 -- 可同时插入多条数据记录! 121 REPLACE 与 INSERT 完全一样,可互换。 122 INSERT [INTO] 表名 SET 字段名=值[, 字段名=值, ...] 123 -- 查 124 SELECT 字段列表 FROM 表名[ 其他子句] 125 -- 可来自多个表的多个字段 126 -- 其他子句可以不使用 127 -- 字段列表可以用*代替,表示所有字段 128 -- 删 129 DELETE FROM 表名[ 删除条件子句] 130 没有条件子句,则会删除全部 131 -- 改 132 UPDATE 表名 SET 字段名=新值[, 字段名=新值] [更新条件] 133 134 /* 字符集编码 */ ------------------ 135 -- MySQL、数据库、表、字段均可设置编码 136 -- 数据编码与客户端编码不需一致 137 SHOW VARIABLES LIKE 'character_set_%' -- 查看所有字符集编码项 138 character_set_client 客户端向服务器发送数据时使用的编码 139 character_set_results 服务器端将结果返回给客户端所使用的编码 140 character_set_connection 连接层编码 141 SET 变量名 = 变量值 142 set character_set_client = gbk; 143 set character_set_results = gbk; 144 set character_set_connection = gbk; 145 SET NAMES GBK; -- 相当于完成以上三个设置 146 -- 校对集 147 校对集用以排序 148 SHOW CHARACTER SET [LIKE 'pattern']/SHOW CHARSET [LIKE 'pattern'] 查看所有字符集 149 SHOW COLLATION [LIKE 'pattern'] 查看所有校对集 150 charset 字符集编码 设置字符集编码 151 collate 校对集编码 设置校对集编码 152 153 /* 数据类型(列类型) */ ------------------ 154 1. 数值类型 155 -- a. 整型 ---------- 156 类型 字节 范围(有符号位) 157 tinyint 1字节 -128 ~ 127 无符号位:0 ~ 255 158 smallint 2字节 -32768 ~ 32767 159 mediumint 3字节 -8388608 ~ 8388607 160 int 4字节 161 bigint 8字节 162 163 int(M) M表示总位数 164 - 默认存在符号位,unsigned 属性修改 165 - 显示宽度,如果某个数不够定义字段时设置的位数,则前面以0补填,zerofill 属性修改 166 例:int(5) 插入一个数'123',补填后为'00123' 167 - 在满足要求的情况下,越小越好。 168 - 1表示bool值真,0表示bool值假。MySQL没有布尔类型,通过整型0和1表示。常用tinyint(1)表示布尔型。 169 170 -- b. 浮点型 ---------- 171 类型 字节 范围 172 float(单精度) 4字节 173 double(双精度) 8字节 174 浮点型既支持符号位 unsigned 属性,也支持显示宽度 zerofill 属性。 175 不同于整型,前后均会补填0. 176 定义浮点型时,需指定总位数和小数位数。 177 float(M, D) double(M, D) 178 M表示总位数,D表示小数位数。 179 M和D的大小会决定浮点数的范围。不同于整型的固定范围。 180 M既表示总位数(不包括小数点和正负号),也表示显示宽度(所有显示符号均包括)。 181 支持科学计数法表示。 182 浮点数表示近似值。 183 184 -- c. 定点数 ---------- 185 decimal -- 可变长度 186 decimal(M, D) M也表示总位数,D表示小数位数。 187 保存一个精确的数值,不会发生数据的改变,不同于浮点数的四舍五入。 188 将浮点数转换为字符串来保存,每9位数字保存为4个字节。 189 190 2. 字符串类型 191 -- a. char, varchar ---------- 192 char 定长字符串,速度快,但浪费空间 193 varchar 变长字符串,速度慢,但节省空间 194 M表示能存储的最大长度,此长度是字符数,非字节数。 195 不同的编码,所占用的空间不同。 196 char,最多255个字符,与编码无关。 197 varchar,最多65535字符,与编码有关。 198 一条有效记录最大不能超过65535个字节。 199 utf8 最大为21844个字符,gbk 最大为32766个字符,latin1 最大为65532个字符 200 varchar 是变长的,需要利用存储空间保存 varchar 的长度,如果数据小于255个字节,则采用一个字节来保存长度,反之需要两个字节来保存。 201 varchar 的最大有效长度由最大行大小和使用的字符集确定。 202 最大有效长度是65532字节,因为在varchar存字符串时,第一个字节是空的,不存在任何数据,然后还需两个字节来存放字符串的长度,所以有效长度是64432-1-2=65532字节。 203 例:若一个表定义为 CREATE TABLE tb(c1 int, c2 char(30), c3 varchar(N)) charset=utf8; 问N的最大值是多少? 答:(65535-1-2-4-30*3)/3 204 205 -- b. blob, text ---------- 206 blob 二进制字符串(字节字符串) 207 tinyblob, blob, mediumblob, longblob 208 text 非二进制字符串(字符字符串) 209 tinytext, text, mediumtext, longtext 210 text 在定义时,不需要定义长度,也不会计算总长度。 211 text 类型在定义时,不可给default值 212 213 -- c. binary, varbinary ---------- 214 类似于char和varchar,用于保存二进制字符串,也就是保存字节字符串而非字符字符串。 215 char, varchar, text 对应 binary, varbinary, blob. 216 217 3. 日期时间类型 218 一般用整型保存时间戳,因为PHP可以很方便的将时间戳进行格式化。 219 datetime 8字节 日期及时间 1000-01-01 00:00:00 到 9999-12-31 23:59:59 220 date 3字节 日期 1000-01-01 到 9999-12-31 221 timestamp 4字节 时间戳 19700101000000 到 2038-01-19 03:14:07 222 time 3字节 时间 -838:59:59 到 838:59:59 223 year 1字节 年份 1901 - 2155 224 225 datetime “YYYY-MM-DD hh:mm:ss” 226 timestamp “YY-MM-DD hh:mm:ss” 227 “YYYYMMDDhhmmss” 228 “YYMMDDhhmmss” 229 YYYYMMDDhhmmss 230 YYMMDDhhmmss 231 date “YYYY-MM-DD” 232 “YY-MM-DD” 233 “YYYYMMDD” 234 “YYMMDD” 235 YYYYMMDD 236 YYMMDD 237 time “hh:mm:ss” 238 “hhmmss” 239 hhmmss 240 year “YYYY” 241 “YY” 242 YYYY 243 YY 244 245 4. 枚举和集合 246 -- 枚举(enum) ---------- 247 enum(val1, val2, val3...) 248 在已知的值中进行单选。最大数量为65535. 249 枚举值在保存时,以2个字节的整型(smallint)保存。每个枚举值,按保存的位置顺序,从1开始逐一递增。 250 表现为字符串类型,存储却是整型。 251 NULL值的索引是NULL。 252 空字符串错误值的索引值是0。 253 254 -- 集合(set) ---------- 255 set(val1, val2, val3...) 256 create table tab ( gender set('男', '女', '无') ); 257 insert into tab values ('男, 女'); 258 最多可以有64个不同的成员。以bigint存储,共8个字节。采取位运算的形式。 259 当创建表时,SET成员值的尾部空格将自动被删除。 260 261 /* 选择类型 */ 262 -- PHP角度 263 1. 功能满足 264 2. 存储空间尽量小,处理效率更高 265 3. 考虑兼容问题 266 267 -- IP存储 ---------- 268 1. 只需存储,可用字符串 269 2. 如果需计算,查找等,可存储为4个字节的无符号int,即unsigned 270 1) PHP函数转换 271 ip2long可转换为整型,但会出现携带符号问题。需格式化为无符号的整型。 272 利用sprintf函数格式化字符串 273 sprintf("%u", ip2long('192.168.3.134')); 274 然后用long2ip将整型转回IP字符串 275 2) MySQL函数转换(无符号整型,UNSIGNED) 276 INET_ATON('127.0.0.1') 将IP转为整型 277 INET_NTOA(2130706433) 将整型转为IP 278 279 280 281 282 /* 列属性(列约束) */ ------------------ 283 1. 主键 284 - 能唯一标识记录的字段,可以作为主键。 285 - 一个表只能有一个主键。 286 - 主键具有唯一性。 287 - 声明字段时,用 primary key 标识。 288 也可以在字段列表之后声明 289 例:create table tab ( id int, stu varchar(10), primary key (id)); 290 - 主键字段的值不能为null。 291 - 主键可以由多个字段共同组成。此时需要在字段列表后声明的方法。 292 例:create table tab ( id int, stu varchar(10), age int, primary key (stu, age)); 293 294 2. unique 唯一索引(唯一约束) 295 使得某字段的值也不能重复。 296 297 3. null 约束 298 null不是数据类型,是列的一个属性。 299 表示当前列是否可以为null,表示什么都没有。 300 null, 允许为空。默认。 301 not null, 不允许为空。 302 insert into tab values (null, 'val'); 303 -- 此时表示将第一个字段的值设为null, 取决于该字段是否允许为null 304 305 4. default 默认值属性 306 当前字段的默认值。 307 insert into tab values (default, 'val'); -- 此时表示强制使用默认值。 308 create table tab ( add_time timestamp default current_timestamp ); 309 -- 表示将当前时间的时间戳设为默认值。 310 current_date, current_time 311 312 5. auto_increment 自动增长约束 313 自动增长必须为索引(主键或unique) 314 只能存在一个字段为自动增长。 315 默认为1开始自动增长。可以通过表属性 auto_increment = x进行设置,或 alter table tbl auto_increment = x; 316 317 6. comment 注释 318 例:create table tab ( id int ) comment '注释内容'; 319 320 7. foreign key 外键约束 321 用于限制主表与从表数据完整性。 322 alter table t1 add constraint `t1_t2_fk` foreign key (t1_id) references t2(id); 323 -- 将表t1的t1_id外键关联到表t2的id字段。 324 -- 每个外键都有一个名字,可以通过 constraint 指定 325 326 存在外键的表,称之为从表(子表),外键指向的表,称之为主表(父表)。 327 328 作用:保持数据一致性,完整性,主要目的是控制存储在外键表(从表)中的数据。 329 330 MySQL中,可以对InnoDB引擎使用外键约束: 331 语法: 332 foreign key (外键字段) references 主表名 (关联字段) [主表记录删除时的动作] [主表记录更新时的动作] 333 此时需要检测一个从表的外键需要约束为主表的已存在的值。外键在没有关联的情况下,可以设置为null.前提是该外键列,没有not null。 334 335 可以不指定主表记录更改或更新时的动作,那么此时主表的操作被拒绝。 336 如果指定了 on update 或 on delete:在删除或更新时,有如下几个操作可以选择: 337 1. cascade,级联操作。主表数据被更新(主键值更新),从表也被更新(外键值更新)。主表记录被删除,从表相关记录也被删除。 338 2. set null,设置为null。主表数据被更新(主键值更新),从表的外键被设置为null。主表记录被删除,从表相关记录外键被设置成null。但注意,要求该外键列,没有not null属性约束。 339 3. restrict,拒绝父表删除和更新。 340 341 注意,外键只被InnoDB存储引擎所支持。其他引擎是不支持的。 342 343 344 /* 建表规范 */ ------------------ 345 -- Normal Format, NF 346 - 每个表保存一个实体信息 347 - 每个具有一个ID字段作为主键 348 - ID主键 + 原子表 349 -- 1NF, 第一范式 350 字段不能再分,就满足第一范式。 351 -- 2NF, 第二范式 352 满足第一范式的前提下,不能出现部分依赖。 353 消除符合主键就可以避免部分依赖。增加单列关键字。 354 -- 3NF, 第三范式 355 满足第二范式的前提下,不能出现传递依赖。 356 某个字段依赖于主键,而有其他字段依赖于该字段。这就是传递依赖。 357 将一个实体信息的数据放在一个表内实现。 358 359 360 /* select */ ------------------ 361 362 select [all|distinct] select_expr from -> where -> group by [合计函数] -> having -> order by -> limit 363 364 a. select_expr 365 -- 可以用 * 表示所有字段。 366 select * from tb; 367 -- 可以使用表达式(计算公式、函数调用、字段也是个表达式) 368 select stu, 29+25, now() from tb; 369 -- 可以为每个列使用别名。适用于简化列标识,避免多个列标识符重复。 370 - 使用 as 关键字,也可省略 as. 371 select stu+10 as add10 from tb; 372 373 b. from 子句 374 用于标识查询来源。 375 -- 可以为表起别名。使用as关键字。 376 select * from tb1 as tt, tb2 as bb; 377 -- from子句后,可以同时出现多个表。 378 -- 多个表会横向叠加到一起,而数据会形成一个笛卡尔积。 379 select * from tb1, tb2; 380 381 c. where 子句 382 -- 从from获得的数据源中进行筛选。 383 -- 整型1表示真,0表示假。 384 -- 表达式由运算符和运算数组成。 385 -- 运算数:变量(字段)、值、函数返回值 386 -- 运算符: 387 =, <=>, <>, !=, <=, <, >=, >, !, &&, ||, 388 in (not) null, (not) like, (not) in, (not) between and, is (not), and, or, not, xor 389 is/is not 加上ture/false/unknown,检验某个值的真假 390 <=>与<>功能相同,<=>可用于null比较 391 392 d. group by 子句, 分组子句 393 group by 字段/别名 [排序方式] 394 分组后会进行排序。升序:ASC,降序:DESC 395 396 以下[合计函数]需配合 group by 使用: 397 count 返回不同的非NULL值数目 count(*)、count(字段) 398 sum 求和 399 max 求最大值 400 min 求最小值 401 avg 求平均值 402 group_concat 返回带有来自一个组的连接的非NULL值的字符串结果。组内字符串连接。 403 404 e. having 子句,条件子句 405 与 where 功能、用法相同,执行时机不同。 406 where 在开始时执行检测数据,对原数据进行过滤。 407 having 对筛选出的结果再次进行过滤。 408 having 字段必须是查询出来的,where 字段必须是数据表存在的。 409 where 不可以使用字段的别名,having 可以。因为执行WHERE代码时,可能尚未确定列值。 410 where 不可以使用合计函数。一般需用合计函数才会用 having 411 SQL标准要求HAVING必须引用GROUP BY子句中的列或用于合计函数中的列。 412 413 f. order by 子句,排序子句 414 order by 排序字段/别名 排序方式 [,排序字段/别名 排序方式]... 415 升序:ASC,降序:DESC 416 支持多个字段的排序。 417 418 g. limit 子句,限制结果数量子句 419 仅对处理好的结果进行数量限制。将处理好的结果的看作是一个集合,按照记录出现的顺序,索引从0开始。 420 limit 起始位置, 获取条数 421 省略第一个参数,表示从索引0开始。limit 获取条数 422 423 h. distinct, all 选项 424 distinct 去除重复记录 425 默认为 all, 全部记录 426 427 428 /* UNION */ ------------------ 429 将多个select查询的结果组合成一个结果集合。 430 SELECT ... UNION [ALL|DISTINCT] SELECT ... 431 默认 DISTINCT 方式,即所有返回的行都是唯一的 432 建议,对每个SELECT查询加上小括号包裹。 433 ORDER BY 排序时,需加上 LIMIT 进行结合。 434 需要各select查询的字段数量一样。 435 每个select查询的字段列表(数量、类型)应一致,因为结果中的字段名以第一条select语句为准。 436 437 438 /* 子查询 */ ------------------ 439 - 子查询需用括号包裹。 440 -- from型 441 from后要求是一个表,必须给子查询结果取个别名。 442 - 简化每个查询内的条件。 443 - from型需将结果生成一个临时表格,可用以原表的锁定的释放。 444 - 子查询返回一个表,表型子查询。 445 select * from (select * from tb where id>0) as subfrom where id>1; 446 -- where型 447 - 子查询返回一个值,标量子查询。 448 - 不需要给子查询取别名。 449 - where子查询内的表,不能直接用以更新。 450 select * from tb where money = (select max(money) from tb); 451 -- 列子查询 452 如果子查询结果返回的是一列。 453 使用 in 或 not in 完成查询 454 exists 和 not exists 条件 455 如果子查询返回数据,则返回1或0。常用于判断条件。 456 select column1 from t1 where exists (select * from t2); 457 -- 行子查询 458 查询条件是一个行。 459 select * from t1 where (id, gender) in (select id, gender from t2); 460 行构造符:(col1, col2, ...) 或 ROW(col1, col2, ...) 461 行构造符通常用于与对能返回两个或两个以上列的子查询进行比较。 462 463 -- 特殊运算符 464 != all() 相当于 not in 465 = some() 相当于 in。any 是 some 的别名 466 != some() 不等同于 not in,不等于其中某一个。 467 all, some 可以配合其他运算符一起使用。 468 469 470 /* 连接查询(join) */ ------------------ 471 将多个表的字段进行连接,可以指定连接条件。 472 -- 内连接(inner join) 473 - 默认就是内连接,可省略inner。 474 - 只有数据存在时才能发送连接。即连接结果不能出现空行。 475 on 表示连接条件。其条件表达式与where类似。也可以省略条件(表示条件永远为真) 476 也可用where表示连接条件。 477 还有 using, 但需字段名相同。 using(字段名) 478 479 -- 交叉连接 cross join 480 即,没有条件的内连接。 481 select * from tb1 cross join tb2; 482 -- 外连接(outer join) 483 - 如果数据不存在,也会出现在连接结果中。 484 -- 左外连接 left join 485 如果数据不存在,左表记录会出现,而右表为null填充 486 -- 右外连接 right join 487 如果数据不存在,右表记录会出现,而左表为null填充 488 -- 自然连接(natural join) 489 自动判断连接条件完成连接。 490 相当于省略了using,会自动查找相同字段名。 491 natural join 492 natural left join 493 natural right join 494 495 select info.id, info.name, info.stu_num, extra_info.hobby, extra_info.sex from info, extra_info where info.stu_num = extra_info.stu_id; 496 497 /* 导入导出 */ ------------------ 498 select * into outfile 文件地址 [控制格式] from 表名; -- 导出表数据 499 load data [local] infile 文件地址 [replace|ignore] into table 表名 [控制格式]; -- 导入数据 500 生成的数据默认的分隔符是制表符 501 local未指定,则数据文件必须在服务器上 502 replace 和 ignore 关键词控制对现有的唯一键记录的重复的处理 503 -- 控制格式 504 fields 控制字段格式 505 默认:fields terminated by '\t' enclosed by '' escaped by '\\' 506 terminated by 'string' -- 终止 507 enclosed by 'char' -- 包裹 508 escaped by 'char' -- 转义 509 -- 示例: 510 SELECT a,b,a+b INTO OUTFILE '/tmp/result.text' 511 FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' 512 LINES TERMINATED BY '\n' 513 FROM test_table; 514 lines 控制行格式 515 默认:lines terminated by '\n' 516 terminated by 'string' -- 终止 517 518 /* insert */ ------------------ 519 select语句获得的数据可以用insert插入。 520 521 可以省略对列的指定,要求 values () 括号内,提供给了按照列顺序出现的所有字段的值。 522 或者使用set语法。 523 insert into tbl_name set field=value,...; 524 525 可以一次性使用多个值,采用(), (), ();的形式。 526 insert into tbl_name values (), (), (); 527 528 可以在列值指定时,使用表达式。 529 insert into tbl_name values (field_value, 10+10, now()); 530 可以使用一个特殊值 default,表示该列使用默认值。 531 insert into tbl_name values (field_value, default); 532 533 可以通过一个查询的结果,作为需要插入的值。 534 insert into tbl_name select ...; 535 536 可以指定在插入的值出现主键(或唯一索引)冲突时,更新其他非主键列的信息。 537 insert into tbl_name values/set/select on duplicate key update 字段=值, …; 538 539 /* delete */ ------------------ 540 DELETE FROM tbl_name [WHERE where_definition] [ORDER BY ...] [LIMIT row_count] 541 542 按照条件删除 543 544 指定删除的最多记录数。Limit 545 546 可以通过排序条件删除。order by + limit 547 548 支持多表删除,使用类似连接语法。 549 delete from 需要删除数据多表1,表2 using 表连接操作 条件。 550 551 /* truncate */ ------------------ 552 TRUNCATE [TABLE] tbl_name 553 清空数据 554 删除重建表 555 556 区别: 557 1,truncate 是删除表再创建,delete 是逐条删除 558 2,truncate 重置auto_increment的值。而delete不会 559 3,truncate 不知道删除了几条,而delete知道。 560 4,当被用于带分区的表时,truncate 会保留分区 561 562 563 /* 备份与还原 */ ------------------ 564 备份,将数据的结构与表内数据保存起来。 565 利用 mysqldump 指令完成。 566 567 -- 导出 568 1. 导出一张表 569 mysqldump -u用户名 -p密码 库名 表名 > 文件名(D:/a.sql) 570 2. 导出多张表 571 mysqldump -u用户名 -p密码 库名 表1 表2 表3 > 文件名(D:/a.sql) 572 3. 导出所有表 573 mysqldump -u用户名 -p密码 库名 > 文件名(D:/a.sql) 574 4. 导出一个库 575 mysqldump -u用户名 -p密码 -B 库名 > 文件名(D:/a.sql) 576 577 可以-w携带备份条件 578 579 -- 导入 580 1. 在登录mysql的情况下: 581 source 备份文件 582 2. 在不登录的情况下 583 mysql -u用户名 -p密码 库名 < 备份文件 584 585 586 /* 视图 */ ------------------ 587 什么是视图: 588 视图是一个虚拟表,其内容由查询定义。同真实的表一样,视图包含一系列带有名称的列和行数据。但是,视图并不在数据库中以存储的数据值集形式存在。行和列数据来自由定义视图的查询所引用的表,并且在引用视图时动态生成。 589 视图具有表结构文件,但不存在数据文件。 590 对其中所引用的基础表来说,视图的作用类似于筛选。定义视图的筛选可以来自当前或其它数据库的一个或多个表,或者其它视图。通过视图进行查询没有任何限制,通过它们进行数据修改时的限制也很少。 591 视图是存储在数据库中的查询的sql语句,它主要出于两种原因:安全原因,视图可以隐藏一些数据,如:社会保险基金表,可以用视图只显示姓名,地址,而不显示社会保险号和工资数等,另一原因是可使复杂的查询易于理解和使用。 592 593 -- 创建视图 594 CREATE [OR REPLACE] [ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}] VIEW view_name [(column_list)] AS select_statement 595 - 视图名必须唯一,同时不能与表重名。 596 - 视图可以使用select语句查询到的列名,也可以自己指定相应的列名。 597 - 可以指定视图执行的算法,通过ALGORITHM指定。 598 - column_list如果存在,则数目必须等于SELECT语句检索的列数 599 600 -- 查看结构 601 SHOW CREATE VIEW view_name 602 603 -- 删除视图 604 - 删除视图后,数据依然存在。 605 - 可同时删除多个视图。 606 DROP VIEW [IF EXISTS] view_name ... 607 608 -- 修改视图结构 609 - 一般不修改视图,因为不是所有的更新视图都会映射到表上。 610 ALTER VIEW view_name [(column_list)] AS select_statement 611 612 -- 视图作用 613 1. 简化业务逻辑 614 2. 对客户端隐藏真实的表结构 615 616 -- 视图算法(ALGORITHM) 617 MERGE 合并 618 将视图的查询语句,与外部查询需要先合并再执行! 619 TEMPTABLE 临时表 620 将视图执行完毕后,形成临时表,再做外层查询! 621 UNDEFINED 未定义(默认),指的是MySQL自主去选择相应的算法。 622 623 624 625 /* 事务(transaction) */ ------------------ 626 事务是指逻辑上的一组操作,组成这组操作的各个单元,要不全成功要不全失败。 627 - 支持连续SQL的集体成功或集体撤销。 628 - 事务是数据库在数据晚自习方面的一个功能。 629 - 需要利用 InnoDB 或 BDB 存储引擎,对自动提交的特性支持完成。 630 - InnoDB被称为事务安全型引擎。 631 632 -- 事务开启 633 START TRANSACTION; 或者 BEGIN; 634 开启事务后,所有被执行的SQL语句均被认作当前事务内的SQL语句。 635 -- 事务提交 636 COMMIT; 637 -- 事务回滚 638 ROLLBACK; 639 如果部分操作发生问题,映射到事务开启前。 640 641 -- 事务的特性 642 1. 原子性(Atomicity) 643 事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。 644 2. 一致性(Consistency) 645 事务前后数据的完整性必须保持一致。 646 - 事务开始和结束时,外部数据一致 647 - 在整个事务过程中,操作是连续的 648 3. 隔离性(Isolation) 649 多个用户并发访问数据库时,一个用户的事务不能被其它用户的事物所干扰,多个并发事务之间的数据要相互隔离。 650 4. 持久性(Durability) 651 一个事务一旦被提交,它对数据库中的数据改变就是永久性的。 652 653 -- 事务的实现 654 1. 要求是事务支持的表类型 655 2. 执行一组相关的操作前开启事务 656 3. 整组操作完成后,都成功,则提交;如果存在失败,选择回滚,则会回到事务开始的备份点。 657 658 -- 事务的原理 659 利用InnoDB的自动提交(autocommit)特性完成。 660 普通的MySQL执行语句后,当前的数据提交操作均可被其他客户端可见。 661 而事务是暂时关闭“自动提交”机制,需要commit提交持久化数据操作。 662 663 -- 注意 664 1. 数据定义语言(DDL)语句不能被回滚,比如创建或取消数据库的语句,和创建、取消或更改表或存储的子程序的语句。 665 2. 事务不能被嵌套 666 667 -- 保存点 668 SAVEPOINT 保存点名称 -- 设置一个事务保存点 669 ROLLBACK TO SAVEPOINT 保存点名称 -- 回滚到保存点 670 RELEASE SAVEPOINT 保存点名称 -- 删除保存点 671 672 -- InnoDB自动提交特性设置 673 SET autocommit = 0|1; 0表示关闭自动提交,1表示开启自动提交。 674 - 如果关闭了,那普通操作的结果对其他客户端也不可见,需要commit提交后才能持久化数据操作。 675 - 也可以关闭自动提交来开启事务。但与START TRANSACTION不同的是, 676 SET autocommit是永久改变服务器的设置,直到下次再次修改该设置。(针对当前连接) 677 而START TRANSACTION记录开启前的状态,而一旦事务提交或回滚后就需要再次开启事务。(针对当前事务) 678 679 680 /* 锁表 */ 681 表锁定只用于防止其它客户端进行不正当地读取和写入 682 MyISAM 支持表锁,InnoDB 支持行锁 683 -- 锁定 684 LOCK TABLES tbl_name [AS alias] 685 -- 解锁 686 UNLOCK TABLES 687 688 689 /* 触发器 */ ------------------ 690 触发程序是与表有关的命名数据库对象,当该表出现特定事件时,将激活该对象 691 监听:记录的增加、修改、删除。 692 693 -- 创建触发器 694 CREATE TRIGGER trigger_name trigger_time trigger_event ON tbl_name FOR EACH ROW trigger_stmt 695 参数: 696 trigger_time是触发程序的动作时间。它可以是 before 或 after,以指明触发程序是在激活它的语句之前或之后触发。 697 trigger_event指明了激活触发程序的语句的类型 698 INSERT:将新行插入表时激活触发程序 699 UPDATE:更改某一行时激活触发程序 700 DELETE:从表中删除某一行时激活触发程序 701 tbl_name:监听的表,必须是永久性的表,不能将触发程序与TEMPORARY表或视图关联起来。 702 trigger_stmt:当触发程序激活时执行的语句。执行多个语句,可使用BEGIN...END复合语句结构 703 704 -- 删除 705 DROP TRIGGER [schema_name.]trigger_name 706 707 可以使用old和new代替旧的和新的数据 708 更新操作,更新前是old,更新后是new. 709 删除操作,只有old. 710 增加操作,只有new. 711 712 -- 注意 713 1. 对于具有相同触发程序动作时间和事件的给定表,不能有两个触发程序。 714 715 716 -- 字符连接函数 717 concat(str1[, str2,...]) 718 719 -- 分支语句 720 if 条件 then 721 执行语句 722 elseif 条件 then 723 执行语句 724 else 725 执行语句 726 end if; 727 728 -- 修改最外层语句结束符 729 delimiter 自定义结束符号 730 SQL语句 731 自定义结束符号 732 733 delimiter ; -- 修改回原来的分号 734 735 -- 语句块包裹 736 begin 737 语句块 738 end 739 740 -- 特殊的执行 741 1. 只要添加记录,就会触发程序。 742 2. Insert into on duplicate key update 语法会触发: 743 如果没有重复记录,会触发 before insert, after insert; 744 如果有重复记录并更新,会触发 before insert, before update, after update; 745 如果有重复记录但是没有发生更新,则触发 before insert, before update 746 3. Replace 语法 如果有记录,则执行 before insert, before delete, after delete, after insert 747 748 749 /* SQL编程 */ ------------------ 750 751 --// 局部变量 ---------- 752 -- 变量声明 753 declare var_name[,...] type [default value] 754 这个语句被用来声明局部变量。要给变量提供一个默认值,请包含一个default子句。值可以被指定为一个表达式,不需要为一个常数。如果没有default子句,初始值为null。 755 756 -- 赋值 757 使用 set 和 select into 语句为变量赋值。 758 759 - 注意:在函数内是可以使用全局变量(用户自定义的变量) 760 761 762 --// 全局变量 ---------- 763 -- 定义、赋值 764 set 语句可以定义并为变量赋值。 765 set @var = value; 766 也可以使用select into语句为变量初始化并赋值。这样要求select语句只能返回一行,但是可以是多个字段,就意味着同时为多个变量进行赋值,变量的数量需要与查询的列数一致。 767 还可以把赋值语句看作一个表达式,通过select执行完成。此时为了避免=被当作关系运算符看待,使用:=代替。(set语句可以使用= 和 :=)。 768 select @var:=20; 769 select @v1:=id, @v2=name from t1 limit 1; 770 select * from tbl_name where @var:=30; 771 772 select into 可以将表中查询获得的数据赋给变量。 773 -| select max(height) into @max_height from tb; 774 775 -- 自定义变量名 776 为了避免select语句中,用户自定义的变量与系统标识符(通常是字段名)冲突,用户自定义变量在变量名前使用@作为开始符号。 777 @var=10; 778 779 - 变量被定义后,在整个会话周期都有效(登录到退出) 780 781 782 --// 控制结构 ---------- 783 -- if语句 784 if search_condition then 785 statement_list 786 [elseif search_condition then 787 statement_list] 788 ... 789 [else 790 statement_list] 791 end if; 792 793 -- case语句 794 CASE value WHEN [compare-value] THEN result 795 [WHEN [compare-value] THEN result ...] 796 [ELSE result] 797 END 798 799 800 -- while循环 801 [begin_label:] while search_condition do 802 statement_list 803 end while [end_label]; 804 805 - 如果需要在循环内提前终止 while循环,则需要使用标签;标签需要成对出现。 806 807 -- 退出循环 808 退出整个循环 leave 809 退出当前循环 iterate 810 通过退出的标签决定退出哪个循环 811 812 813 --// 内置函数 ---------- 814 -- 数值函数 815 abs(x) -- 绝对值 abs(-10.9) = 10 816 format(x, d) -- 格式化千分位数值 format(1234567.456, 2) = 1,234,567.46 817 ceil(x) -- 向上取整 ceil(10.1) = 11 818 floor(x) -- 向下取整 floor (10.1) = 10 819 round(x) -- 四舍五入去整 820 mod(m, n) -- m%n m mod n 求余 10%3=1 821 pi() -- 获得圆周率 822 pow(m, n) -- m^n 823 sqrt(x) -- 算术平方根 824 rand() -- 随机数 825 truncate(x, d) -- 截取d位小数 826 827 -- 时间日期函数 828 now(), current_timestamp(); -- 当前日期时间 829 current_date(); -- 当前日期 830 current_time(); -- 当前时间 831 date('yyyy-mm-dd hh:ii:ss'); -- 获取日期部分 832 time('yyyy-mm-dd hh:ii:ss'); -- 获取时间部分 833 date_format('yyyy-mm-dd hh:ii:ss', '%d %y %a %d %m %b %j'); -- 格式化时间 834 unix_timestamp(); -- 获得unix时间戳 835 from_unixtime(); -- 从时间戳获得时间 836 837 -- 字符串函数 838 length(string) -- string长度,字节 839 char_length(string) -- string的字符个数 840 substring(str, position [,length]) -- 从str的position开始,取length个字符 841 replace(str ,search_str ,replace_str) -- 在str中用replace_str替换search_str 842 instr(string ,substring) -- 返回substring首次在string中出现的位置 843 concat(string [,...]) -- 连接字串 844 charset(str) -- 返回字串字符集 845 lcase(string) -- 转换成小写 846 left(string, length) -- 从string2中的左边起取length个字符 847 load_file(file_name) -- 从文件读取内容 848 locate(substring, string [,start_position]) -- 同instr,但可指定开始位置 849 lpad(string, length, pad) -- 重复用pad加在string开头,直到字串长度为length 850 ltrim(string) -- 去除前端空格 851 repeat(string, count) -- 重复count次 852 rpad(string, length, pad) --在str后用pad补充,直到长度为length 853 rtrim(string) -- 去除后端空格 854 strcmp(string1 ,string2) -- 逐字符比较两字串大小 855 856 -- 流程函数 857 case when [condition] then result [when [condition] then result ...] [else result] end 多分支 858 if(expr1,expr2,expr3) 双分支。 859 860 -- 聚合函数 861 count() 862 sum(); 863 max(); 864 min(); 865 avg(); 866 group_concat() 867 868 -- 其他常用函数 869 md5(); 870 default(); 871 872 873 --// 存储函数,自定义函数 ---------- 874 -- 新建 875 CREATE FUNCTION function_name (参数列表) RETURNS 返回值类型 876 函数体 877 878 - 函数名,应该合法的标识符,并且不应该与已有的关键字冲突。 879 - 一个函数应该属于某个数据库,可以使用db_name.funciton_name的形式执行当前函数所属数据库,否则为当前数据库。 880 - 参数部分,由"参数名"和"参数类型"组成。多个参数用逗号隔开。 881 - 函数体由多条可用的mysql语句,流程控制,变量声明等语句构成。 882 - 多条语句应该使用 begin...end 语句块包含。 883 - 一定要有 return 返回值语句。 884 885 -- 删除 886 DROP FUNCTION [IF EXISTS] function_name; 887 888 -- 查看 889 SHOW FUNCTION STATUS LIKE 'partten' 890 SHOW CREATE FUNCTION function_name; 891 892 -- 修改 893 ALTER FUNCTION function_name 函数选项 894 895 896 --// 存储过程,自定义功能 ---------- 897 -- 定义 898 存储存储过程 是一段代码(过程),存储在数据库中的sql组成。 899 一个存储过程通常用于完成一段业务逻辑,例如报名,交班费,订单入库等。 900 而一个函数通常专注与某个功能,视为其他程序服务的,需要在其他语句中调用函数才可以,而存储过程不能被其他调用,是自己执行 通过call执行。 901 902 -- 创建 903 CREATE PROCEDURE sp_name (参数列表) 904 过程体 905 906 参数列表:不同于函数的参数列表,需要指明参数类型 907 IN,表示输入型 908 OUT,表示输出型 909 INOUT,表示混合型 910 911 注意,没有返回值。 912 913 914 /* 存储过程 */ ------------------ 915 存储过程是一段可执行性代码的集合。相比函数,更偏向于业务逻辑。 916 调用:CALL 过程名 917 -- 注意 918 - 没有返回值。 919 - 只能单独调用,不可夹杂在其他语句中 920 921 -- 参数 922 IN|OUT|INOUT 参数名 数据类型 923 IN 输入:在调用过程中,将数据输入到过程体内部的参数 924 OUT 输出:在调用过程中,将过程体处理完的结果返回到客户端 925 INOUT 输入输出:既可输入,也可输出 926 927 -- 语法 928 CREATE PROCEDURE 过程名 (参数列表) 929 BEGIN 930 过程体 931 END 932 933 934 /* 用户和权限管理 */ ------------------ 935 用户信息表:mysql.user 936 -- 刷新权限 937 FLUSH PRIVILEGES 938 -- 增加用户 939 CREATE USER 用户名 IDENTIFIED BY [PASSWORD] 密码(字符串) 940 - 必须拥有mysql数据库的全局CREATE USER权限,或拥有INSERT权限。 941 - 只能创建用户,不能赋予权限。 942 - 用户名,注意引号:如 'user_name'@'192.168.1.1' 943 - 密码也需引号,纯数字密码也要加引号 944 - 要在纯文本中指定密码,需忽略PASSWORD关键词。要把密码指定为由PASSWORD()函数返回的混编值,需包含关键字PASSWORD 945 -- 重命名用户 946 RENAME USER old_user TO new_user 947 -- 设置密码 948 SET PASSWORD = PASSWORD('密码') -- 为当前用户设置密码 949 SET PASSWORD FOR 用户名 = PASSWORD('密码') -- 为指定用户设置密码 950 -- 删除用户 951 DROP USER 用户名 952 -- 分配权限/添加用户 953 GRANT 权限列表 ON 表名 TO 用户名 [IDENTIFIED BY [PASSWORD] 'password'] 954 - all privileges 表示所有权限 955 - *.* 表示所有库的所有表 956 - 库名.表名 表示某库下面的某表 957 -- 查看权限 958 SHOW GRANTS FOR 用户名 959 -- 查看当前用户权限 960 SHOW GRANTS; 或 SHOW GRANTS FOR CURRENT_USER; 或 SHOW GRANTS FOR CURRENT_USER(); 961 -- 撤消权限 962 REVOKE 权限列表 ON 表名 FROM 用户名 963 REVOKE ALL PRIVILEGES, GRANT OPTION FROM 用户名 -- 撤销所有权限 964 -- 权限层级 965 -- 要使用GRANT或REVOKE,您必须拥有GRANT OPTION权限,并且您必须用于您正在授予或撤销的权限。 966 全局层级:全局权限适用于一个给定服务器中的所有数据库,mysql.user 967 GRANT ALL ON *.*和 REVOKE ALL ON *.*只授予和撤销全局权限。 968 数据库层级:数据库权限适用于一个给定数据库中的所有目标,mysql.db, mysql.host 969 GRANT ALL ON db_name.*和REVOKE ALL ON db_name.*只授予和撤销数据库权限。 970 表层级:表权限适用于一个给定表中的所有列,mysql.talbes_priv 971 GRANT ALL ON db_name.tbl_name和REVOKE ALL ON db_name.tbl_name只授予和撤销表权限。 972 列层级:列权限适用于一个给定表中的单一列,mysql.columns_priv 973 当使用REVOKE时,您必须指定与被授权列相同的列。 974 -- 权限列表 975 ALL [PRIVILEGES] -- 设置除GRANT OPTION之外的所有简单权限 976 ALTER -- 允许使用ALTER TABLE 977 ALTER ROUTINE -- 更改或取消已存储的子程序 978 CREATE -- 允许使用CREATE TABLE 979 CREATE ROUTINE -- 创建已存储的子程序 980 CREATE TEMPORARY TABLES -- 允许使用CREATE TEMPORARY TABLE 981 CREATE USER -- 允许使用CREATE USER, DROP USER, RENAME USER和REVOKE ALL PRIVILEGES。 982 CREATE VIEW -- 允许使用CREATE VIEW 983 DELETE -- 允许使用DELETE 984 DROP -- 允许使用DROP TABLE 985 EXECUTE -- 允许用户运行已存储的子程序 986 FILE -- 允许使用SELECT...INTO OUTFILE和LOAD DATA INFILE 987 INDEX -- 允许使用CREATE INDEX和DROP INDEX 988 INSERT -- 允许使用INSERT 989 LOCK TABLES -- 允许对您拥有SELECT权限的表使用LOCK TABLES 990 PROCESS -- 允许使用SHOW FULL PROCESSLIST 991 REFERENCES -- 未被实施 992 RELOAD -- 允许使用FLUSH 993 REPLICATION CLIENT -- 允许用户询问从属服务器或主服务器的地址 994 REPLICATION SLAVE -- 用于复制型从属服务器(从主服务器中读取二进制日志事件) 995 SELECT -- 允许使用SELECT 996 SHOW DATABASES -- 显示所有数据库 997 SHOW VIEW -- 允许使用SHOW CREATE VIEW 998 SHUTDOWN -- 允许使用mysqladmin shutdown 999 SUPER -- 允许使用CHANGE MASTER, KILL, PURGE MASTER LOGS和SET GLOBAL语句,mysqladmin debug命令;允许您连接(一次),即使已达到max_connections。 1000 UPDATE -- 允许使用UPDATE 1001 USAGE -- “无权限”的同义词 1002 GRANT OPTION -- 允许授予权限 1003 1004 1005 /* 表维护 */ 1006 -- 分析和存储表的关键字分布 1007 ANALYZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE 表名 ... 1008 -- 检查一个或多个表是否有错误 1009 CHECK TABLE tbl_name [, tbl_name] ... [option] ... 1010 option = {QUICK | FAST | MEDIUM | EXTENDED | CHANGED} 1011 -- 整理数据文件的碎片 1012 OPTIMIZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ... 1013 1014 1015 /* 杂项 */ ------------------ 1016 1. 可用反引号(`)为标识符(库名、表名、字段名、索引、别名)包裹,以避免与关键字重名!中文也可以作为标识符! 1017 2. 每个库目录存在一个保存当前数据库的选项文件db.opt。 1018 3. 注释: 1019 单行注释 # 注释内容 1020 多行注释 /* 注释内容 */ 1021 单行注释 -- 注释内容 (标准SQL注释风格,要求双破折号后加一空格符(空格、TAB、换行等)) 1022 4. 模式通配符: 1023 _ 任意单个字符 1024 % 任意多个字符,甚至包括零字符 1025 单引号需要进行转义 \' 1026 5. CMD命令行内的语句结束符可以为 ";", "\G", "\g",仅影响显示结果。其他地方还是用分号结束。delimiter 可修改当前对话的语句结束符。 1027 6. SQL对大小写不敏感 1028 7. 清除已有语句:\c
更多最新文章:【传送门】
********** 如果您认为这篇文章还不错或者有所收获,请点击右下角的【推荐】/【赞助】按钮,因为您的支持是我继续写作,分享的最大动力! **********
作者:讲文张字
出处:https://www.cnblogs.com/zhangwencheng
版权:本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出
原文链接
出处:https://www.cnblogs.com/zhangwencheng
版权:本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出
原文链接
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/206077.html

