
前言
在最近的互联网项目开发中,需要获取用户的访问ip信息进行统计的需求,用户的访问方式可能会从微信内置浏览器、Windows浏览器等方式对产品进行访问。
当然,获取这些关于ip的信息是合法的。但是,这些ip信息我们采用了其它第三方的服务来记录,并不在我们的数据库中。
这些ip信息是分组存放的,且每个分组都都是分页(1页10条)存放的,如果一次性访问大量的数据,API很有可能会报错。
怎样通过HTTP的方式去获取到信息,并且模拟浏览器每页每页获取10条的信息,且持久到数据库中,就成了当下亟需解决的问题。
通过以上的分析,可以有大致以下思路:
1、拿到该网页http请求的url地址,同时获取到调用该网页信息的参数(如:header、param等);
2、针对分页参数进行设计,由于需要不断地访问同一个接口,所以可以用循环+递归的方式来调用;
3、将http接口的信息进行解析,同时保证一定的访问频率(大部分外部http请求都会有访问频率限制)让返回的数据准确;
4、整理和转化数据,按照一定的条件,批量持久化到数据库中。
一、模拟http请求
我们除了在项目自己写API接口提供服务访问外,很多时候也会使用到外部服务的API接口,通过调用这些API来返回我们需要的数据。
如:
钉钉开放平台https://open.dingtalk.com/document/orgapp/user-information-creation、
微信开放平台https://open.weixin.qq.com/cgi-bin/index?t=home/index&lang=zh_CN等等进行开发。
这里分享一下从普通网页获取http接口url的方式,从而达到模拟http请求的效果:
以谷歌chrome浏览器为例,打开调式模式,根据下图步骤: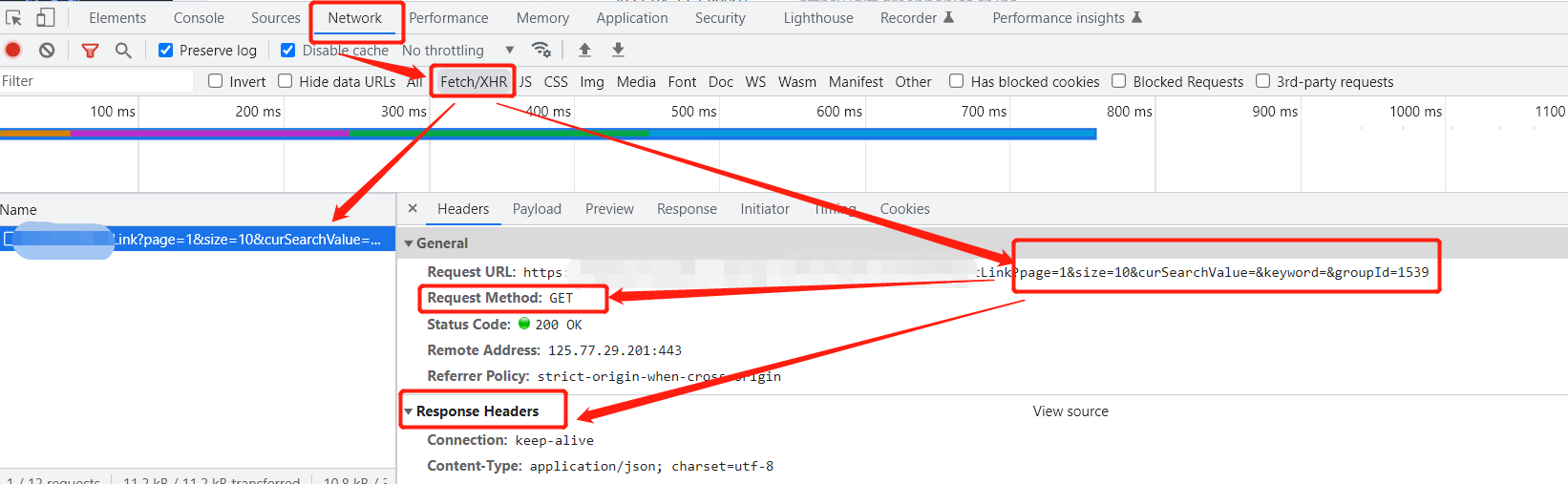
尤其注意使用Fetch/XHR,右键该url—>copy—>copy as cURL(bash):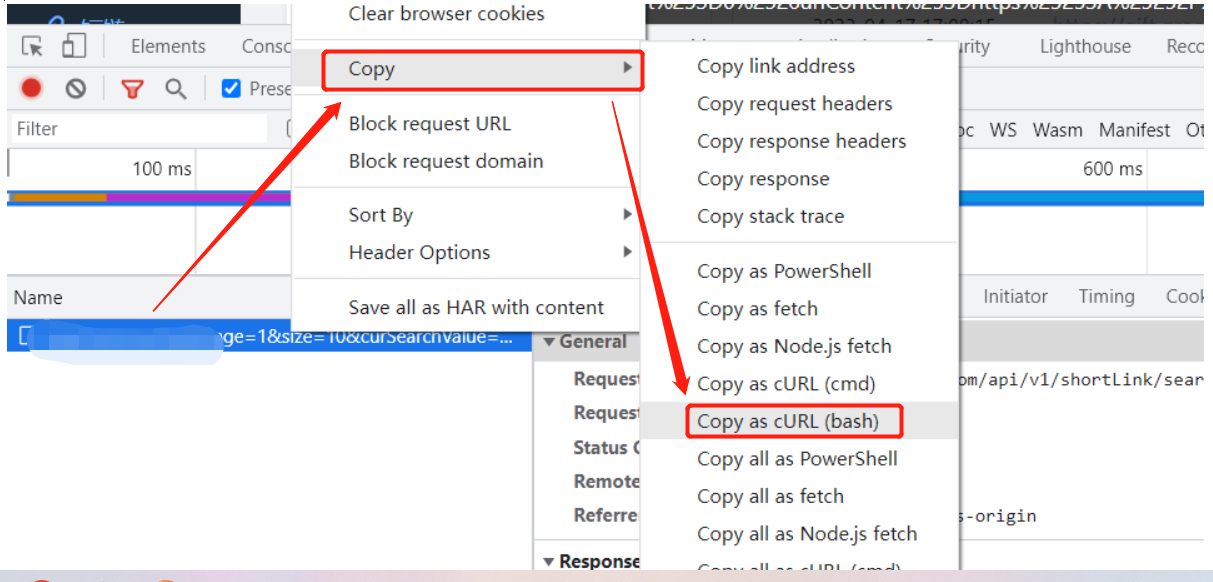
随后粘贴到Postman中,模拟http请求: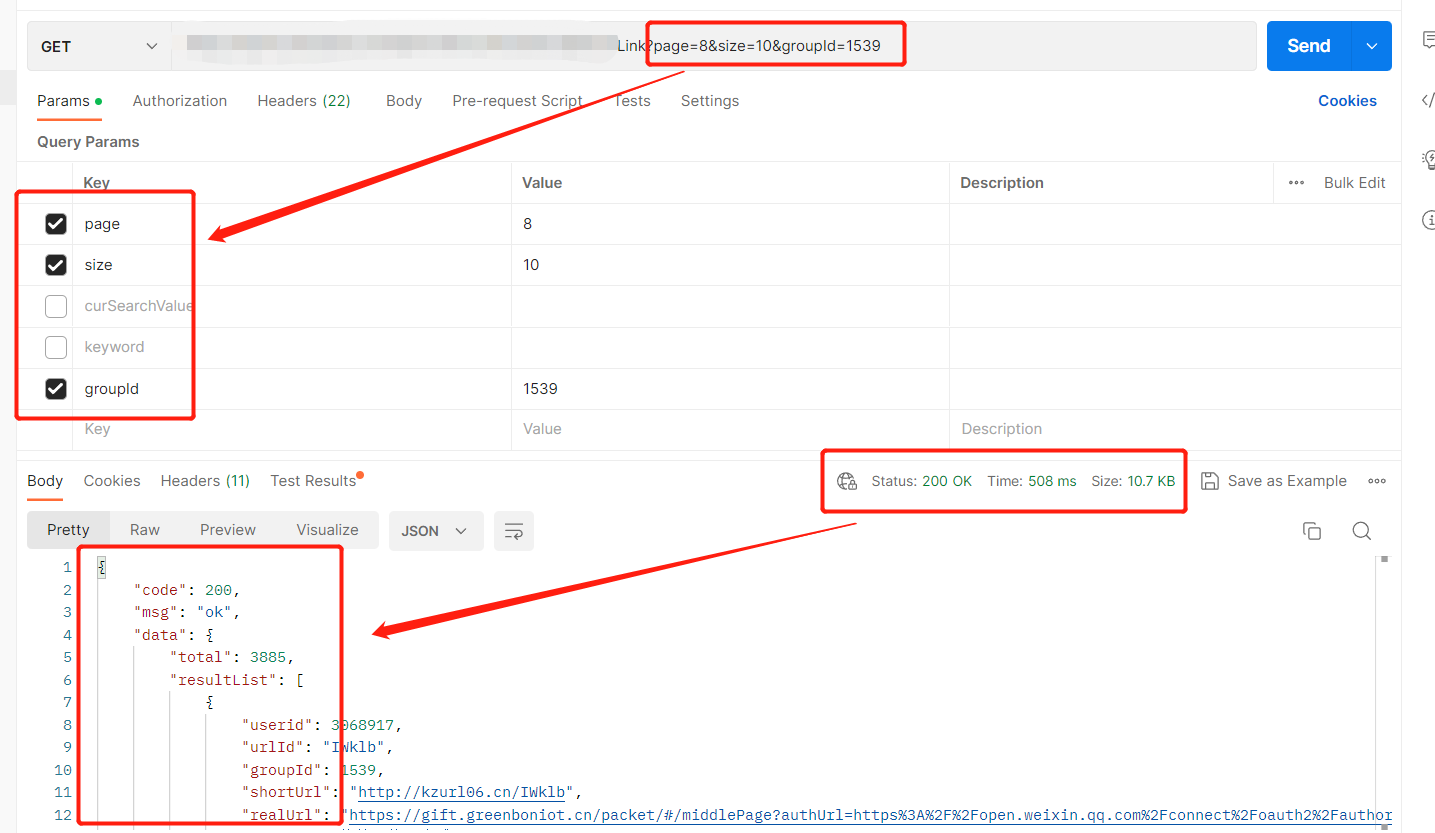
粘贴的同时,还会自动带上header参数(以下这4个参数比较重要,尤其是cookie):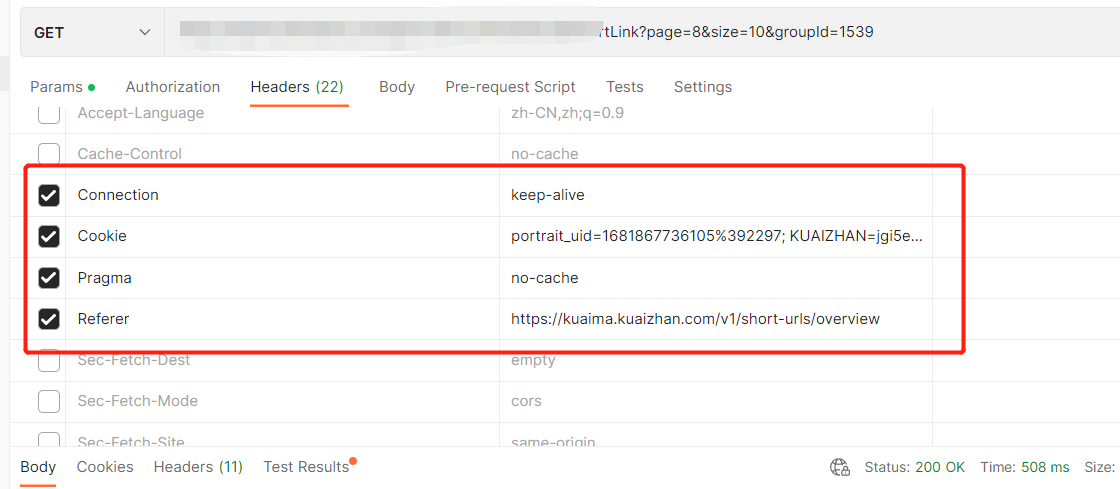
这样,就可以访问到所需的数据了,并且数据是json格式化的,这便于我们下一步的数据解析。
二、递归+循环设计
有几个要点需要注意:
1、分内外两层,内外都需要获取数据,即外层获取的数据是内层所需要的;
2、每页按照10条数据来返回,直到该请求没有数据,则访问下一个请求;
3、递归获取当前请求的数据,注意页数的增加和递归终止条件。
废话不多说,直接上代码:
点击查看代码
public boolean getIpPoolOriginLinksInfo(HashMap<String, Object> commonPageMap, HashMap<String, String> headersMap,String charset){
//接口调用频率限制
check(commonAPICheckData);
String linkUrl = "https://xxx.xxx.com/api/v1/xxx/xxx";
HashMap<String, Object> linkParamsMap = new HashMap<>();
linkParamsMap.put("page",commonPageMap.get("page"));
linkParamsMap.put("size",commonPageMap.get("size"));
String httpLinkResponse = null;
//封装好的工具类,可以直接用apache的原生httpClient,也可以用Hutool的工具包
httpLinkResponse = IpPoolHttpUtils.doGet(linkUrl,linkParamsMap,headersMap,charset);
JSONObject linkJson = null;
JSONArray linkArray = null;
linkJson = JSON.parseObject(httpLinkResponse).getJSONObject("data");
linkArray = linkJson.getJSONArray("resultList");
if (linkArray != null){
//递归计数
if (!commonPageMap.get("page").toString().equals("1")){
commonPageMap.put("page","1");
}
// 每10条urlId,逐一遍历
for (Object linkObj : linkJson.getJSONArray("resultList")) {
JSONObject info = JSON.parseObject(linkObj.toString());
String urlId = info.getString("urlId");
// 获取到的每个urlId,根据urlId去获取ip信息(即内层的业务逻辑,我这里忽略,本质就是拿这里的参数传到内层的方法中去)
boolean flag = getIpPoolOriginRecords(urlId, commonPageMap, headersMap, charset);
if (!flag){
break;
}
}
Integer page = Integer.parseInt(linkParamsMap.get("page").toString());
if (page <= Math.ceil(Integer.parseInt(linkJson.getString("total"))/10)){
Integer newPage = Integer.parseInt(linkParamsMap.get("page").toString()) + 1;
linkParamsMap.put("page", Integer.toString(newPage));
// 递归分页拉取
getIpPoolOriginLinksInfo(linkParamsMap,headersMap,charset);
}
else {
return true;
}
}
return true;
}
三、解析数据(调用频率限制)
一般来说,调用外部API接口会有调用频率的限制,即一段时间内不允许频繁请求接口,否则会返回报错,或者禁止调用。基于这样的限制,我们可以简单设计一个接口校验频率的方法,防止请求的频率太快。
废话不多说,代码如下:
点击查看代码
/**
* 调用频率校验,按照分钟为单位校验
* @param commonAPICheckData
*/
private void check(CommonAPICheckData commonAPICheckData){
int minuteCount = commonAPICheckData.getMinuteCount();
try {
if (minuteCount < 2){
//接近频率限制时,休眠2秒
Thread.sleep(2000);
}else {
commonAPICheckData.setMinuteCount(minuteCount-1);
}
} catch (InterruptedException e) {
throw new RuntimeException("-------外部API调用频率错误!--------");
}
}
CommonAPICheckData类代码:
点击查看代码
@Data
public class CommonAPICheckData {
/**
* 每秒调用次数计数器,限制频率:每秒钟2次
*/
private int secondCount = 3;
/**
* 每分钟调用次数计数器,频率限制:每分钟100次
*/
private int minuteCount = 100;
}
四、数据持久化
爬出来的数据我这里是按照一条一条入库的,当然也可以按照批次进行batch的方式入库:
点击查看代码
/**
* 数据持久化
* @param commonIpPool
*/
private boolean getIpPoolDetails(CommonIpPool commonIpPool){
try {
//list元素去重,ip字段唯一索引
commonIpPoolService.insert(commonIpPool);
} catch (Exception e) {
if (e instanceof DuplicateKeyException){
return true;
}
throw new RuntimeException(e.getMessage());
}
return true;
}
五、小结
其实,爬取数据的时候我们会遇到各种各样的场景,这次分享的主要是分页递归的相关思路。
有的时候,如果网页做了防爬的功能,比如在header上加签、访问前进行滑动图片校验、在cookie上做加密等等,之后有时间还会接着分享。
代码比较粗糙,如果大家有其它建议,欢迎讨论。
如有错误,还望大家指正。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/207991.html

