
PDF文件是一种静态文档格式,通常难以编辑,而Excel则是一个灵活的表格工具。如果你需要处理PDF表格中的数据,那么将其导出为Excel文件可以大大节省工作时间和精力。Excel提供的强大数据编辑和格式化功能,允许你对转换后的PDF数据进行修改、排序、筛选、计算等操作。同时,你还可以调整单元格大小、更改字体、应用样式等。本文将提供在Python中将PDF表格转换为Excel文件的解决方案。
一、环境准备
需要先安装Spire.PDF for Python库来帮助实现PDF转Excel。可以通过以下pip命令安装:(或参考 如何在 VS Code 中安装 Spire.PDF for Python)
pip install Spire.PDF
二、Python 将PDF转为Excel 实现步骤
1. 加载PDF文档。
2. 创建 XlsxLineLayoutOptions 类的对象来指定转换选项。
3. 应用上述设置的转换选项,然后使用 PdfDocument.SaveToFile() 将PDF文件保存为Excel xlsx表格。
其中XlsxLineLayoutOptions类的构造函数接受以下5个参数:
| 参数 | 描述 |
| convertToMultipleSheet (bool) | 表示是否将多个 PDF 页面渲染到一个 Excel 工作表中 |
| rotatedText (bool) | 表示是否显示旋转的文本 |
| splitCell (bool) | 表示一个包含多行文本的 PDF 表格单元格是否会在 Excel 中被拆分成多行 |
| wrapText (bool) | 表示是否对 Excel 单元格中的文本进行换行 |
| overlapText (bool) | 表示是否显示重叠的文本 |
测试代码:
from spire.pdf.common import * from spire.pdf import * # 创建PdfDocument对象 pdf = PdfDocument() # 加载PDF文档 pdf.LoadFromFile("数据.pdf") # 创建 XlsxLineLayoutOptions 对象来指定转换选项 convertOptions = XlsxLineLayoutOptions(True, True, False, True, False) # 设置转换选项 pdf.ConvertOptions.SetPdfToXlsxOptions(convertOptions) # 将PDF文档保存为Excel XLSX格式 pdf.SaveToFile("Pdf转Excel.xlsx", FileFormat.XLSX) pdf.Close()
转换结果:
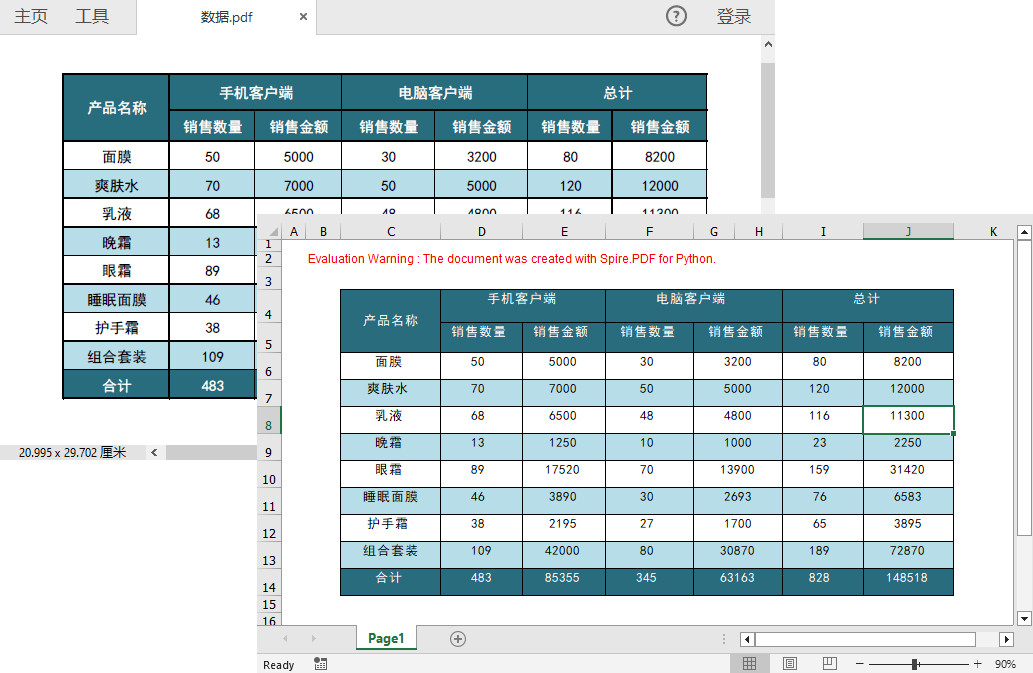
实现更多Python对PDF文档的处理功能:Spire.PDF for Python 中文教程
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/209140.html

