
C-06.多表查询
多表查询,也称为关联查询,指两个或更多个表一起完成查询操作。
前提条件,这些一起查询的表之间是有关系的(一对一,一对多等),它们之间一定是有关联字段,这个关联字段可能建立了外键,也可能没有建立外键。
1.一个案例引发的多表连接
1.1 案例说明
涉及到的表结构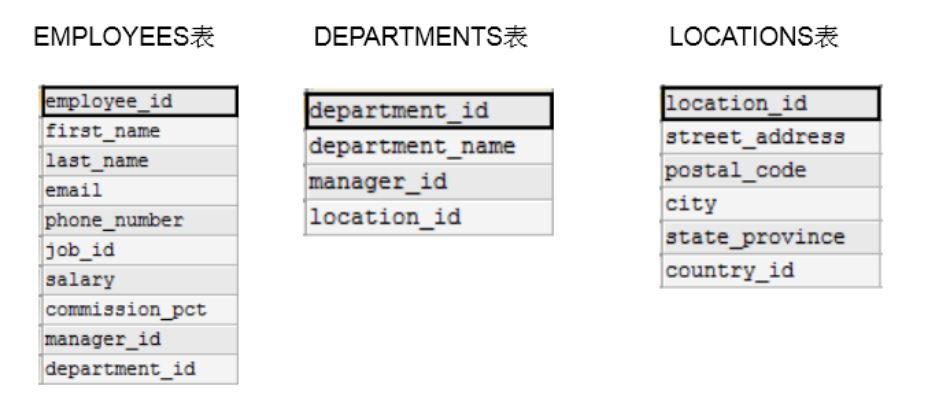
查询员工名(last_name)为’Abel’在那个城市工作。
1.1.2 非多表查询实现
-- 第一步,首先查出'Abel'所在的department_id 部门id
SELECT department_id FROM employees WHERE last_name = 'Abel' LIMIT 0,1;
-- 第二步,查出Abel所在部门,对应的location_id 地区id
SELECT location_id FROM departments WHERE department_id = ();//第一步查出的数据
-- 第三步,根据location_id获取,city信息
SELECT city FROM locations WHERE location_id = ();//第二步查出的数据
但是,这样有问题,为了查出Abel工作的城市,需要执行3次sql,很浪费时间。
1.1.3 多表查询实现
-- 使用多表查询中
SELECT last_name,city
FROM employees,departments,locations
WHERE employees.department_id = departments.department_id
AND departments.location_id = locations.location_id;
-- 上述可以优化
SELECT e.last_name,l.city
FROM employees e,departments d,locations l
WHERE e.department_id = d.department_id
AND d.location_id = l.location_id;
为什么,多表查询,以及优化的内容要这样写,后续会介绍。
1.2 笛卡尔积(交叉连接)的理解
笛卡尔积是一个数学运算。假设有两个集合X{a,b},Y{m,n},那么X和Y的笛卡尔积就是X和Y的所有可能组合,也就是这样一个公式
X={a,b},Y={m,n},X和Y的笛卡尔积 = {a,m},{a,n},{b,m},{b,n};
对应的两张表里的笛卡尔积就是,假设a表和b表,a表和b表的笛卡尔积就是a表中的任意一条数据和b表中的任意一条数据组合。理想情况下,a表有m条数据,b表有n条数据,则下a表和b表的笛卡尔积(也就是进行联合查询)后的表,应该有m * n条数据。
这里用employees表和departments表进行笛卡尔积演示。
mysql> SELECT COUNT(*) FROM employees;//count(*)统计表中非空列的数据
+----------+
| COUNT(*) |
+----------+
| 107 |
+----------+
1 row in set (0.00 sec)
mysql> SELECT COUNT(*) FROM departments;
+----------+
| COUNT(*) |
+----------+
| 27 |
+----------+
1 row in set (0.00 sec)
mysql> SELECT COUNT(*) FROM employees,departments;
+----------+
| COUNT(*) |
+----------+
| 2889 |
+----------+
1 row in set (0.00 sec)//107 * 27 = 2889
在SQL92(1992年发布的SQL标准)中,笛卡尔积也称为交叉连接,英文是CROSS JOIN。在SQL99(1999年发布的SQL标准)也是使用CROSS JOIN表示交叉连接。它的作用就是可以把任意表进行连接,即使这两张表不相关。在MySQL中如下情况下会出现笛卡尔积:
-- 以employees,departments表举例
SELECT last_name,department_name FROM employees,departments;
SELECT last_name,department_name FROM employees CROSS JOIN departments;
SELECT last_name,department_name FROM employees INNER JOIN departments;-- INNER JOIN 内连接
SELECT last_name,department_name FROM employees JOIN departments;
1.3 案例分析和问题解决
- 会出现笛卡尔积的原因
- 省略多个表的连接条件(也叫过滤笛卡尔积的条件)。
- 连接条件无效。
- 所有表中的所有行互相连接(很少出现)。
- 为了避免笛卡尔积,可以在WHERE加入有效的连接条件(但是连接条件,并不是只能写在WHERE子句中,后续的外连接是写在ON子句)。
- 加入连接条件后,查询语法:
SELECT t1.column_name,t2.column_name
FROM table1 t1,table2 t2
WHERE t1.column1 = t2.column2; -- 连接条件,应用到实际的表,需要替换实际的列名
- 使用employees,deparments表写案例:
SELECT e.last_name,d.department_name
FROM employees e,departments d
WHERE e.dapartment_id = d.dapartment_id;
-- 在进行多表查询时,可以给表起别名,但是要注意,起表的别名,和列名的别名不同。可以省略as关键字和列别名相同,但是表名不能写在''中,否则会报错。
mysql> SELECT e.last_name,d.department_name
-> FROM employees 'e',department 'd'
-> WHERE e.department_id = d.department_id;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near ''e',department 'd'
WHERE e.department_id = d.department_id' at line 2
- 在不同的表中有相同列时,必须在列名前要加上使用的表名前缀。
2.多表查询分类讲解
2.1 等值连接 vs 非等值连接
2.1.1 等值连接
mysql> SELECT e.employee_id,e.last_name,e.department_id,d.department_id,d.location_id
-> FROM employees e,departments d
-> WHERE e.department_id = d.department_id;
+-------------+-------------+---------------+---------------+-------------+
| employee_id | last_name | department_id | department_id | location_id |
+-------------+-------------+---------------+---------------+-------------+
| 103 | Hunold | 60 | 60 | 1400 |
| 104 | Ernst | 60 | 60 | 1400 |
| 105 | Austin | 60 | 60 | 1400 |
| 106 | Pataballa | 60 | 60 | 1400 | -- 只显示一部分数据,一共有106行数据
拓展1:多个连接条件要使用AND操作符。
拓展2:区分重复的别名:
- 进行表查询的表中有相同列时,必须在列名之前加上表名前缀进行区分,使用的是那张表的列数据。
拓展3:表的别名。
- 使用别名可以简化查询。
- 列名前使用表名前缀可以提高查询效率。
但是需要注意,如果给表起了别名,在查询字段中,过滤条件中就只能使用别名进行代替,不能使用原有的表名,否则就会报错。
建议,从SQL优化的角度,建议多表查询时,每个字段前都指明其所在的表。


拓展4:连接多个表
总结:连接n个表,至少需要n-1个连接条件。比如,连接三个表,至少需要两个连接条件。
2.2.2 非等值连接
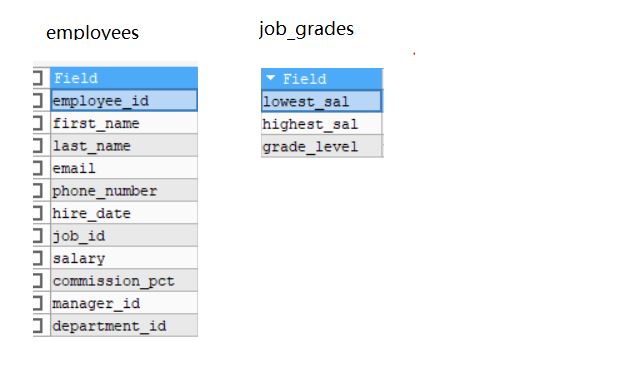
-- 查询员工薪资和薪资等级
SELECT e.salary,j.grade_level
FROM employees e,job_grades j
WHERE e.salary >= lowest_sal AND e.salary <= highest.sal;
2.2 自连接 vs 非自连接
当table1和table2是同一张表,只是采用起别名的方式虚拟成两张表,代表不同的意义。然后两张表进行连接查询,就是自连接。
employees表中,有employee_id列,和manager_id列。
-- 查询员工和其对应领导的信息
SELECT
w.`employee_id` AS 'worker_id',
w.`last_name` AS 'worker_name',
m.`employee_id` AS 'manager_id',
m.`last_name` AS 'manager_name'
FROM
employees w,employees m
WHERE
w.manager_id = m.employee_id;
-- 但是这里会有个小漏洞,就是可能会遗漏manager_id是null的数据
mysql> SELECT
-> w.`employee_id` AS 'worker_id',
-> w.`last_name` AS 'worker_name',
-> m.`employee_id` AS 'manager_id',
-> m.`last_name` AS 'manager_name'
-> FROM
-> employees w,employees m
-> WHERE
-> w.manager_id = m.employee_id;
+-----------+-------------+------------+--------------+
| worker_id | worker_name | manager_id | manager_name |
+-----------+-------------+------------+--------------+
| 101 | Kochhar | 100 | King |
| 102 | De Haan | 100 | King |
| 103 | Hunold | 102 | De Haan |
...
| 204 | Baer | 101 | Kochhar |
| 205 | Higgins | 101 | Kochhar |
| 206 | Gietz | 205 | Higgins |
+-----------+-------------+------------+--------------+
106 rows in set (0.00 sec)
mysql> SELECT COUNT(*) FROM employees;
+----------+
| COUNT(*) |
+----------+
| 107 |
+----------+
1 row in set (0.00 sec)
从执行结果看,此自连接语句,查询一共有106条数据,但是employees表有107条数据。这是因为内连接(从另一个分类角度,该条自连接语句也属于内连接),对于连接条件为NULL的一行数据会不显示。
mysql> SELECT
-> w.`employee_id` AS 'worker_id',
-> w.`last_name` AS 'worker_name',
-> m.`employee_id` AS 'manager_id',
-> m.`last_name` AS 'manager_name'
-> FROM
-> employees w
-> LEFT JOIN employees m
-> ON w.manager_id = m.employee_id;
+-----------+-------------+------------+--------------+
| worker_id | worker_name | manager_id | manager_name |
+-----------+-------------+------------+--------------+
| 100 | King | NULL | NULL |
| 101 | Kochhar | 100 | King |
| 102 | De Haan | 100 | King |
...
| 203 | Mavris | 101 | Kochhar |
| 204 | Baer | 101 | Kochhar |
| 205 | Higgins | 101 | Kochhar |
| 206 | Gietz | 205 | Higgins |
+-----------+-------------+------------+--------------+
107 rows in set (0.00 sec)
这里使用外连接,就会显示107条数据其中worker_id = 100的一行数据,就是上述自连接不显示的一条。下面进行内连接和外连接的讲解。
2.3 内连接 vs 外连接
除了查询满足条件的记录以外,外连接还可以查询某一方不满足条件的记录。
- 内连接, 合并具有同一列的两个以上的表的行,结果集中不包含一个表与另一个表不匹配的行
- 外连接,两个表在连接过程中除了返回满足连接条件的行以外,还返回左(或右)表中不满足条件的行,这种连接称为左(或右)外连接。没有匹配的行时,结果表中相应的列为null
- 如果是左外连接,则连接条件中左边的表为
主表,右边的表为从表。
如果是右外连接,则连接条件中右边的表为主表,左边的表为从表。
SQL 92 使用(+)创建连接
- 在SQL 92中采用(+)代表从表所在的位置。即左或右外连接中,(+)在连接条件的那边那个就是从表。
- Oracle对SQL92支持较好,而MySQL则不支持SQL92的外连接
- 在SQL 92中,只有左外连接和右外连接,没有满(或全)外连接。
3.SQL99语法实现多表查询
3.1 基本语法
- 使用JOIN…ON子句创建连接的语法结构:
SELECT table1.column,table2.column,table3.column
FROM table1
JOIN table2 ON -- table1和table2的连接条件
JOIN table3 ON -- table2和table3的连接条件
它的嵌套逻辑类似我们使用的FOR循环:
for t1 in table1:
for t2 in table2:
if condition1:
for t3 in table3:
if condition2:
output t1 + t2 + t3;
SQL99采用的这种嵌套结构,非常清爽,层次性更强,可读性更强,即是更多的表进行连接也都清晰可见。如果采用SQL92,可读性就会大打折扣。
- 语法说明
- 可使用ON子句指定额外的连接条件。
- 这个连接条件是与其他条件分开的。
- ON子句使语句具有更高的可读性。
- 关键字JOIN,INNER JOIN,CROSS JOIN的含义是一样的,都表示为内连接。
3.2 内连接(INNER JOIN)的实现
- 语法:
SELECT 字段列表
FROM A表 INNER JOIN B表
ON 关联条件
WHERE 过滤条件
-- INNER关键字可省略
mysql> SELECT e.employee_id,d.department_name,d.department_id
-> FROM employees AS e INNER JOIN departments AS d
-> ON e.department_id = d.department_id;
+-------------+------------------+---------------+
| employee_id | department_name | department_id |
+-------------+------------------+---------------+
| 200 | Administration | 10 |
| 201 | Marketing | 20 |
| 202 | Marketing | 20 |
...
| 113 | Finance | 100 |
| 205 | Accounting | 110 |
| 206 | Accounting | 110 |
+-------------+------------------+---------------+
106 rows in set (0.01 sec)
mysql> SELECT
-> e.employee_id,
-> d.department_name,
-> d.department_id,
-> l.city
-> FROM
-> employees e
-> JOIN departments d
-> ON e.department_id = d.department_id
-> JOIN locations l
-> ON d.`location_id` = l.location_id;
+-------------+------------------+---------------+---------------------+
| employee_id | department_name | department_id | city |
+-------------+------------------+---------------+---------------------+
| 200 | Administration | 10 | Seattle |
| 201 | Marketing | 20 | Toronto |
| 202 | Marketing | 20 | Toronto |
...
| 113 | Finance | 100 | Seattle |
| 205 | Accounting | 110 | Seattle |
| 206 | Accounting | 110 | Seattle |
+-------------+------------------+---------------+---------------------+
106 rows in set (0.00 sec)
3.3 外连接(OUTER JOIN)的实现
3.3.1 左外连接(LEFT OUTER JOIN)
- 语法
-- 主表是A OUTER关键字可以省略
SELECT 字段列表
FROM A表 LEFT OUTER JOIN B表
ON 关联条件
WHERE 过滤条件
- 举例
mysql> SELECT e.employee_id,d.department_name,d.department_id
-> FROM employees e LEFT OUTER JOIN departments d
-> ON e.department_id = d.department_id;
+-------------+------------------+---------------+
| employee_id | department_name | department_id |
+-------------+------------------+---------------+
| 178 | NULL | NULL |
| 200 | Administration | 10 |
| 201 | Marketing | 20 |
| 202 | Marketing | 20 |
...
| 112 | Finance | 100 |
| 113 | Finance | 100 |
| 205 | Accounting | 110 |
| 206 | Accounting | 110 |
+-------------+------------------+---------------+
107 rows in set (0.00 sec)
3.3.2 右外连接(RIGHT OUTER JOIN)
- 语法
-- 主表是B表 OUTER关键词也可以省略
SELECT 字段列表
FROM A表 RIGHT OUTER JOIN B表
ON 关联条件
WHERE 过滤条件
- 举例
mysql> SELECT e.employee_id,d.department_name,d.department_id
-> FROM employees e RIGHT JOIN departments d
-> ON e.department_id = d.department_id;
+-------------+----------------------+---------------+
| employee_id | department_name | department_id |
+-------------+----------------------+---------------+
| 200 | Administration | 10 |
| 201 | Marketing | 20 |
| 202 | Marketing | 20 |
| 114 | Purchasing | 30 |
...
| NULL | Government Sales | 240 |
| NULL | Retail Sales | 250 |
| NULL | Recruiting | 260 |
| NULL | Payroll | 270 |
+-------------+----------------------+---------------+
122 rows in set (0.00 sec)
注意,LEFT JOIN和RIGHT JOIN只存在于SQL99及以后的标准中,在SQL92中不存在,只能用(+)表示。
3.3.3 满外连接(FULL OUTER JOIN)
- 满外连接的结果 = 左右表匹配的数据 + 左表没有匹配到的数据 + 右表没有匹配到的数据。
- SQL99是支持满外连接的。使用FULL JOIN或FULL OUTER JOIN来实现。
- 需要注意的是,MySQL不支持FULL JOIN,但是可以用LEFT JOIN UNION RIGHT JOIN等替代。
4.UNION的使用
合并查询结果利用UNION关键字,可以给出多条SELECT语句,并将它们的结果组合成单个结果集。合并时,两个表对于的列数和数据类型必须相同,并且互相对应。各个SELECT语句之间使用UNION或UNION ALL关键字分隔。
语法格式:
SELECT column,... FROM t1
UNION [ALL]
SELECT column,... FROM t2
UNION操作符
UNION 操作符返回两个查询的结果集的并集,去除重复记录。
UNION ALL操作符
UNION ALL操作符返回两个查询的结果集的并集。对于两个结果集的重复部分,不去重。
注意,执行UNION ALL 语句时所需要的资源比UNION语句少,如果明确知道合并数据后的结果数据不存在重复数据,或者不需要去除重复的数据,则尽量使用UNION ALL语句,以提高数据查询的效率。
5. 7种SQL JOINS的实现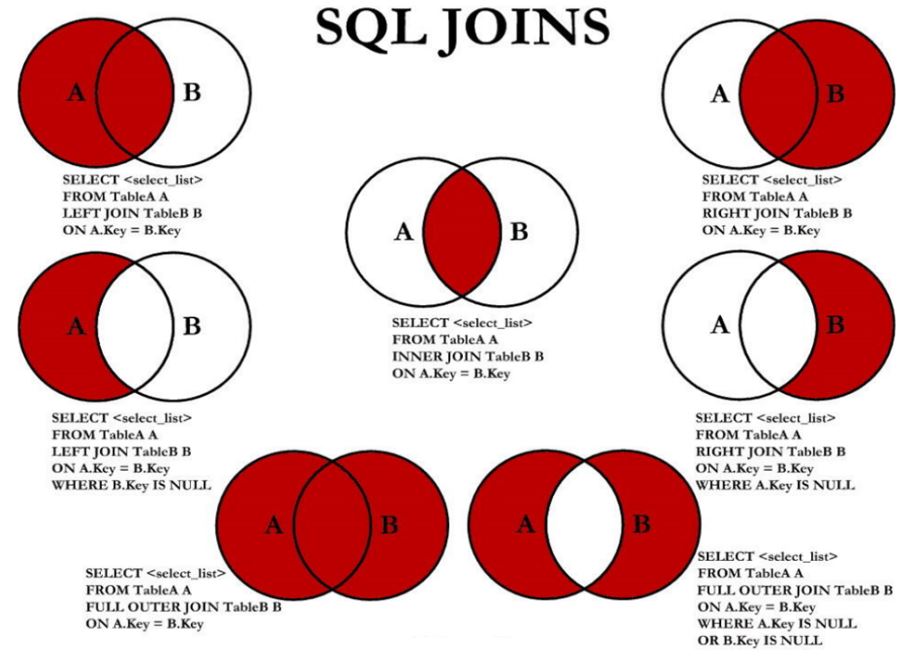
5.7.1 SQL实现
# 7种JOIN 使用employees表和departments表代表A和B
#中图
SELECT e.employee_id,d.department_name,d.department_id
FROM employees e JOIN departments d
ON e.department_id = d.department_id;
# 左上图
# 分析,将e表和d表比作两个集合的话
# 左上图就是 (e - e ∩ d) ∪ ( e ∩ d) 在MySQL中用LEFT JOIN ... ON实现
# 分析,为什么LEFT JOIN ... ON可以实现
# 因为,在外连接中,相当于有一个表是主表,另一个表是从表,在外连接中
# 主表的数据一定要全部实现,对于主表中有数据,而从表没有与之对于连接条件成立的数据
# 就将要显示的从表中的列补null进行显示
SELECT e.employee_id,d.department_name,d.department_id
FROM employees e LEFT JOIN departments d
ON e.department_id = d.department_id;
# 右上图
# 分析,将e表和d表比作两个集合的话
# 右上图就是 (d - e ∩ d) ∪ ( e ∩ d) 在MySQL中用RIGHT JOIN ... ON实现
SELECT e.employee_id,d.department_name,d.department_id
FROM employees e RIGHT JOIN departments d
ON e.department_id = d.department_id;
#分析主从表就是,左连接左是主表,右连接右是主表
# 左中图
# 分析,将e表和d表比作两个集合的话
# 左中图就是 (e - e ∩ d)
# 就是在左上图(e和d表进行左连接)的前提下,去掉e表和d表中都出现的数据
# 只保留主表中有数据,但是从表无数据的列
# 从表无数据就是,从表的过滤条件中不满足,所以过滤条件是 WHERE d.department_id IS NULL
SELECT e.employee_id,d.department_name,d.department_id
FROM employees e LEFT JOIN departments d
ON e.department_id = d.department_id
WHERE d.department_id IS NULL;
# 右中图
# 分析,将e表和d表比作两个集合的话
# 右中图就是 (d - e ∩ d)
# 就是在右上图(e和d表进行右连接)的前提下,去掉e表和d表中都出现的数据
# 只保留主表中有数据,但是从表无数据的列
# 从表无数据就是,从表的过滤条件中不满足,所以过滤条件是 WHERE e.department_id IS NULL
SELECT e.employee_id,d.department_name,d.department_id
FROM employees e RIGHT JOIN departments d
ON e.department_id = d.department_id
WHERE e.department_id IS NULL;
# 左下图
# 就是满外连接
# MySQL实现满外连接
# 使用到UNION/UNION ALL关键字
# 可以用左上图 UNION 右上图
# 也可以用左上图 UNION ALL 右中图
# 也可以用左中图 UNION ALL 右上图
-- 具体的SQL语句略
# 右下图
# 就是左中图 UNION ALL 右中图
SELECT e.employee_id,d.department_name,d.department_id
FROM employees e LEFT JOIN departments d
ON e.department_id = d.department_id
WHERE d.department_id IS NULL
UNION ALL
SELECT e.employee_id,d.department_name,d.department_id
FROM employees e RIGHT JOIN departments d
ON e.department_id = d.department_id
WHERE e.department_id IS NULL;
5.7.2 语法格式小结
- 左中图
-- 实现 A - A ∩ B
SELECT 字段列表
FROM A LEFT JOIN B
ON 关联条件
WHERE 从表关联字段 IS NULL ANd 其他过滤子句;
- 右中图
-- 实现B - A ∩ B
SELECT 字段列表
FROM A RIGHT JOIN B
ON 关联条件
WHERE 从表关联字段 IS NULL ANd 其他过滤子句;
6.SQL99语法新特性
6.1 自然连接
SQL99在SQL92的基础上,提供了一些特殊语法,比如 NATURAL JOIN用来表示自然连接。我们可以把自然连接理解为SQL92中的等值连接。它会自动查询两张表里所有相同的字段,然后进行等值连接。
-- 等值连接
SELECT e.employee_id,d.department_name,d.department_id
FROM employees e JOIN departments d
ON e.department_id = d.department_id
AND e.`manager_id` = d.`manager_id`;
-- 使用NATURAL JOIN新特性实现等值连接
SELECT e.employee_id,d.department_name,d.department_id
FROM employees e NATURAL JOIN departments d;
6.2 USING连接
SELECT e.employee_id,d.department_name,d.department_id
FROM employees e JOIN departments d
USING (department_id);
-- 等价于
SELECT e.employee_id,d.department_name,d.department_id
FROM employees e JOIN departments d
USING e.department_id = d.department_id;
7.章节小结
表连接的约束条件可以有三种方式,WHERE,ON,USING
- WHERE: 适用于所有关联查询。
- ON:只能和JOIN一起使用,只能写关联条件。虽然关联条件可以并到WHERE中和其他条件一起写,但分开写可读性更好。
- USING: 只能和JOIN一起使用,而且要求关联字段在两张表中相同,而且只能表示关联字段相等。
注意:
要控制连接表的数量,多表连接就相当于嵌套for循环一样,非常消耗资源,会让SQL查询性能下降很严重,因此不要连接不必要的表。在许多DBMS中,也都会有最大连接表限制。

只是为了记录自己的学习历程,且本人水平有限,不对之处,请指正。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/213044.html

